 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinancial Time Series Forecasting using CNN and Transformer
Apr 11, 2023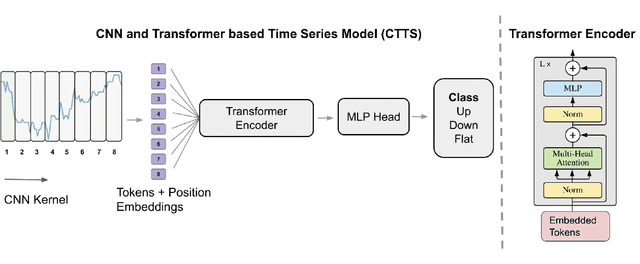
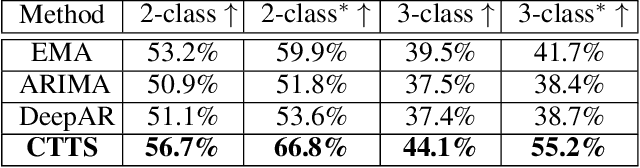
Time series forecasting is important across various domains for decision-making. In particular, financial time series such as stock prices can be hard to predict as it is difficult to model short-term and long-term temporal dependencies between data points. Convolutional Neural Networks (CNN) are good at capturing local patterns for modeling short-term dependencies. However, CNNs cannot learn long-term dependencies due to the limited receptive field. Transformers on the other hand are capable of learning global context and long-term dependencies. In this paper, we propose to harness the power of CNNs and Transformers to model both short-term and long-term dependencies within a time series, and forecast if the price would go up, down or remain the same (flat) in the future. In our experiments, we demonstrated the success of the proposed method in comparison to commonly adopted statistical and deep learning methods on forecasting intraday stock price change of S&P 500 constituents.
Fast Learning of Multidimensional Hawkes Processes via Frank-Wolfe
Dec 12, 2022



Hawkes processes have recently risen to the forefront of tools when it comes to modeling and generating sequential events data. Multidimensional Hawkes processes model both the self and cross-excitation between different types of events and have been applied successfully in various domain such as finance, epidemiology and personalized recommendations, among others. In this work we present an adaptation of the Frank-Wolfe algorithm for learning multidimensional Hawkes processes. Experimental results show that our approach has better or on par accuracy in terms of parameter estimation than other first order methods, while enjoying a significantly faster runtime.
Learn to explain yourself, when you can: Equipping Concept Bottleneck Models with the ability to abstain on their concept predictions
Nov 21, 2022



The Concept Bottleneck Models (CBMs) of Koh et al. [2020] provide a means to ensure that a neural network based classifier bases its predictions solely on human understandable concepts. The concept labels, or rationales as we refer to them, are learned by the concept labeling component of the CBM. Another component learns to predict the target classification label from these predicted concept labels. Unfortunately, these models are heavily reliant on human provided concept labels for each datapoint. To enable CBMs to behave robustly when these labels are not readily available, we show how to equip them with the ability to abstain from predicting concepts when the concept labeling component is uncertain. In other words, our model learns to provide rationales for its predictions, but only whenever it is sure the rationale is correct.
Towards learning to explain with concept bottleneck models: mitigating information leakage
Nov 07, 2022

Concept bottleneck models perform classification by first predicting which of a list of human provided concepts are true about a datapoint. Then a downstream model uses these predicted concept labels to predict the target label. The predicted concepts act as a rationale for the target prediction. Model trust issues emerge in this paradigm when soft concept labels are used: it has previously been observed that extra information about the data distribution leaks into the concept predictions. In this work we show how Monte-Carlo Dropout can be used to attain soft concept predictions that do not contain leaked information.
