 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubmodular Kernels for Efficient Rankings
May 26, 2021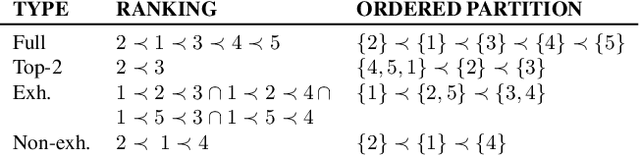
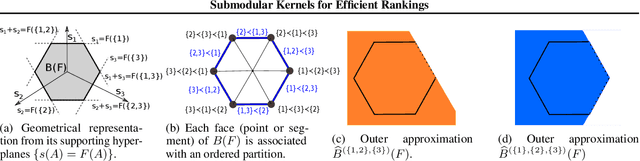
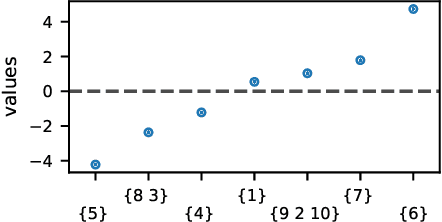
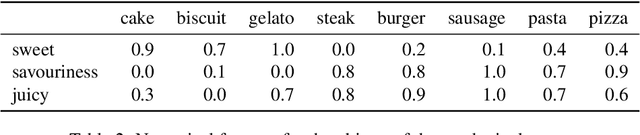
Many algorithms for ranked data become computationally intractable as the number of objects grows due to complex geometric structure induced by rankings. An additional challenge is posed by partial rankings, i.e. rankings in which the preference is only known for a subset of all objects. For these reasons, state-of-the-art methods cannot scale to real-world applications, such as recommender systems. We address this challenge by exploiting geometric structure of ranked data and additional available information about the objects to derive a submodular kernel for ranking. The submodular kernel combines the efficiency of submodular optimization with the theoretical properties of kernel-based methods. We demonstrate that the submodular kernel drastically reduces the computational cost compared to state-of-the-art kernels and scales well to large datasets while attaining good empirical performance.
Learning Contact Dynamics using Physically Structured Neural Networks
Feb 22, 2021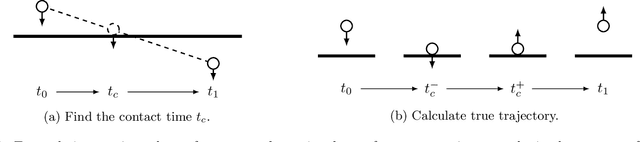

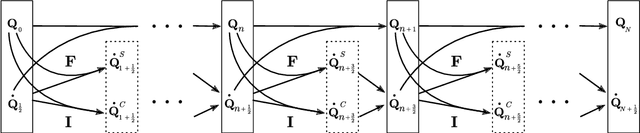

Learning physically structured representations of dynamical systems that include contact between different objects is an important problem for learning-based approaches in robotics. Black-box neural networks can learn to approximately represent discontinuous dynamics, but they typically require large quantities of data and often suffer from pathological behaviour when forecasting for longer time horizons. In this work, we use connections between deep neural networks and differential equations to design a family of deep network architectures for representing contact dynamics between objects. We show that these networks can learn discontinuous contact events in a data-efficient manner from noisy observations in settings that are traditionally difficult for black-box approaches and recent physics inspired neural networks. Our results indicate that an idealised form of touch feedback -- which is heavily relied upon by biological systems -- is a key component of making this learning problem tractable. Together with the inductive biases introduced through the network architectures, our techniques enable accurate learning of contact dynamics from observations.
