 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquivalence Between SE(3) Equivariant Networks via Steerable Kernels and Group Convolution
Nov 29, 2022A wide range of techniques have been proposed in recent years for designing neural networks for 3D data that are equivariant under rotation and translation of the input. Most approaches for equivariance under the Euclidean group $\mathrm{SE}(3)$ of rotations and translations fall within one of the two major categories. The first category consists of methods that use $\mathrm{SE}(3)$-convolution which generalizes classical $\mathbb{R}^3$-convolution on signals over $\mathrm{SE}(3)$. Alternatively, it is possible to use \textit{steerable convolution} which achieves $\mathrm{SE}(3)$-equivariance by imposing constraints on $\mathbb{R}^3$-convolution of tensor fields. It is known by specialists in the field that the two approaches are equivalent, with steerable convolution being the Fourier transform of $\mathrm{SE}(3)$ convolution. Unfortunately, these results are not widely known and moreover the exact relations between deep learning architectures built upon these two approaches have not been precisely described in the literature on equivariant deep learning. In this work we provide an in-depth analysis of both methods and their equivalence and relate the two constructions to multiview convolutional networks. Furthermore, we provide theoretical justifications of separability of $\mathrm{SE}(3)$ group convolution, which explain the applicability and success of some recent approaches. Finally, we express different methods using a single coherent formalism and provide explicit formulas that relate the kernels learned by different methods. In this way, our work helps to unify different previously-proposed techniques for achieving roto-translational equivariance, and helps to shed light on both the utility and precise differences between various alternatives. We also derive new TFN non-linearities from our equivalence principle and test them on practical benchmark datasets.
Reduced Representation of Deformation Fields for Effective Non-rigid Shape Matching
Nov 26, 2022



