 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Bias in Deep Face Analysis: The KANFace Dataset and Empirical Study
May 15, 2020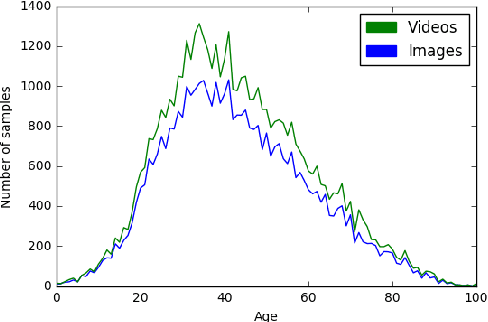
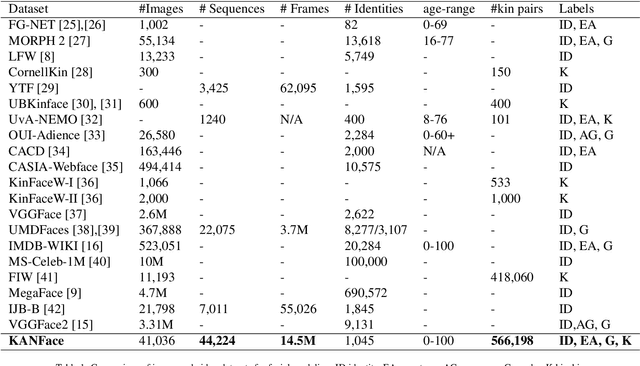

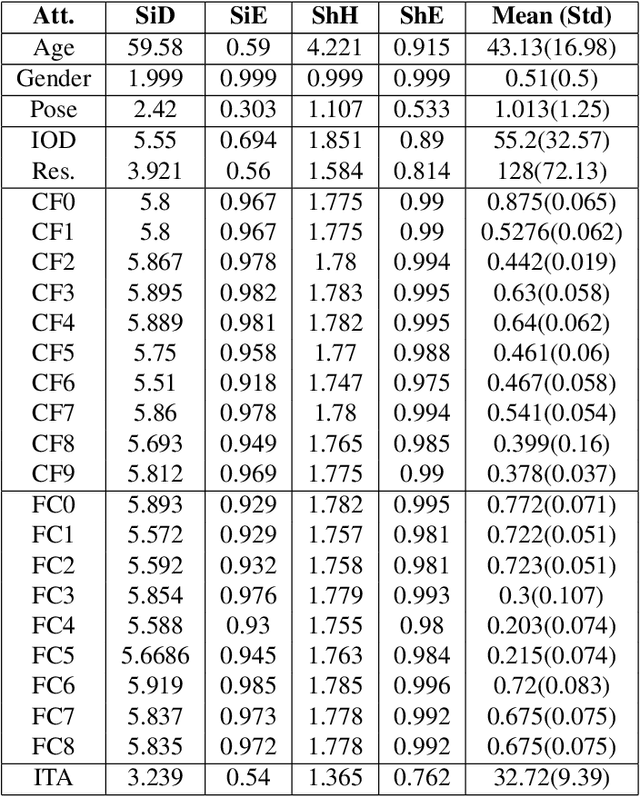
Deep learning-based methods have pushed the limits of the state-of-the-art in face analysis. However, despite their success, these models have raised concerns regarding their bias towards certain demographics. This bias is inflicted both by limited diversity across demographics in the training set, as well as the design of the algorithms. In this work, we investigate the demographic bias of deep learning models in face recognition, age estimation, gender recognition and kinship verification. To this end, we introduce the most comprehensive, large-scale dataset of facial images and videos to date. It consists of 40K still images and 44K sequences (14.5M video frames in total) captured in unconstrained, real-world conditions from 1,045 subjects. The data are manually annotated in terms of identity, exact age, gender and kinship. The performance of state-of-the-art models is scrutinized and demographic bias is exposed by conducting a series of experiments. Lastly, a method to debias network embeddings is introduced and tested on the proposed benchmarks.
