 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Speech-Translation with Knowledge Distillation: FBK@IWSLT2020
Jun 04, 2020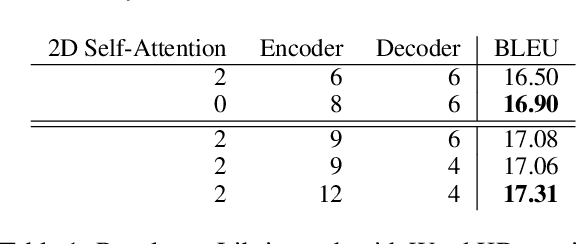
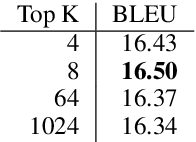
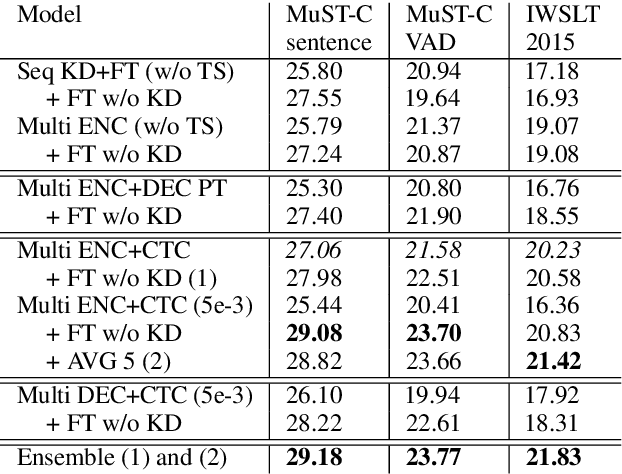
This paper describes FBK's participation in the IWSLT 2020 offline speech translation (ST) task. The task evaluates systems' ability to translate English TED talks audio into German texts. The test talks are provided in two versions: one contains the data already segmented with automatic tools and the other is the raw data without any segmentation. Participants can decide whether to work on custom segmentation or not. We used the provided segmentation. Our system is an end-to-end model based on an adaptation of the Transformer for speech data. Its training process is the main focus of this paper and it is based on: i) transfer learning (ASR pretraining and knowledge distillation), ii) data augmentation (SpecAugment, time stretch and synthetic data), iii) combining synthetic and real data marked as different domains, and iv) multi-task learning using the CTC loss. Finally, after the training with word-level knowledge distillation is complete, our ST models are fine-tuned using label smoothed cross entropy. Our best model scored 29 BLEU on the MuST-C En-De test set, which is an excellent result compared to recent papers, and 23.7 BLEU on the same data segmented with VAD, showing the need for researching solutions addressing this specific data condition.
Is 42 the Answer to Everything in Subtitling-oriented Speech Translation?
Jun 01, 2020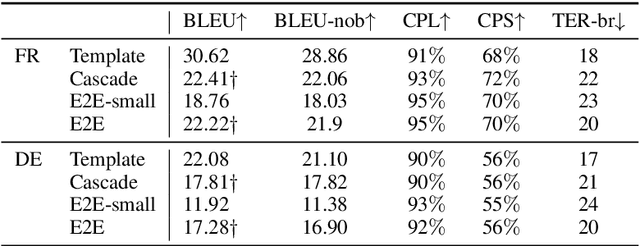
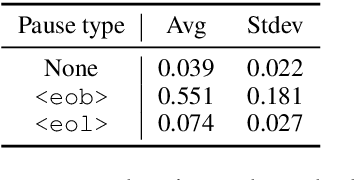

Subtitling is becoming increasingly important for disseminating information, given the enormous amounts of audiovisual content becoming available daily. Although Neural Machine Translation (NMT) can speed up the process of translating audiovisual content, large manual effort is still required for transcribing the source language, and for spotting and segmenting the text into proper subtitles. Creating proper subtitles in terms of timing and segmentation highly depends on information present in the audio (utterance duration, natural pauses). In this work, we explore two methods for applying Speech Translation (ST) to subtitling: a) a direct end-to-end and b) a classical cascade approach. We discuss the benefit of having access to the source language speech for improving the conformity of the generated subtitles to the spatial and temporal subtitling constraints and show that length is not the answer to everything in the case of subtitling-oriented ST.
