 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphological Inflection Generation Using Character Sequence to Sequence Learning
Mar 22, 2016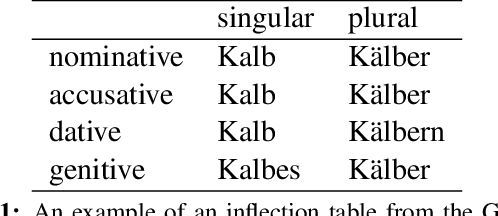
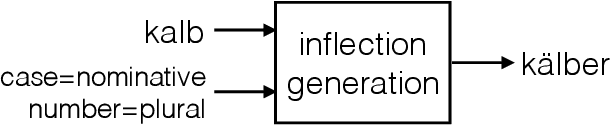
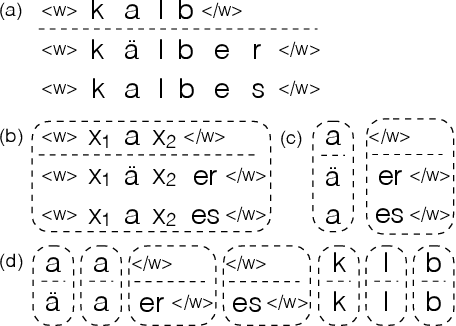

Morphological inflection generation is the task of generating the inflected form of a given lemma corresponding to a particular linguistic transformation. We model the problem of inflection generation as a character sequence to sequence learning problem and present a variant of the neural encoder-decoder model for solving it. Our model is language independent and can be trained in both supervised and semi-supervised settings. We evaluate our system on seven datasets of morphologically rich languages and achieve either better or comparable results to existing state-of-the-art models of inflection generation.
Morpho-syntactic Lexicon Generation Using Graph-based Semi-supervised Learning
Jan 24, 2016Morpho-syntactic lexicons provide information about the morphological and syntactic roles of words in a language. Such lexicons are not available for all languages and even when available, their coverage can be limited. We present a graph-based semi-supervised learning method that uses the morphological, syntactic and semantic relations between words to automatically construct wide coverage lexicons from small seed sets. Our method is language-independent, and we show that we can expand a 1000 word seed lexicon to more than 100 times its size with high quality for 11 languages. In addition, the automatically created lexicons provide features that improve performance in two downstream tasks: morphological tagging and dependency parsing.
Non-distributional Word Vector Representations
Jun 17, 2015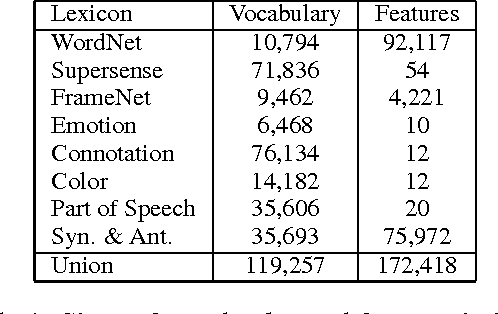


Data-driven representation learning for words is a technique of central importance in NLP. While indisputably useful as a source of features in downstream tasks, such vectors tend to consist of uninterpretable components whose relationship to the categories of traditional lexical semantic theories is tenuous at best. We present a method for constructing interpretable word vectors from hand-crafted linguistic resources like WordNet, FrameNet etc. These vectors are binary (i.e, contain only 0 and 1) and are 99.9% sparse. We analyze their performance on state-of-the-art evaluation methods for distributional models of word vectors and find they are competitive to standard distributional approaches.