Does Visual Self-Supervision Improve Learning of Speech Representations?
May 04, 2020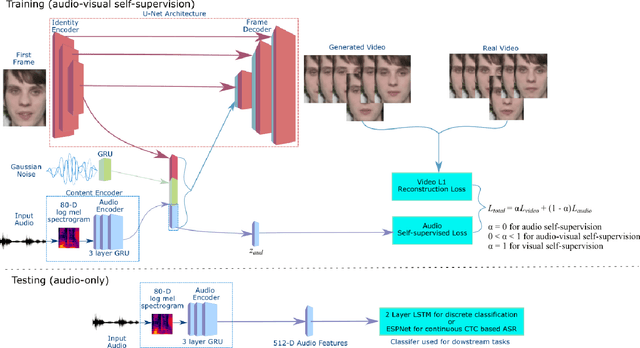
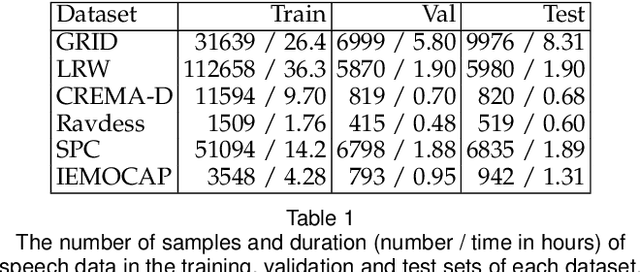
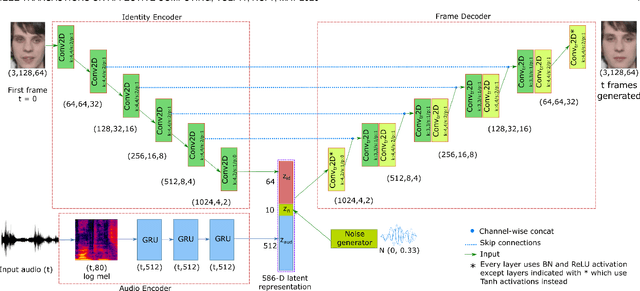
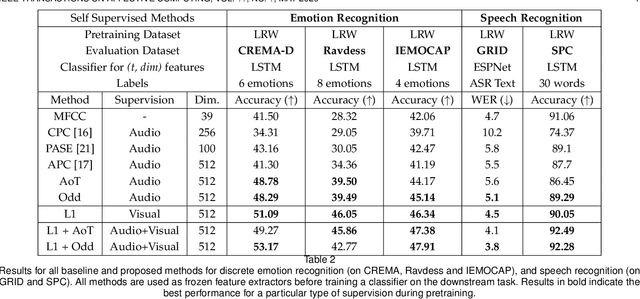
Self-supervised learning has attracted plenty of recent research interest. However, most works are typically unimodal and there has been limited work that studies the interaction between audio and visual modalities for self-supervised learning. This work (1) investigates visual self-supervision via face reconstruction to guide the learning of audio representations; (2) proposes two audio-only self-supervision approaches for speech representation learning; (3) shows that a multi-task combination of the proposed visual and audio self-supervision is beneficial for learning richer features that are more robust in noisy conditions; (4) shows that self-supervised pretraining leads to a superior weight initialization, which is especially useful to prevent overfitting and lead to faster model convergence on smaller sized datasets. We evaluate our audio representations for emotion and speech recognition, achieving state of the art performance for both problems. Our results demonstrate the potential of visual self-supervision for audio feature learning and suggest that joint visual and audio self-supervision leads to more informative speech representations.
