 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIE XYZ Net: Unprocessing Images for Low-Level Computer Vision Tasks
Jun 23, 2020



Cameras currently allow access to two image states: (i) a minimally processed linear raw-RGB image state (i.e., raw sensor data) or (ii) a highly-processed nonlinear image state (e.g., sRGB). There are many computer vision tasks that work best with a linear image state, such as image deblurring and image dehazing. Unfortunately, the vast majority of images are saved in the nonlinear image state. Because of this, a number of methods have been proposed to "unprocess" nonlinear images back to a raw-RGB state. However, existing unprocessing methods have a drawback because raw-RGB images are sensor-specific. As a result, it is necessary to know which camera produced the sRGB output and use a method or network tailored for that sensor to properly unprocess it. This paper addresses this limitation by exploiting another camera image state that is not available as an output, but it is available inside the camera pipeline. In particular, cameras apply a colorimetric conversion step to convert the raw-RGB image to a device-independent space based on the CIE XYZ color space before they apply the nonlinear photo-finishing. Leveraging this canonical image state, we propose a deep learning framework, CIE XYZ Net, that can unprocess a nonlinear image back to the canonical CIE XYZ image. This image can then be processed by any low-level computer vision operator and re-rendered back to the nonlinear image. We demonstrate the usefulness of the CIE XYZ Net on several low-level vision tasks and show significant gains that can be obtained by this processing framework. Code and dataset are publicly available at https://github.com/mahmoudnafifi/CIE_XYZ_NET.
NTIRE 2020 Challenge on Real Image Denoising: Dataset, Methods and Results
May 08, 2020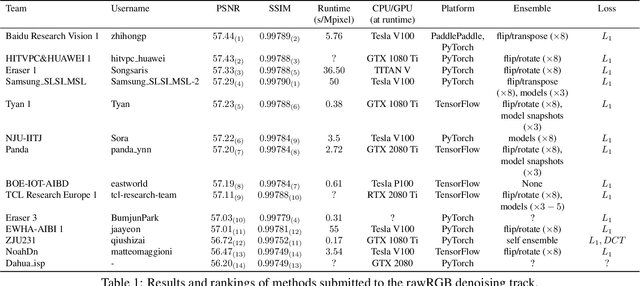
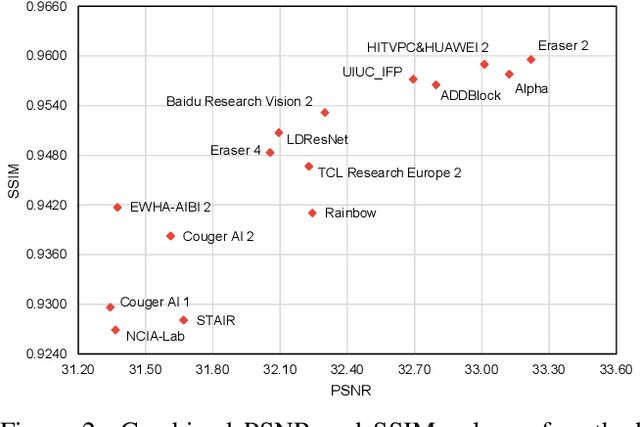
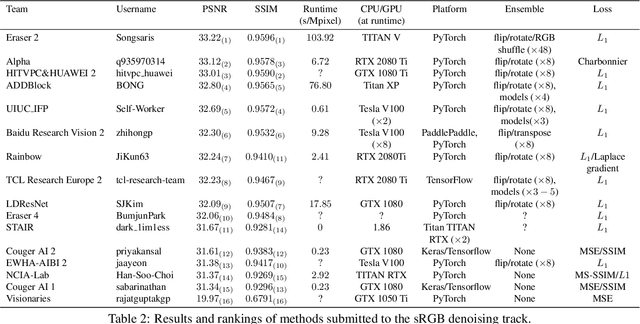
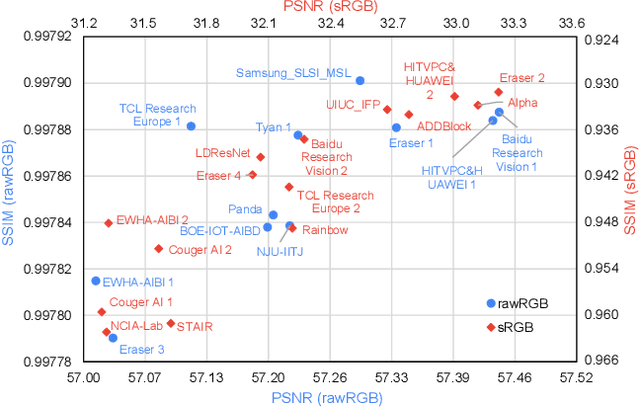
This paper reviews the NTIRE 2020 challenge on real image denoising with focus on the newly introduced dataset, the proposed methods and their results. The challenge is a new version of the previous NTIRE 2019 challenge on real image denoising that was based on the SIDD benchmark. This challenge is based on a newly collected validation and testing image datasets, and hence, named SIDD+. This challenge has two tracks for quantitatively evaluating image denoising performance in (1) the Bayer-pattern rawRGB and (2) the standard RGB (sRGB) color spaces. Each track ~250 registered participants. A total of 22 teams, proposing 24 methods, competed in the final phase of the challenge. The proposed methods by the participating teams represent the current state-of-the-art performance in image denoising targeting real noisy images. The newly collected SIDD+ datasets are publicly available at: https://bit.ly/siddplus_data.
