 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHashSet -- A Dataset For Hashtag Segmentation
Jan 18, 2022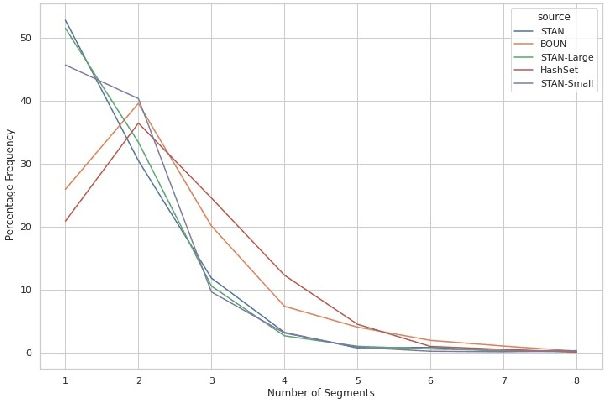
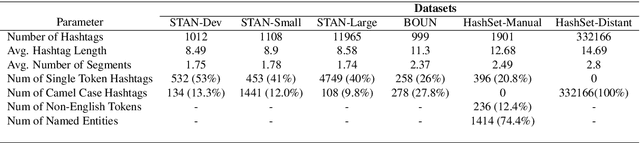
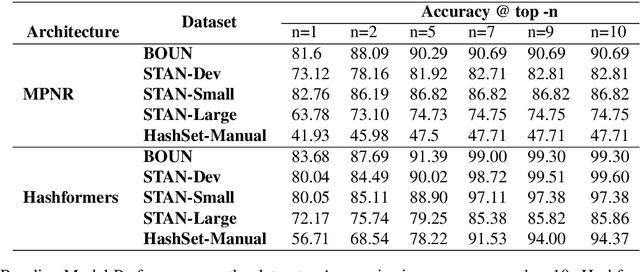

Hashtag segmentation is the task of breaking a hashtag into its constituent tokens. Hashtags often encode the essence of user-generated posts, along with information like topic and sentiment, which are useful in downstream tasks. Hashtags prioritize brevity and are written in unique ways -- transliterating and mixing languages, spelling variations, creative named entities. Benchmark datasets used for the hashtag segmentation task -- STAN, BOUN -- are small in size and extracted from a single set of tweets. However, datasets should reflect the variations in writing styles of hashtags and also account for domain and language specificity, failing which the results will misrepresent model performance. We argue that model performance should be assessed on a wider variety of hashtags, and datasets should be carefully curated. To this end, we propose HashSet, a dataset comprising of: a) 1.9k manually annotated dataset; b) 3.3M loosely supervised dataset. HashSet dataset is sampled from a different set of tweets when compared to existing datasets and provides an alternate distribution of hashtags to build and validate hashtag segmentation models. We show that the performance of SOTA models for Hashtag Segmentation drops substantially on proposed dataset, indicating that the proposed dataset provides an alternate set of hashtags to train and assess models.