Toward fast and accurate human pose estimation via soft-gated skip connections
Feb 25, 2020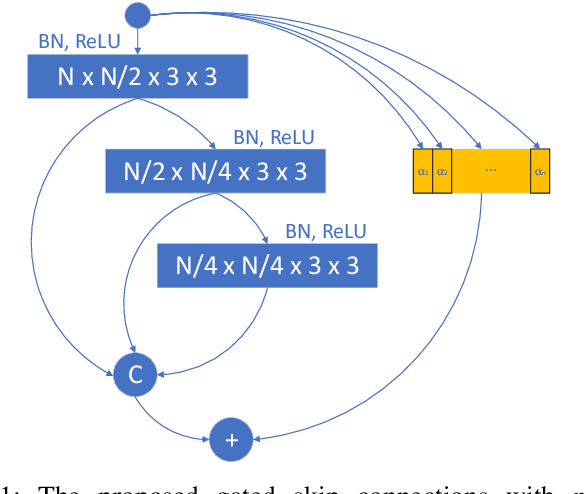
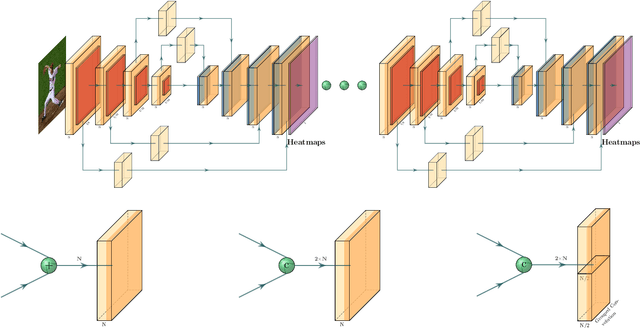

This paper is on highly accurate and highly efficient human pose estimation. Recent works based on Fully Convolutional Networks (FCNs) have demonstrated excellent results for this difficult problem. While residual connections within FCNs have proved to be quintessential for achieving high accuracy, we re-analyze this design choice in the context of improving both the accuracy and the efficiency over the state-of-the-art. In particular, we make the following contributions: (a) We propose gated skip connections with per-channel learnable parameters to control the data flow for each channel within the module within the macro-module. (b) We introduce a hybrid network that combines the HourGlass and U-Net architectures which minimizes the number of identity connections within the network and increases the performance for the same parameter budget. Our model achieves state-of-the-art results on the MPII and LSP datasets. In addition, with a reduction of 3x in model size and complexity, we show no decrease in performance when compared to the original HourGlass network.
Visually Guided Self Supervised Learning of Speech Representations
Feb 20, 2020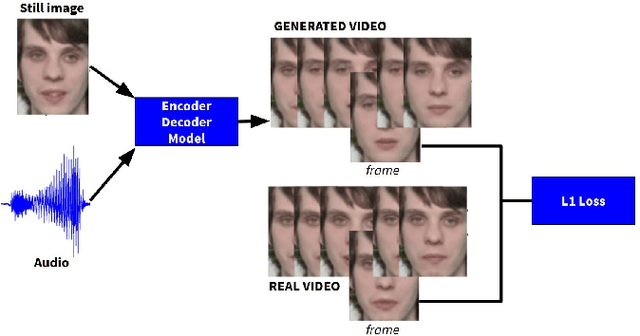
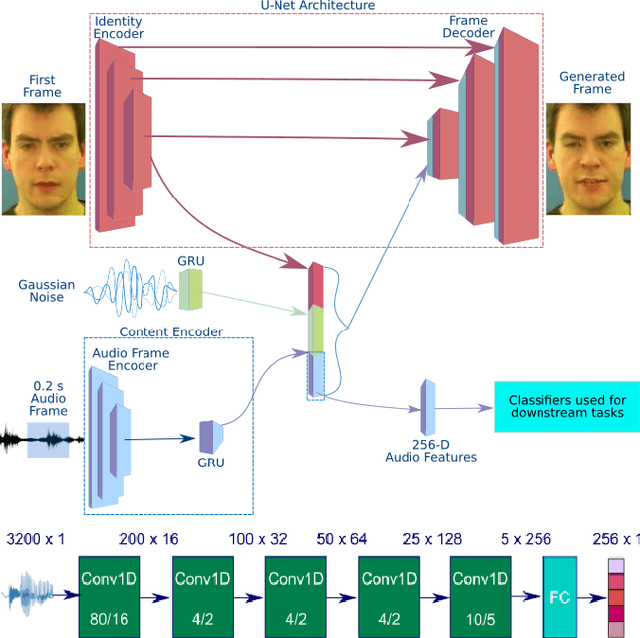
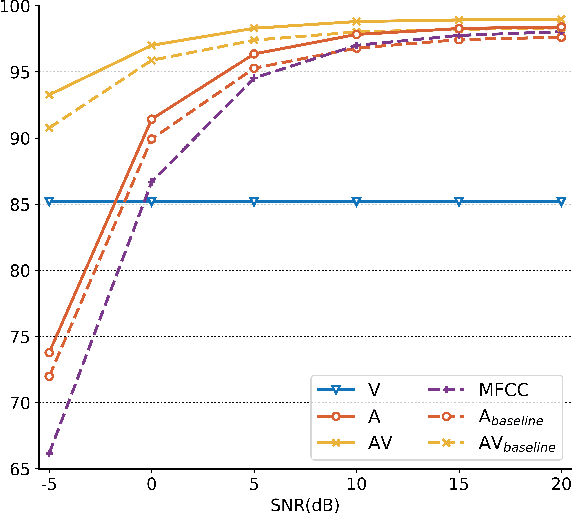
Self supervised representation learning has recently attracted a lot of research interest for both the audio and visual modalities. However, most works typically focus on a particular modality or feature alone and there has been very limited work that studies the interaction between the two modalities for learning self supervised representations. We propose a framework for learning audio representations guided by the visual modality in the context of audiovisual speech. We employ a generative audio-to-video training scheme in which we animate a