 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan we Adopt Self-supervised Pretraining for Chest X-Rays?
Nov 23, 2022



Chest radiograph (or Chest X-Ray, CXR) is a popular medical imaging modality that is used by radiologists across the world to diagnose heart or lung conditions. Over the last decade, Convolutional Neural Networks (CNN), have seen success in identifying pathologies in CXR images. Typically, these CNNs are pretrained on the standard ImageNet classification task, but this assumes availability of large-scale annotated datasets. In this work, we analyze the utility of pretraining on unlabeled ImageNet or Chest X-Ray (CXR) datasets using various algorithms and in multiple settings. Some findings of our work include: (i) supervised training with labeled ImageNet learns strong representations that are hard to beat; (ii) self-supervised pretraining on ImageNet (~1M images) shows performance similar to self-supervised pretraining on a CXR dataset (~100K images); and (iii) the CNN trained on supervised ImageNet can be trained further with self-supervised CXR images leading to improvements, especially when the downstream dataset is on the order of a few thousand images.
Language Conditioned Spatial Relation Reasoning for 3D Object Grounding
Nov 17, 2022



Localizing objects in 3D scenes based on natural language requires understanding and reasoning about spatial relations. In particular, it is often crucial to distinguish similar objects referred by the text, such as "the left most chair" and "a chair next to the window". In this work we propose a language-conditioned transformer model for grounding 3D objects and their spatial relations. To this end, we design a spatial self-attention layer that accounts for relative distances and orientations between objects in input 3D point clouds. Training such a layer with visual and language inputs enables to disambiguate spatial relations and to localize objects referred by the text. To facilitate the cross-modal learning of relations, we further propose a teacher-student approach where the teacher model is first trained using ground-truth object labels, and then helps to train a student model using point cloud inputs. We perform ablation studies showing advantages of our approach. We also demonstrate our model to significantly outperform the state of the art on the challenging Nr3D, Sr3D and ScanRefer 3D object grounding datasets.
Unsupervised Audio-Visual Lecture Segmentation
Oct 29, 2022



Over the last decade, online lecture videos have become increasingly popular and have experienced a meteoric rise during the pandemic. However, video-language research has primarily focused on instructional videos or movies, and tools to help students navigate the growing online lectures are lacking. Our first contribution is to facilitate research in the educational domain, by introducing AVLectures, a large-scale dataset consisting of 86 courses with over 2,350 lectures covering various STEM subjects. Each course contains video lectures, transcripts, OCR outputs for lecture frames, and optionally lecture notes, slides, assignments, and related educational content that can inspire a variety of tasks. Our second contribution is introducing video lecture segmentation that splits lectures into bite-sized topics that show promise in improving learner engagement. We formulate lecture segmentation as an unsupervised task that leverages visual, textual, and OCR cues from the lecture, while clip representations are fine-tuned on a pretext self-supervised task of matching the narration with the temporally aligned visual content. We use these representations to generate segments using a temporally consistent 1-nearest neighbor algorithm, TW-FINCH. We evaluate our method on 15 courses and compare it against various visual and textual baselines, outperforming all of them. Our comprehensive ablation studies also identify the key factors driving the success of our approach.
