 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning in Multilingual Neural Machine Translation with Dynamic Vocabulary
Nov 03, 2018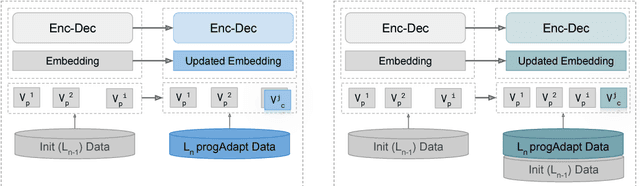
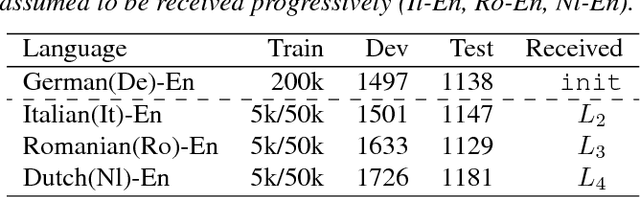
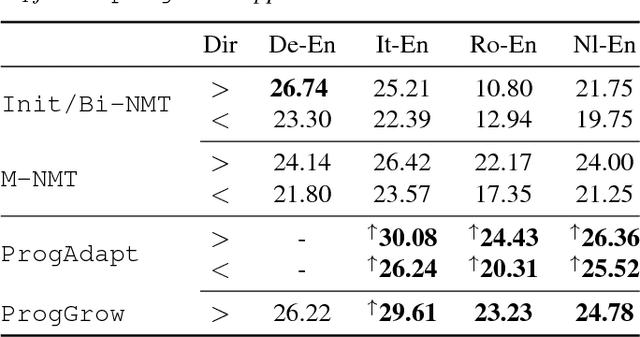
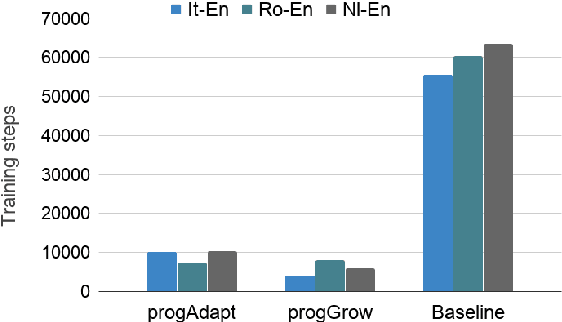
We propose a method to transfer knowledge across neural machine translation (NMT) models by means of a shared dynamic vocabulary. Our approach allows to extend an initial model for a given language pair to cover new languages by adapting its vocabulary as long as new data become available (i.e., introducing new vocabulary items if they are not included in the initial model). The parameter transfer mechanism is evaluated in two scenarios: i) to adapt a trained single language NMT system to work with a new language pair and ii) to continuously add new language pairs to grow to a multilingual NMT system. In both the scenarios our goal is to improve the translation performance, while minimizing the training convergence time. Preliminary experiments spanning five languages with different training data sizes (i.e., 5k and 50k parallel sentences) show a significant performance gain ranging from +3.85 up to +13.63 BLEU in different language directions. Moreover, when compared with training an NMT model from scratch, our transfer-learning approach allows us to reach higher performance after training up to 4% of the total training steps.