Towards Multi-Agent Reinforcement Learning driven Over-The-Counter Market Simulations
Oct 13, 2022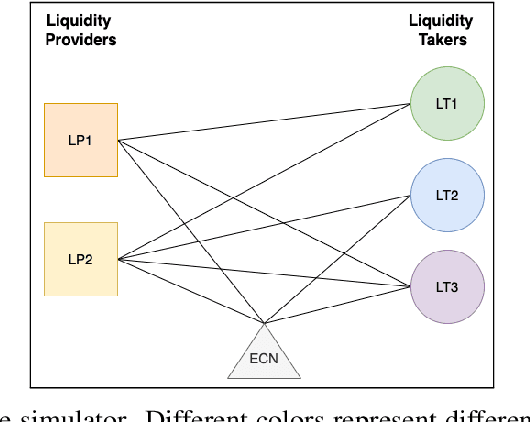

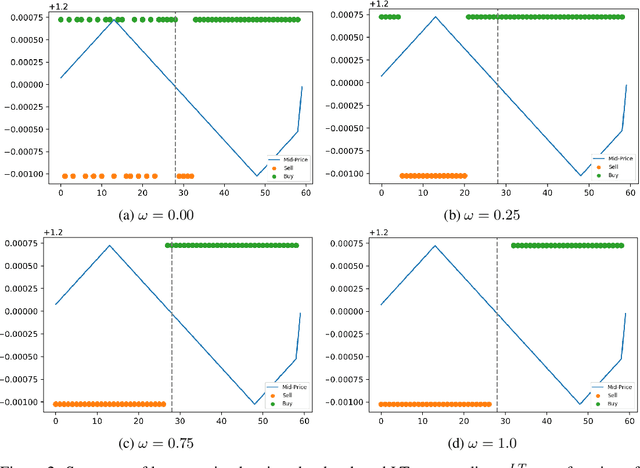

We study a game between liquidity provider and liquidity taker agents interacting in an over-the-counter market, for which the typical example is foreign exchange. We show how a suitable design of parameterized families of reward functions coupled with associated shared policy learning constitutes an efficient solution to this problem. Precisely, we show that our deep-reinforcement-learning-driven agents learn emergent behaviors relative to a wide spectrum of incentives encompassing profit-and-loss, optimal execution and market share, by playing against each other. In particular, we find that liquidity providers naturally learn to balance hedging and skewing as a function of their incentives, where the latter refers to setting their buy and sell prices asymmetrically as a function of their inventory. We further introduce a novel RL-based calibration algorithm which we found performed well at imposing constraints on the game equilibrium, both on toy and real market data.
ASPiRe:Adaptive Skill Priors for Reinforcement Learning
Sep 30, 2022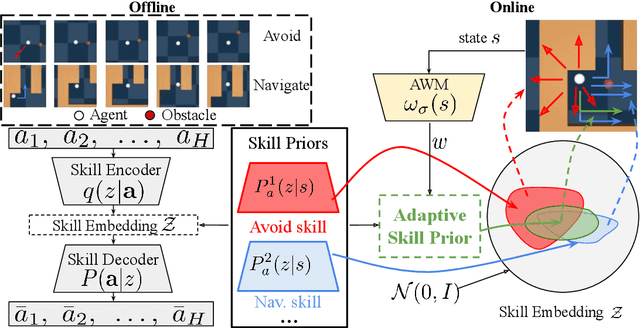
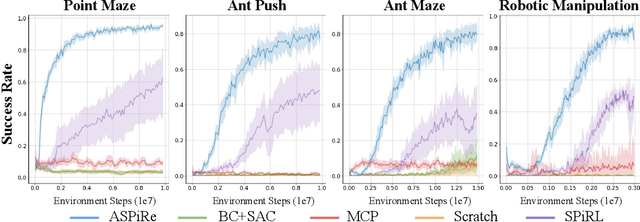
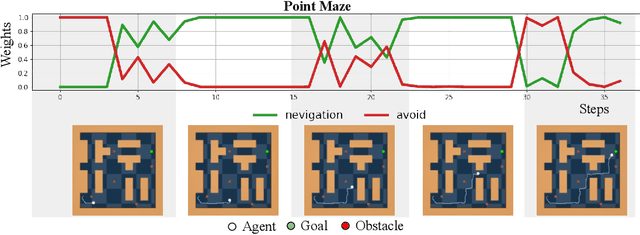
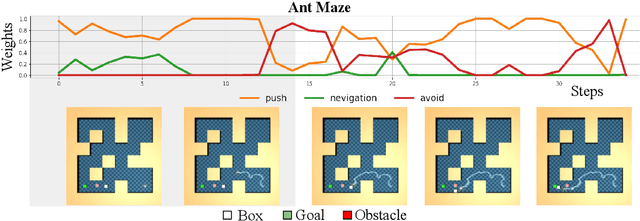
We introduce ASPiRe (Adaptive Skill Prior for RL), a new approach that leverages prior experience to accelerate reinforcement learning. Unlike existing methods that learn a single skill prior from a large and diverse dataset, our framework learns a library of different distinction skill priors (i.e., behavior priors) from a collection of specialized datasets, and learns how to combine them to solve a new task. This formulation allows the algorithm to acquire a set of specialized skill priors that are more reusable for downstream tasks; however, it also brings up additional challenges of how to effectively combine these unstructured sets of skill priors to form a new prior for new tasks. Specifically, it requires the agent not only to identify which skill prior(s) to use but also how to combine them (either sequentially or concurrently) to form a new prior. To achieve this goal, ASPiRe includes Adaptive Weight Module (AWM) that learns to infer an adaptive weight assignment between different skill priors and uses them to guide policy learning for downstream tasks via weighted Kullback-Leibler divergences. Our experiments demonstrate that ASPiRe can significantly accelerate the learning of new downstream tasks in the presence of multiple priors and show improvement on competitive baselines.
