 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe CIFAR Synthetic Evidence Corpus for Detecting AI-Generated Evidence
Jun 06, 2026The growing ability of generative models to produce realistic documents poses a direct challenge to evidentiary workflows in the justice system and the courts, where decisions increasingly depend on the authenticity of evidence such as receipts, communications, and administrative records. Unlike social media or academic settings, evidentiary documents are often only subtly altered, with small, localized edits that preserve overall plausibility while changing legal meaning. Yet progress on automated detection remains limited, largely due to the absence of suitable training and evaluation data especially suited for the justice system requirements. Existing resources are either focused on photos of human faces or natural scenery or on narrowly scoped academic or social media document types, and do not capture the structure, diversity, or manipulation patterns characteristic of real-world evidentiary data. As a result, current detection systems do not necessarily learn meaningful signals appropriate for the justice system. We introduce the CIFAR Synthetic Evidence Corpus, a dataset designed to enable rigorous evaluation of evidence verification under realistic and controlled conditions. The corpus spans multiple document families and a spectrum of manipulation strategies, from small field-level edits to complete document fabrication, and is constructed using a diverse set of state-of-the-art generative tools. It is organized to systematically vary both manipulation complexity and generation method, while enforcing source-level separation between training and test data to reflect real-world generalization challenges.
DetectZoo: A Unified Toolkit for AI-Generated Content Detection Across Text, Audio, and Image Modalities
Jun 02, 2026The growing popularity and capacity of generative models have eroded the distinction between human and machine-generated content, motivating a growing body of work on detection across text, images, and audio. Most available detectors are either commercial software or, if open-source, come with incompatible codebases with bespoke preprocessing, evaluation protocols, and evaluation metrics, which make their adoption, fair comparison, and reproduction quite difficult. To address this critical gap, we introduce DetectZoo, a first-of-its-kind, extensible toolkit designed to provide a unified interface for AI-generated content detection across text, audio, and image modalities. DetectZoo standardizes the complete empirical pipeline, from data ingestion and preprocessing to model assessment, offering researchers a cohesive framework to benchmark state-of-the-art detectors systematically. By integrating diverse public datasets and baseline detection algorithms under a single, unified API, our toolkit facilitates rigorous and reproducible evaluation. DetectZoo provides reference implementations of 61 detectors, native loaders for 22 benchmark datasets, and a standardized evaluation pipeline that reports multiple metrics through a common interface. Each detector is self-contained yet accessible through the same interface, automatically caches pretrained weights, and reproduces the original published results. DetectZoo lowers the barrier to entry for multi-modal AI forensics, enabling researchers to identify performance gaps across domains and accelerating the development of robust, generalizable detection techniques. The open-source repository and comprehensive documentation are publicly available at https://github.com/sadjadeb/DetectZoo, and the package can be installed via pip install detectzoo.
CanLegalRAGBench: Evaluating Retrieval-Augmented Generation on Canadian Case Law
May 28, 2026RAG-based legal assistants have been growing in popularity, but LLM hallucinations remain a key issue and potentially undermines justice. While benchmarks have been developed to evaluate progress, many rely on synthetic queries rather than realistic legal scenarios. Moreover, Canadian law remains underrepresented in existing evaluations. To address this gap, we introduce CanLegalRAGBench, a Canadian legal QA benchmark based on realistic queries and expert-annotated answers grounded in case law. Our evaluation shows that retrieval performance is sensitive to design choices and that open-source embedding models are competitive with closed source models. However, it also reveals the limitation of automatic evaluations that penalize systems for retrieving alternative relevant documents. We also find that generated answers often diverge from gold responses, either with hallucinations or by producing overly detailed or irrelevant content, with 8-29% of claims not being supported by the retrieved documents. We hope this benchmark will help drive continued progress in addressing limitations of legal RAG systems.