still image corresponding to a given audio clip and optimize the generated video to be as close as possible to the real video of the speech segment. Through this process, the audio encoder network learns useful speech representations that we evaluate on emotion recognition and speech recognition. We achieve state of the art results for emotion recognition and competitive results for speech recognition. This demonstrates the potential of visual supervision for learning audio representations as a novel way for self-supervised learning which has not been explored in the past. The proposed unsupervised audio features can leverage a virtually unlimited amount of training data of unlabelled audiovisual speech and have a large number of potentially promising applications.
Lipreading using Temporal Convolutional Networks
Jan 23, 2020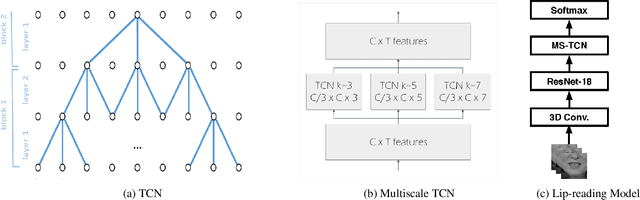


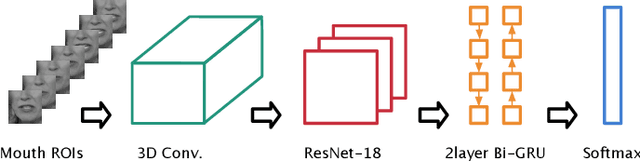
Lip-reading has attracted a lot of research attention lately thanks to advances in deep learning. The current state-of-the-art model for recognition of isolated words in-the-wild consists of a residual network and Bidirectional Gated Recurrent Unit (BGRU) layers. In this work, we address the limitations of this model and we propose changes which further improve its performance. Firstly, the BGRU layers are replaced with Temporal Convolutional Networks (TCN). Secondly, we greatly simplify the training procedure, which allows us to train the model in one single stage. Thirdly, we show that the current state-of-the-art methodology produces models that do not generalize well to variations on the sequence length, and we addresses this issue by proposing a variable-length augmentation. We present results on the largest publicly-available datasets for isolated word recognition in English and Mandarin, LRW and LRW1000, respectively. Our proposed model results in an absolute improvement of 1.2% and 3.2%, respectively, in these datasets which is the new state-of-the-art performance.