Battling Hateful Content in Indic Languages HASOC '21
Nov 05, 2021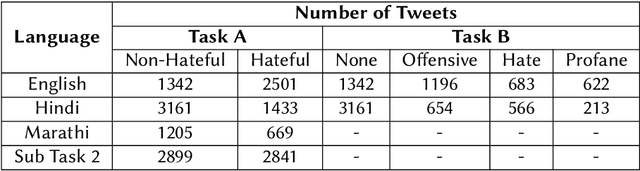
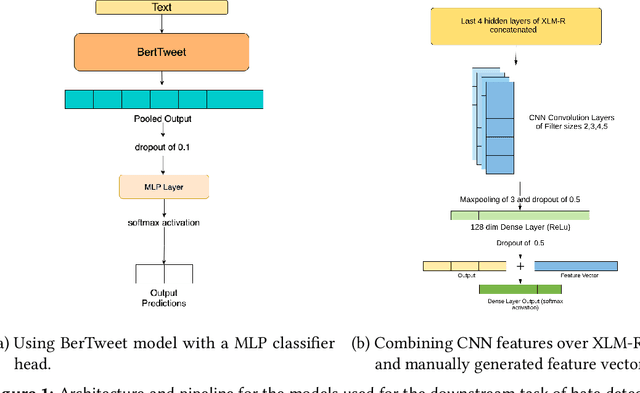
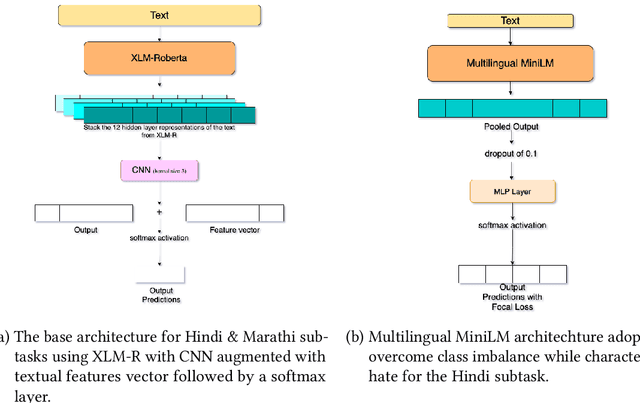
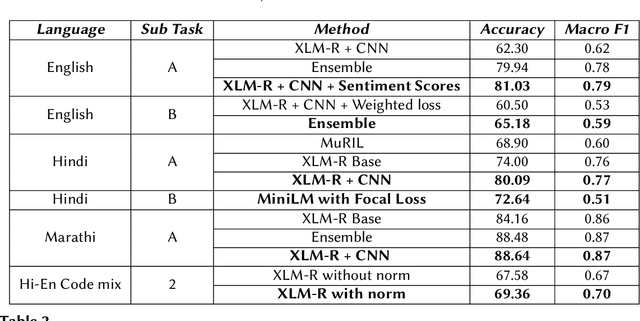
The extensive rise in consumption of online social media (OSMs) by a large number of people poses a critical problem of curbing the spread of hateful content on these platforms. With the growing usage of OSMs in multiple languages, the task of detecting and characterizing hate becomes more complex. The subtle variations of code-mixed texts along with switching scripts only add to the complexity. This paper presents a solution for the HASOC 2021 Multilingual Twitter Hate-Speech Detection challenge by team PreCog IIIT Hyderabad. We adopt a multilingual transformer based approach and describe our architecture for all 6 subtasks as part of the challenge. Out of the 6 teams that participated in all the subtasks, our submissions rank 3rd overall.
A Dynamic Head Importance Computation Mechanism for Neural Machine Translation
Aug 03, 2021
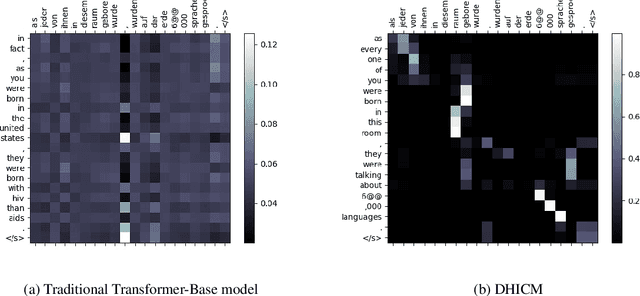
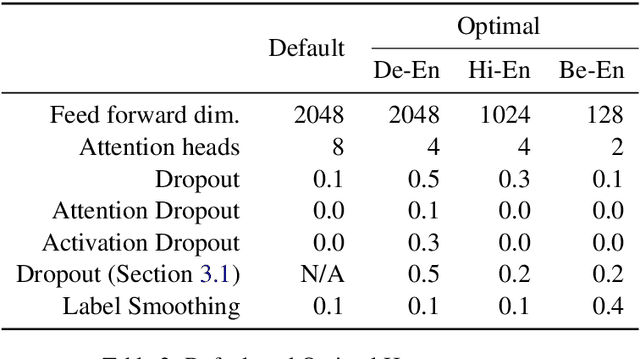
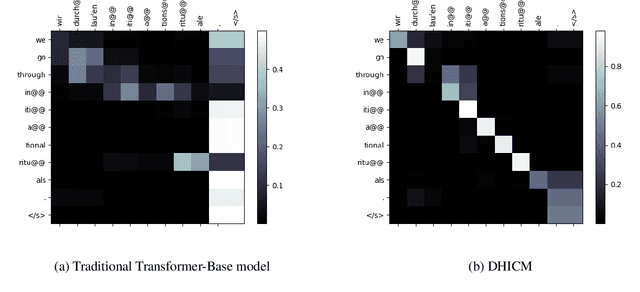
Multiple parallel attention mechanisms that use multiple attention heads facilitate greater performance of the Transformer model for various applications e.g., Neural Machine Translation (NMT), text classification. In multi-head attention mechanism, different heads attend to different parts of the input. However, the limitation is that multiple heads might attend to the same part of the input, resulting in multiple heads being redundant. Thus, the model resources are under-utilized. One approach to avoid this is to prune least important heads based on certain importance score. In this work, we focus on designing a Dynamic Head Importance Computation Mechanism (DHICM) to dynamically calculate the importance of a head with respect to the input. Our insight is to