 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence
Apr 27, 2026We introduce Nemotron 3 Nano Omni, the latest model in the Nemotron multimodal series and the first to natively support audio inputs alongside text, images, and video. Nemotron 3 Nano Omni delivers consistent accuracy improvements over its predecessor, Nemotron Nano V2 VL, across all modalities, enabled by advances in architecture, training data and recipes. In particular, Nemotron 3 delivers leading results in real-world document understanding, long audio-video comprehension, and agentic computer use. Built on the highly efficient Nemotron 3 Nano 30B-A3B backbone, Nemotron 3 Nano Omni further incorporates innovative multimodal token-reduction techniques to deliver substantially lower inference latency and higher throughput than other models of similar size. We are releasing model checkpoints in BF16, FP8, and FP4 formats, along with portions of the training data and codebase to facilitate further research and development.
Speaker Turn Modeling for Dialogue Act Classification
Sep 10, 2021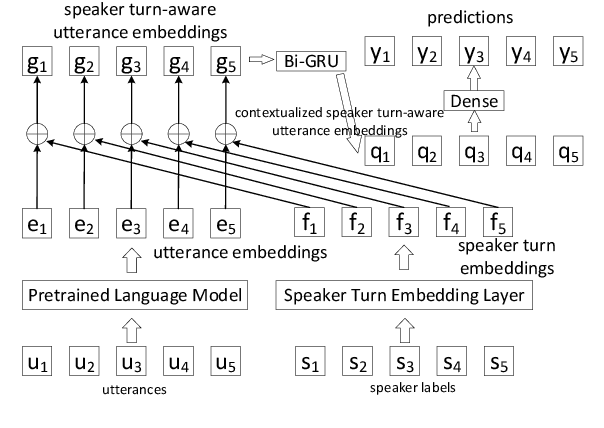

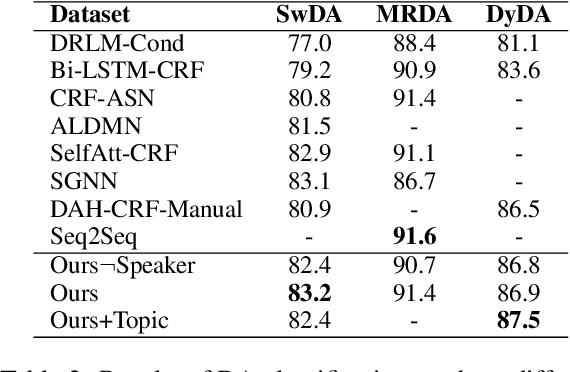
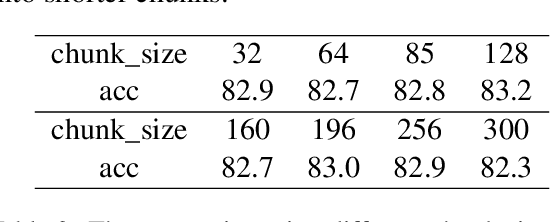
Dialogue Act (DA) classification is the task of classifying utterances with respect to the function they serve in a dialogue. Existing approaches to DA classification model utterances without incorporating the turn changes among speakers throughout the dialogue, therefore treating it no different than non-interactive written text. In this paper, we propose to integrate the turn changes in conversations among speakers when modeling DAs. Specifically, we learn conversation-invariant speaker turn embeddings to represent the speaker turns in a conversation; the learned speaker turn embeddings are then merged with the utterance embeddings for the downstream task of DA classification. With this simple yet effective mechanism, our model is able to capture the semantics from the dialogue content while accounting for different speaker turns in a conversation. Validation on three benchmark public datasets demonstrates superior performance of our model.
AVEC 2019 Workshop and Challenge: State-of-Mind, Detecting Depression with AI, and Cross-Cultural Affect Recognition
Jul 10, 2019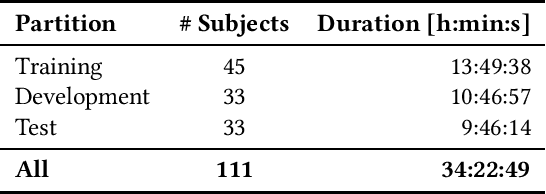
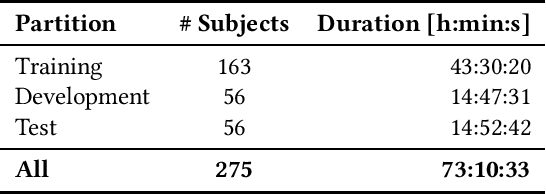
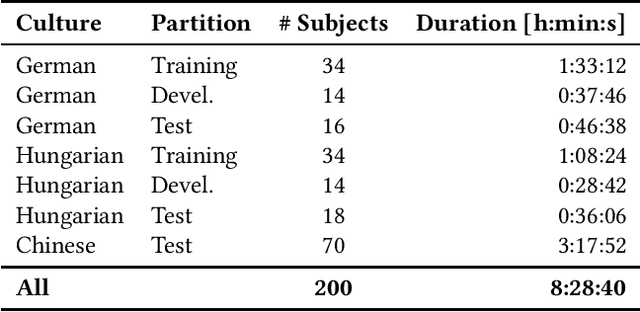
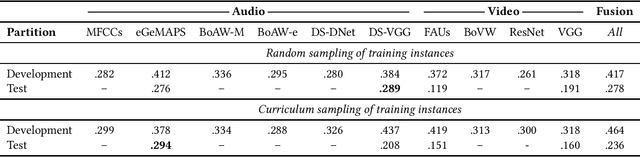
The Audio/Visual Emotion Challenge and Workshop (AVEC 2019) "State-of-Mind, Detecting Depression with AI, and Cross-cultural Affect Recognition" is the ninth competition event aimed at the comparison of multimedia processing and machine learning methods for automatic audiovisual health and emotion analysis, with all participants competing strictly under the same conditions. The goal of the Challenge is to provide a common benchmark test set for multimodal information processing and to bring together the health and emotion recognition communities, as well as the audiovisual processing communities, to compare the relative merits of various approaches to health and emotion recognition from real-life data. This paper presents the major novelties introduced this year, the challenge guidelines, the data used, and the performance of the baseline systems on the three proposed tasks: state-of-mind recognition, depression assessment with AI, and cross-cultural affect sensing, respectively.