 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotic self-representation improves manipulation skills and transfer learning
Nov 13, 2020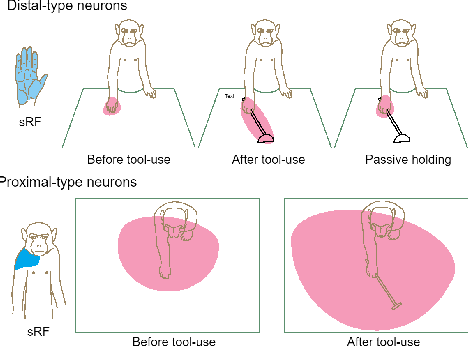
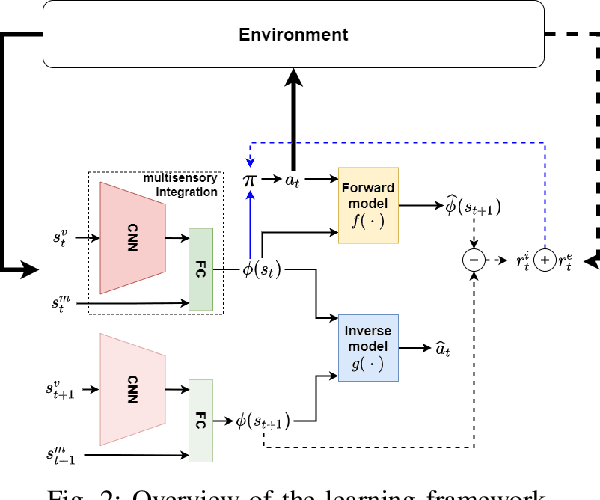
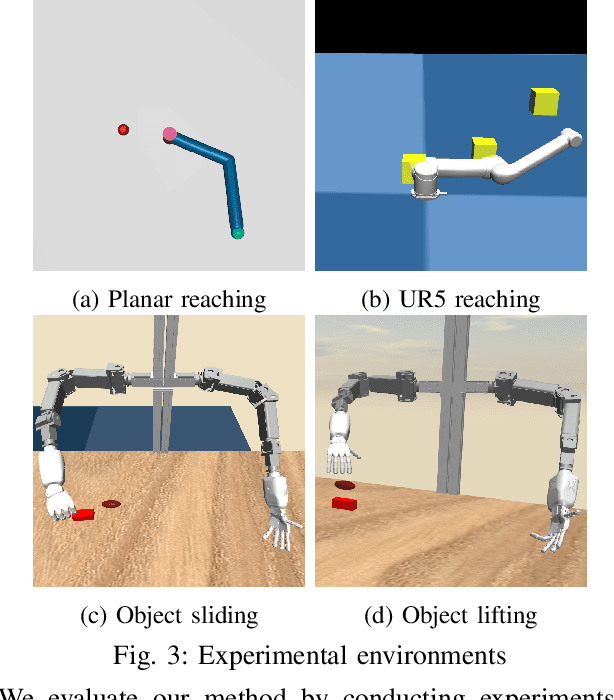
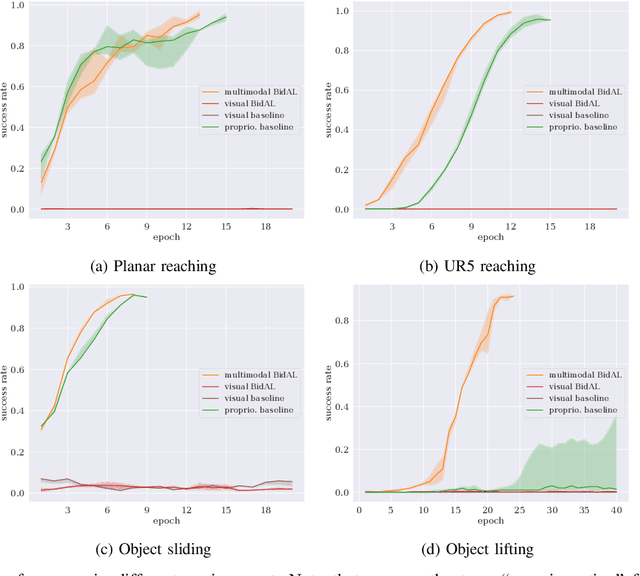
Cognitive science suggests that the self-representation is critical for learning and problem-solving. However, there is a lack of computational methods that relate this claim to cognitively plausible robots and reinforcement learning. In this paper, we bridge this gap by developing a model that learns bidirectional action-effect associations to encode the representations of body schema and the peripersonal space from multisensory information, which is named multimodal BidAL. Through three different robotic experiments, we demonstrate that this approach significantly stabilizes the learning-based problem-solving under noisy conditions and that it improves transfer learning of robotic manipulation skills.
