 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning in Multilingual Neural Machine Translation with Dynamic Vocabulary
Nov 03, 2018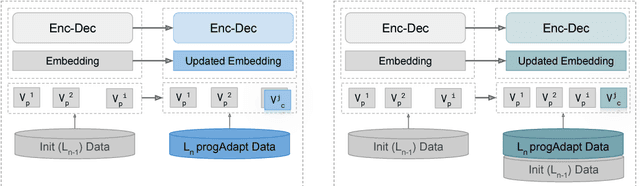
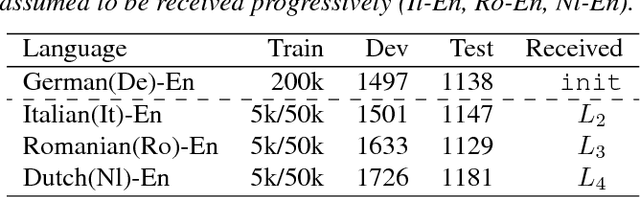
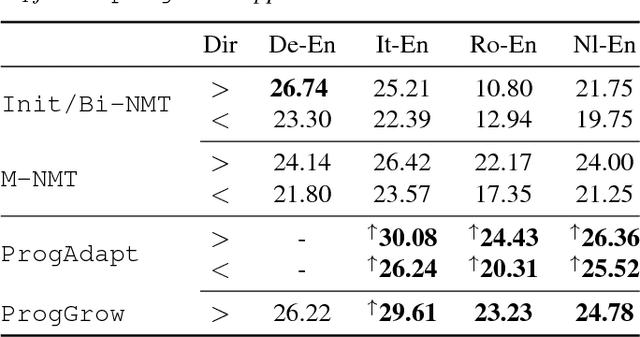
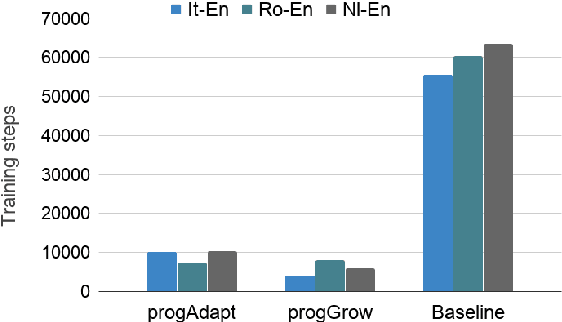
We propose a method to transfer knowledge across neural machine translation (NMT) models by means of a shared dynamic vocabulary. Our approach allows to extend an initial model for a given language pair to cover new languages by adapting its vocabulary as long as new data become available (i.e., introducing new vocabulary items if they are not included in the initial model). The parameter transfer mechanism is evaluated in two scenarios: i) to adapt a trained single language NMT system to work with a new language pair and ii) to continuously add new language pairs to grow to a multilingual NMT system. In both the scenarios our goal is to improve the translation performance, while minimizing the training convergence time. Preliminary experiments spanning five languages with different training data sizes (i.e., 5k and 50k parallel sentences) show a significant performance gain ranging from +3.85 up to +13.63 BLEU in different language directions. Moreover, when compared with training an NMT model from scratch, our transfer-learning approach allows us to reach higher performance after training up to 4% of the total training steps.
