 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Tokenization for Rich Morphology: The Dominance of Unigram over BPE and Morphological Alignment
Aug 11, 2025Prior work on language modeling showed conflicting findings about whether morphologically aligned approaches to tokenization improve performance, particularly for languages with complex morphology. To investigate this, we select a typologically diverse set of languages: Telugu (agglutinative), Hindi (primarily fusional with some agglutination), and English (fusional). We conduct a comprehensive evaluation of language models -- starting from tokenizer training and extending through the finetuning and downstream task evaluation. To account for the consistent performance differences observed across tokenizer variants, we focus on two key factors: morphological alignment and tokenization quality. To assess morphological alignment of tokenizers in Telugu, we create a dataset containing gold morpheme segmentations of 600 derivational and 7000 inflectional word forms. Our experiments reveal that better morphological alignment correlates positively -- though moderately -- with performance in syntax-based tasks such as Parts-of-Speech tagging, Named Entity Recognition and Dependency Parsing. However, we also find that the tokenizer algorithm (Byte-pair Encoding vs. Unigram) plays a more significant role in influencing downstream performance than morphological alignment alone. Naive Unigram tokenizers outperform others across most settings, though hybrid tokenizers that incorporate morphological segmentation significantly improve performance within the BPE framework. In contrast, intrinsic metrics like Corpus Token Count (CTC) and R\'enyi entropy showed no correlation with downstream performance.
Curriculum Learning Strategies for Hindi-English Codemixed Sentiment Analysis
Jun 18, 2019
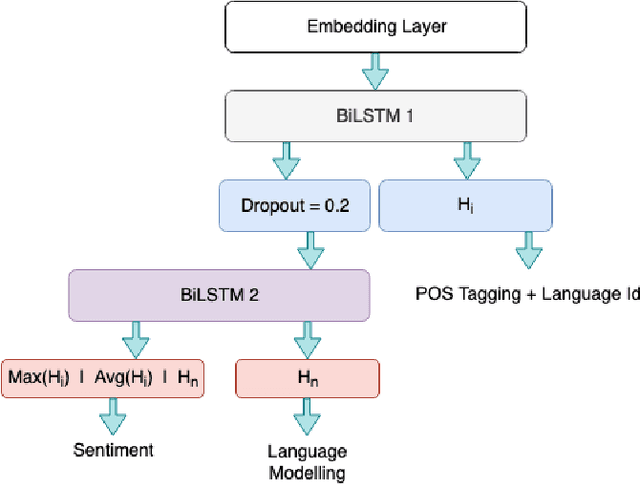


Sentiment Analysis and other semantic tasks are commonly used for social media textual analysis to gauge public opinion and make sense from the noise on social media. The language used on social media not only commonly diverges from the formal language, but is compounded by codemixing between languages, especially in large multilingual societies like India. Traditional methods for learning semantic NLP tasks have long relied on end to end task specific training, requiring expensive data creation process, even more so for deep learning methods. This challenge is even more severe for resource scarce texts like codemixed language pairs, with lack of well learnt representations as model priors, and task specific datasets can be few and small in quantities to efficiently exploit recent deep learning approaches. To address above challenges, we introduce curriculum learning strategies for semantic tasks in code-mixed Hindi-English (Hi-En) texts, and investigate various training strategies for enhancing model performance. Our method outperforms the state of the art methods for Hi-En codemixed sentiment analysis by 3.31% accuracy, and also shows better model robustness in terms of convergence, and variance in test performance.