Detecting Adversarial Attacks On Audio-Visual Speech Recognition
Dec 18, 2019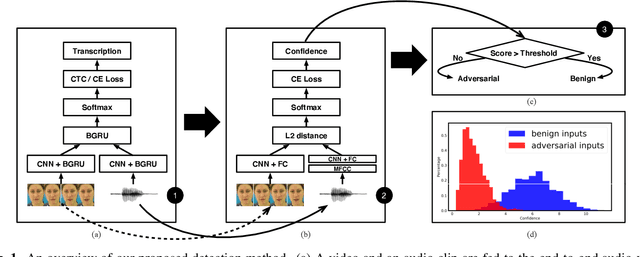
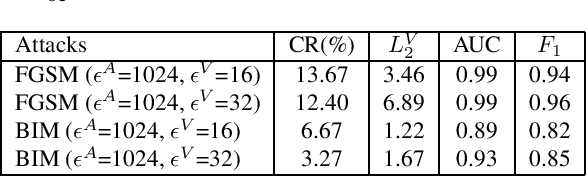

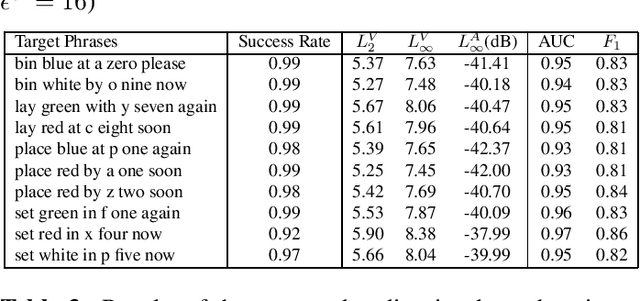
Adversarial attacks pose a threat to deep learning models. However, research on adversarial detection methods, especially in the multi-modal domain, is very limited. In this work, we propose an efficient and straightforward detection method based on the temporal correlation between audio and video streams. The main idea is that the correlation between audio and video in adversarial examples will be lower than benign examples due to added adversarial noise. We use the synchronisation confidence score as a proxy for audio-visual correlation and based on it we can detect adversarial attacks. To the best of our knowledge, this is the first work on detection of adversarial attacks on audio-visual speech recognition models. We apply recent adversarial attacks on two audio-visual speech recognition models trained on the GRID and LRW datasets. The experimental results demonstrated that the proposed approach is an effective way for detecting such attacks.