Neural Machine Translation into Language Varieties
Nov 02, 2018
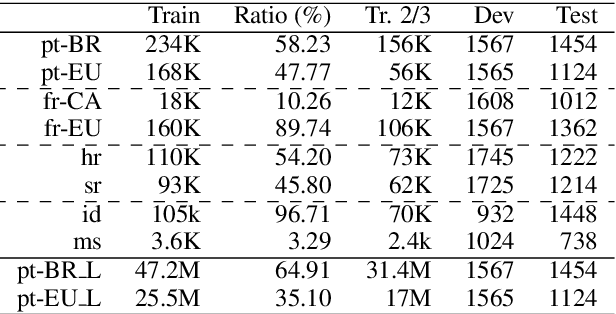

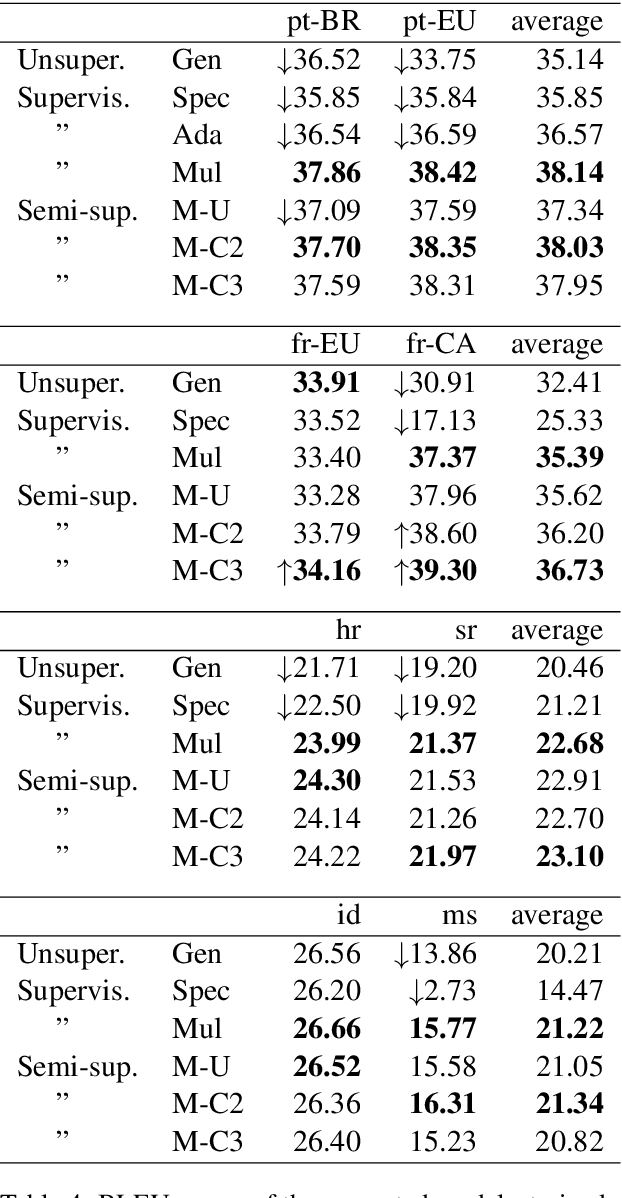
Both research and commercial machine translation have so far neglected the importance of properly handling the spelling, lexical and grammar divergences occurring among language varieties. Notable cases are standard national varieties such as Brazilian and European Portuguese, and Canadian and European French, which popular online machine translation services are not keeping distinct. We show that an evident side effect of modeling such varieties as unique classes is the generation of inconsistent translations. In this work, we investigate the problem of training neural machine translation from English to specific pairs of language varieties, assuming both labeled and unlabeled parallel texts, and low-resource conditions. We report experiments from English to two pairs of dialects, EuropeanBrazilian Portuguese and European-Canadian French, and two pairs of standardized varieties, Croatian-Serbian and Indonesian-Malay. We show significant BLEU score improvements over baseline systems when translation into similar languages is learned as a multilingual task with shared representations.