design an additional attention layer together with multi-head attention, and utilize the outputs of the multi-head attention along with the input, to compute the importance for each head. Additionally, we add an extra loss function to prevent the model from assigning same score to all heads, to identify more important heads and improvise performance. We analyzed performance of DHICM for NMT with different languages. Experiments on different datasets show that DHICM outperforms traditional Transformer-based approach by large margin, especially, when less training data is available.
Volta at SemEval-2021 Task 9: Statement Verification and Evidence Finding with Tables using TAPAS and Transfer Learning
Jun 17, 2021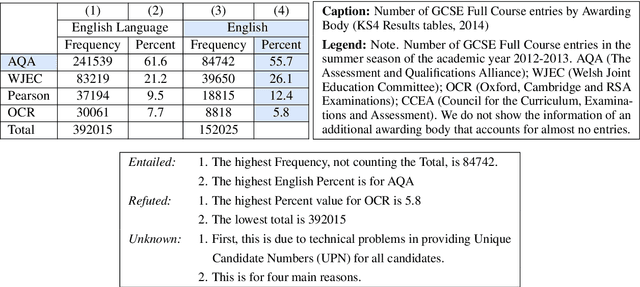

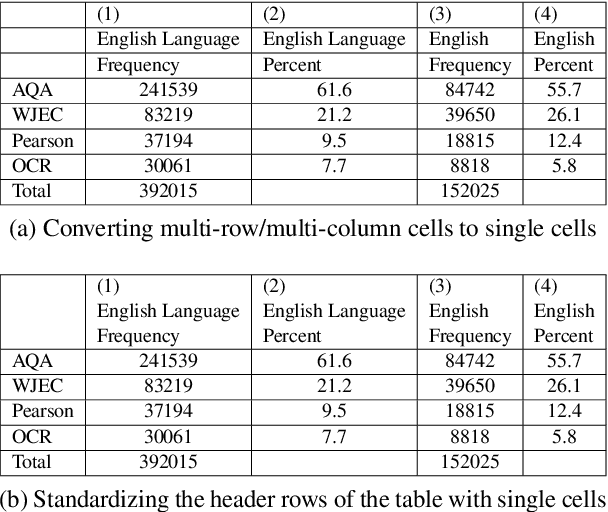

Tables are widely used in various kinds of documents to present information concisely. Understanding tables is a challenging problem that requires an understanding of language and table structure, along with numerical and logical reasoning. In this paper, we present our systems to solve Task 9 of SemEval-2021: Statement Verification and Evidence Finding with Tables (SEM-TAB-FACTS). The task consists of two subtasks: (A) Given a table and a statement, predicting whether the table supports the statement and (B) Predicting which cells in the table provide evidence for/against the statement. We fine-tune TAPAS (a model which extends BERT's architecture to capture tabular structure) for both the subtasks as it has shown state-of-the-art performance in various table understanding tasks. In subtask A, we evaluate how transfer learning and standardizing tables to have a single header row improves TAPAS' performance. In subtask B, we evaluate how different fine-tuning strategies can improve TAPAS' performance. Our systems achieve an F1 score of 67.34 in subtask A three-way classification, 72.89 in subtask A two-way classification, and 62.95 in subtask B.