Speech-driven facial animation using polynomial fusion of features
Dec 12, 2019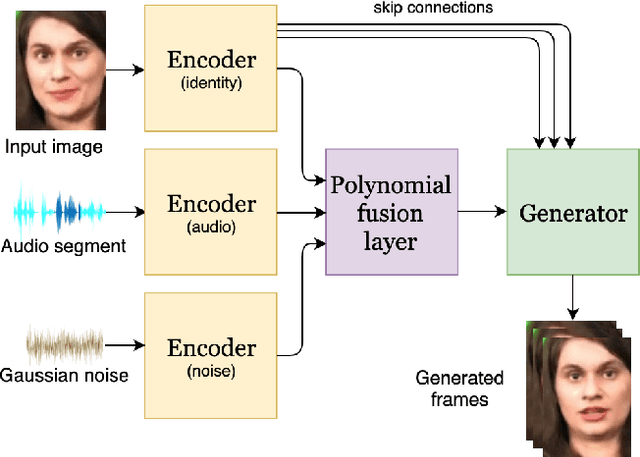
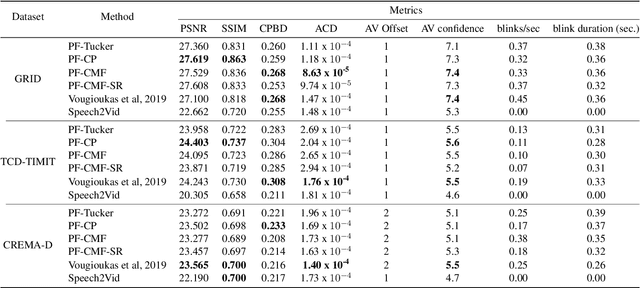
Speech-driven facial animation involves using a speech signal to generate realistic videos of talking faces. Recent deep learning approaches to facial synthesis rely on extracting low-dimensional representations and concatenating them, followed by a decoding step of the concatenated vector. This accounts for only first-order interactions of the features and ignores higher-order interactions. In this paper we propose a polynomial fusion layer that models the joint representation of the encodings by a higher-order polynomial, with the parameters modelled by a tensor decomposition. We demonstrate the the suitability of this approach through experiments on generated videos evaluated on a range of metrics on video quality, audiovisual synchronisation and generation of blinks.
Towards Pose-invariant Lip-Reading
Nov 14, 2019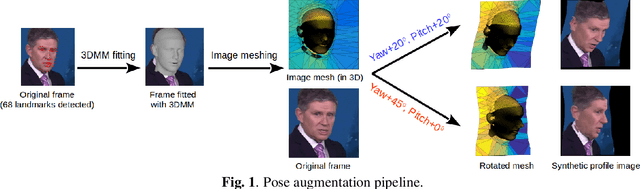
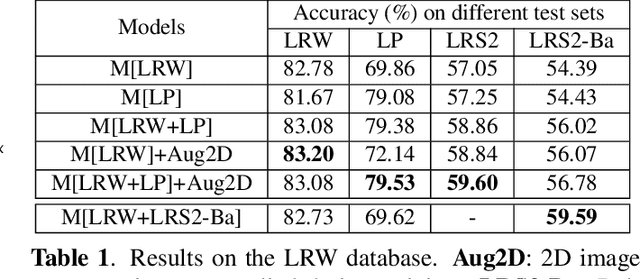
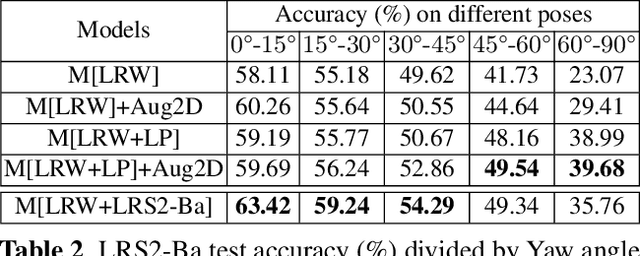
Lip-reading models have been significantly improved recently thanks to powerful deep learning architectures. However, most works focused on frontal or near frontal views of the mouth. As a consequence, lip-reading performance seriously deteriorates in non-frontal mouth views. In this work, we present a framework for training pose-invariant lip-reading models on synthetic data instead of collecting and annotating non-frontal data which is costly and tedious. The proposed model significantly outperforms previous approaches on non-frontal views while retaining the superior performance on frontal and near frontal mouth views. Specifically, we propose to use a 3D Morphable Model (3DMM) to augment LRW, an existing large-scale but mostly frontal dataset, by generating synthetic facial data in arbitrary poses. The newly derived dataset, is used to train a state-of-the-art neural network for lip-reading. We conducted a cross-database experiment for isolated word recognition on the LRS2 dataset, and reported an absolute improvement of 2.55%. The benefit of the proposed approach becomes clearer in extreme poses where an absolute improvement of up to 20.64% over the baseline is achieved.