A Comparison of Transformer and Recurrent Neural Networks on Multilingual Neural Machine Translation
Jun 20, 2018

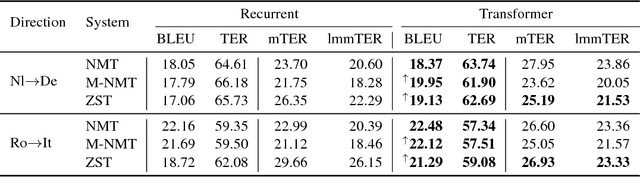
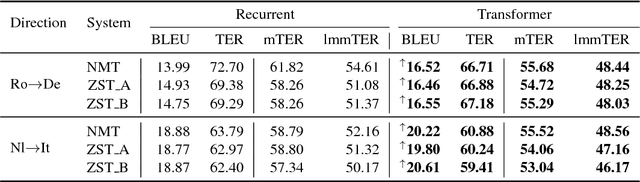
Recently, neural machine translation (NMT) has been extended to multilinguality, that is to handle more than one translation direction with a single system. Multilingual NMT showed competitive performance against pure bilingual systems. Notably, in low-resource settings, it proved to work effectively and efficiently, thanks to shared representation space that is forced across languages and induces a sort of transfer-learning. Furthermore, multilingual NMT enables so-called zero-shot inference across language pairs never seen at training time. Despite the increasing interest in this framework, an in-depth analysis of what a multilingual NMT model is capable of and what it is not is still missing. Motivated by this, our work (i) provides a quantitative and comparative analysis of the translations produced by bilingual, multilingual and zero-shot systems; (ii) investigates the translation quality of two of the currently dominant neural architectures in MT, which are the Recurrent and the Transformer ones; and (iii) quantitatively explores how the closeness between languages influences the zero-shot translation. Our analysis leverages multiple professional