Reinforcement Learning with Time-dependent Goals for Robotic Musicians
Nov 11, 2020

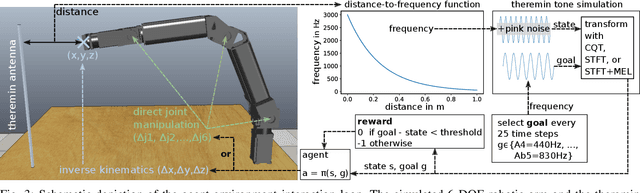

Reinforcement learning is a promising method to accomplish robotic control tasks. The task of playing musical instruments is, however, largely unexplored because it involves the challenge of achieving sequential goals - melodies - that have a temporal dimension. In this paper, we address robotic musicianship by introducing a temporal extension to goal-conditioned reinforcement learning: Time-dependent goals. We demonstrate that these can be used to train a robotic musician to play the theremin instrument. We train the robotic agent in simulation and transfer the acquired policy to a real-world robotic thereminist. Supplemental video: https://youtu.be/jvC9mPzdQN4
Enhancing a Neurocognitive Shared Visuomotor Model for Object Identification, Localization, and Grasping With Learning From Auxiliary Tasks
Sep 26, 2020
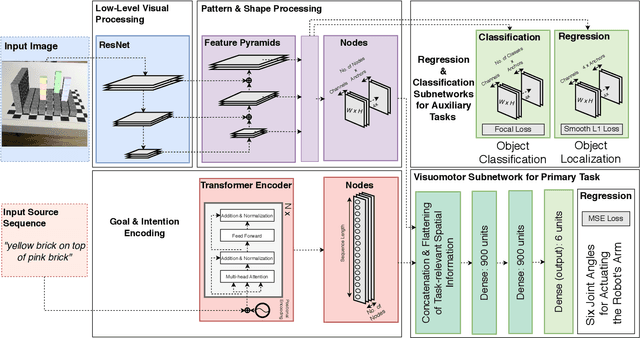


We present a follow-up study on our unified visuomotor neural model for the robotic tasks of identifying, localizing, and grasping a target object in a scene with multiple objects. Our Retinanet-based model enables end-to-end training of visuomotor abilities in a biologically inspired developmental approach. In our initial implementation, a neural model was able to grasp selected objects from a planar surface. We embodied the model on the NICO humanoid robot. In this follow-up study, we expand the task and the model to reaching for objects in a three-dimensional space with a novel dataset based on augmented reality and a simulation environment. We evaluate the influence of training with auxiliary tasks, i.e., if learning of the primary visuomotor task is supported by learning to classify and locate different objects. We show that the proposed visuomotor model can learn to reach for objects in a three-dimensional space. We analyze the results for biologically-plausible biases based on object locations or properties. We show that the primary visuomotor task can be successfully trained simultaneously with one of the two auxiliary tasks. This is enabled by a complex neurocognitive model with shared and task-specific components, similar to models found in biological systems.