Sliced Multi-Marginal Optimal Transport
Feb 14, 2021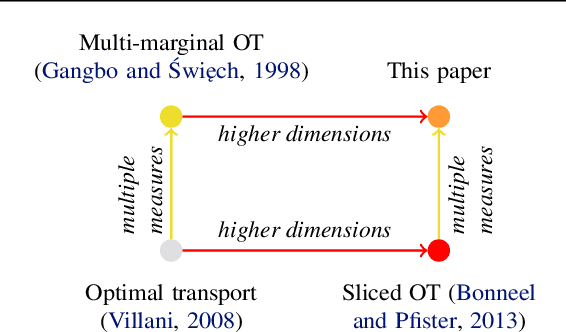
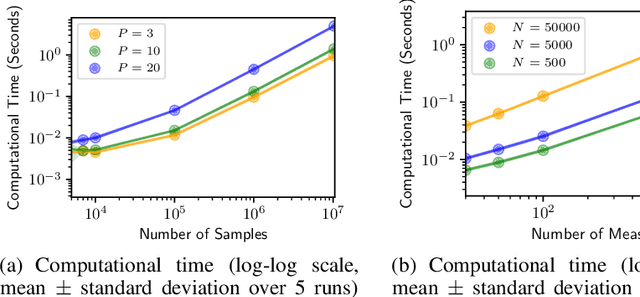
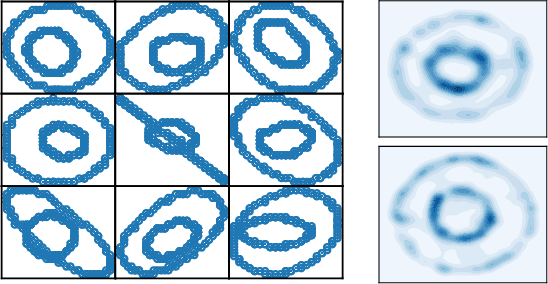
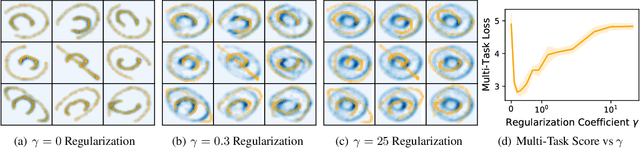
We study multi-marginal optimal transport, a generalization of optimal transport that allows us to define discrepancies between multiple measures. It provides a framework to solve multi-task learning problems and to perform barycentric averaging. However, multi-marginal distances between multiple measures are typically challenging to compute because they require estimating a transport plan with $N^P$ variables. In this paper, we address this issue in the following way: 1) we efficiently solve the one-dimensional multi-marginal Monge-Wasserstein problem for a classical cost function in closed form, and 2) we propose a higher-dimensional multi-marginal discrepancy via slicing and study its generalized metric properties. We show that computing the sliced multi-marginal discrepancy is massively scalable for a large number of probability measures with support as large as $10^7$ samples. Our approach can be applied to solving problems such as barycentric averaging, multi-task density estimation and multi-task reinforcement learning.
Healing Products of Gaussian Processes
Feb 14, 2021

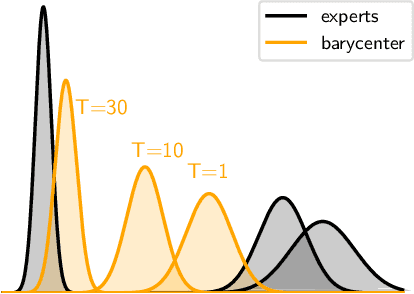
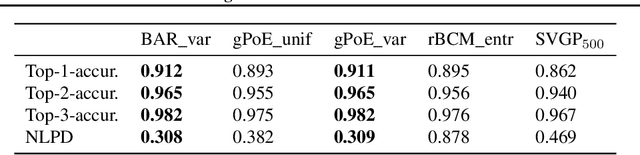
Gaussian processes (GPs) are nonparametric Bayesian models that have been applied to regression and classification problems. One of the approaches to alleviate their cubic training cost is the use of local GP experts trained on subsets of the data. In particular, product-of-expert models combine the predictive distributions of local experts through a tractable product operation. While these expert models allow for massively distributed computation, their predictions typically suffer from erratic behaviour of the mean or uncalibrated uncertainty quantification. By calibrating predictions via a tempered softmax weighting, we provide a solution to these problems for multiple product-of-expert models, including the generalised product of experts and the robust Bayesian committee machine. Furthermore, we leverage the optimal transport literature and propose a new product-of-expert model that combines predictions of local experts by computing their Wasserstein barycenter, which can be applied to both regression and classification.