post-edits of automatic translations by several different systems and focuses both on automatic standard metrics (BLEU and TER) and on widely used error categories, which are lexical, morphology, and word order errors.
Deep Neural Machine Translation with Weakly-Recurrent Units
May 10, 2018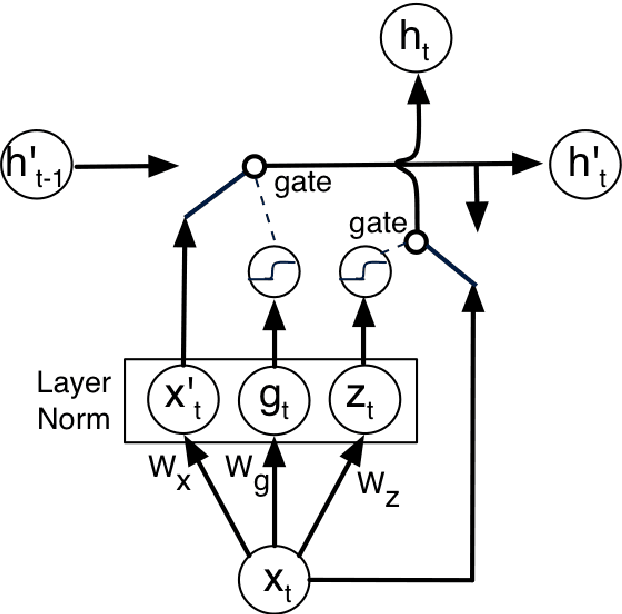
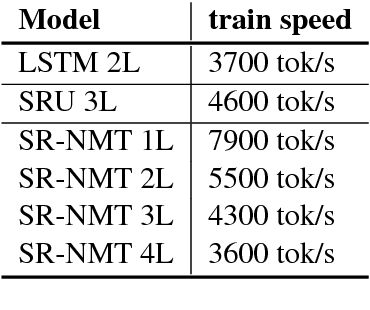
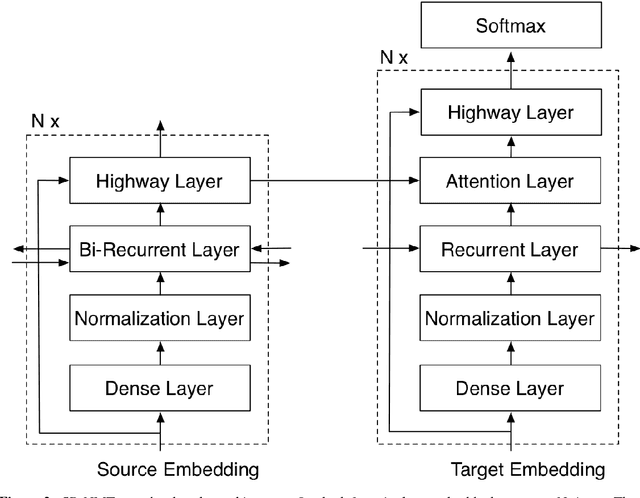
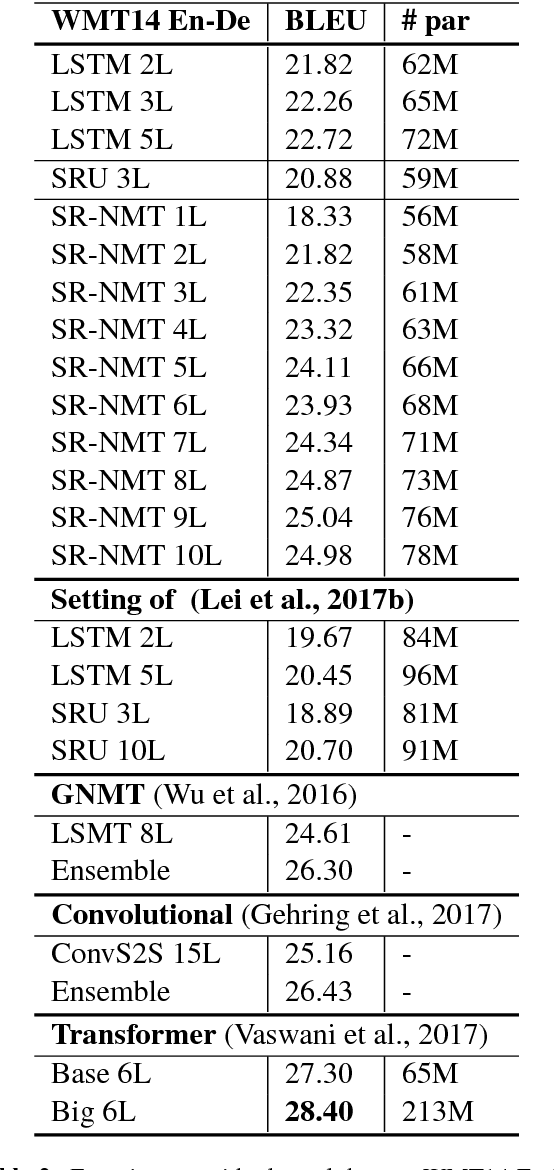
Recurrent neural networks (RNNs) have represented for years the state of the art in neural machine translation. Recently, new architectures have been proposed, which can leverage parallel computation on GPUs better than classical RNNs. Faster training and inference combined with different sequence-to-sequence modeling also lead to performance improvements. While the new models completely depart from the original recurrent architecture, we decided to investigate how to make RNNs more efficient. In this work, we propose a new recurrent NMT architecture, called Simple Recurrent NMT, built on a class of fast and weakly-recurrent units that use layer normalization and multiple attentions. Our experiments on the WMT14 English-to-German and WMT16 English-Romanian benchmarks show that our model represents a valid alternative to LSTMs, as it can achieve better results at a significantly lower computational cost.