Online Learning for Mixture of Multivariate Hawkes Processes
Aug 16, 2022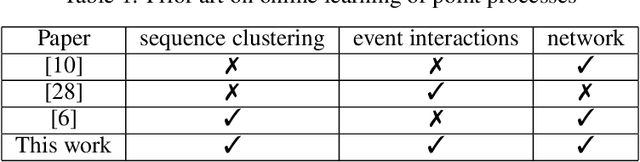
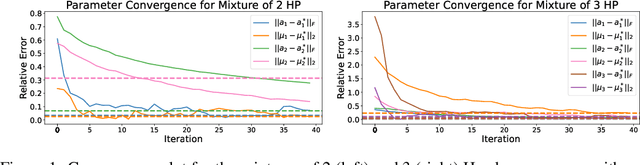
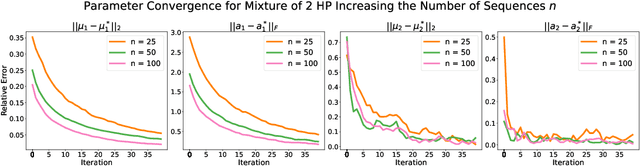

Online learning of Hawkes processes has received increasing attention in the last couple of years especially for modeling a network of actors. However, these works typically either model the rich interaction between the events or the latent cluster of the actors or the network structure between the actors. We propose to model the latent structure of the network of actors as well as their rich interaction across events for real-world settings of medical and financial applications. Experimental results on both synthetic and real-world data showcase the efficacy of our approach.
Differentially Private Learning of Hawkes Processes
Jul 27, 2022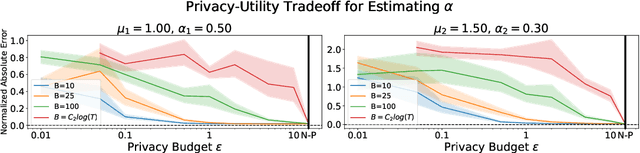
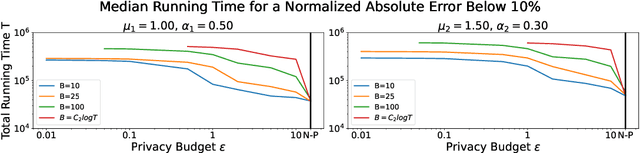
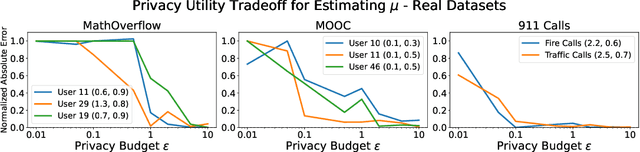
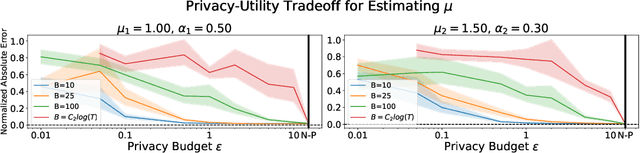
Hawkes processes have recently gained increasing attention from the machine learning community for their versatility in modeling event sequence data. While they have a rich history going back decades, some of their properties, such as sample complexity for learning the parameters and releasing differentially private versions, are yet to be thoroughly analyzed. In this work, we study standard Hawkes processes with background intensity $\mu$ and excitation function $\alpha e^{-\beta t}$. We provide both non-private and differentially private estimators of $\mu$ and $\alpha$, and obtain sample complexity results in both settings to quantify the cost of privacy. Our analysis exploits the strong mixing property of Hawkes processes and classical central limit theorem results for weakly dependent random variables. We validate our theoretical findings on both synthetic and real datasets.