Low Resource Neural Machine Translation: A Benchmark for Five African Languages
Mar 31, 2020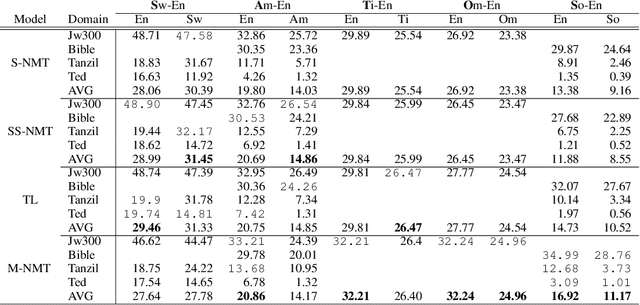
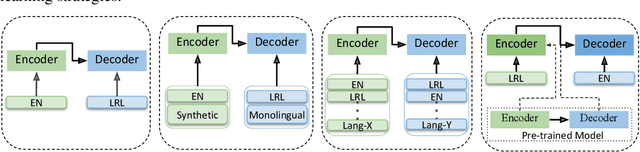

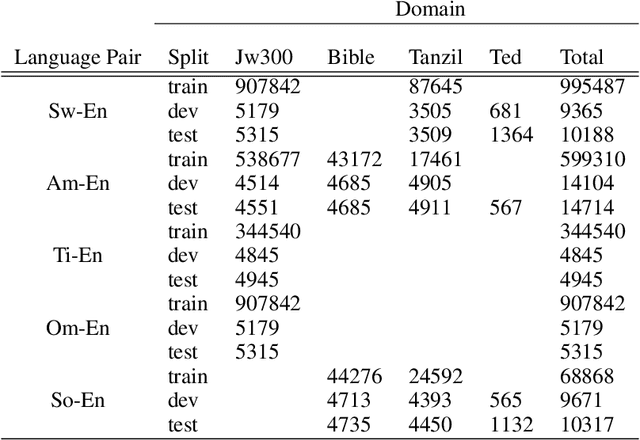
Recent advents in Neural Machine Translation (NMT) have shown improvements in low-resource language (LRL) translation tasks. In this work, we benchmark NMT between English and five African LRL pairs (Swahili, Amharic, Tigrigna, Oromo, Somali [SATOS]). We collected the available resources on the SATOS languages to evaluate the current state of NMT for LRLs. Our evaluation, comparing a baseline single language pair NMT model against semi-supervised learning, transfer learning, and multilingual modeling, shows significant performance improvements both in the En-LRL and LRL-En directions. In terms of averaged BLEU score, the multilingual approach shows the largest gains, up to +5 points, in six out of ten translation directions. To demonstrate the generalization capability of each model, we also report results on multi-domain test sets. We release the standardized experimental data and the test sets for future works addressing the challenges of NMT in under-resourced settings, in particular for the SATOS languages.