Grounded Video Situation Recognition
Oct 19, 2022
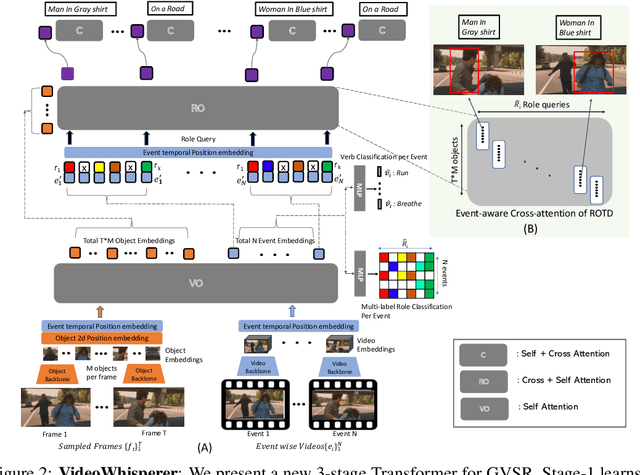


Dense video understanding requires answering several questions such as who is doing what to whom, with what, how, why, and where. Recently, Video Situation Recognition (VidSitu) is framed as a task for structured prediction of multiple events, their relationships, and actions and various verb-role pairs attached to descriptive entities. This task poses several challenges in identifying, disambiguating, and co-referencing entities across multiple verb-role pairs, but also faces some challenges of evaluation. In this work, we propose the addition of spatio-temporal grounding as an essential component of the structured prediction task in a weakly supervised setting, and present a novel three stage Transformer model, VideoWhisperer, that is empowered to make joint predictions. In stage one, we learn contextualised embeddings for video features in parallel with key objects that appear in the video clips to enable fine-grained spatio-temporal reasoning. The second stage sees verb-role queries attend and pool information from object embeddings, localising answers to questions posed about the action. The final stage generates these answers as captions to describe each verb-role pair present in the video. Our model operates on a group of events (clips) simultaneously and predicts verbs, verb-role pairs, their nouns, and their grounding on-the-fly. When evaluated on a grounding-augmented version of the VidSitu dataset, we observe a large improvement in entity captioning accuracy, as well as the ability to localize verb-roles without grounding annotations at training time.
Instruction-driven history-aware policies for robotic manipulations
Sep 22, 2022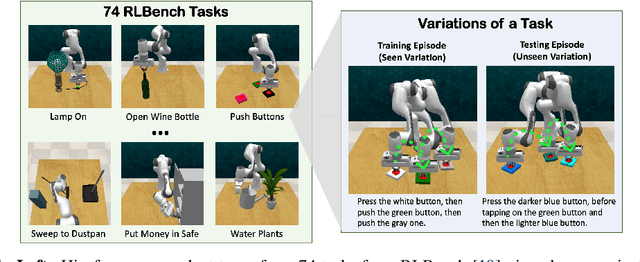
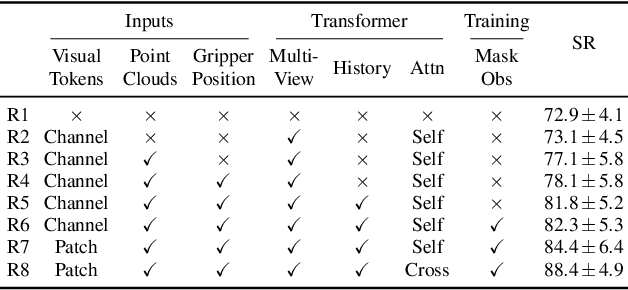
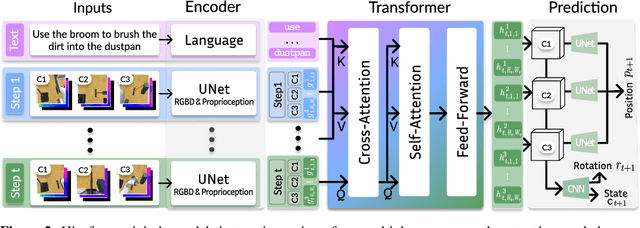
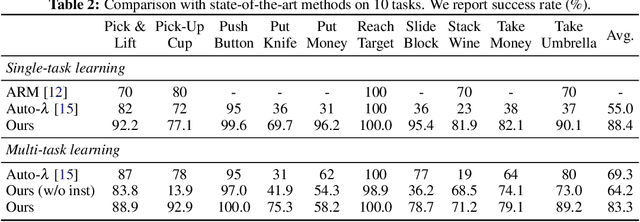
In human environments, robots are expected to accomplish a variety of manipulation tasks given simple natural language instructions. Yet, robotic manipulation is extremely challenging as it requires fine-grained motor control, long-term memory as well as generalization to previously unseen tasks and environments. To address these challenges, we propose a unified transformer-based approach that takes into account multiple inputs. In particular, our transformer architecture integrates (i) natural language instructions and (ii) multi-view scene observations while (iii) keeping track of the full history of observations and actions. Such an approach enables learning dependencies between history and instructions and improves manipulation precision using multiple views. We evaluate our method on the challenging RLBench benchmark and on a real-world robot. Notably, our approach scales to 74 diverse RLBench tasks and outperforms the state of the art. We also address instruction-conditioned tasks and demonstrate excellent generalization to previously unseen variations.