In this work we present a novel approach for computing correspondences between non-rigid objects, by exploiting a reduced representation of deformation fields. Different from existing works that represent deformation fields by training a general-purpose neural network, we advocate for an approximation based on mesh-free methods. By letting the network learn deformation parameters at a sparse set of positions in space (nodes), we reconstruct the continuous deformation field in a closed-form with guaranteed smoothness. With this reduction in degrees of freedom, we show significant improvement in terms of data-efficiency thus enabling limited supervision. Furthermore, our approximation provides direct access to first-order derivatives of deformation fields, which facilitates enforcing desirable regularization effectively. Our resulting model has high expressive power and is able to capture complex deformations. We illustrate its effectiveness through state-of-the-art results across multiple deformable shape matching benchmarks. Our code and data are publicly available at: https://github.com/Sentient07/DeformationBasis.
Learning Multi-resolution Functional Maps with Spectral Attention for Robust Shape Matching
Oct 12, 2022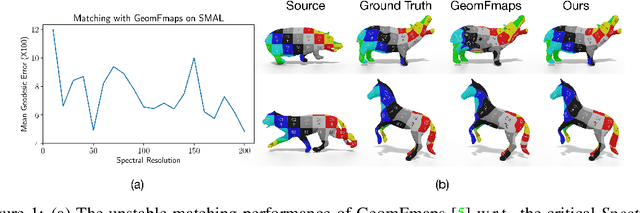
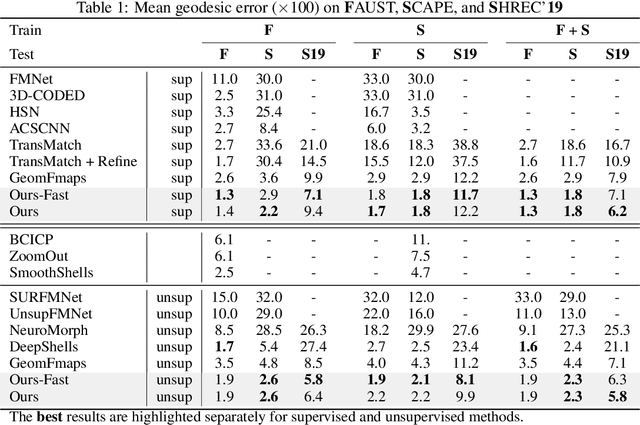
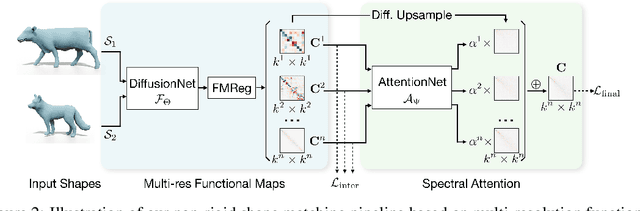
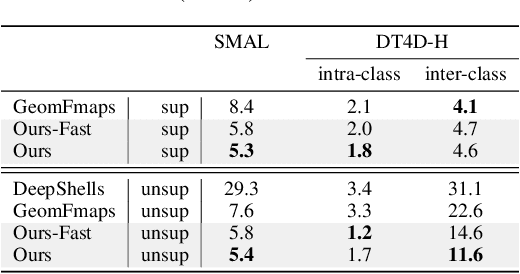
In this work, we present a novel non-rigid shape matching framework based on multi-resolution functional maps with spectral attention. Existing functional map learning methods all rely on the critical choice of the spectral resolution hyperparameter, which can severely affect the overall accuracy or lead to overfitting, if not chosen carefully. In this paper, we show that spectral resolution tuning can be alleviated by introducing spectral attention. Our framework is applicable in both supervised and unsupervised settings, and we show that it is possible to train the network so that it can adapt the spectral resolution, depending on the given shape input. More specifically, we propose to compute multi-resolution functional maps that characterize correspondence across a range of spectral resolutions, and introduce a spectral attention network that helps to combine this representation into a single coherent final correspondence. Our approach is not only accurate with near-isometric input, for which a high spectral resolution is typically preferred, but also robust and able to produce reasonable matching even in the presence of significant non-isometric distortion, which poses great challenges to existing methods. We demonstrate the superior performance of our approach through experiments on a suite of challenging near-isometric and non-isometric shape matching benchmarks.