Fine-tuning on Clean Data for End-to-End Speech Translation: FBK @ IWSLT 2018
Oct 16, 2018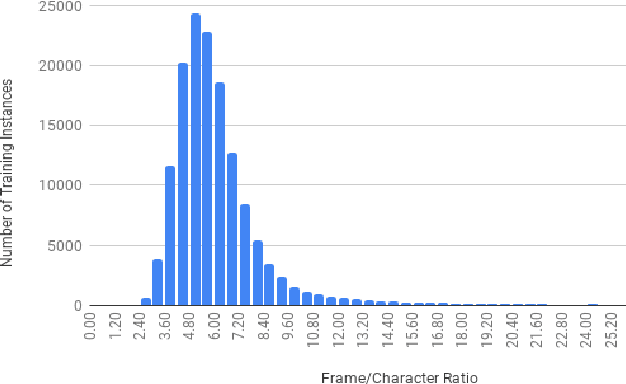
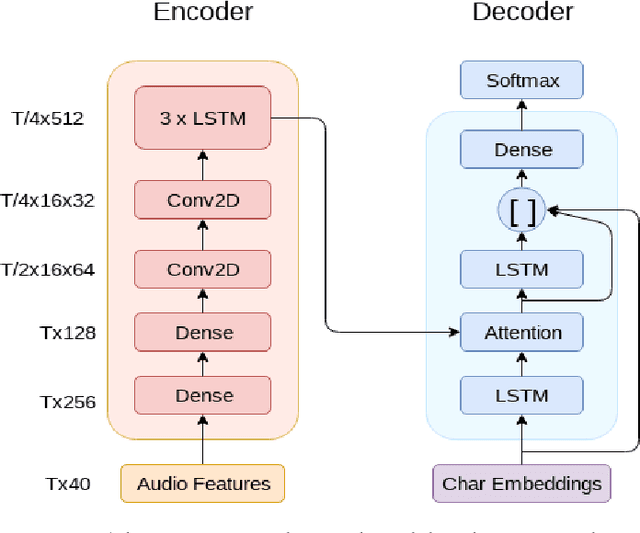

This paper describes FBK's submission to the end-to-end English-German speech translation task at IWSLT 2018. Our system relies on a state-of-the-art model based on LSTMs and CNNs, where the CNNs are used to reduce the temporal dimension of the audio input, which is in general much higher than machine translation input. Our model was trained only on the audio-to-text parallel data released for the task, and fine-tuned on cleaned subsets of the original training corpus. The addition of weight normalization and label smoothing improved the baseline system by 1.0 BLEU point on our validation set. The final submission also featured checkpoint averaging within a training run and ensemble decoding of models trained during multiple runs. On test data, our best single model obtained a BLEU score of 9.7, while the ensemble obtained a BLEU score of 10.24.
eSCAPE: a Large-scale Synthetic Corpus for Automatic Post-Editing
Mar 20, 2018
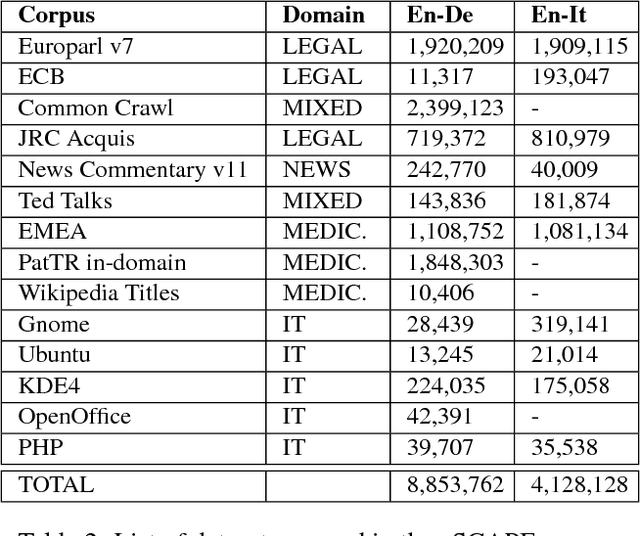
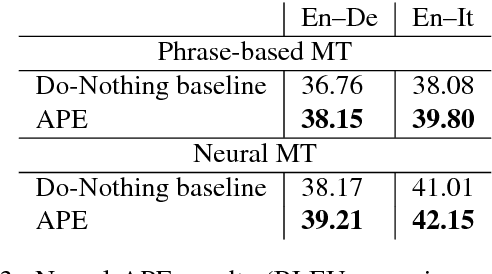
Training models for the automatic correction of machine-translated text usually relies on data consisting of (source, MT, human post- edit) triplets providing, for each source sentence, examples of translation errors with the corresponding corrections made by a human post-editor. Ideally, a large amount of data of this kind should allow the model to learn reliable correction patterns and effectively apply them at test stage on unseen (source, MT) pairs. In practice, however, their limited availability calls for solutions that also integrate in the training process other sources of knowledge. Along this direction, state-of-the-art results have been recently achieved by systems that, in addition to a limited amount of available training data, exploit artificial corpora that approximate elements of the "gold" training instances with automatic translations. Following this idea, we present eSCAPE, the largest freely-available Synthetic Corpus for Automatic Post-Editing released so far. eSCAPE consists of millions of entries in which the MT element of the training triplets has been obtained by translating the source side of publicly-available parallel corpora, and using the target side as an artificial human post-edit. Translations are obtained both with phrase-based and neural models. For each MT paradigm, eSCAPE contains 7.2 million triplets for English-German and 3.3 millions for English-Italian, resulting in a total of 14,4 and 6,6 million instances respectively. The usefulness of eSCAPE is proved through experiments in a general-domain scenario, the most challenging one for automatic post-editing. For both language directions, the models trained on our artificial data always improve MT quality with statistically significant gains. The current version of eSCAPE can be freely downloaded from: http://hltshare.fbk.eu/QT21/eSCAPE.html.