Deep White-Balance Editing
Apr 03, 2020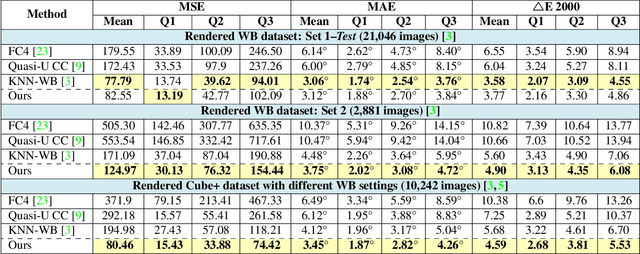
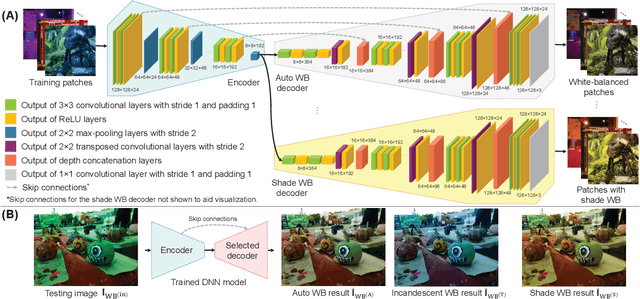

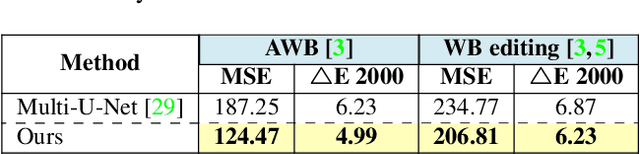
We introduce a deep learning approach to realistically edit an sRGB image's white balance. Cameras capture sensor images that are rendered by their integrated signal processor (ISP) to a standard RGB (sRGB) color space encoding. The ISP rendering begins with a white-balance procedure that is used to remove the color cast of the scene's illumination. The ISP then applies a series of nonlinear color manipulations to enhance the visual quality of the final sRGB image. Recent work by [3] showed that sRGB images that were rendered with the incorrect white balance cannot be easily corrected due to the ISP's nonlinear rendering. The work in [3] proposed a k-nearest neighbor (KNN) solution based on tens of thousands of image pairs. We propose to solve this problem with a deep neural network (DNN) architecture trained in an end-to-end manner to learn the correct white balance. Our DNN maps an input image to two additional white-balance settings corresponding to indoor and outdoor illuminations. Our solution not only is more accurate than the KNN approach in terms of correcting a wrong white-balance setting but also provides the user the freedom to edit the white balance in the sRGB image to other illumination settings.