Cauchy-Schwarz Regularized Autoencoder
Feb 12, 2021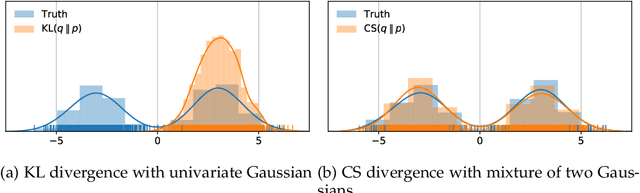
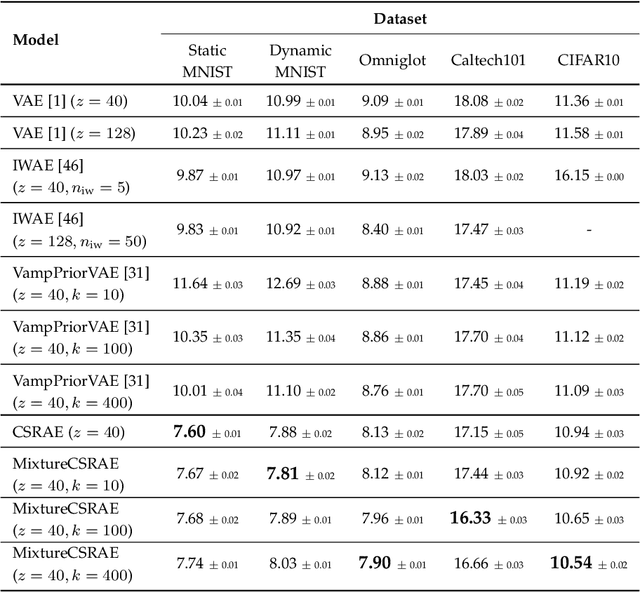
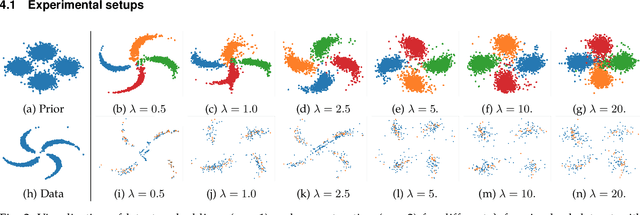
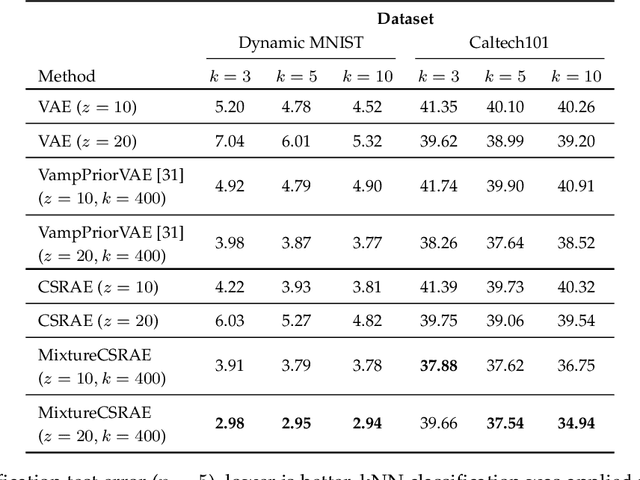
Recent work in unsupervised learning has focused on efficient inference and learning in latent variables models. Training these models by maximizing the evidence (marginal likelihood) is typically intractable. Thus, a common approximation is to maximize the Evidence Lower BOund (ELBO) instead. Variational autoencoders (VAE) are a powerful and widely-used class of generative models that optimize the ELBO efficiently for large datasets. However, the VAE's default Gaussian choice for the prior imposes a strong constraint on its ability to represent the true posterior, thereby degrading overall performance. A Gaussian mixture model (GMM) would be a richer prior, but cannot be handled efficiently within the VAE framework because of the intractability of the Kullback-Leibler divergence for GMMs. We deviate from the common VAE framework in favor of one with an analytical solution for Gaussian mixture prior. To perform efficient inference for GMM priors, we introduce a new constrained objective based on the Cauchy-Schwarz divergence, which can be computed analytically for GMMs. This new objective allows us to incorporate richer, multi-modal priors into the autoencoding framework. We provide empirical studies on a range of datasets and show that our objective improves upon variational auto-encoding models in density estimation, unsupervised clustering, semi-supervised learning, and face analysis.