Learning from Unlabeled 3D Environments for Vision-and-Language Navigation
Aug 24, 2022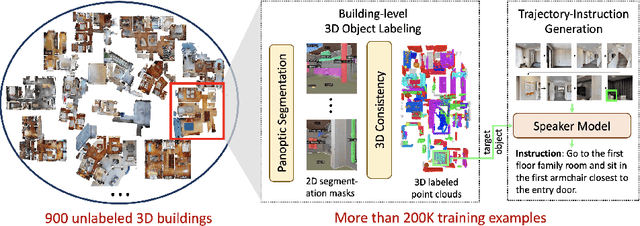
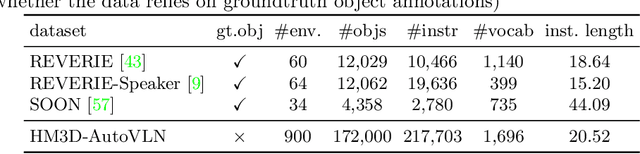
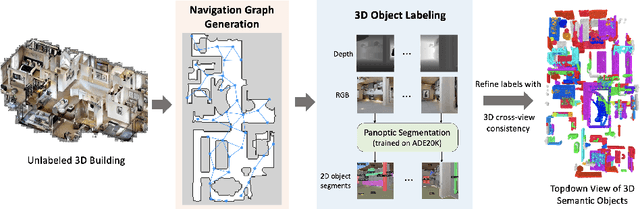
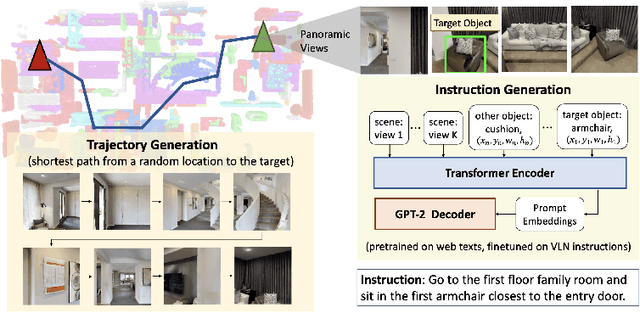
In vision-and-language navigation (VLN), an embodied agent is required to navigate in realistic 3D environments following natural language instructions. One major bottleneck for existing VLN approaches is the lack of sufficient training data, resulting in unsatisfactory generalization to unseen environments. While VLN data is typically collected manually, such an approach is expensive and prevents scalability. In this work, we address the data scarcity issue by proposing to automatically create a large-scale VLN dataset from 900 unlabeled 3D buildings from HM3D. We generate a navigation graph for each building and transfer object predictions from 2D to generate pseudo 3D object labels by cross-view consistency. We then fine-tune a pretrained language model using pseudo object labels as prompts to alleviate the cross-modal gap in instruction generation. Our resulting HM3D-AutoVLN dataset is an order of magnitude larger than existing VLN datasets in terms of navigation environments and instructions. We experimentally demonstrate that HM3D-AutoVLN significantly increases the generalization ability of resulting VLN models. On the SPL metric, our approach improves over state of the art by 7.1% and 8.1% on the unseen validation splits of REVERIE and SOON datasets respectively.