"Subverting the Jewtocracy": Online Antisemitism Detection Using Multimodal Deep Learning
Apr 13, 2021
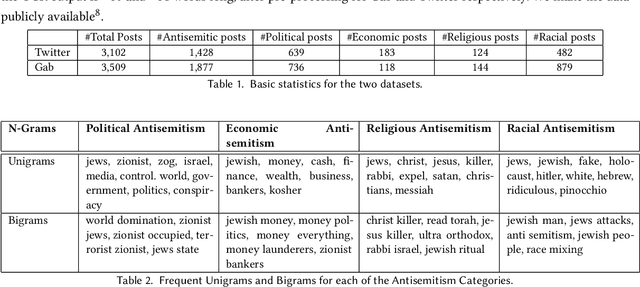
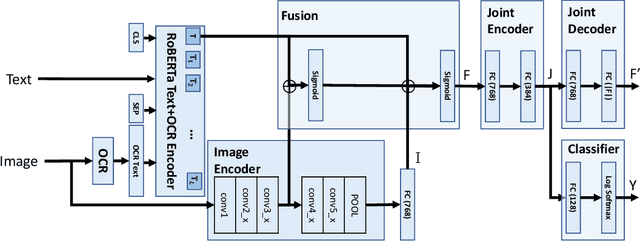
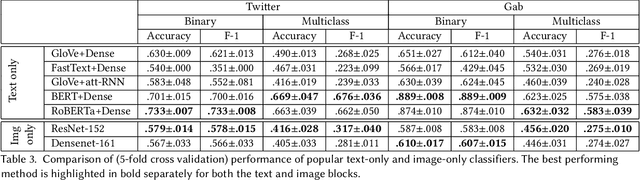
The exponential rise of online social media has enabled the creation, distribution, and consumption of information at an unprecedented rate. However, it has also led to the burgeoning of various forms of online abuse. Increasing cases of online antisemitism have become one of the major concerns because of its socio-political consequences. Unlike other major forms of online abuse like racism, sexism, etc., online antisemitism has not been studied much from a machine learning perspective. To the best of our knowledge, we present the first work in the direction of automated multimodal detection of online antisemitism. The task poses multiple challenges that include extracting signals across multiple modalities, contextual references, and handling multiple aspects of antisemitism. Unfortunately, there does not exist any publicly available benchmark corpus for this critical task. Hence, we collect and label two datasets with 3,102 and 3,509 social media posts from Twitter and Gab respectively. Further, we present a multimodal deep learning system that detects the presence of antisemitic content and its specific antisemitism category using text and images from posts. We perform an extensive set of experiments on the two datasets to evaluate the efficacy of the proposed system. Finally, we also present a qualitative analysis of our study.
AbuseAnalyzer: Abuse Detection, Severity and Target Prediction for Gab Posts
Oct 08, 2020
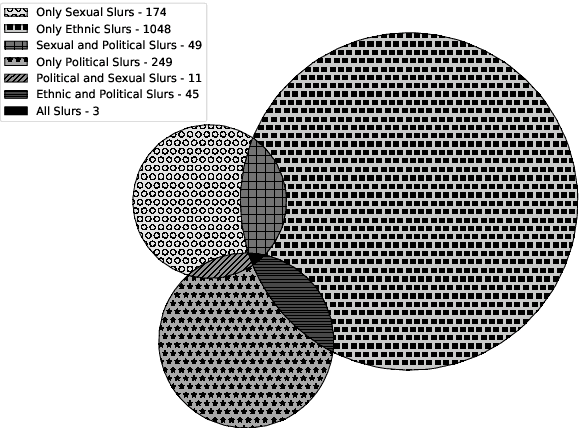
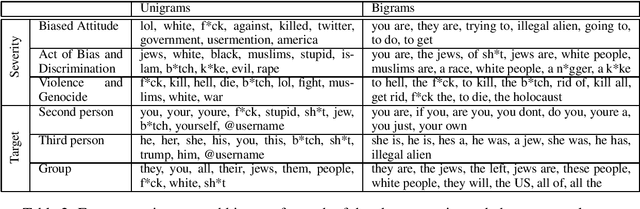

While extensive popularity of online social media platforms has made information dissemination faster, it has also resulted in widespread online abuse of different types like hate speech, offensive language, sexist and racist opinions, etc. Detection and curtailment of such abusive content is critical for avoiding its psychological impact on victim communities, and thereby preventing hate crimes. Previous works have focused on classifying user posts into various forms of abusive behavior. But there has hardly been any focus on estimating the severity of abuse and the target. In this paper, we present a first of the kind dataset with 7601 posts from Gab which looks at online abuse from the perspective of presence of abuse, severity and target of abusive behavior. We also propose a system to address these tasks, obtaining an accuracy of ~80% for abuse presence, ~82% for abuse target prediction, and ~65% for abuse severity prediction.