Design of Dynamic Experiments for Black-Box Model Discrimination
Feb 07, 2021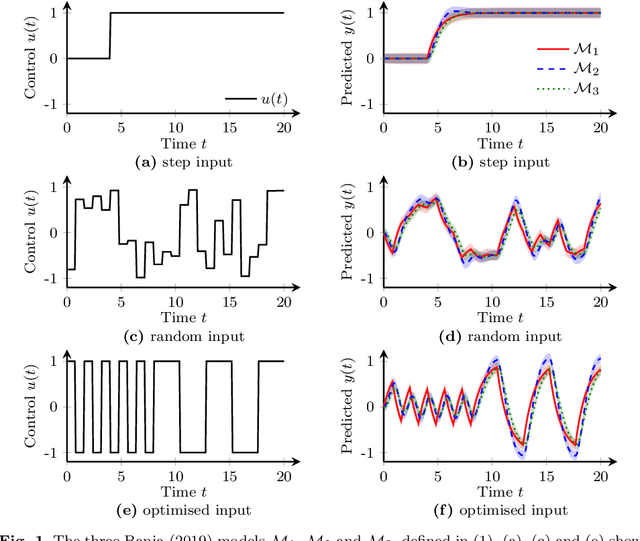
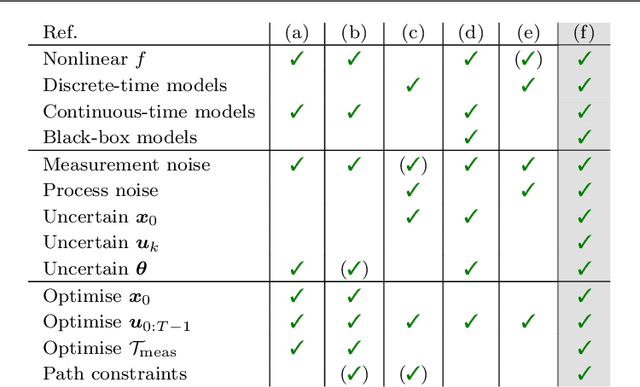
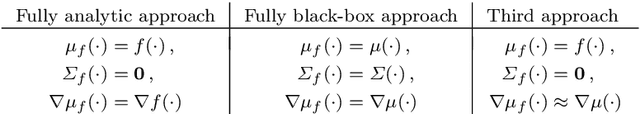
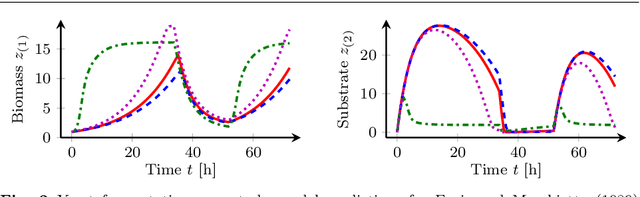
Diverse domains of science and engineering require and use mechanistic mathematical models, e.g. systems of differential algebraic equations. Such models often contain uncertain parameters to be estimated from data. Consider a dynamic model discrimination setting where we wish to chose: (i) what is the best mechanistic, time-varying model and (ii) what are the best model parameter estimates. These tasks are often termed model discrimination/selection/validation/verification. Typically, several rival mechanistic models can explain data, so we incorporate available data and also run new experiments to gather more data. Design of dynamic experiments for model discrimination helps optimally collect data. For rival mechanistic models where we have access to gradient information, we extend existing methods to incorporate a wider range of problem uncertainty and show that our proposed approach is equivalent to historical approaches when limiting the types of considered uncertainty. We also consider rival mechanistic models as dynamic black boxes that we can evaluate, e.g. by running legacy code, but where gradient or other advanced information is unavailable. We replace these black-box models with Gaussian process surrogate models and thereby extend the model discrimination setting to additionally incorporate rival black-box model. We also explore the consequences of using Gaussian process surrogates to approximate gradient-based methods.