Smooth Non-Rigid Shape Matching via Effective Dirichlet Energy Optimization
Oct 05, 2022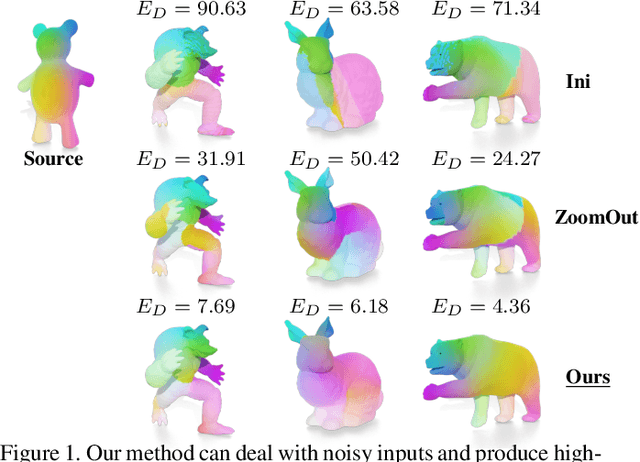
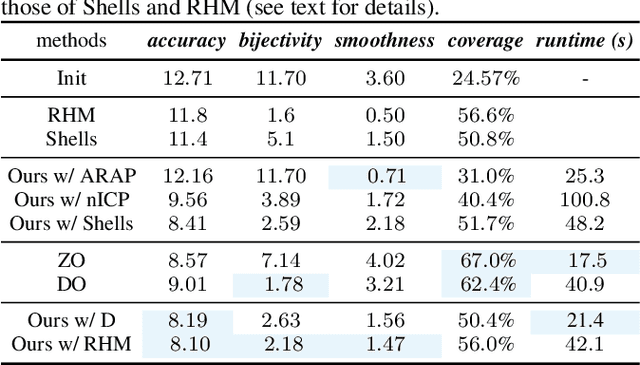
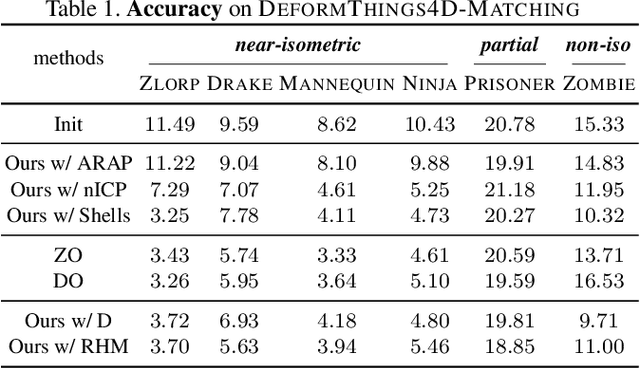

We introduce pointwise map smoothness via the Dirichlet energy into the functional map pipeline, and propose an algorithm for optimizing it efficiently, which leads to high-quality results in challenging settings. Specifically, we first formulate the Dirichlet energy of the pulled-back shape coordinates, as a way to evaluate smoothness of a pointwise map across discrete surfaces. We then extend the recently proposed discrete solver and show how a strategy based on auxiliary variable reformulation allows us to optimize pointwise map smoothness alongside desirable functional map properties such as bijectivity. This leads to an efficient map refinement strategy that simultaneously improves functional and point-to-point correspondences, obtaining smooth maps even on non-isometric shape pairs. Moreover, we demonstrate that several previously proposed methods for computing smooth maps can be reformulated as variants of our approach, which allows us to compare different formulations in a consistent framework. Finally, we compare these methods both on existing benchmarks and on a new rich dataset that we introduce, which contains non-rigid, non-isometric shape pairs with inter-category and cross-category correspondences. Our work leads to a general framework for optimizing and analyzing map smoothness both conceptually and in challenging practical settings.
Affection: Learning Affective Explanations for Real-World Visual Data
Oct 04, 2022
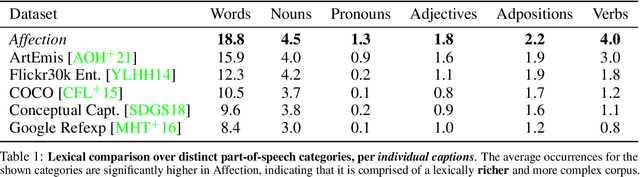
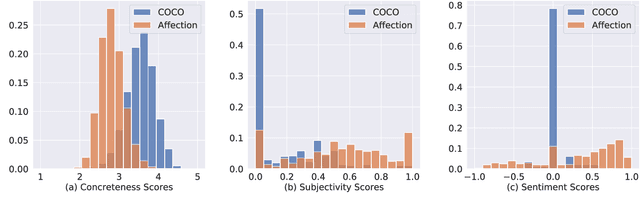
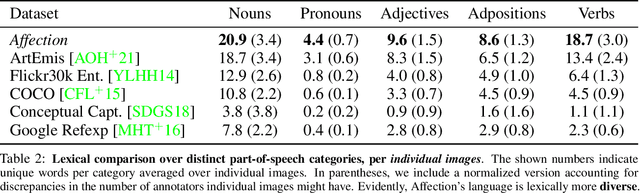
In this work, we explore the emotional reactions that real-world images tend to induce by using natural language as the medium to express the rationale behind an affective response to a given visual stimulus. To embark on this journey, we introduce and share with the research community a large-scale dataset that contains emotional reactions and free-form textual explanations for 85,007 publicly available images, analyzed by 6,283 annotators who were asked to indicate and explain how and why they felt in a particular way when observing a specific image, producing a total