ConfNet2Seq: Full Length Answer Generation from Spoken Questions
Jun 11, 2020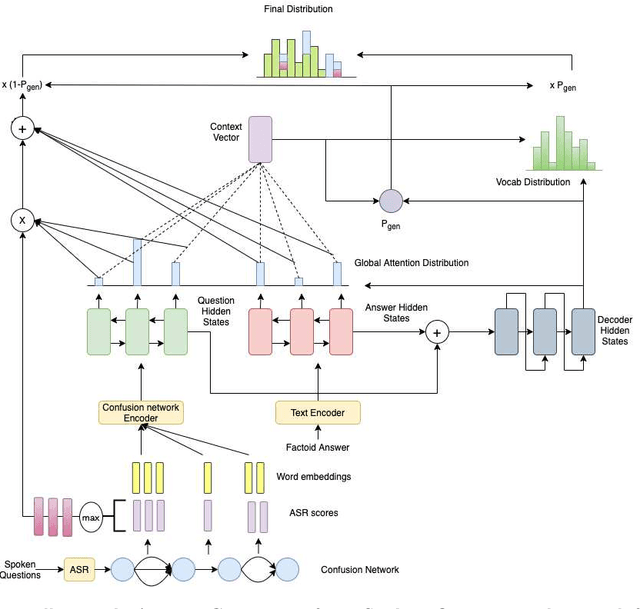
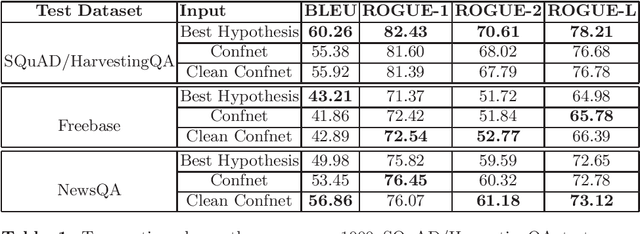
Conversational and task-oriented dialogue systems aim to interact with the user using natural responses through multi-modal interfaces, such as text or speech. These desired responses are in the form of full-length natural answers generated over facts retrieved from a knowledge source. While the task of generating natural answers to questions from an answer span has been widely studied, there has been little research on natural sentence generation over spoken content. We propose a novel system to generate full length natural language answers from spoken questions and factoid answers. The spoken sequence is compactly represented as a confusion network extracted from a pre-trained Automatic Speech Recognizer. This is the first attempt towards generating full-length natural answers from a graph input(confusion network) to the best of our knowledge. We release a large-scale dataset of 259,788 samples of spoken questions, their factoid answers and corresponding full-length textual answers. Following our proposed approach, we achieve comparable performance with best ASR hypothesis.
Transition-Based Deep Input Linearization
Nov 07, 2019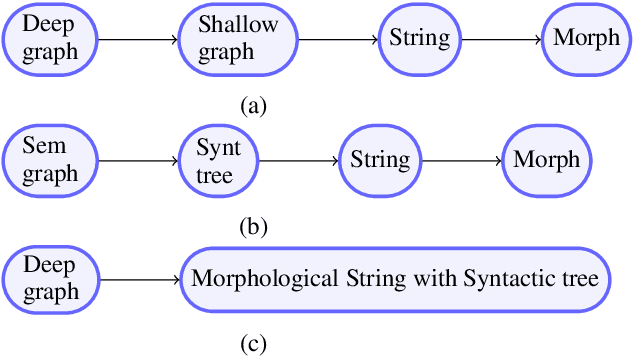


Traditional methods for deep NLG adopt pipeline approaches comprising stages such as constructing syntactic input, predicting function words, linearizing the syntactic input and generating the surface forms. Though easier to visualize, pipeline approaches suffer from error propagation. In addition, information available across modules cannot be leveraged by all modules. We construct a transition-based model to jointly perform linearization, function word prediction and morphological generation, which considerably improves upon the accuracy compared to a pipelined baseline system. On a standard deep input linearization shared task, our system achieves the best results reported so far.