Curious Hierarchical Actor-Critic Reinforcement Learning
May 27, 2020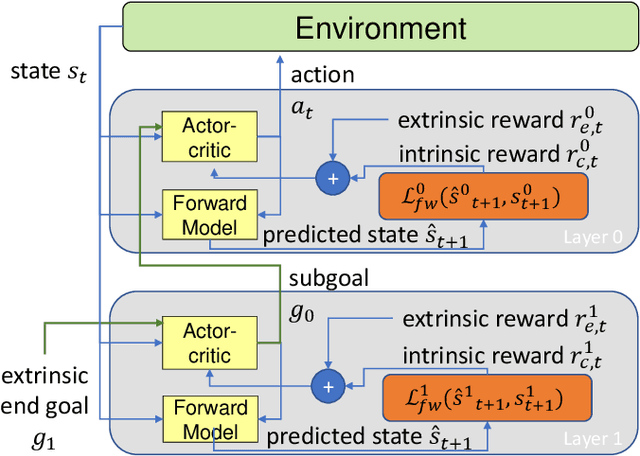
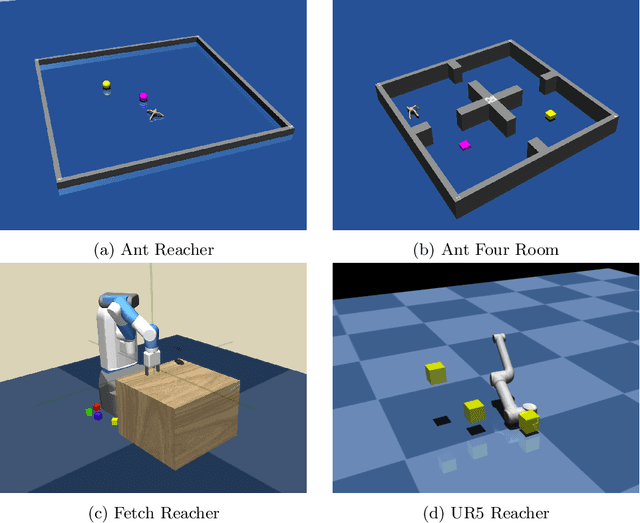
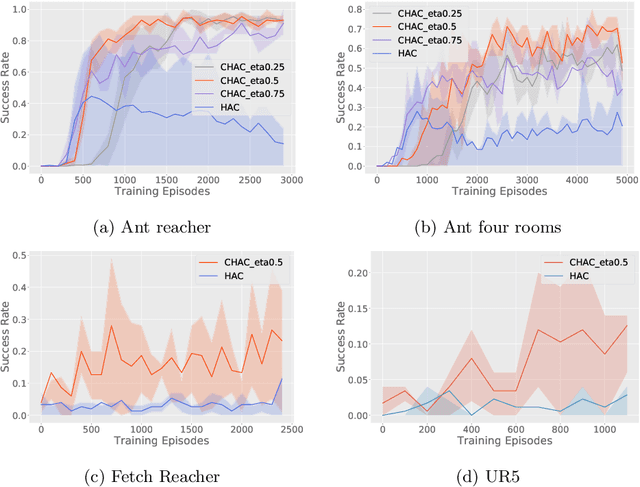
Hierarchical abstraction and curiosity-driven exploration are two common paradigms in current reinforcement learning approaches to break down difficult problems into a sequence of simpler ones and to overcome reward sparsity. However, there is a lack of approaches that combine these paradigms, and it is currently unknown whether curiosity also helps to perform the hierarchical abstraction. As a novelty and scientific contribution, we tackle this issue and develop a method that combines hierarchical reinforcement learning with curiosity. Herein, we extend a contemporary hierarchical actor-critic approach with a forward model to develop a hierarchical notion of curiosity. We demonstrate in several continuous-space environments that curiosity approximately doubles the learning performance and success rates for most of the investigated benchmarking problems.