of 526,749 responses. Even though emotional reactions are subjective and sensitive to context (personal mood, social status, past experiences) - we show that there is significant common ground to capture potentially plausible emotional responses with a large support in the subject population. In light of this crucial observation, we ask the following questions: i) Can we develop multi-modal neural networks that provide reasonable affective responses to real-world visual data, explained with language? ii) Can we steer such methods towards producing explanations with varying degrees of pragmatic language or justifying different emotional reactions while adapting to the underlying visual stimulus? Finally, iii) How can we evaluate the performance of such methods for this novel task? With this work, we take the first steps in addressing all of these questions, thus paving the way for richer, more human-centric, and emotionally-aware image analysis systems. Our introduced dataset and all developed methods are available on https://affective-explanations.org
SRFeat: Learning Locally Accurate and Globally Consistent Non-Rigid Shape Correspondence
Sep 16, 2022
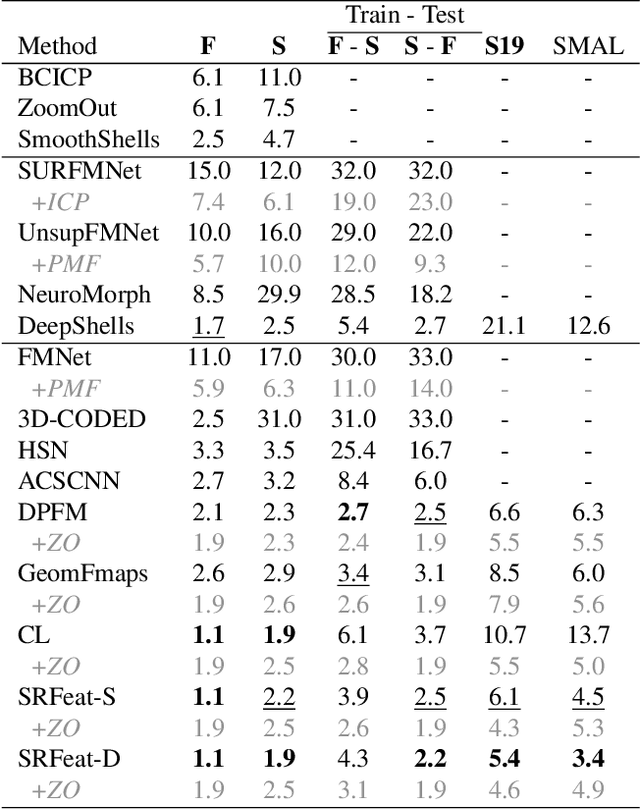
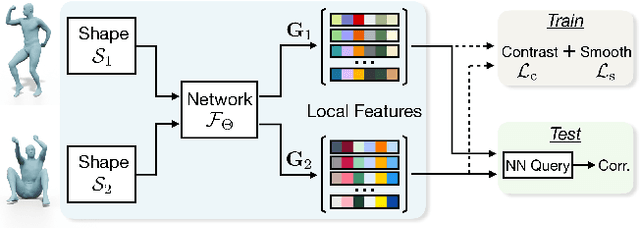
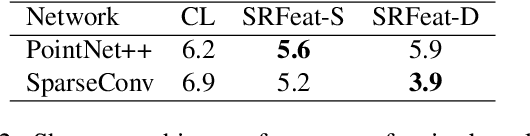
In this work, we present a novel learning-based framework that combines the local accuracy of contrastive learning with the global consistency of geometric approaches, for robust non-rigid matching. We first observe that while contrastive learning can lead to powerful point-wise features, the learned correspondences commonly lack smoothness and consistency, owing to the purely combinatorial nature of the standard contrastive losses. To overcome this limitation we propose to boost contrastive feature learning with two types of smoothness regularization that inject geometric information into correspondence learning. With this novel combination in hand, the resulting features are both highly discriminative across individual points, and, at the same time, lead to robust and consistent correspondences, through simple proximity queries. Our framework is general and is applicable to local feature learning in both the 3D and 2D domains. We demonstrate the superiority of our approach through extensive experiments on a wide range of challenging matching benchmarks, including 3D non-rigid shape correspondence and 2D image keypoint matching.