Multilingual Open Relation Extraction Using Cross-lingual Projection
Jun 05, 2015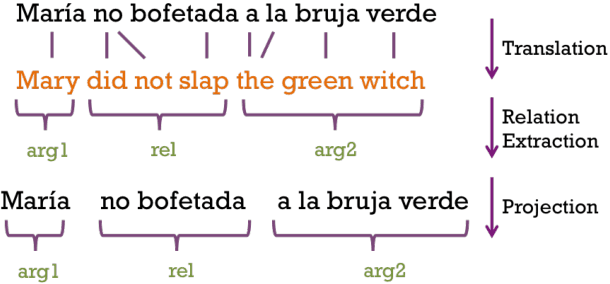
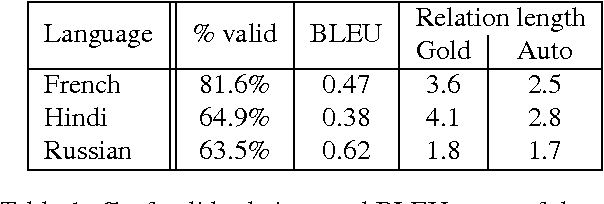
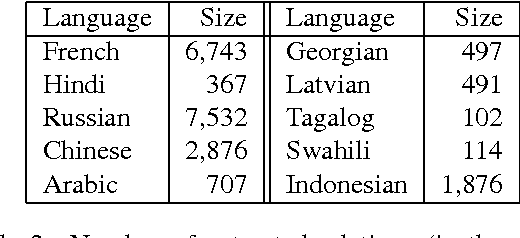
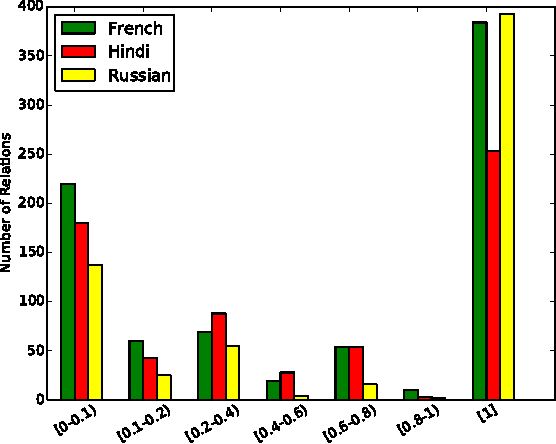
Open domain relation extraction systems identify relation and argument phrases in a sentence without relying on any underlying schema. However, current state-of-the-art relation extraction systems are available only for English because of their heavy reliance on linguistic tools such as part-of-speech taggers and dependency parsers. We present a cross-lingual annotation projection method for language independent relation extraction. We evaluate our method on a manually annotated test set and present results on three typologically different languages. We release these manual annotations and extracted relations in 61 languages from Wikipedia.
Sparse Overcomplete Word Vector Representations
Jun 05, 2015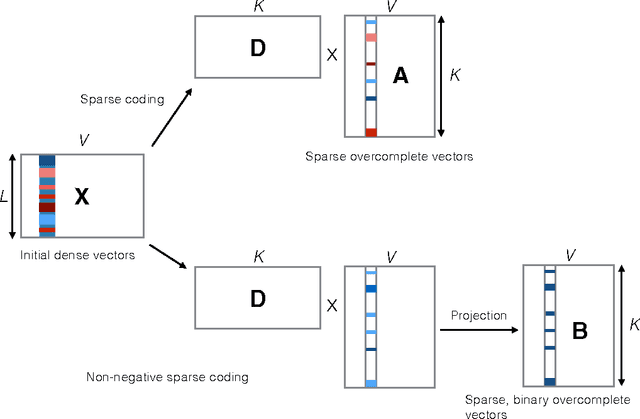
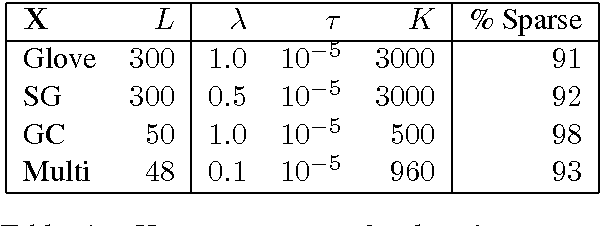
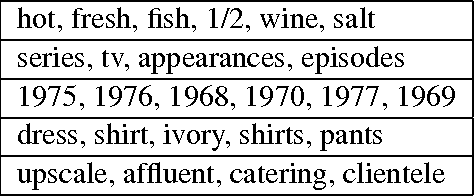
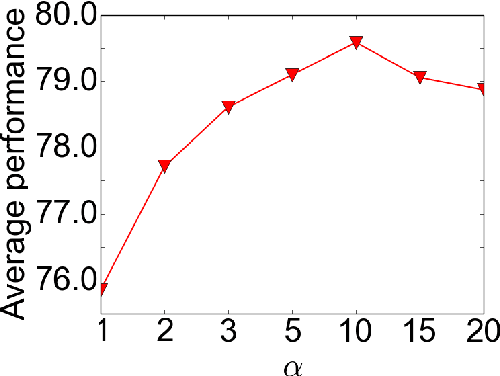
Current distributed representations of words show little resemblance to theories of lexical semantics. The former are dense and uninterpretable, the latter largely based on familiar, discrete classes (e.g., supersenses) and relations (e.g., synonymy and hypernymy). We propose methods that transform word vectors into sparse (and optionally binary) vectors. The resulting representations are more similar to the interpretable features typically used in NLP, though they are discovered automatically from raw corpora. Because the vectors are highly sparse, they are computationally easy to work with. Most importantly, we find that they outperform the original vectors on benchmark tasks.