Linguistically Motivated Vocabulary Reduction for Neural Machine Translation from Turkish to English
Jul 31, 2017
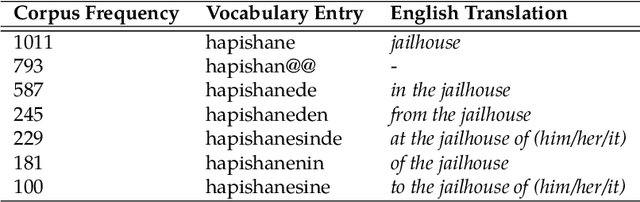


The necessity of using a fixed-size word vocabulary in order to control the model complexity in state-of-the-art neural machine translation (NMT) systems is an important bottleneck on performance, especially for morphologically rich languages. Conventional methods that aim to overcome this problem by using sub-word or character-level representations solely rely on statistics and disregard the linguistic properties of words, which leads to interruptions in the word structure and causes semantic and syntactic losses. In this paper, we propose a new vocabulary reduction method for NMT, which can reduce the vocabulary of a given input corpus at any rate while also considering the morphological properties of the language. Our method is based on unsupervised morphology learning and can be, in principle, used for pre-processing any language pair. We also present an alternative word segmentation method based on supervised morphological analysis, which aids us in measuring the accuracy of our model. We evaluate our method in Turkish-to-English NMT task where the input language is morphologically rich and agglutinative. We analyze different representation methods in terms of translation accuracy as well as the semantic and syntactic properties of the generated output. Our method obtains a significant improvement of 2.3 BLEU points over the conventional vocabulary reduction technique, showing that it can provide better accuracy in open vocabulary translation of morphologically rich languages.
* The 20th Annual Conference of the European Association for Machine Translation (EAMT), Research Paper, 12 pages
Automatic Quality Estimation for ASR System Combination
Jun 22, 2017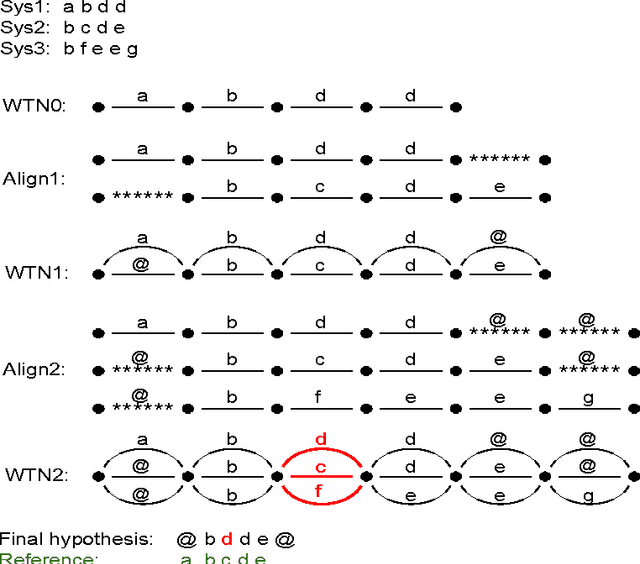
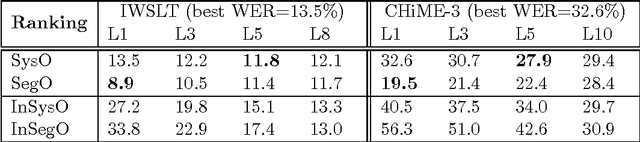


Recognizer Output Voting Error Reduction (ROVER) has been widely used for system combination in automatic speech recognition (ASR). In order to select the most appropriate words to insert at each position in the output transcriptions, some ROVER extensions rely on critical information such as confidence scores and other ASR decoder features. This information, which is not always available, highly depends on the decoding process and sometimes tends to over estimate the real quality of the recognized words. In this paper we propose a novel variant of ROVER that takes advantage of ASR quality estimation (QE) for