Non-Isometric Shape Matching via Functional Maps on Landmark-Adapted Bases
May 10, 2022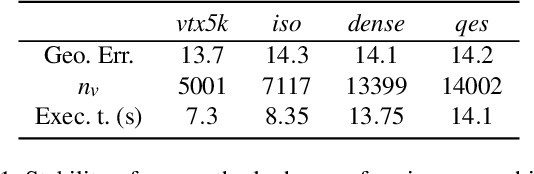
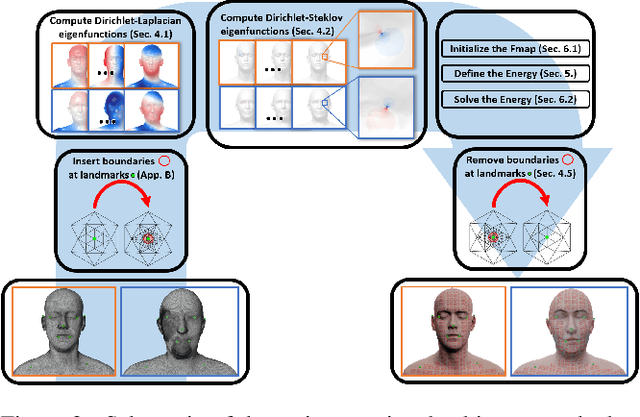
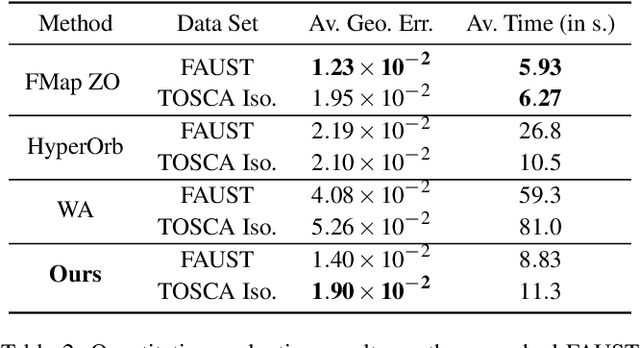
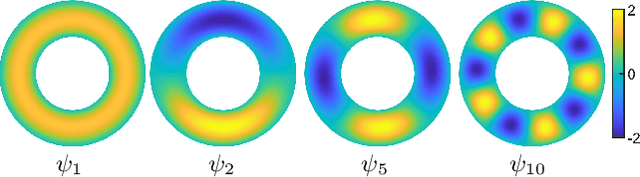
We propose a principled approach for non-isometric landmark-preserving non-rigid shape matching. Our method is based on the functional maps framework, but rather than promoting isometries we focus instead on near-conformal maps that preserve landmarks exactly. We achieve this, first, by introducing a novel landmark-adapted basis using an intrinsic Dirichlet-Steklov eigenproblem. Second, we establish the functional decomposition of conformal maps expressed in this basis. Finally, we formulate a conformally-invariant energy that promotes high-quality landmark-preserving maps, and show how it can be solved via a variant of the recently proposed ZoomOut method that we extend to our setting. Our method is descriptor-free, efficient and robust to significant mesh variability. We evaluate our approach on a range of benchmark datasets and demonstrate state-of-the-art performance on non-isometric benchmarks and near state-of-the-art performance on isometric ones.