A Survey of Explainable Reinforcement Learning
Feb 17, 2022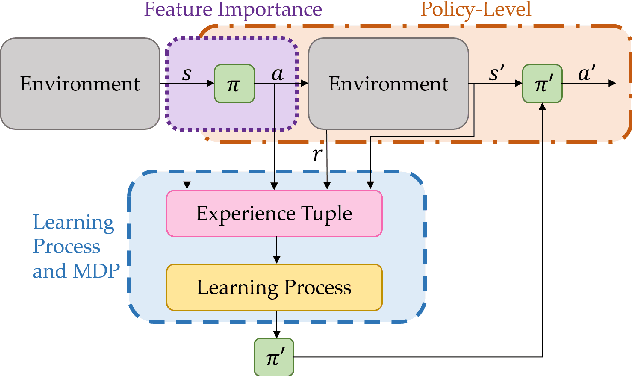
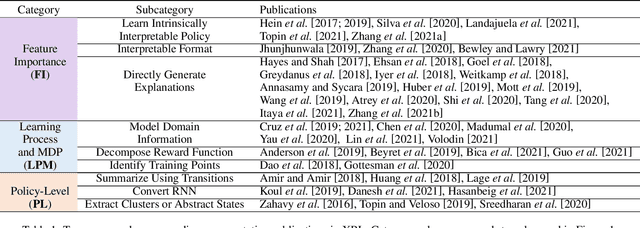
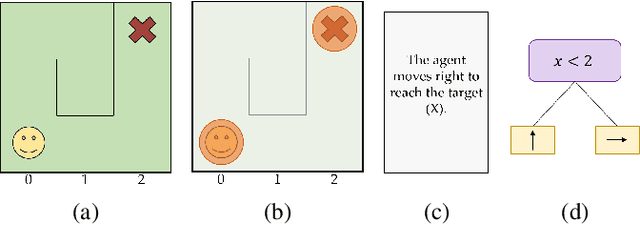
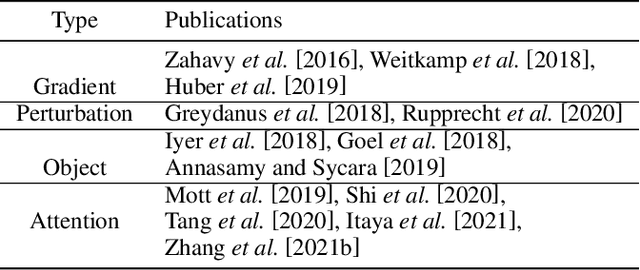
Explainable reinforcement learning (XRL) is an emerging subfield of explainable machine learning that has attracted considerable attention in recent years. The goal of XRL is to elucidate the decision-making process of learning agents in sequential decision-making settings. In this survey, we propose a novel taxonomy for organizing the XRL literature that prioritizes the RL setting. We overview techniques according to this taxonomy. We point out gaps in the literature, which we use to motivate and outline a roadmap for future work.
Structure with Semantics: Exploiting Document Relations for Retrieval
Jan 12, 2022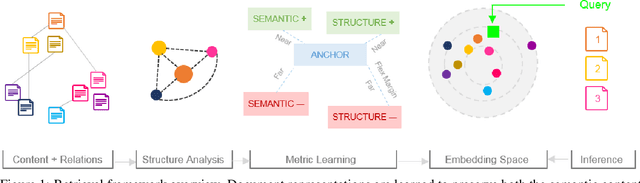
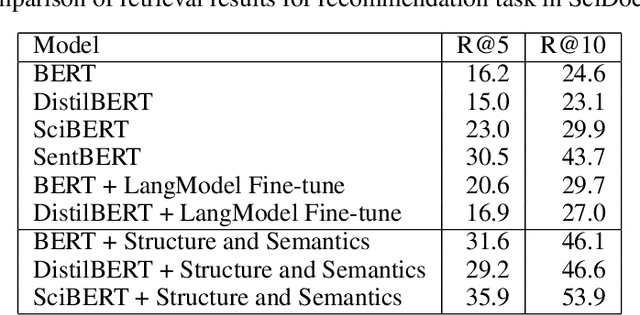
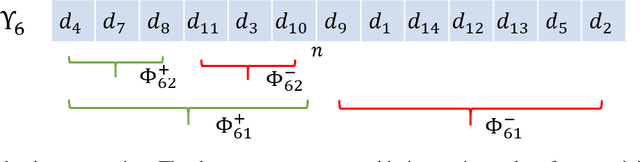
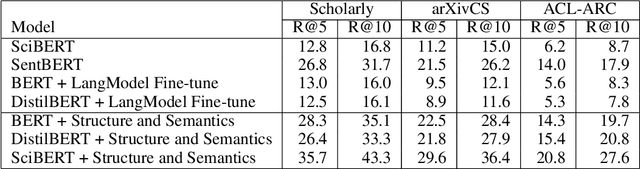
Retrieving relevant documents from a corpus is typically based on the semantic similarity between the document content and query text. The inclusion of structural relationship between documents can benefit the retrieval mechanism by addressing semantic gaps. However, incorporating these relationships requires tractable mechanisms that balance structure with semantics and take advantage of the prevalent pre-train/fine-tune paradigm. We propose here a holistic approach to learning document representations by integrating intra-document content with inter-document relations. Our deep metric learning solution analyzes the complex neighborhood structure in the relationship network to efficiently sample similar/dissimilar document pairs and defines a novel quintuplet loss function that simultaneously encourages document pairs that are semantically relevant to be closer and structurally unrelated to be far apart in the representation space. Furthermore, the separation margins between the documents are varied flexibly to encode the heterogeneity in relationship strengths. The model is fully fine-tunable and natively supports query projection during inference. We demonstrate that it outperforms competing methods on multiple datasets for document retrieval tasks.