Retrofitting Word Vectors to Semantic Lexicons
Mar 22, 2015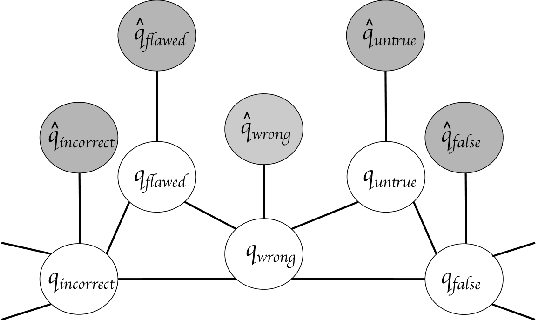
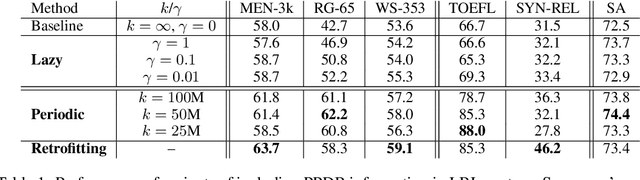
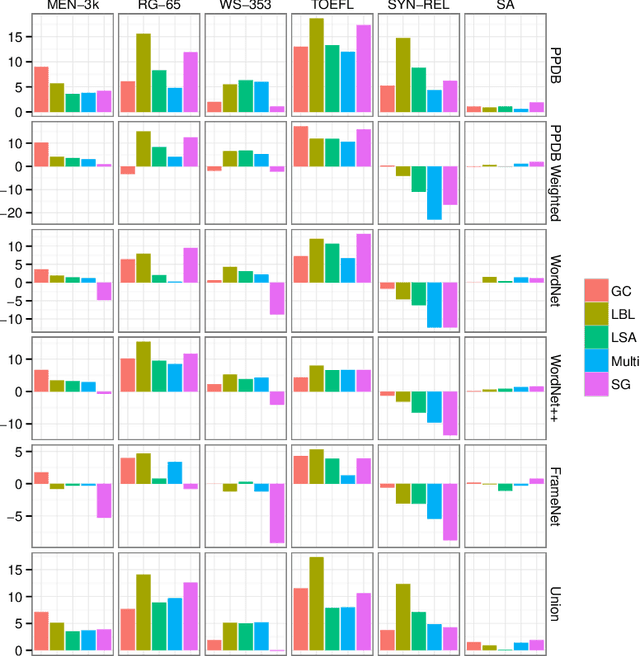
Vector space word representations are learned from distributional information of words in large corpora. Although such statistics are semantically informative, they disregard the valuable information that is contained in semantic lexicons such as WordNet, FrameNet, and the Paraphrase Database. This paper proposes a method for refining vector space representations using relational information from semantic lexicons by encouraging linked words to have similar vector representations, and it makes no assumptions about how the input vectors were constructed. Evaluated on a battery of standard lexical semantic evaluation tasks in several languages, we obtain substantial improvements starting with a variety of word vector models. Our refinement method outperforms prior techniques for incorporating semantic lexicons into the word vector training algorithms.
