 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCALAR: A Part-of-speech Tagger for Identifiers
Apr 23, 2025The paper presents the Source Code Analysis and Lexical Annotation Runtime (SCALAR), a tool specialized for mapping (annotating) source code identifier names to their corresponding part-of-speech tag sequence (grammar pattern). SCALAR's internal model is trained using scikit-learn's GradientBoostingClassifier in conjunction with a manually-curated oracle of identifier names and their grammar patterns. This specializes the tagger to recognize the unique structure of the natural language used by developers to create all types of identifiers (e.g., function names, variable names etc.). SCALAR's output is compared with a previous version of the tagger, as well as a modern off-the-shelf part-of-speech tagger to show how it improves upon other taggers' output for annotating identifiers. The code is available on Github
An Ensemble Approach for Annotating Source Code Identifiers with Part-of-speech Tags
Sep 01, 2021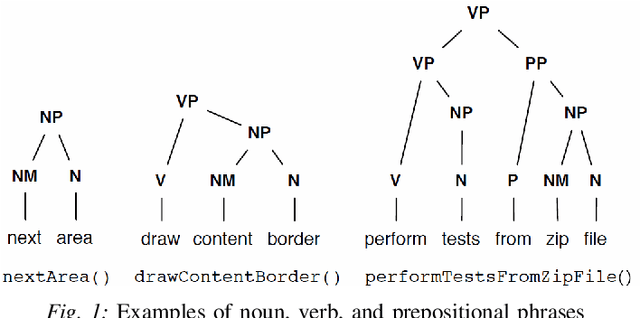

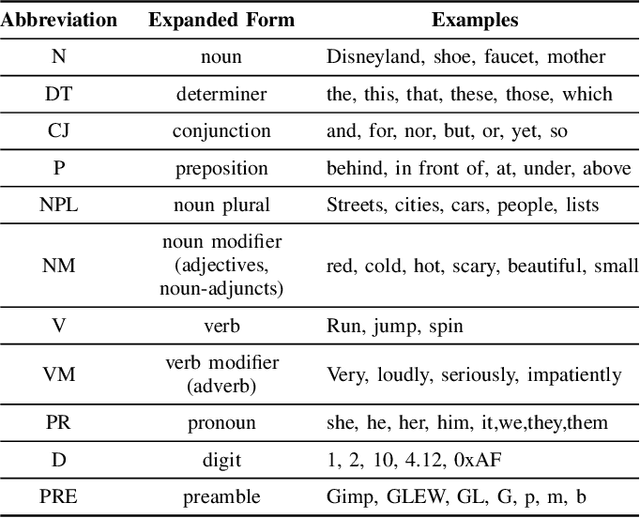
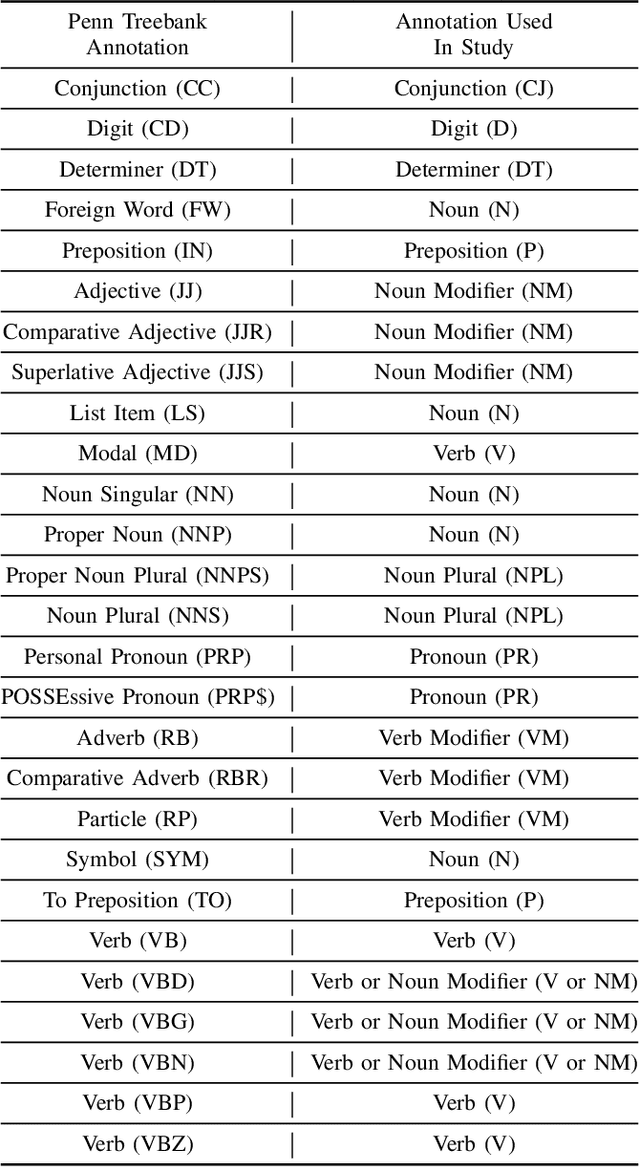
This paper presents an ensemble part-of-speech tagging approach for source code identifiers. Ensemble tagging is a technique that uses machine-learning and the output from multiple part-of-speech taggers to annotate natural language text at a higher quality than the part-of-speech taggers are able to obtain independently. Our ensemble uses three state-of-the-art part-of-speech taggers: SWUM, POSSE, and Stanford. We study the quality of the ensemble's annotations on five different types of identifier names: function, class, attribute, parameter, and declaration statement at the level of both individual words and full identifier names. We also study and discuss the weaknesses of our tagger to promote the future amelioration of these problems through further research. Our results show that the ensemble achieves 75\% accuracy at the identifier level and 84-86\% accuracy at the word level. This is an increase of +17\% points at the identifier level from the closest independent part-of-speech tagger.
* 18 pages. arXiv admin note: text overlap with arXiv:2007.08033