GENNI: Visualising the Geometry of Equivalences for Neural Network Identifiability
Nov 14, 2020We propose an efficient algorithm to visualise symmetries in neural networks. Typically, models are defined with respect to a parameter space, where non-equal parameters can produce the same input-output map. Our proposed method, GENNI, allows us to efficiently identify parameters that are functionally equivalent and then visualise the subspace of the resulting equivalence class. By doing so, we are now able to better explore questions surrounding identifiability, with applications to optimisation and generalizability, for commonly used or newly developed neural network architectures.
Pathwise Conditioning of Gaussian Processes
Nov 08, 2020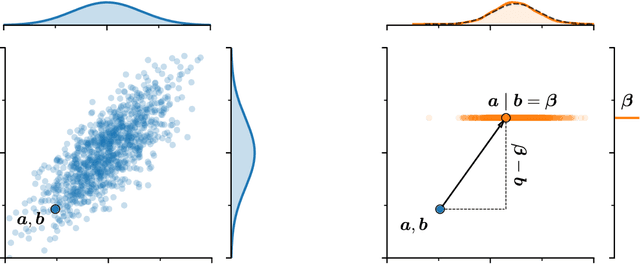
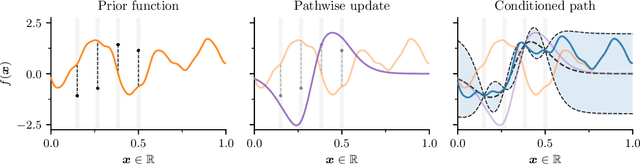
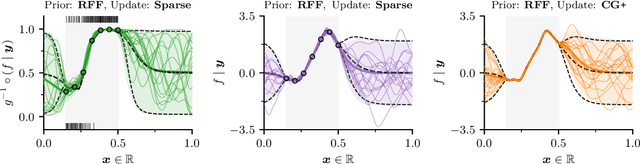
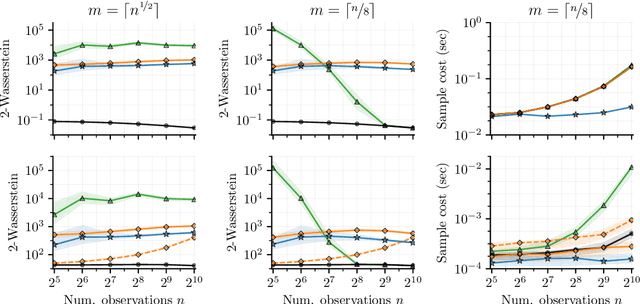
As Gaussian processes are integrated into increasingly complex problem settings, analytic solutions to quantities of interest become scarcer and scarcer. Monte Carlo methods act as a convenient bridge for connecting intractable mathematical expressions with actionable estimates via sampling. Conventional approaches for simulating Gaussian process posteriors view samples as vectors drawn from marginal distributions over process values at a finite number of input location. This distribution-based characterization leads to generative strategies that scale cubically in the size of the desired random vector. These methods are, therefore, prohibitively expensive in cases where high-dimensional vectors - let alone continuous functions - are required. In this work, we investigate a different line of reasoning. Rather than focusing on distributions, we articulate Gaussian conditionals at the level of random variables. We show how this pathwise interpretation of conditioning gives rise to a general family of approximations that lend themselves to fast sampling from Gaussian process posteriors. We analyze these methods, along with the approximation errors they introduce, from first principles. We then complement this theory, by exploring the practical ramifications of pathwise conditioning in a various applied settings.