MuST-Cinema: a Speech-to-Subtitles corpus
Feb 25, 2020
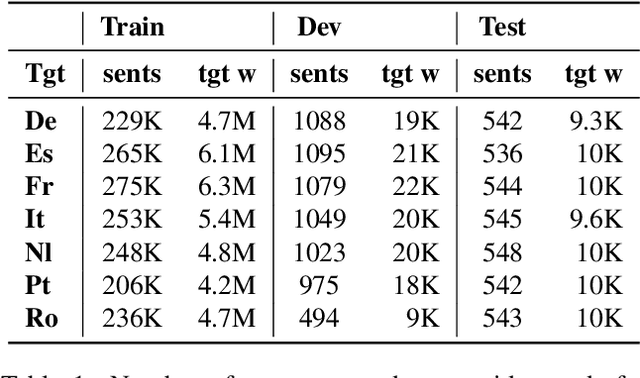

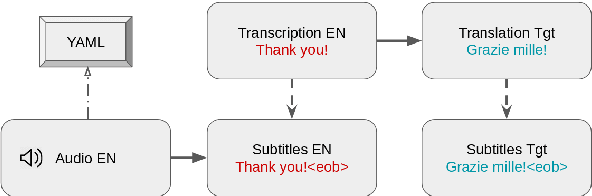
Growing needs in localising audiovisual content in multiple languages through subtitles call for the development of automatic solutions for human subtitling. Neural Machine Translation (NMT) can contribute to the automatisation of subtitling, facilitating the work of human subtitlers and reducing turn-around times and related costs. NMT requires high-quality, large, task-specific training data. The existing subtitling corpora, however, are missing both alignments to the source language audio and important information about subtitle breaks. This poses a significant limitation for developing efficient automatic approaches for subtitling, since the length and form of a subtitle directly depends on the duration of the utterance. In this work, we present MuST-Cinema, a multilingual speech translation corpus built from TED subtitles. The corpus is comprised of (audio, transcription, translation) triplets. Subtitle breaks are preserved by inserting special symbols. We show that the corpus can be used to build models that efficiently segment sentences into subtitles and propose a method for annotating existing subtitling corpora with subtitle breaks, conforming to the constraint of length.
Adapting Multilingual Neural Machine Translation to Unseen Languages
Oct 30, 2019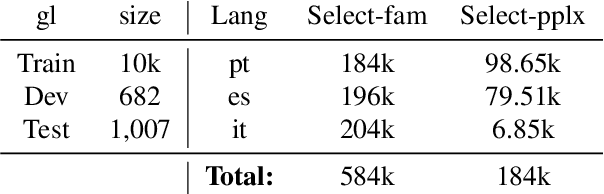
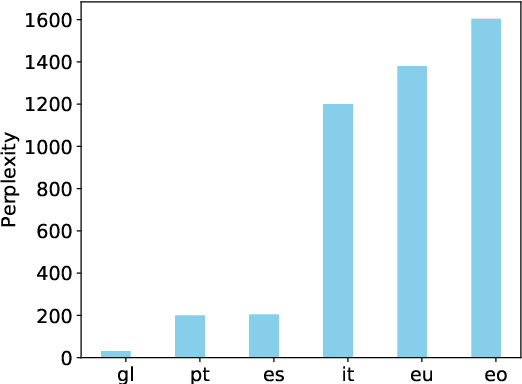
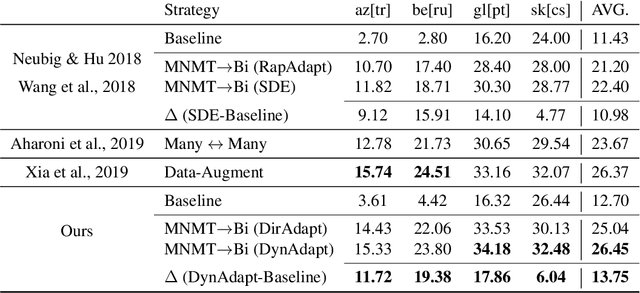
Multilingual Neural Machine Translation (MNMT) for low-resource languages (LRL) can be enhanced by the presence of related high-resource languages (HRL), but the relatedness of HRL usually relies on predefined linguistic assumptions about language similarity. Recently, adapting MNMT to a LRL has shown to greatly improve performance. In this work, we explore the problem of adapting an MNMT model to an unseen LRL using data selection and model adaptation. In order to improve NMT for LRL, we employ perplexity to select HRL data that are most similar to the LRL on the basis of language distance. We extensively explore data selection in popular multilingual NMT settings, namely in (zero-shot) translation, and in adaptation from a multilingual pre-trained model, for both directions (LRL-en). We further show that dynamic adaptation of the model's vocabulary results in a more favourable segmentation for the LRL in comparison with direct adaptation. Experiments show reductions in training time and significant performance gains over LRL baselines, even with zero LRL data (+13.0 BLEU), up to +17.0 BLEU for pre-trained multilingual model dynamic adaptation with related data selection. Our method outperforms current approaches, such as massively multilingual models and data augmentation, on four LRL.