Shape Constrained Network for Eye Segmentation in the Wild
Oct 11, 2019

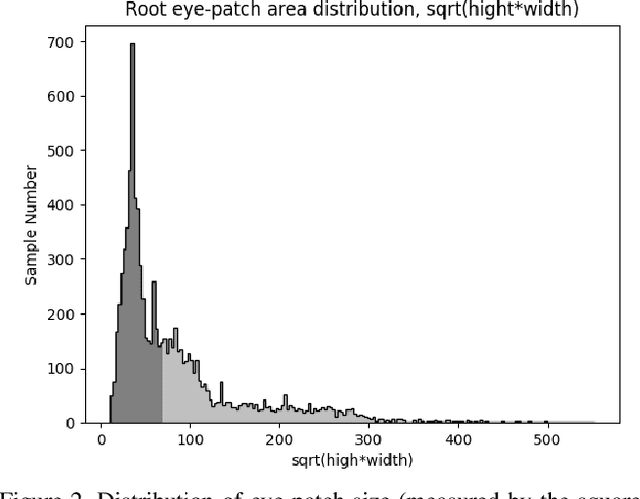
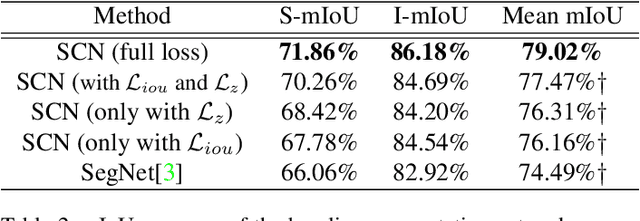
Semantic segmentation of eyes has long been a vital pre-processing step in many biometric applications. Majority of the works focus only on high resolution eye images, while little has been done to segment the eyes from low quality images in the wild. However, this is a particularly interesting and meaningful topic, as eyes play a crucial role in conveying the emotional state and mental well-being of a person. In this work, we take two steps toward solving this problem: (1) We collect and annotate a challenging eye segmentation dataset containing 8882 eye patches from 4461 facial images of different resolutions, illumination conditions and head poses; (2) We develop a novel eye segmentation method, Shape Constrained Network (SCN), that incorporates shape prior into the segmentation network training procedure. Specifically, we learn the shape prior from our dataset using VAE-GAN, and leverage the pre-trained encoder and discriminator to regularise the training of SegNet. To improve the accuracy and quality of predicted masks, we replace the loss of SegNet with three new losses: Intersection-over-Union (IoU) loss, shape discriminator loss and shape embedding loss. Extensive experiments shows that our method outperforms state-of-the-art segmentation and landmark detection methods in terms of mean IoU (mIoU) accuracy and the quality of segmentation masks. The eye segmentation database is available at https://www.dropbox.com/s/yvveouvxsvti08x/Eye_Segmentation_Database.zip?dl=0.