Compositional Representation of Morphologically-Rich Input for Neural Machine Translation
May 05, 2018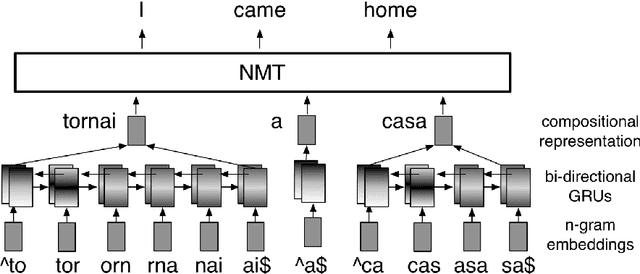
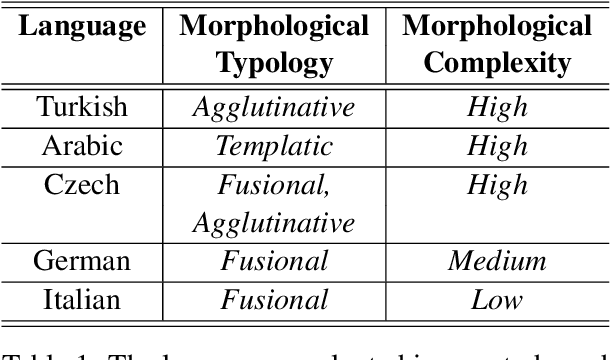
Neural machine translation (NMT) models are typically trained with fixed-size input and output vocabularies, which creates an important bottleneck on their accuracy and generalization capability. As a solution, various studies proposed segmenting words into sub-word units and performing translation at the sub-lexical level. However, statistical word segmentation methods have recently shown to be prone to morphological errors, which can lead to inaccurate translations. In this paper, we propose to overcome this problem by replacing the source-language embedding layer of NMT with a bi-directional recurrent neural network that generates compositional representations of the input at any desired level of granularity. We test our approach in a low-resource setting with five languages from different morphological typologies, and under different composition assumptions. By training NMT to compose word representations from character n-grams, our approach consistently outperforms (from 1.71 to 2.48 BLEU points) NMT learning embeddings of statistically generated sub-word units.
Linguistically Motivated Vocabulary Reduction for Neural Machine Translation from Turkish to English
Jul 31, 2017
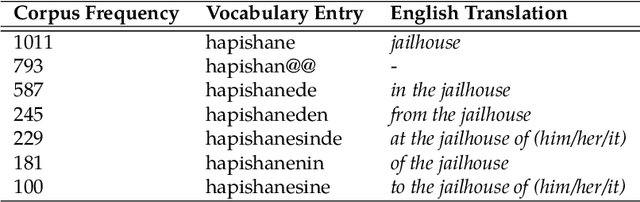


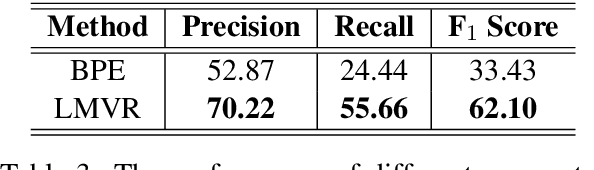
The necessity of using a fixed-size word vocabulary in order to control the model complexity in state-of-the-art neural machine translation (NMT) systems is an important bottleneck on performance, especially for morphologically rich languages. Conventional methods that aim to overcome this problem by using sub-word or character-level representations solely rely on statistics and disregard the linguistic properties of words, which leads to interruptions in the word structure and causes semantic and syntactic losses. In this paper, we propose a new vocabulary reduction method for NMT, which can reduce the vocabulary of a given input corpus at any rate while also considering the morphological properties of the language. Our method is based on unsupervised morphology learning and can be, in principle, used for pre-processing any language pair. We also present an alternative word segmentation method based on supervised morphological analysis, which aids us in measuring the accuracy of our model. We evaluate our method in Turkish-to-English NMT task where the input language is morphologically rich and agglutinative. We analyze different representation methods in terms of translation accuracy as well as the semantic and syntactic properties of the generated output. Our method obtains a significant improvement of 2.3 BLEU points over the conventional vocabulary reduction technique, showing that it can provide better accuracy in open vocabulary translation of morphologically rich languages.