ranking the transcriptions at "segment level" instead of: i) relying on confidence scores, or ii) feeding ROVER with randomly ordered hypotheses. We first introduce an effective set of features to compensate for the absence of ASR decoder information. Then, we apply QE techniques to perform accurate hypothesis ranking at segment-level before starting the fusion process. The evaluation is carried out on two different tasks, in which we respectively combine hypotheses coming from independent ASR systems and multi-microphone recordings. In both tasks, it is assumed that the ASR decoder information is not available. The proposed approach significantly outperforms standard ROVER and it is competitive with two strong oracles that e xploit prior knowledge about the real quality of the hypotheses to be combined. Compared to standard ROVER, the abs olute WER improvements in the two evaluation scenarios range from 0.5% to 7.3%.
DNN adaptation by automatic quality estimation of ASR hypotheses
Feb 06, 2017
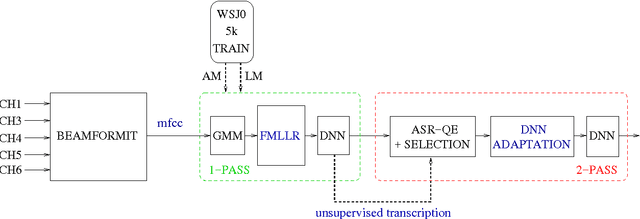
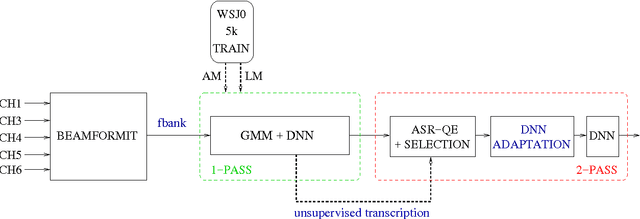
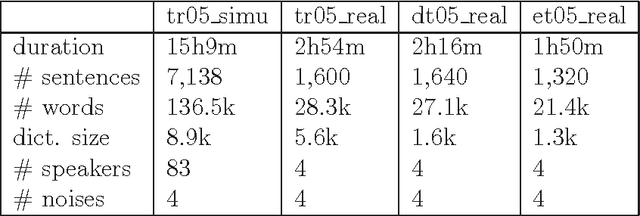
In this paper we propose to exploit the automatic Quality Estimation (QE) of ASR hypotheses to perform the unsupervised adaptation of a deep neural network modeling acoustic probabilities. Our hypothesis is that significant improvements can be achieved by: i)automatically transcribing the evaluation data we are currently trying to recognise, and ii) selecting from it a subset of "good quality" instances based on the word error rate (WER) scores predicted by a QE component. To validate this hypothesis, we run several experiments on the evaluation data sets released for the CHiME-3 challenge. First, we operate in oracle conditions in which manual transcriptions of the evaluation data are available, thus allowing us to compute the "true" sentence WER. In this scenario, we perform the adaptation with variable amounts of data, which are characterised by different levels of quality. Then, we move to realistic conditions in which the manual transcriptions of the evaluation data are not available. In this case, the adaptation is performed on data selected according to the WER scores "predicted" by a QE component. Our results indicate that: i) QE predictions allow us to closely approximate the adaptation results obtained in oracle conditions, and ii) the overall ASR performance based on the proposed QE-driven adaptation method is significantly better than the strong, most recent, CHiME-3 baseline.