Instance-Based Model Adaptation For Direct Speech Translation
Oct 23, 2019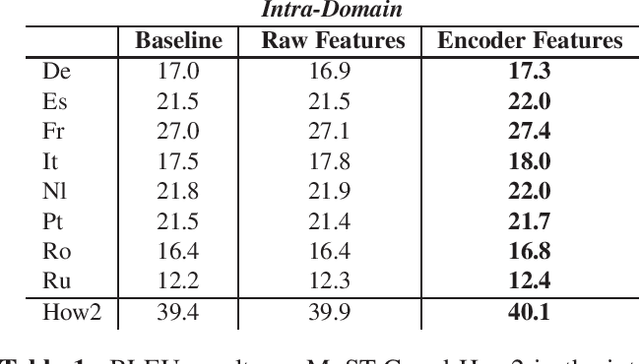
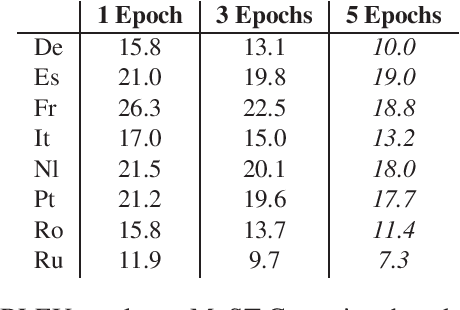
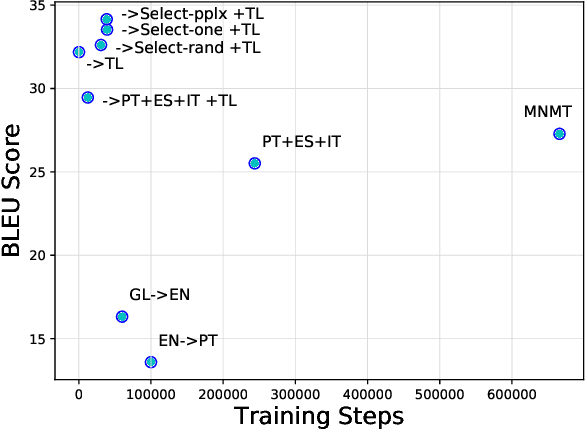
Despite recent technology advancements, the effectiveness of neural approaches to end-to-end speech-to-text translation is still limited by the paucity of publicly available training corpora. We tackle this limitation with a method to improve data exploitation and boost the system's performance at inference time. Our approach allows us to customize "on the fly" an existing model to each incoming translation request. At its core, it exploits an instance selection procedure to retrieve, from a given pool of data, a small set of samples similar to the input query in terms of latent properties of its audio signal. The retrieved samples are then used for an instance-specific fine-tuning of the model. We evaluate our approach in three different scenarios. In all data conditions (different languages, in/out-of-domain adaptation), our instance-based adaptation yields coherent performance gains over static models.
One-To-Many Multilingual End-to-end Speech Translation
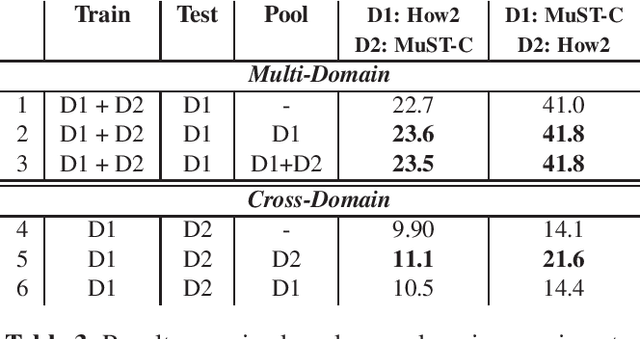
Oct 08, 2019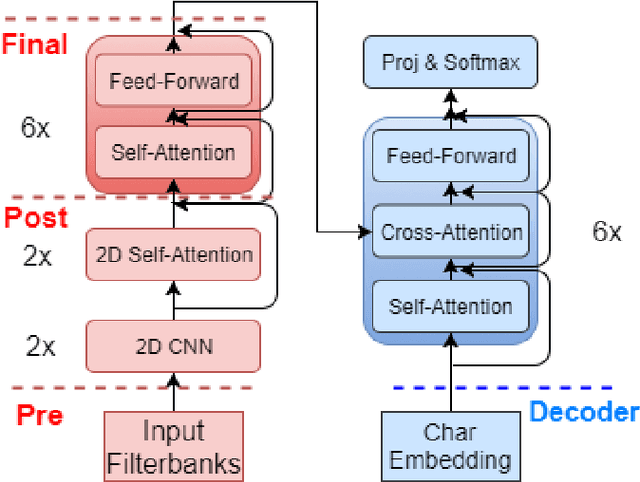
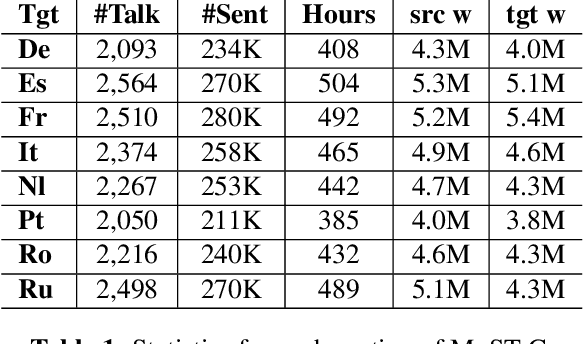
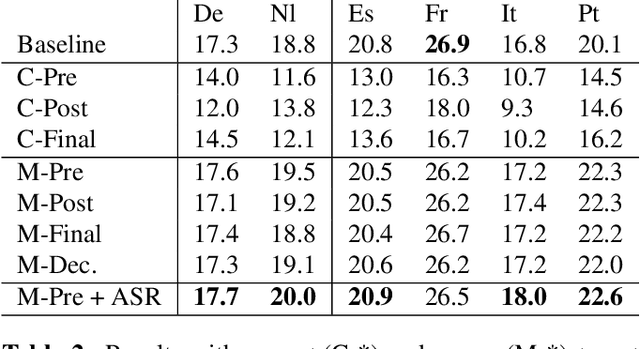
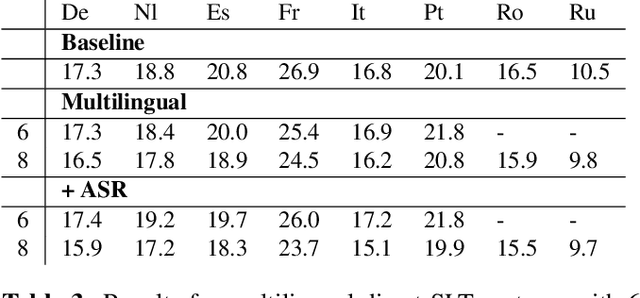
Nowadays, training end-to-end neural models for spoken language translation (SLT) still has to confront with extreme data scarcity conditions. The existing SLT parallel corpora are indeed orders of magnitude smaller than those available for the closely related tasks of automatic speech recognition (ASR) and machine translation (MT), which usually comprise tens of millions of instances. To cope with data paucity, in this paper we explore the effectiveness of transfer learning in end-to-end SLT by presenting a multilingual approach to the task. Multilingual solutions are widely studied in MT and usually rely on ``\textit{target forcing}'', in which multilingual parallel data are combined to train a single model by prepending to the input sequences a language token that specifies the target language. However, when tested in speech translation, our experiments show that MT-like \textit{target forcing}, used as is, is not effective in discriminating among the target languages. Thus, we propose a variant that uses target-language embeddings to shift the input representations in different portions of the space according to the language, so to better support the production of output in the desired target language. Our experiments on end-to-end SLT from English into six languages show important improvements when translating into similar languages, especially when these are supported by scarce data. Further improvements are obtained when using English ASR data as an additional language (up to $+2.5$ BLEU points).