From semantics to execution: Integrating action planning with reinforcement learning for robotic tool use
May 23, 2019
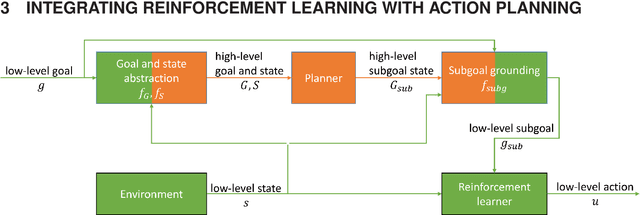
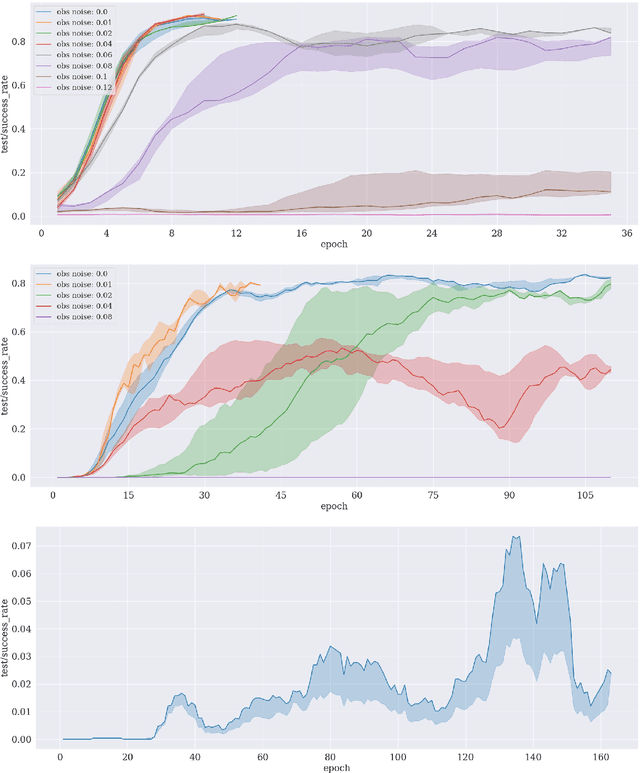
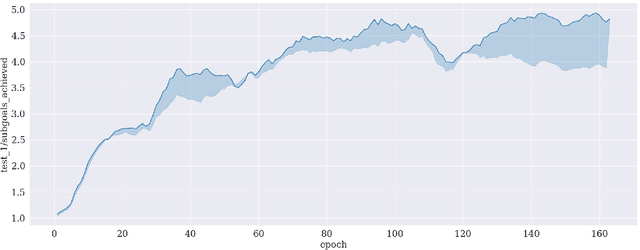
Reinforcement learning is an appropriate and successful method to robustly perform low-level robot control under noisy conditions. Symbolic action planning is useful to resolve causal dependencies and to break a causally complex problem down into a sequence of simpler high-level actions. A problem with the integration of both approaches is that action planning is based on discrete high-level action- and state spaces, whereas reinforcement learning is usually driven by a continuous reward function. However, recent advances in reinforcement learning, specifically, universal value function approximators and hindsight experience replay, have focused on goal-independent methods based on sparse rewards. In this article, we build on these novel methods to facilitate the integration of action planning with reinforcement learning by exploiting the reward-sparsity as a bridge between the high-level and low-level state- and control spaces. As a result, we demonstrate that the integrated neuro-symbolic method is able to solve object manipulation problems that involve tool use and non-trivial causal dependencies under noisy conditions, exploiting both data and knowledge.