SentiWords: Deriving a High Precision and High Coverage Lexicon for Sentiment Analysis
Oct 30, 2015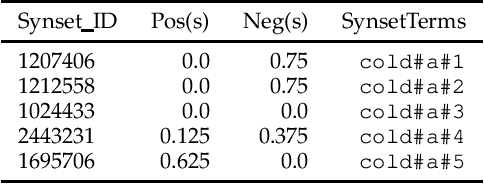
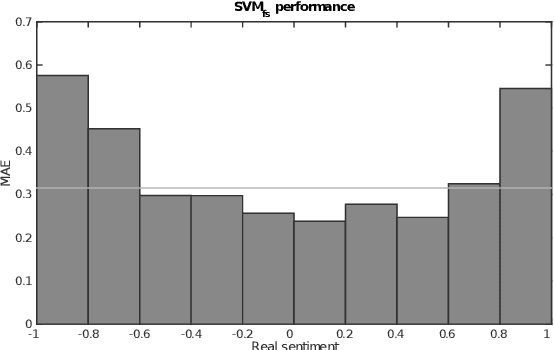
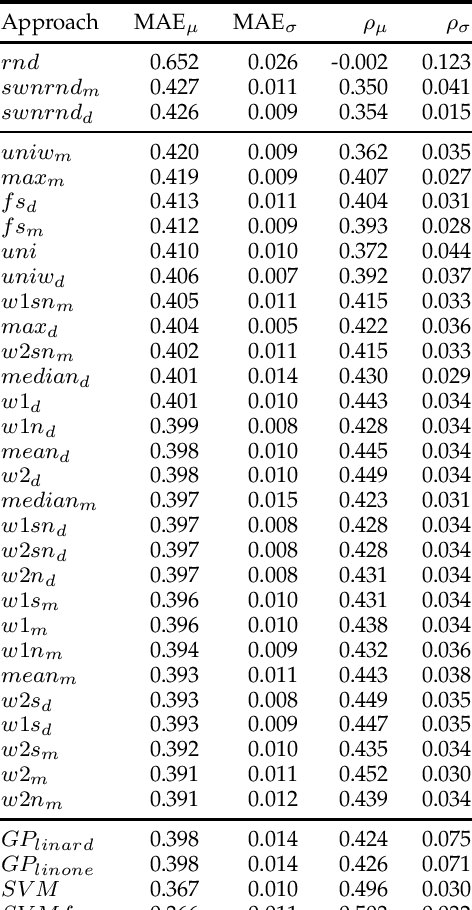
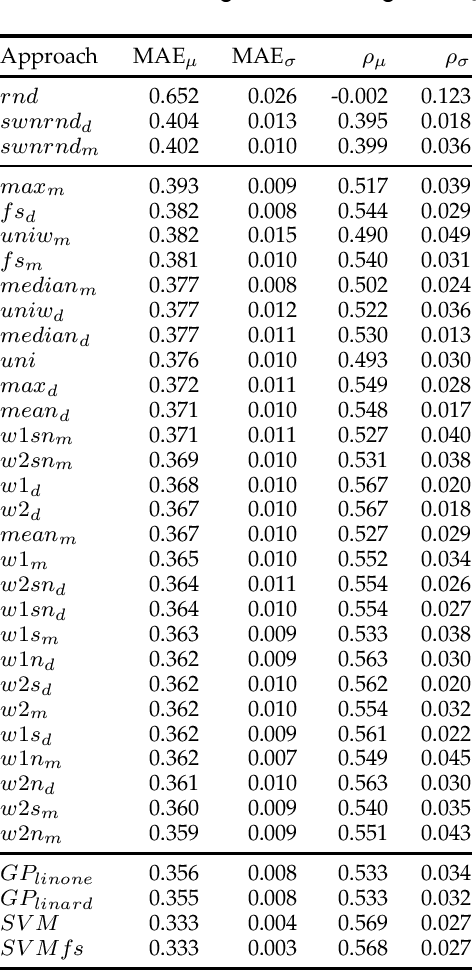
Deriving prior polarity lexica for sentiment analysis - where positive or negative scores are associated with words out of context - is a challenging task. Usually, a trade-off between precision and coverage is hard to find, and it depends on the methodology used to build the lexicon. Manually annotated lexica provide a high precision but lack in coverage, whereas automatic derivation from pre-existing knowledge guarantees high coverage at the cost of a lower precision. Since the automatic derivation of prior polarities is less time consuming than manual annotation, there has been a great bloom of these approaches, in particular based on the SentiWordNet resource. In this paper, we compare the most frequently used techniques based on SentiWordNet with newer ones and blend them in a learning framework (a so called 'ensemble method'). By taking advantage of manually built prior polarity lexica, our ensemble method is better able to predict the prior value of unseen words and to outperform all the other SentiWordNet approaches. Using this technique we have built SentiWords, a prior polarity lexicon of approximately 155,000 words, that has both a high precision and a high coverage. We finally show that in sentiment analysis tasks, using our lexicon allows us to outperform both the single metrics derived from SentiWordNet and popular manually annotated sentiment lexica.