Deep Orientation-Aware Functional Maps: Tackling Symmetry Issues in Shape Matching
Apr 28, 2022
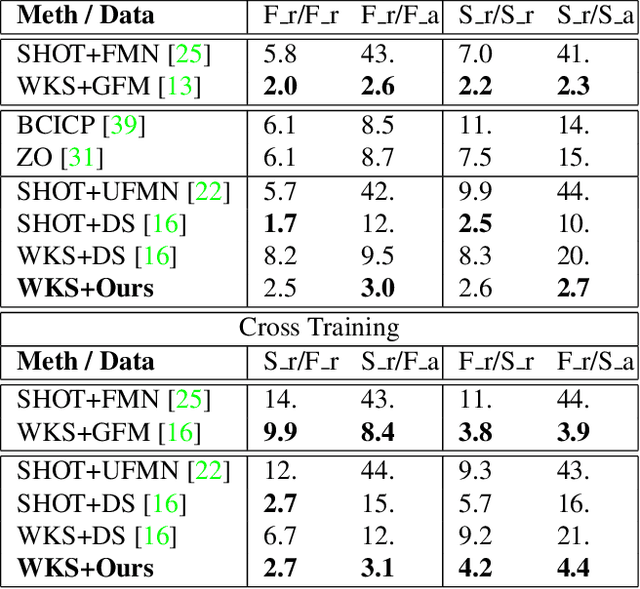
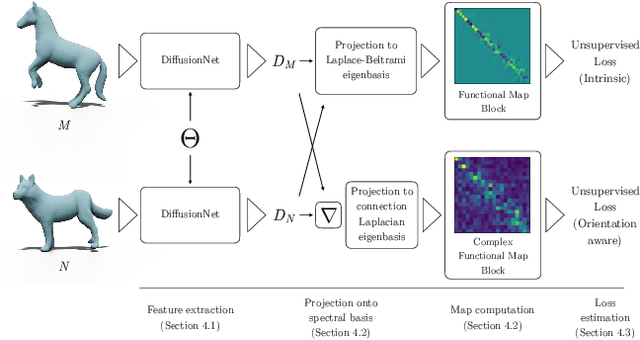
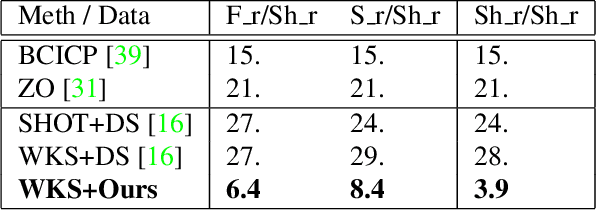
State-of-the-art fully intrinsic networks for non-rigid shape matching often struggle to disambiguate the symmetries of the shapes leading to unstable correspondence predictions. Meanwhile, recent advances in the functional map framework allow to enforce orientation preservation using a functional representation for tangent vector field transfer, through so-called complex functional maps. Using this representation, we propose a new deep learning approach to learn orientation-aware features in a fully unsupervised setting. Our architecture is built on top of DiffusionNet, making it robust to discretization changes. Additionally, we introduce a vector field-based loss, which promotes orientation preservation without using (often unstable) extrinsic descriptors.
Implicit field supervision for robust non-rigid shape matching
Mar 16, 2022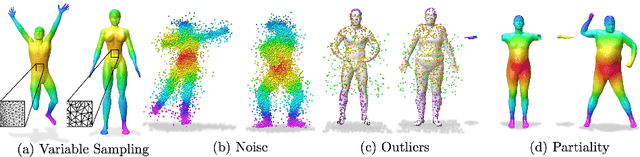
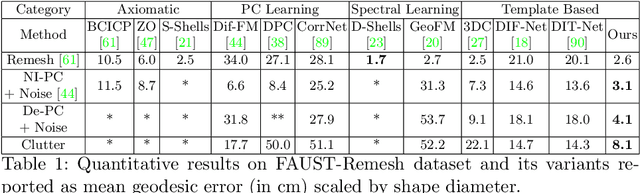
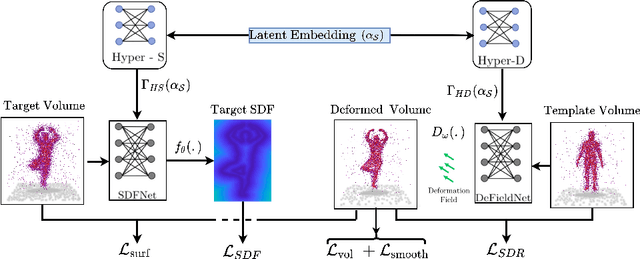
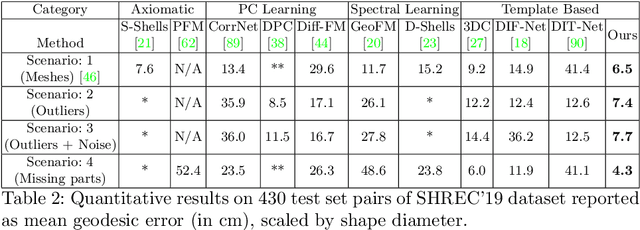
Establishing a correspondence between two non-rigidly deforming shapes is one of the most fundamental problems in visual computing. Existing methods often show weak resilience when presented with challenges innate to real-world data such as noise, outliers, self-occlusion etc. On the other hand, auto-decoders have demonstrated strong expressive power in learning geometrically meaningful latent embeddings. However, their use in shape analysis and especially in non-rigid shape correspondence has been limited. In this paper, we introduce an approach based on auto-decoder framework, that learns a continuous shape-wise deformation field over a fixed template. By supervising the deformation field for points on-surface and regularising for points off-surface through a novel Signed Distance Regularisation (SDR), we learn an alignment between the template and shape volumes. Unlike classical correspondence techniques, our method is remarkably robust in the presence of strong artefacts and can be generalised to arbitrary shape categories. Trained on clean water-tight meshes, without any data-augmentation, we demonstrate compelling performance on compromised data and real-world scans.