Learning Object Manipulation Skills from Video via Approximate Differentiable Physics
Aug 03, 2022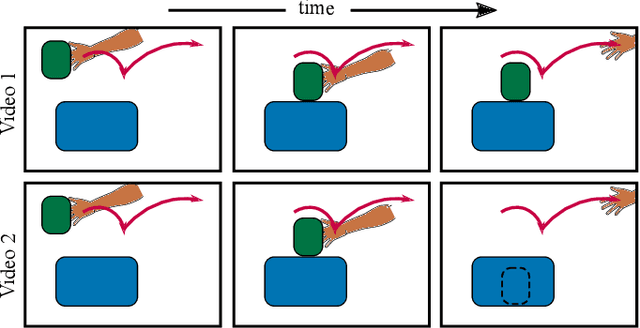
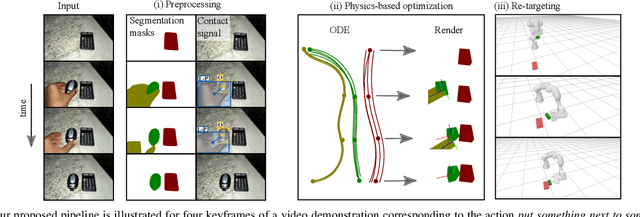


We aim to teach robots to perform simple object manipulation tasks by watching a single video demonstration. Towards this goal, we propose an optimization approach that outputs a coarse and temporally evolving 3D scene to mimic the action demonstrated in the input video. Similar to previous work, a differentiable renderer ensures perceptual fidelity between the 3D scene and the 2D video. Our key novelty lies in the inclusion of a differentiable approach to solve a set of Ordinary Differential Equations (ODEs) that allows us to approximately model laws of physics such as gravity, friction, and hand-object or object-object interactions. This not only enables us to dramatically improve the quality of estimated hand and object states, but also produces physically admissible trajectories that can be directly translated to a robot without the need for costly reinforcement learning. We evaluate our approach on a 3D reconstruction task that consists of 54 video demonstrations sourced from 9 actions such as pull something from right to left or put something in front of something. Our approach improves over previous state-of-the-art by almost 30%, demonstrating superior quality on especially challenging actions involving physical interactions of two objects such as put something onto something. Finally, we showcase the learned skills on a Franka Emika Panda robot.
Think Global, Act Local: Dual-scale Graph Transformer for Vision-and-Language Navigation
Feb 23, 2022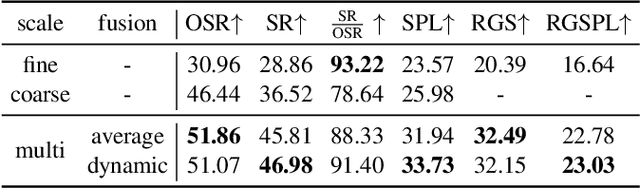
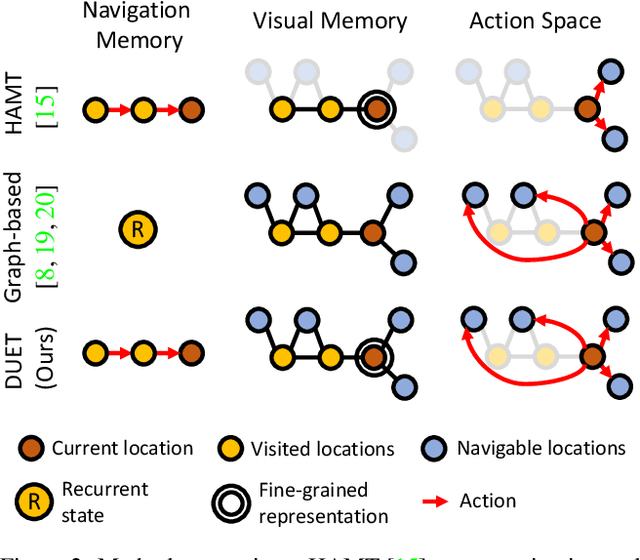
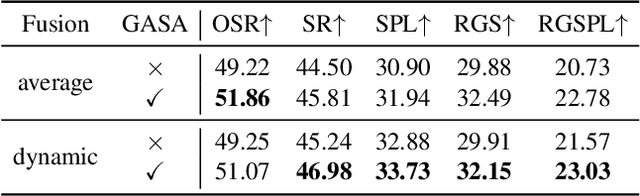
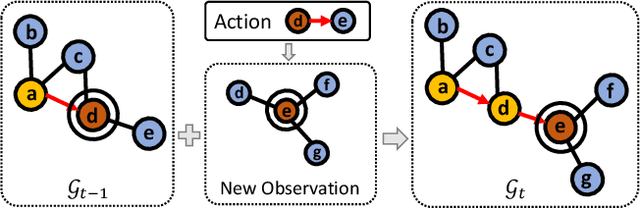
Following language instructions to navigate in unseen environments is a challenging problem for autonomous embodied agents. The agent not only needs to ground languages in visual scenes, but also should explore the environment to reach its target. In this work, we propose a dual-scale graph transformer (DUET) for joint long-term action planning and fine-grained