Fast and Effective Adaptation of Facial Action Unit Detection Deep Model
Sep 26, 2019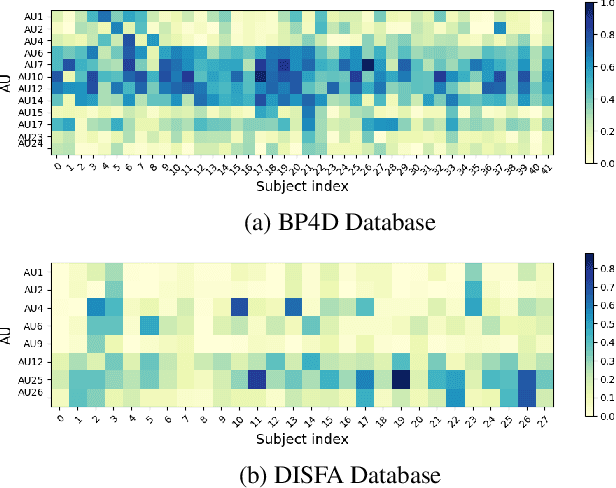
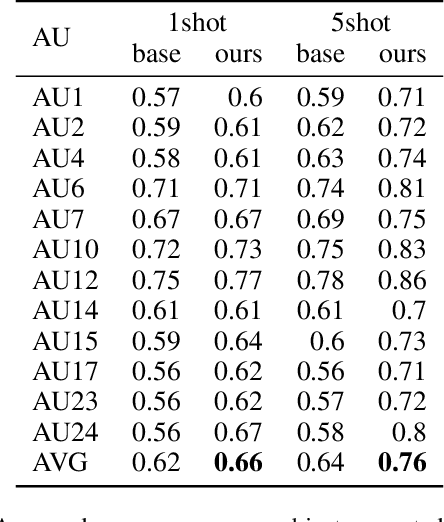
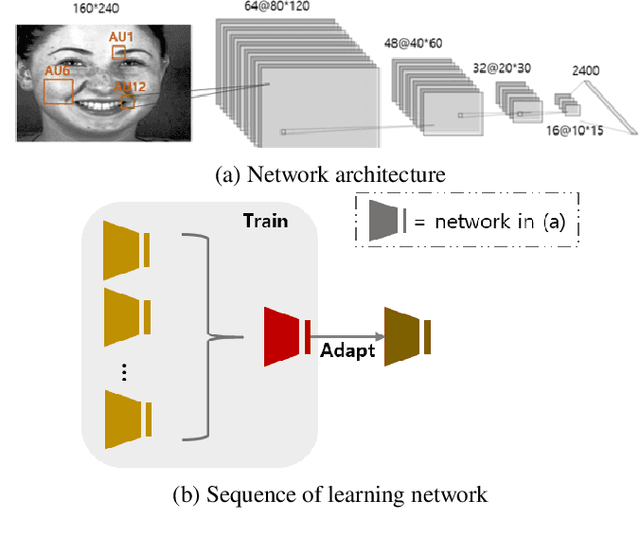
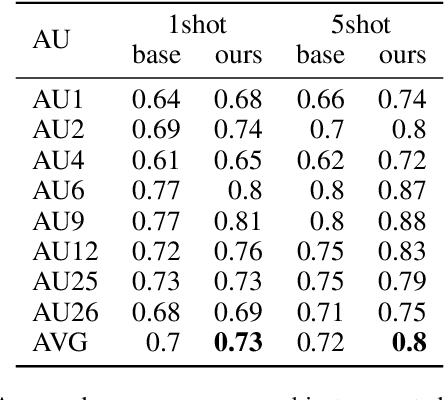
Detecting facial action units (AU) is one of the fundamental steps in automatic recognition of facial expression of emotions and cognitive states. Though there have been a variety of approaches proposed for this task, most of these models are trained only for the specific target AUs, and as such they fail to easily adapt to the task of recognition of new AUs (i.e., those not initially used to train the target models). In this paper, we propose a deep learning approach for facial AU detection that can easily and in a fast manner adapt to a new AU or target subject by leveraging only a few labeled samples from the new task (either an AU or subject). To this end, we propose a modeling approach based on the notion of the model-agnostic meta-learning [C. Finn and Levine, 2017], originally proposed for the general image recognition/detection tasks (e.g., the character recognition from the Omniglot dataset). Specifically, each subject and/or AU is treated as a new learning task and the model learns to adapt based on the knowledge of the previous tasks (the AUs and subjects used to pre-train the target models). Thus, given a new subject or AU, this meta-knowledge (that is shared among training and test tasks) is used to adapt the model to the new task using the notion of deep learning and model-agnostic meta-learning. We show on two benchmark datasets (BP4D and DISFA) for facial AU detection that the proposed approach can be easily adapted to new tasks (AUs/subjects). Using only a few labeled examples from these tasks, the model achieves large improvements over the baselines (i.e., non-adapted models).