Complex Functional Maps : a Conformal Link Between Tangent Bundles
Dec 17, 2021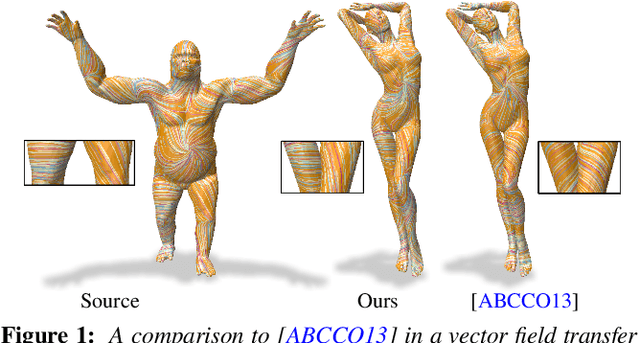

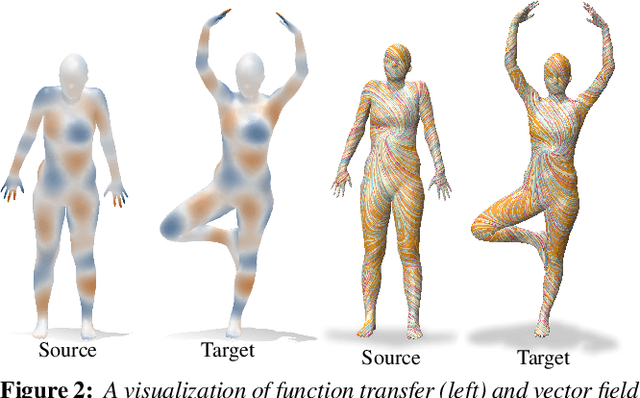
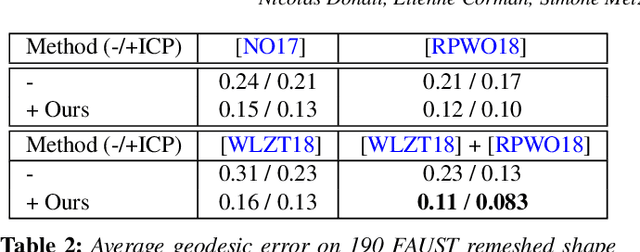
In this paper, we introduce complex functional maps, which extend the functional map framework to conformal maps between tangent vector fields on surfaces. A key property of these maps is their orientation awareness. More specifically, we demonstrate that unlike regular functional maps that link functional spaces of two manifolds, our complex functional maps establish a link between oriented tangent bundles, thus permitting robust and efficient transfer of tangent vector fields. By first endowing and then exploiting the tangent bundle of each shape with a complex structure, the resulting operations become naturally orientationaware, thus favoring orientation and angle preserving correspondence across shapes, without relying on descriptors or extra regularization. Finally, and perhaps more importantly, we demonstrate how these objects enable several practical applications within the functional map framework. We show that functional maps and their complex counterparts can be estimated jointly to promote orientation preservation, regularizing pipelines that previously suffered from orientation-reversing symmetry errors.