cross-modal understanding. We build a topological map on-the-fly to enable efficient exploration in global action space. To balance the complexity of large action space reasoning and fine-grained language grounding, we dynamically combine a fine-scale encoding over local observations and a coarse-scale encoding on a global map via graph transformers. The proposed approach, DUET, significantly outperforms state-of-the-art methods on goal-oriented vision-and-language navigation (VLN) benchmarks REVERIE and SOON. It also improves the success rate on the fine-grained VLN benchmark R2R.
Feature Generation for Long-tail Classification
Nov 10, 2021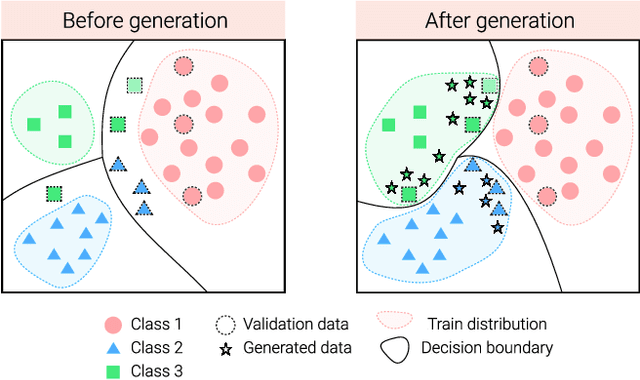
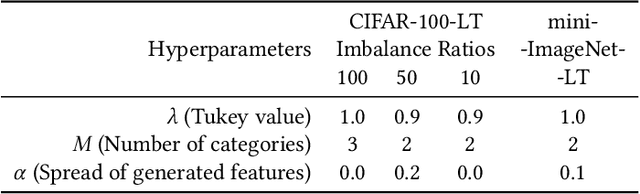
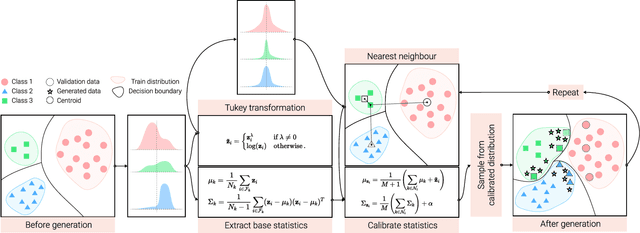
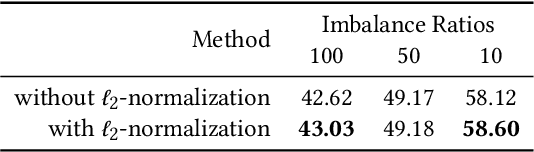
The visual world naturally exhibits an imbalance in the number of object or scene instances resulting in a \emph{long-tailed distribution}. This imbalance poses significant challenges for classification models based on deep learning. Oversampling instances of the tail classes attempts to solve this imbalance. However, the limited visual diversity results in a network with poor representation ability. A simple counter to this is decoupling the representation and classifier networks and using oversampling only to train the classifier. In this paper, instead of repeatedly re-sampling the same image (and thereby features), we explore a direction that attempts to generate meaningful features by estimating the tail category's distribution. Inspired by ideas from recent work on few-shot learning, we create calibrated distributions to sample additional features that are subsequently used to train the classifier. Through several experiments on the CIFAR-100-LT (long-tail) dataset with varying imbalance factors and on mini-ImageNet-LT (long-tail), we show the efficacy of our approach and establish a new state-of-the-art. We also present a qualitative analysis of generated features using t-SNE visualizations and analyze the nearest neighbors used to calibrate the tail class distributions. Our code is available at https://github.com/rahulvigneswaran/TailCalibX.