* The 20th Annual Conference of the European Association for Machine Translation (EAMT), Research Paper, 12 pages
Neural versus Phrase-Based Machine Translation Quality: a Case Study
Oct 09, 2016
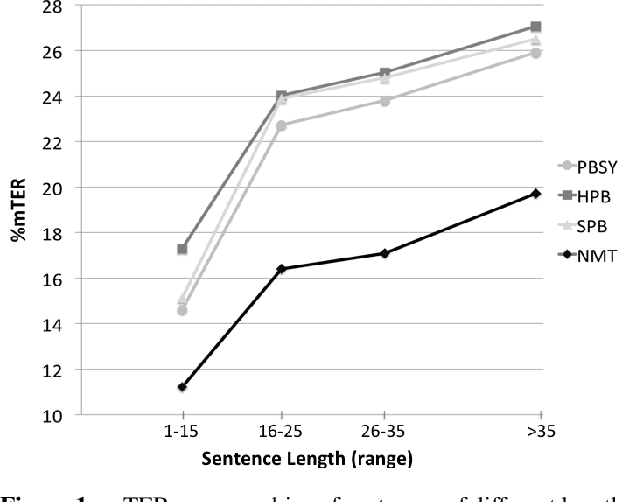
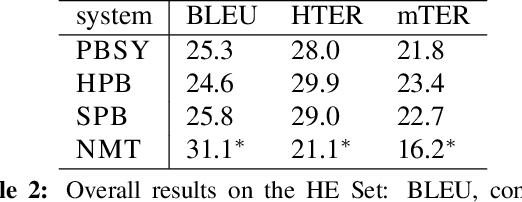
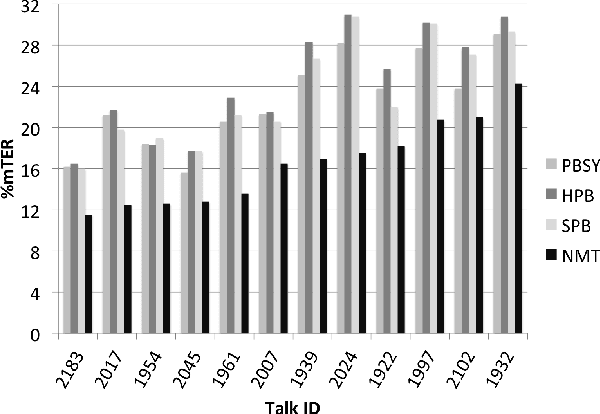
Within the field of Statistical Machine Translation (SMT), the neural approach (NMT) has recently emerged as the first technology able to challenge the long-standing dominance of phrase-based approaches (PBMT). In particular, at the IWSLT 2015 evaluation campaign, NMT outperformed well established state-of-the-art PBMT systems on English-German, a language pair known to be particularly hard because of morphology and syntactic differences. To understand in what respects NMT provides better translation quality than PBMT, we perform a detailed analysis of neural versus phrase-based SMT outputs, leveraging high quality post-edits performed by professional translators on the IWSLT data. For the first time, our analysis provides useful insights on what linguistic phenomena are best modeled by neural models -- such as the reordering of verbs -- while pointing out other aspects that remain to be improved.
A Survey of Word Reordering in Statistical Machine Translation: Computational Models and Language Phenomena
Mar 14, 2016Word reordering is one of the most difficult aspects of statistical machine translation (SMT), and an important factor of its quality and efficiency. Despite the vast amount of research published to date, the interest of the community in this problem has not decreased, and no single method appears to be strongly dominant across language pairs. Instead, the choice of the optimal approach for a new translation task still seems to be mostly driven by empirical trials. To orientate the reader in this vast and complex research area, we present a comprehensive survey of word reordering viewed as a statistical modeling challenge and as a natural language phenomenon. The survey describes in detail how word reordering is modeled within different string-based and tree-based SMT frameworks and as a stand-alone task, including systematic overviews of the literature in advanced reordering modeling. We then question why some approaches are more successful than others in different language pairs. We argue that, besides measuring the amount of reordering, it is important to understand which kinds of reordering occur in a given language pair. To this end, we conduct a qualitative analysis of word reordering phenomena in a diverse sample of language pairs, based on a large collection of linguistic knowledge. Empirical results in the SMT literature are shown to support the hypothesis that a few linguistic facts can be very useful to anticipate the reordering characteristics of a language pair and to select the SMT framework that best suits them.
* 44 pages, to appear in Computational Linguistics