Stance Reasoner: Zero-Shot Stance Detection on Social Media with Explicit Reasoning
Mar 22, 2024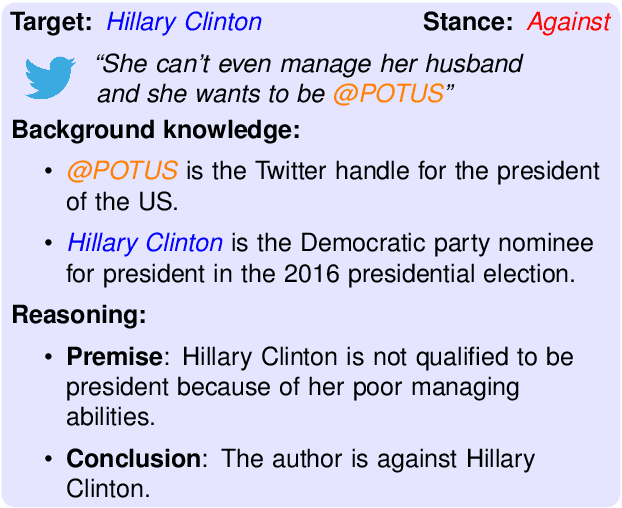
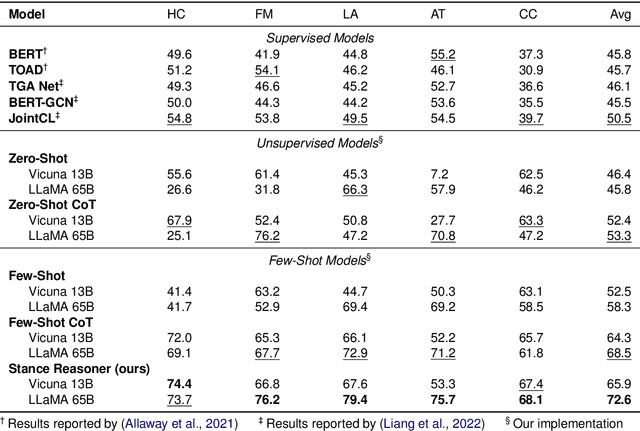
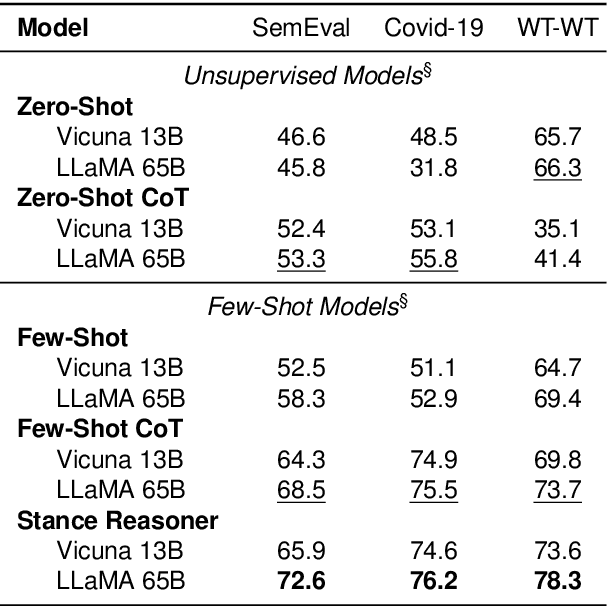
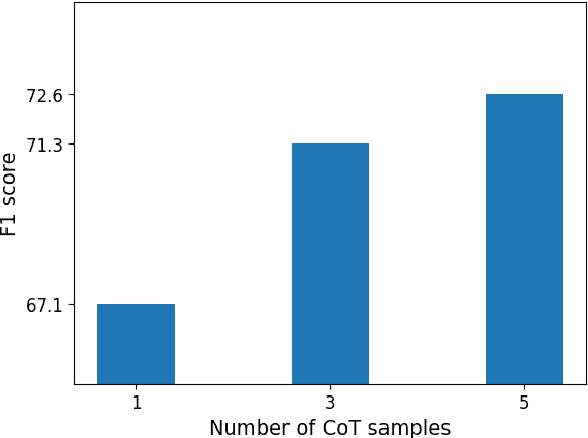
Social media platforms are rich sources of opinionated content. Stance detection allows the automatic extraction of users' opinions on various topics from such content. We focus on zero-shot stance detection, where the model's success relies on (a) having knowledge about the target topic; and (b) learning general reasoning strategies that can be employed for new topics. We present Stance Reasoner, an approach to zero-shot stance detection on social media that leverages explicit reasoning over background knowledge to guide the model's inference about the document's stance on a target. Specifically, our method uses a pre-trained language model as a source of world knowledge, with the chain-of-thought in-context learning approach to generate intermediate reasoning steps. Stance Reasoner outperforms the current state-of-the-art models on 3 Twitter datasets, including fully supervised models. It can better generalize across targets, while at the same time providing explicit and interpretable explanations for its predictions.
Empowering Air Travelers: A Chatbot for Canadian Air Passenger Rights
Mar 19, 2024The Canadian air travel sector has seen a significant increase in flight delays, cancellations, and other issues concerning passenger rights. Recognizing this demand, we present a chatbot to assist passengers and educate them about their rights. Our system breaks a complex user input into simple queries which are used to retrieve information from a collection of documents detailing air travel regulations. The most relevant passages from these documents are presented along with links to the original documents and the generated queries, enabling users to dissect and leverage the information for their unique circumstances. The system successfully overcomes two predominant challenges: understanding complex user inputs, and delivering accurate answers, free of hallucinations, that passengers can rely on for making informed decisions. A user study comparing the chatbot to a Google search demonstrated the chatbot's usefulness and ease of use. Beyond the primary goal of providing accurate and timely information to air passengers regarding their rights, we hope that this system will also enable further research exploring the tradeoff between the user-friendly conversational interface of chatbots and the accuracy of retrieval systems.