Airbert: In-domain Pretraining for Vision-and-Language Navigation
Aug 20, 2021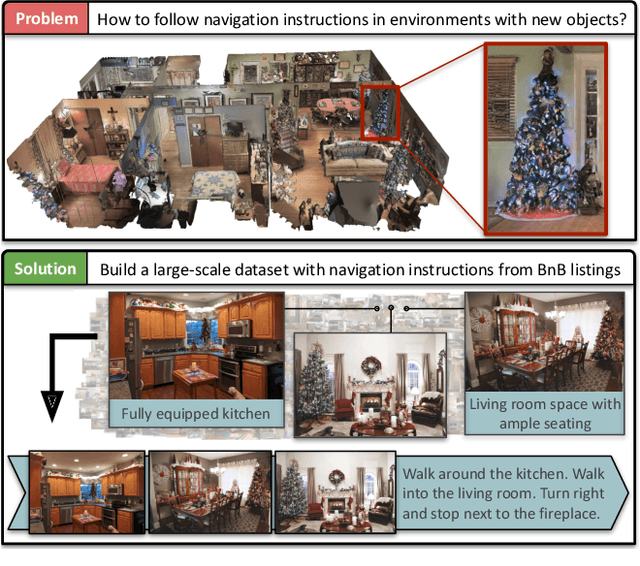

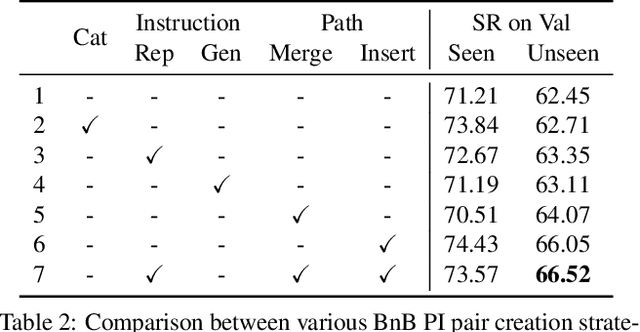
Vision-and-language navigation (VLN) aims to enable embodied agents to navigate in realistic environments using natural language instructions. Given the scarcity of domain-specific training data and the high diversity of image and language inputs, the generalization of VLN agents to unseen environments remains challenging. Recent methods explore pretraining to improve generalization, however, the use of generic image-caption datasets or existing small-scale VLN environments is suboptimal and results in limited improvements. In this work, we introduce BnB, a large-scale and diverse in-domain VLN dataset. We first collect image-caption (IC) pairs from hundreds of thousands of listings from online rental marketplaces. Using IC pairs we next propose automatic strategies to generate millions of VLN path-instruction (PI) pairs. We further propose a shuffling loss that improves the learning of temporal order inside PI pairs. We use BnB pretrain our Airbert model that can be adapted to discriminative and generative settings and show that it outperforms state of the art for Room-to-Room (R2R) navigation and Remote Referring Expression (REVERIE) benchmarks. Moreover, our in-domain pretraining significantly increases performance on a challenging few-shot VLN evaluation, where we train the model only on VLN instructions from a few houses.