Learning Word Representations with Hierarchical Sparse Coding
Nov 06, 2014
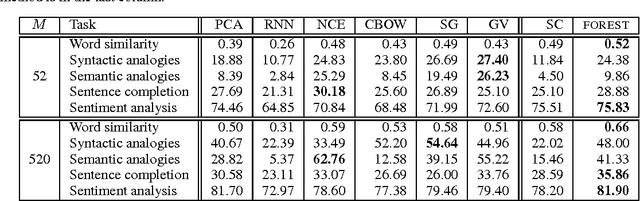

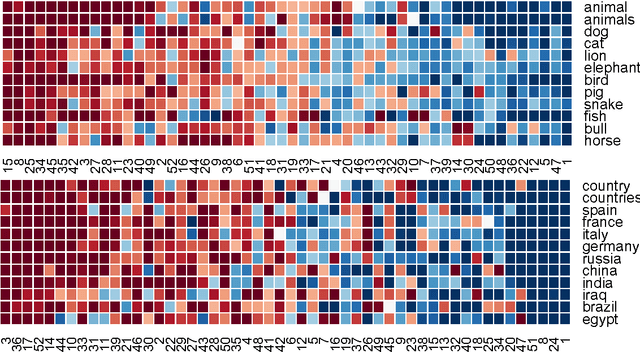
We propose a new method for learning word representations using hierarchical regularization in sparse coding inspired by the linguistic study of word meanings. We show an efficient learning algorithm based on stochastic proximal methods that is significantly faster than previous approaches, making it possible to perform hierarchical sparse coding on a corpus of billions of word tokens. Experiments on various benchmark tasks---word similarity ranking, analogies, sentence completion, and sentiment analysis---demonstrate that the method outperforms or is competitive with state-of-the-art methods. Our word representations are available at \url{http://www.ark.cs.cmu.edu/dyogatam/wordvecs/}.
"Translation can't change a name": Using Multilingual Data for Named Entity Recognition
May 04, 2014
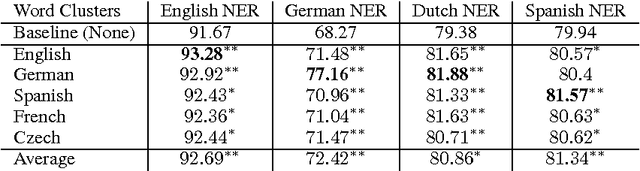
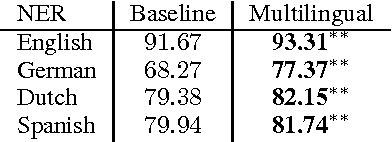
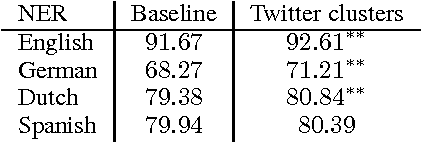
Named Entities (NEs) are often written with no orthographic changes across different languages that share a common alphabet. We show that this can be leveraged so as to improve named entity recognition (NER) by using unsupervised word clusters from secondary languages as features in state-of-the-art discriminative NER systems. We observe significant increases in performance, finding that person and location identification is particularly improved, and that phylogenetically close languages provide more valuable features than more distant languages.
A framework for (under)specifying dependency syntax without overloading annotators
Jun 15, 2013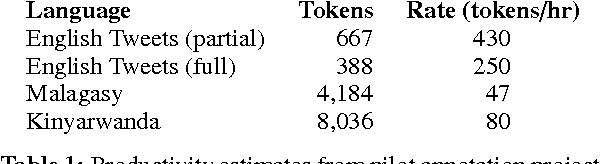

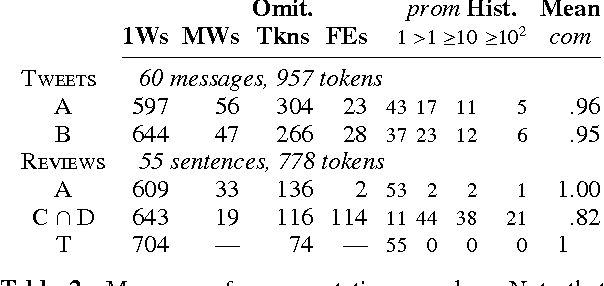
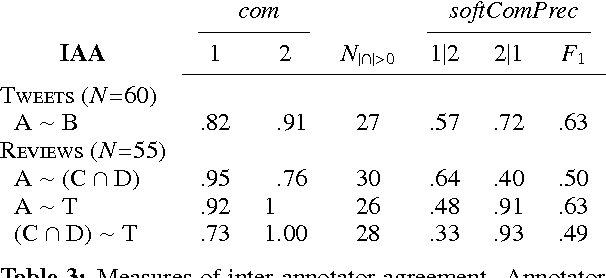
We introduce a framework for lightweight dependency syntax annotation. Our formalism builds upon the typical representation for unlabeled dependencies, permitting a simple notation and annotation workflow. Moreover, the formalism encourages annotators to underspecify parts of the syntax if doing so would streamline the annotation process. We demonstrate the efficacy of this annotation on three languages and develop algorithms to evaluate and compare underspecified annotations.