Curriculum Learning Strategies for Hindi-English Codemixed Sentiment Analysis
Jun 18, 2019
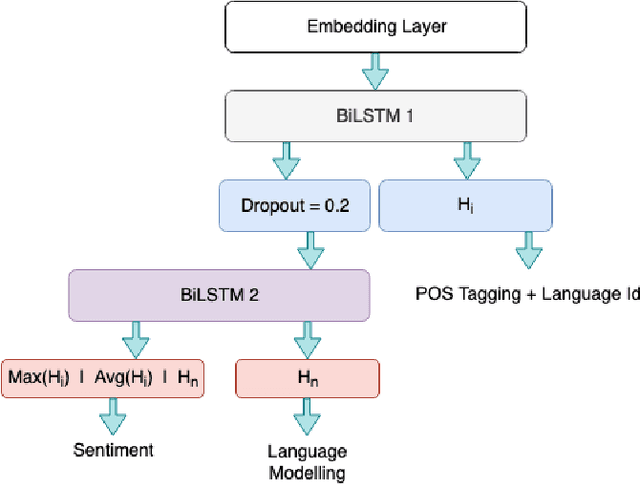


Sentiment Analysis and other semantic tasks are commonly used for social media textual analysis to gauge public opinion and make sense from the noise on social media. The language used on social media not only commonly diverges from the formal language, but is compounded by codemixing between languages, especially in large multilingual societies like India. Traditional methods for learning semantic NLP tasks have long relied on end to end task specific training, requiring expensive data creation process, even more so for deep learning methods. This challenge is even more severe for resource scarce texts like codemixed language pairs, with lack of well learnt representations as model priors, and task specific datasets can be few and small in quantities to efficiently exploit recent deep learning approaches. To address above challenges, we introduce curriculum learning strategies for semantic tasks in code-mixed Hindi-English (Hi-En) texts, and investigate various training strategies for enhancing model performance. Our method outperforms the state of the art methods for Hi-En codemixed sentiment analysis by 3.31% accuracy, and also shows better model robustness in terms of convergence, and variance in test performance.
Predicting Algorithm Classes for Programming Word Problems
Apr 04, 2019
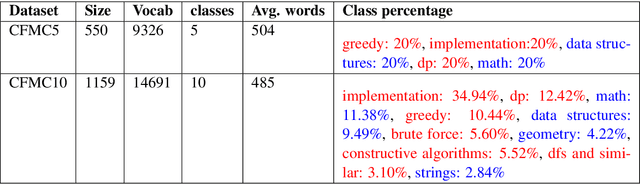

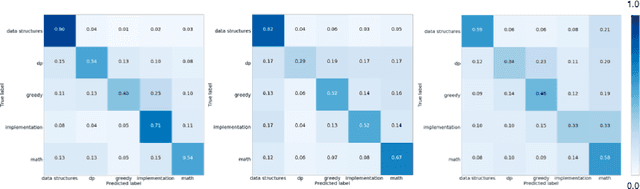
We introduce the task of algorithm class prediction for programming word problems. A programming word problem is a problem written in natural language, which can be solved using an algorithm or a program. We define classes of various programming word problems which correspond to the class of algorithms required to solve the problem. We present four new datasets for this task, two multiclass datasets with 550 and 1159 problems each and two multilabel datasets having 3737 and 3960 problems each. We pose the problem as a text classification problem and train neural network and non-neural network-based models on this task. Our best performing classifier gets an accuracy of 62.7 percent for the multiclass case on the five class classification dataset, Codeforces Multiclass-5 (CFMC5). We also do some human-level analysis and compare human performance with that of our text classification models. Our best classifier has an accuracy only 9 percent lower than that of a human on this task. To the best of our knowledge, these are the first reported results on such a task. We make our code and datasets publicly available.