Matern Gaussian Processes on Graphs
Oct 29, 2020
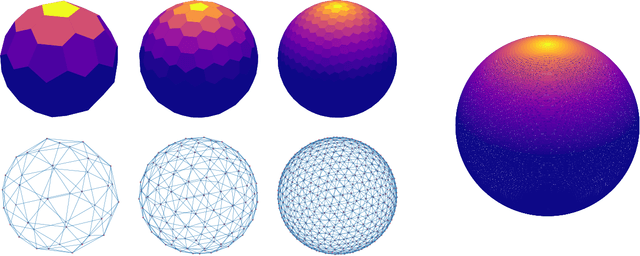
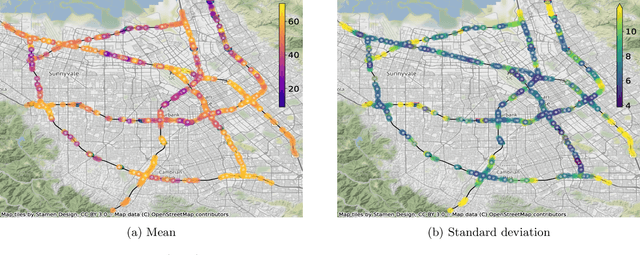
Gaussian processes are a versatile framework for learning unknown functions in a manner that permits one to utilize prior information about their properties. Although many different Gaussian process models are readily available when the input space is Euclidean, the choice is much more limited for Gaussian processes whose input space is an undirected graph. In this work, we leverage the stochastic partial differential equation characterization of Mat\'{e}rn Gaussian processes - a widely-used model class in the Euclidean setting - to study their analog for undirected graphs. We show that the resulting Gaussian processes inherit various attractive properties of their Euclidean and Riemannian analogs and provide techniques that allow them to be trained using standard methods, such as inducing points. This enables graph Mat\'{e}rn Gaussian processes to be employed in mini-batch and non-conjugate settings, thereby making them more accessible to practitioners and easier to deploy within larger learning frameworks.
A Foliated View of Transfer Learning
Aug 02, 2020
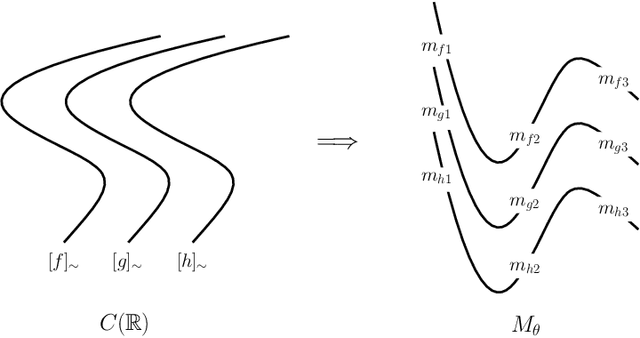
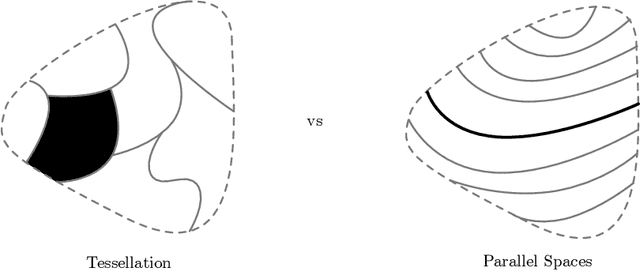
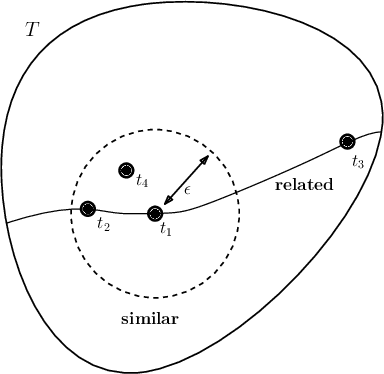
Transfer learning considers a learning process where a new task is solved by transferring relevant knowledge from known solutions to related tasks. While this has been studied experimentally, there lacks a foundational description of the transfer learning problem that exposes what related tasks are, and how they can be exploited. In this work, we present a definition for relatedness between tasks and identify foliations as a mathematical framework to represent such relationships.