Machine Translation for Machines: the Sentiment Classification Use Case
Oct 01, 2019
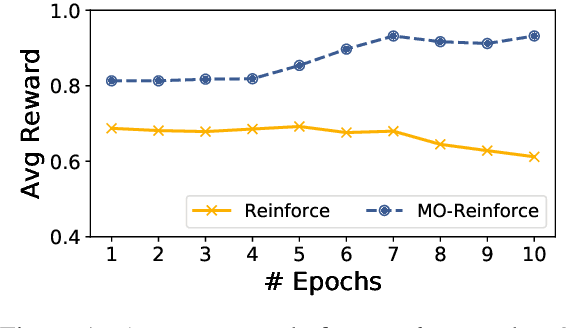
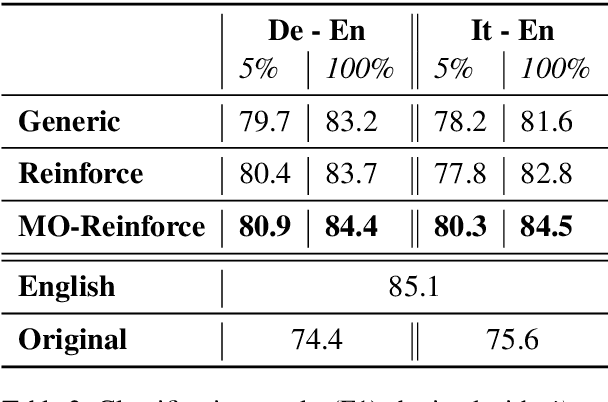
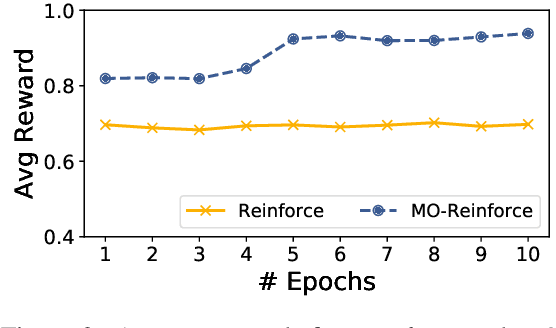
We propose a neural machine translation (NMT) approach that, instead of pursuing adequacy and fluency ("human-oriented" quality criteria), aims to generate translations that are best suited as input to a natural language processing component designed for a specific downstream task (a "machine-oriented" criterion). Towards this objective, we present a reinforcement learning technique based on a new candidate sampling strategy, which exploits the results obtained on the downstream task as weak feedback. Experiments in sentiment classification of Twitter data in German and Italian show that feeding an English classifier with machine-oriented translations significantly improves its performance. Classification results outperform those obtained with translations produced by general-purpose NMT models as well as by an approach based on reinforcement learning. Moreover, our results on both languages approximate the classification accuracy computed on gold standard English tweets.
Multilingual Neural Machine Translation for Zero-Resource Languages
Sep 16, 2019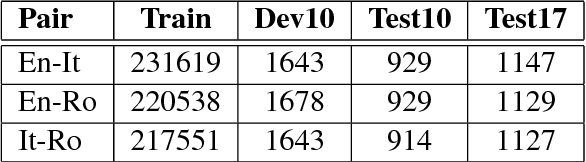
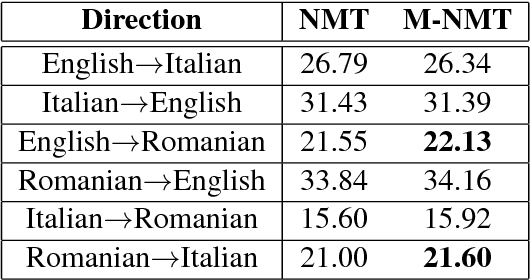
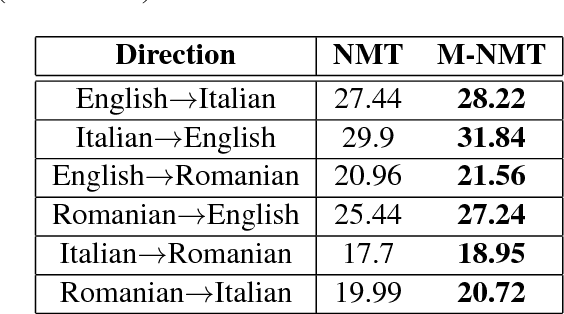
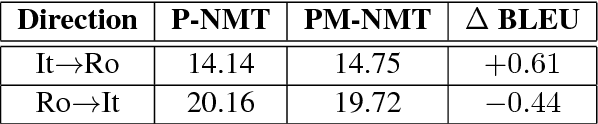
In recent years, Neural Machine Translation (NMT) has been shown to be more effective than phrase-based statistical methods, thus quickly becoming the state of the art in machine translation (MT). However, NMT systems are limited in translating low-resourced languages, due to the significant amount of parallel data that is required to learn useful mappings between languages. In this work, we show how the so-called multilingual NMT can help to tackle the challenges associated with low-resourced language translation. The underlying principle of multilingual NMT is to force the creation of hidden representations of words in a shared semantic space across multiple languages, thus enabling a positive parameter transfer across languages. Along this direction, we present multilingual translation