Curriculum goal masking for continuous deep reinforcement learning
Sep 17, 2018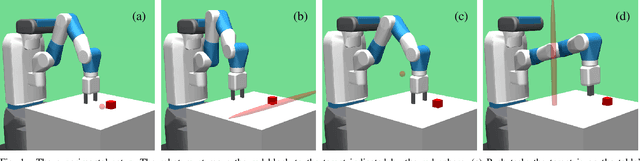
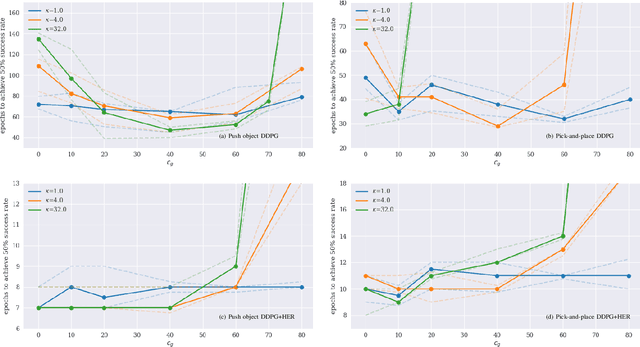
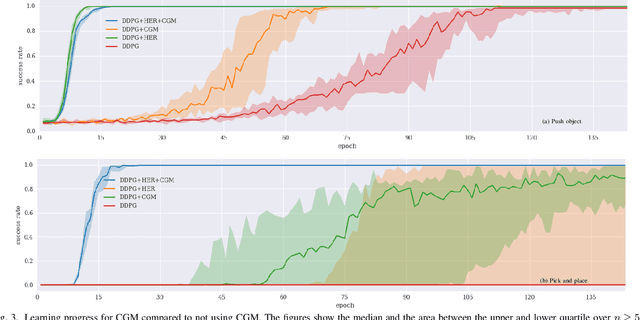
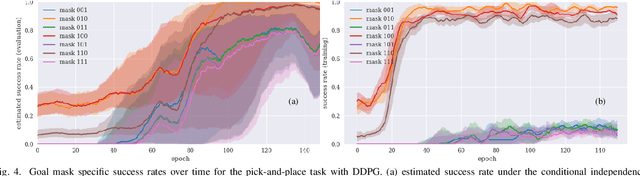
Deep reinforcement learning has recently gained a focus on problems where policy or value functions are independent of goals. Evidence exists that the sampling of goals has a strong effect on the learning performance, but there is a lack of general mechanisms that focus on optimizing the goal sampling process. In this work, we present a simple and general goal masking method that also allows us to estimate a goal's difficulty level and thus realize a curriculum learning approach for deep RL. Our results indicate that focusing on goals with a medium difficulty level is appropriate for deep deterministic policy gradient (DDPG) methods, while an "aim for the stars and reach the moon-strategy", where hard goals are sampled much more often than simple goals, leads to the best learning performance in cases where DDPG is combined with for hindsight experience replay (HER). We demonstrate that the approach significantly outperforms standard goal sampling for different robotic object manipulation problems.
Deep Neural Object Analysis by Interactive Auditory Exploration with a Humanoid Robot
Jul 10, 2018

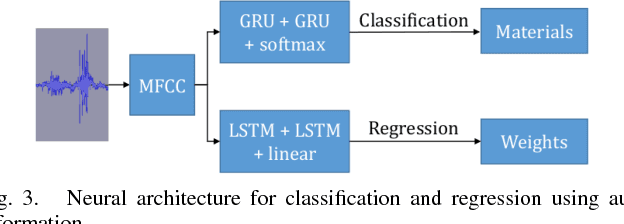
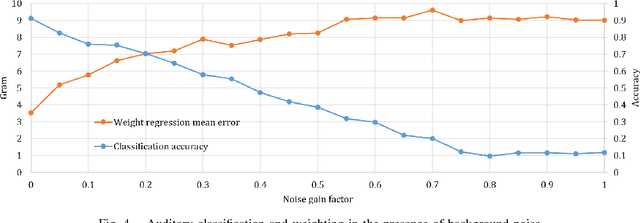
We present a novel approach for interactive auditory object analysis with a humanoid robot. The robot elicits sensory information by physically shaking visually indistinguishable plastic capsules. It gathers the resulting audio signals from microphones that are embedded into the robotic ears. A neural network architecture learns from these signals to analyze properties of the contents of the containers. Specifically, we evaluate the material classification and weight prediction accuracy and demonstrate that the framework is fairly robust to acoustic real-world noise.