ONTS: "Optima" News Translation System
Jan 13, 2014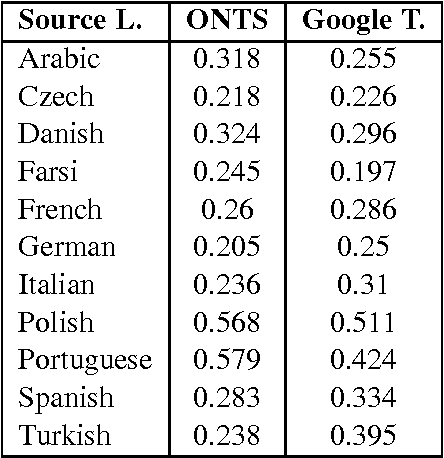

We propose a real-time machine translation system that allows users to select a news category and to translate the related live news articles from Arabic, Czech, Danish, Farsi, French, German, Italian, Polish, Portuguese, Spanish and Turkish into English. The Moses-based system was optimised for the news domain and differs from other available systems in four ways: (1) News items are automatically categorised on the source side, before translation; (2) Named entity translation is optimised by recognising and extracting them on the source side and by re-inserting their translation in the target language, making use of a separate entity repository; (3) News titles are translated with a separate translation system which is optimised for the specific style of news titles; (4) The system was optimised for speed in order to cope with the large volume of daily news articles.
Sentiment Analysis: How to Derive Prior Polarities from SentiWordNet