experiments with three languages (English, Italian, Romanian) covering six translation directions, utilizing both recurrent neural networks and transformer (or self-attentive) neural networks. We then focus on the zero-shot translation problem, that is how to leverage multi-lingual data in order to learn translation directions that are not covered by the available training material. To this aim, we introduce our recently proposed iterative self-training method, which incrementally improves a multilingual NMT on a zero-shot direction by just relying on monolingual data. Our results on TED talks data show that multilingual NMT outperforms conventional bilingual NMT, that the transformer NMT outperforms recurrent NMT, and that zero-shot NMT outperforms conventional pivoting methods and even matches the performance of a fully-trained bilingual system.
Improving Zero-Shot Translation of Low-Resource Languages
Nov 04, 2018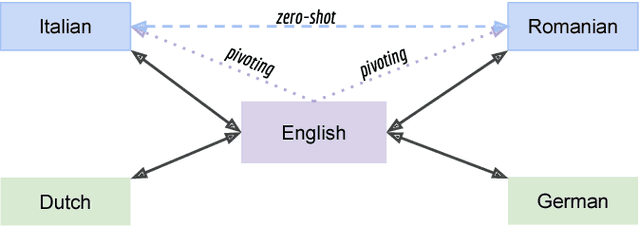

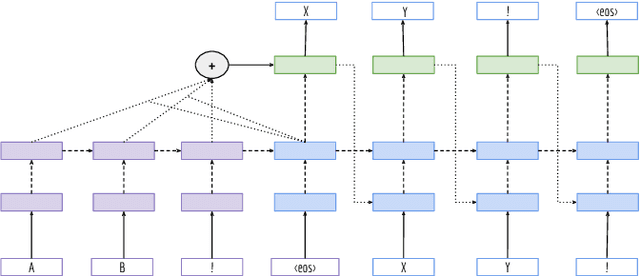
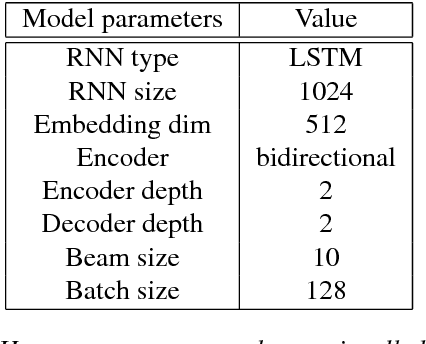
Recent work on multilingual neural machine translation reported competitive performance with respect to bilingual models and surprisingly good performance even on (zeroshot) translation directions not observed at training time. We investigate here a zero-shot translation in a particularly lowresource multilingual setting. We propose a simple iterative training procedure that leverages a duality of translations directly generated by the system for the zero-shot directions. The translations produced by the system (sub-optimal since they contain mixed language from the shared vocabulary), are then used together with the original parallel data to feed and iteratively re-train the multilingual network. Over time, this allows the system to learn from its own generated and increasingly better output. Our approach shows to be effective in improving the two zero-shot directions of our multilingual model. In particular, we observed gains of about 9 BLEU points over a baseline multilingual model and up to 2.08 BLEU over a pivoting mechanism using two bilingual models. Further analysis shows that there is also a slight improvement in the non-zero-shot language directions.