 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-GUI Technical Report
Dec 19, 2025



Recent advances in multimodal large language models unlock unprecedented opportunities for GUI automation. However, a fundamental challenge remains: how to efficiently acquire high-quality training data while maintaining annotation reliability? We introduce a self-evolving training pipeline powered by the Calibrated Step Reward System, which converts model-generated trajectories into reliable training signals through trajectory-level calibration, achieving >90% annotation accuracy with 10-100x lower cost. Leveraging this pipeline, we introduce Step-GUI, a family of models (4B/8B) that achieves state-of-the-art GUI performance (8B: 80.2% AndroidWorld, 48.5% OSWorld, 62.6% ScreenShot-Pro) while maintaining robust general capabilities. As GUI agent capabilities improve, practical deployment demands standardized interfaces across heterogeneous devices while protecting user privacy. To this end, we propose GUI-MCP, the first Model Context Protocol for GUI automation with hierarchical architecture that combines low-level atomic operations and high-level task delegation to local specialist models, enabling high-privacy execution where sensitive data stays on-device. Finally, to assess whether agents can handle authentic everyday usage, we introduce AndroidDaily, a benchmark grounded in real-world mobile usage patterns with 3146 static actions and 235 end-to-end tasks across high-frequency daily scenarios (8B: static 89.91%, end-to-end 52.50%). Our work advances the development of practical GUI agents and demonstrates strong potential for real-world deployment in everyday digital interactions.
Branching Strategy Selection Approach Based on Vivification Ratio
Dec 11, 2021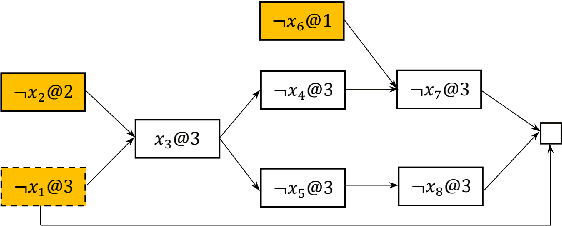

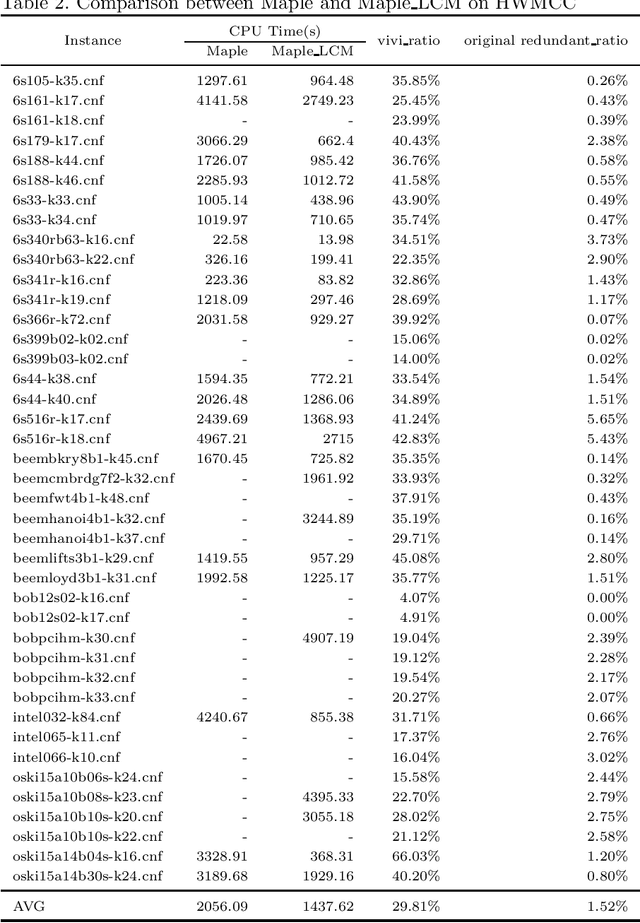
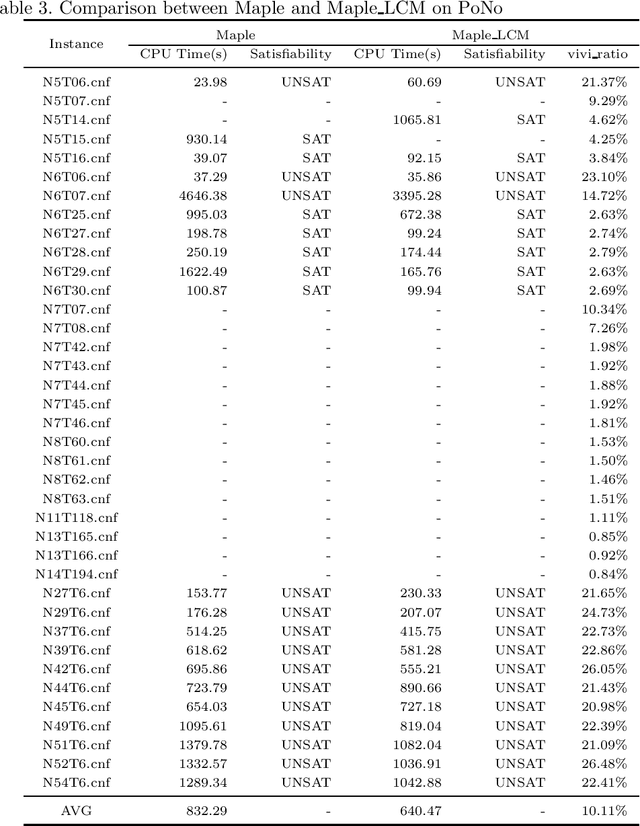
The two most effective branching strategies LRB and VSIDS perform differently on different types of instances. Generally, LRB is more effective on crafted instances, while VSIDS is more effective on application ones. However, distinguishing the types of instances is difficult. To overcome this drawback, we propose a branching strategy selection approach based on the vivification ratio. This approach uses the LRB branching strategy more to solve the instances with a very low vivification ratio. We tested the instances from the main track of SAT competitions in recent years. The results show that the proposed approach is robust and it significantly increases the number of solved instances. It is worth mentioning that, with the help of our approach, the solver Maple\_CM can solve more than 16 instances for the benchmark from the 2020 SAT competition.