Grounding Dynamic Spatial Relations for Embodied (Robot) Interaction
Jul 26, 2016

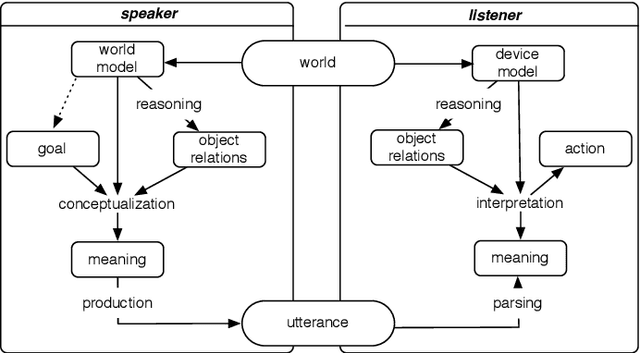
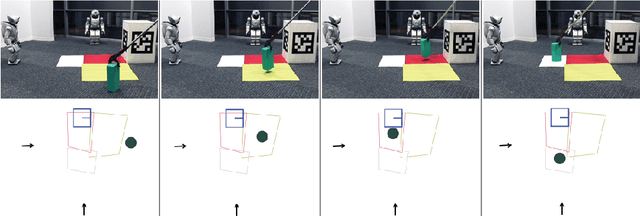
This paper presents a computational model of the processing of dynamic spatial relations occurring in an embodied robotic interaction setup. A complete system is introduced that allows autonomous robots to produce and interpret dynamic spatial phrases (in English) given an environment of moving objects. The model unites two separate research strands: computational cognitive semantics and on commonsense spatial representation and reasoning. The model for the first time demonstrates an integration of these different strands.
Exploiting Deep Semantics and Compositionality of Natural Language for Human-Robot-Interaction
Apr 22, 2016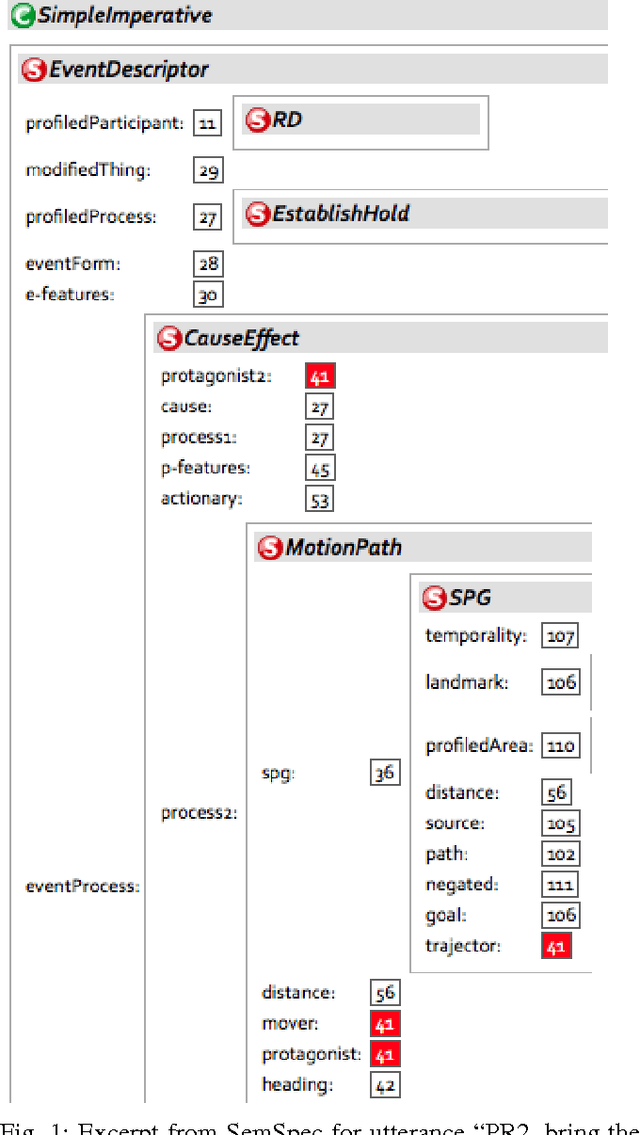
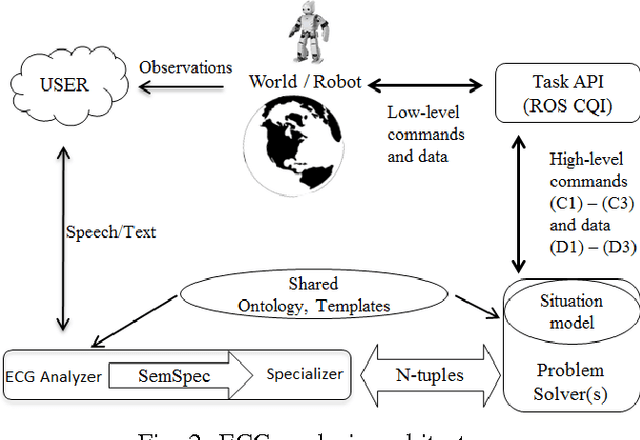
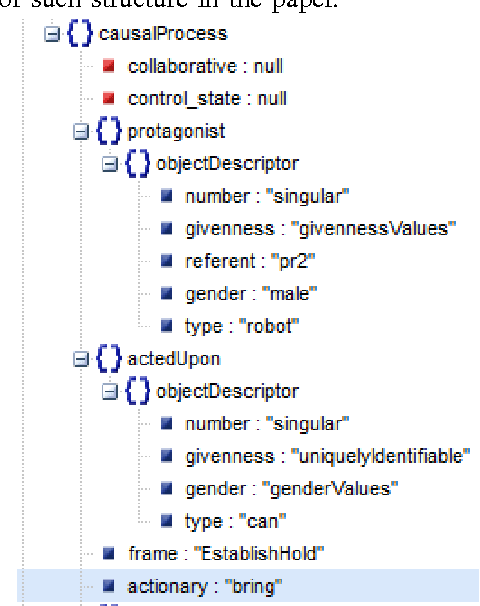

We develop a natural language interface for human robot interaction that implements reasoning about deep semantics in natural language. To realize the required deep analysis, we employ methods from cognitive linguistics, namely the modular and compositional framework of Embodied Construction Grammar (ECG) [Feldman, 2009]. Using ECG, robots are able to solve fine-grained reference resolution problems and other issues related to deep semantics and compositionality of natural language. This also includes verbal interaction with humans to clarify commands and queries that are too ambiguous to be executed safely. We implement our NLU framework as a ROS package and present proof-of-concept scenarios with different robots, as well as a survey on the state of the art.
Tractable Epistemic Reasoning with Functional Fluents, Static Causal Laws and Postdiction
Mar 22, 2014We present an epistemic action theory for tractable epistemic reasoning as an extension to the h-approximation (HPX) theory. In contrast to existing tractable approaches, the theory supports functional fluents and postdictive reasoning with static causal laws. We argue that this combination is particularly synergistic because it allows one not only to perform direct postdiction about the conditions of actions, but also indirect postdiction about the conditions of static causal laws. We show that despite the richer expressiveness, the temporal projection problem remains tractable (polynomial), and therefore the planning problem remains in NP. We present the operational semantics of our theory as well as its formulation as Answer Set Programming.