Sep 23, 2013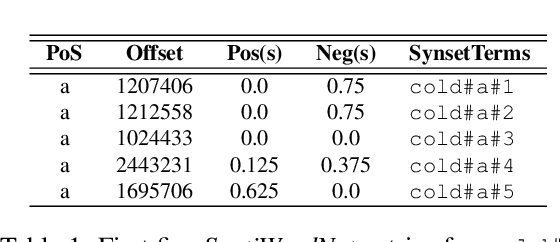
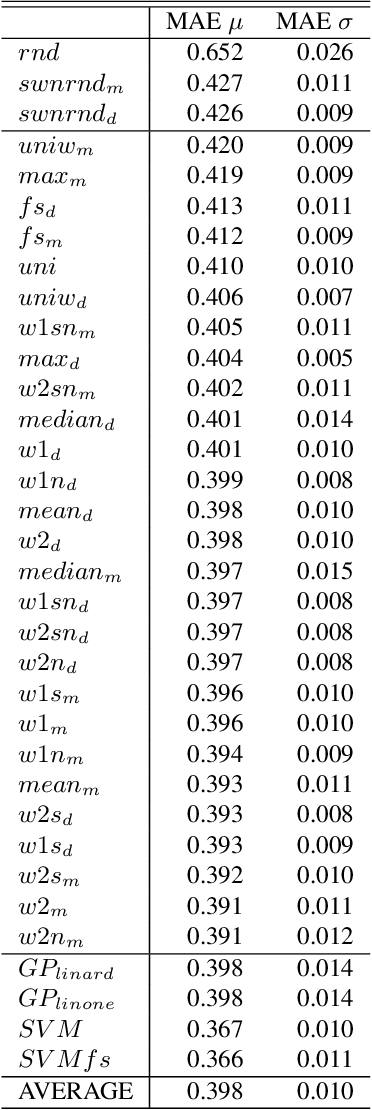
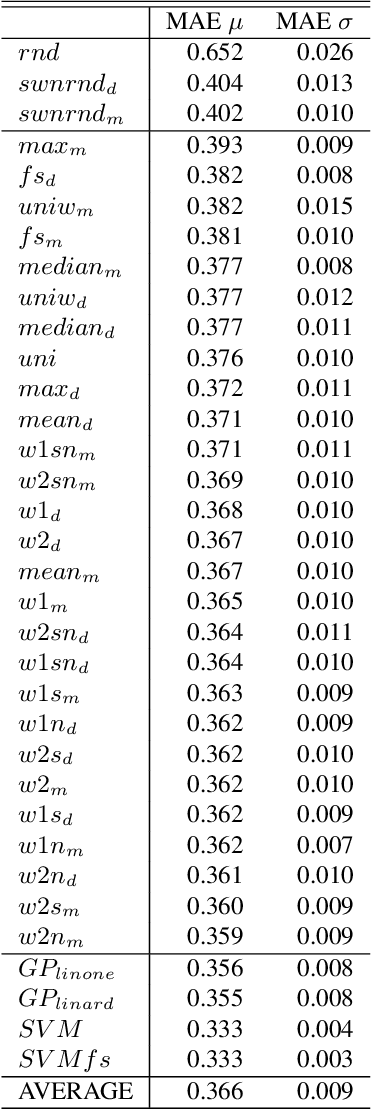
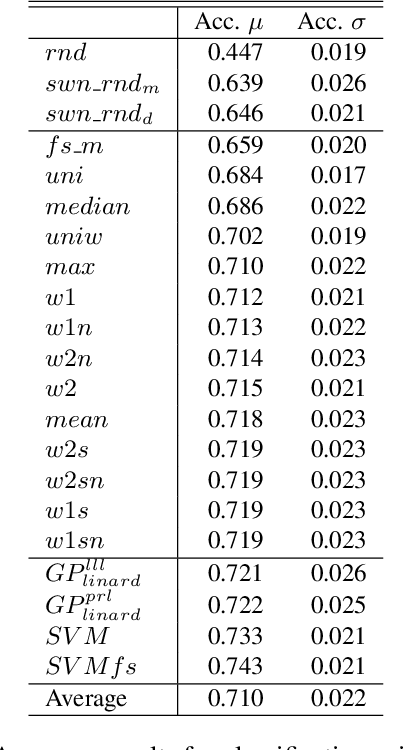
Assigning a positive or negative score to a word out of context (i.e. a word's prior polarity) is a challenging task for sentiment analysis. In the literature, various approaches based on SentiWordNet have been proposed. In this paper, we compare the most often used techniques together with newly proposed ones and incorporate all of them in a learning framework to see whether blending them can further improve the estimation of prior polarity scores. Using two different versions of SentiWordNet and testing regression and classification models across tasks and datasets, our learning approach consistently outperforms the single metrics, providing a new state-of-the-art approach in computing words' prior polarity for sentiment analysis. We conclude our investigation showing interesting biases in calculated prior polarity scores when word Part of Speech and annotator gender are considered.