Clause Vivification by Unit Propagation in CDCL SAT Solvers
Jul 29, 2018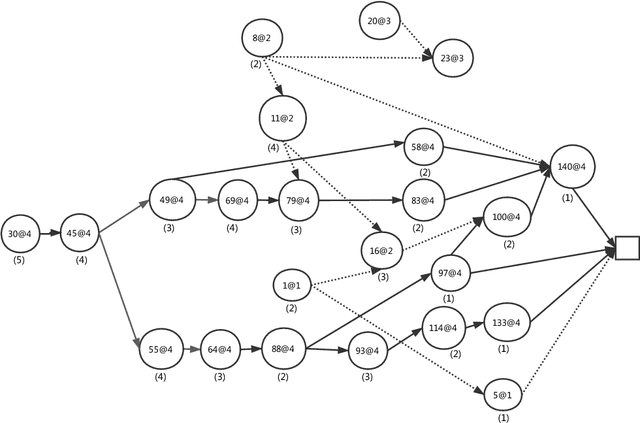
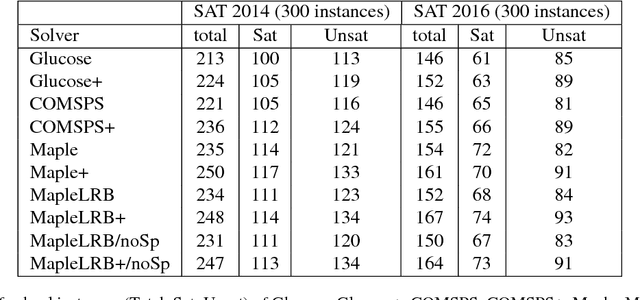
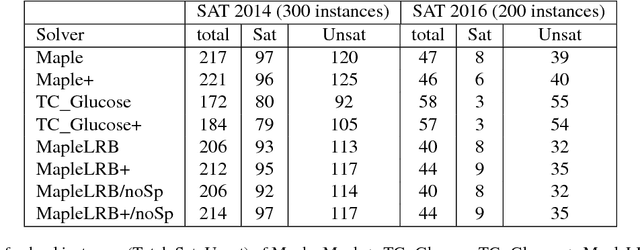
Original and learnt clauses in Conflict-Driven Clause Learning (CDCL) SAT solvers often contain redundant literals. This may have a negative impact on performance because redundant literals may deteriorate both the effectiveness of Boolean constraint propagation and the quality of subsequent learnt clauses. To overcome this drawback, we propose a clause vivification approach that eliminates redundant literals by applying unit propagation. The proposed clause vivification is activated before the SAT solver triggers some selected restarts, and only affects a subset of original and learnt clauses, which are considered to be more relevant according to metrics like the literal block distance (LBD). Moreover, we conducted an empirical investigation with instances coming from the hard combinatorial and application categories of recent SAT competitions. The results show that a remarkable number of additional instances are solved when the proposed approach is incorporated into five of the best performing CDCL SAT solvers (Glucose, TC_Glucose, COMiniSatPS, MapleCOMSPS and MapleCOMSPS_LRB). More importantly, the empirical investigation includes an in-depth analysis of the effectiveness of clause vivification. It is worth mentioning that one of the SAT solvers described here was ranked first in the main track of SAT Competition 2017 thanks to the incorporation of the proposed clause vivification. That solver was further improved in this paper and won the bronze medal in the main track of SAT Competition 2018.