JRC EuroVoc Indexer JEX - A freely available multi-label categorisation tool
Sep 20, 2013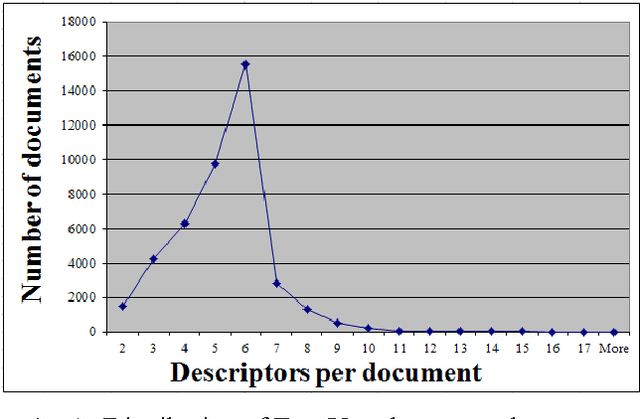
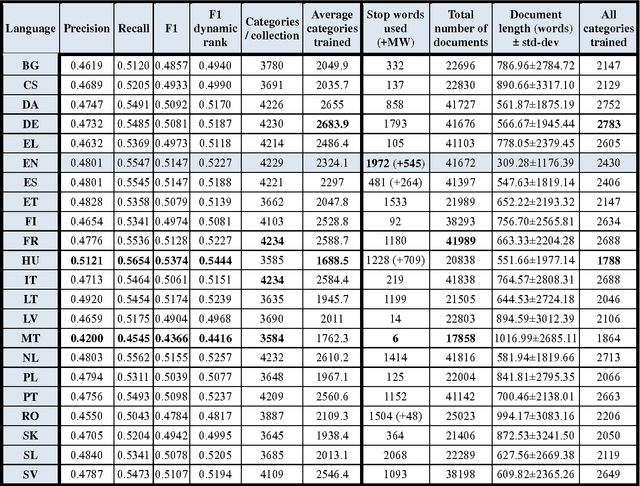
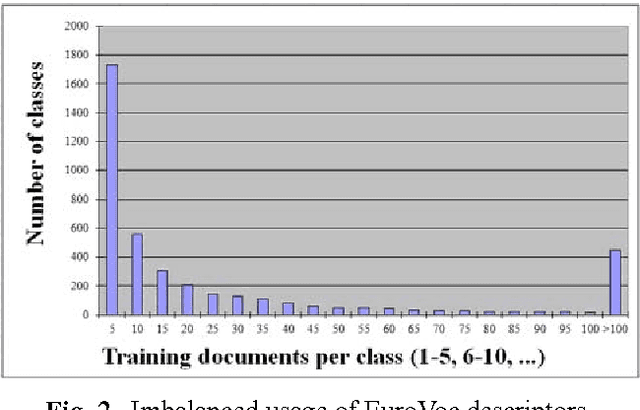
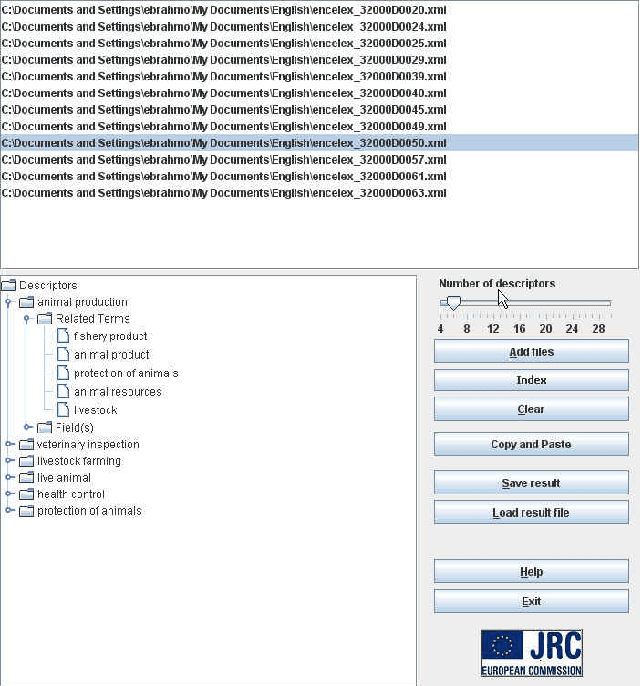
EuroVoc (2012) is a highly multilingual thesaurus consisting of over 6,700 hierarchically organised subject domains used by European Institutions and many authorities in Member States of the European Union (EU) for the classification and retrieval of official documents. JEX is JRC-developed multi-label classification software that learns from manually labelled data to automatically assign EuroVoc descriptors to new documents in a profile-based category-ranking task. The JEX release consists of trained classifiers for 22 official EU languages, of parallel training data in the same languages, of an interface that allows viewing and amending the assignment results, and of a module that allows users to re-train the tool on their own document collections. JEX allows advanced users to change the document representation so as to possibly improve the categorisation result through linguistic pre-processing. JEX can be used as a tool for interactive EuroVoc descriptor assignment to increase speed and consistency of the human categorisation process, or it can be used fully automatically. The output of JEX is a language-independent EuroVoc feature vector lending itself also as input to various other Language Technology tasks, including cross-lingual clustering and classification, cross-lingual plagiarism detection, sentence selection and ranking, and more.