Learning to Correct Overexposed and Underexposed Photos
Mar 25, 2020
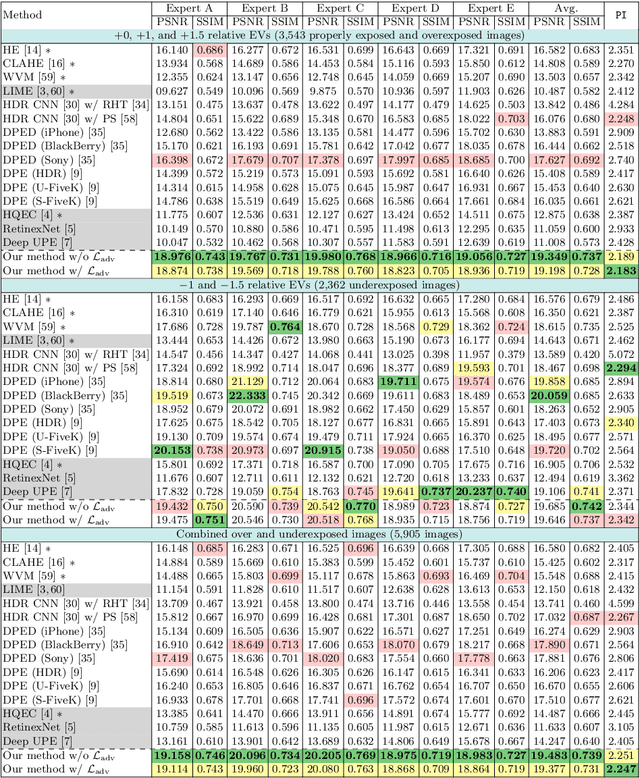
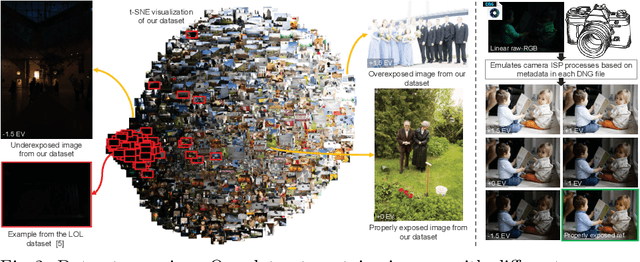

Capturing photographs with wrong exposures remains a major source of errors in camera-based imaging. Exposure problems are categorized as either: (i) overexposed, where the camera exposure was too long, resulting in bright and washed-out image regions, or (ii) underexposed, where the exposure was too short, resulting in dark regions. Both under- and overexposure greatly reduce the contrast and visual appeal of an image. Prior work mainly focuses on underexposed images or general image enhancement. In contrast, our proposed method targets both over- and underexposure errors in photographs. We formulate the exposure correction problem as two main sub-problems: (i) color enhancement and (ii) detail enhancement. Accordingly, we propose a coarse-to-fine deep neural network (DNN) model, trainable in an end-to-end manner, that addresses each sub-problem separately. A key aspect of our solution is a new dataset of over 24,000 images exhibiting a range of exposure values with a corresponding properly exposed image. Our method achieves results on par with existing state-of-the-art methods on underexposed images and yields significant improvements for images suffering from overexposure errors.
What Else Can Fool Deep Learning? Addressing Color Constancy Errors on Deep Neural Network Performance
Dec 15, 2019There is active research targeting local image manipulations that can fool deep neural networks (DNNs) into producing incorrect results. This paper examines a type of global image manipulation that can produce similar adverse effects. Specifically, we explore how strong color casts caused by incorrectly applied computational color constancy - referred to as white balance (WB) in photography - negatively impact the performance of DNNs targeting image segmentation and classification. In addition, we discuss how existing image augmentation methods used to improve the robustness of DNNs are not well suited for modeling WB errors. To address this problem, a novel augmentation method is proposed that can emulate accurate color constancy degradation. We also explore pre-processing training and testing images with a recent WB correction algorithm to reduce the effects of incorrectly white-balanced images. We examine both augmentation and pre-processing strategies on different datasets and demonstrate notable improvements on the CIFAR-10, CIFAR-100, and ADE20K datasets.
Sensor-Independent Illumination Estimation for DNN Models
Dec 14, 2019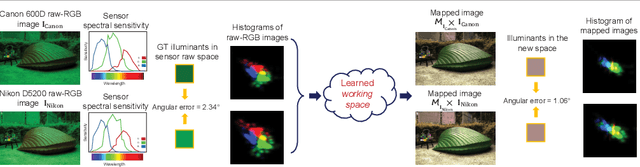

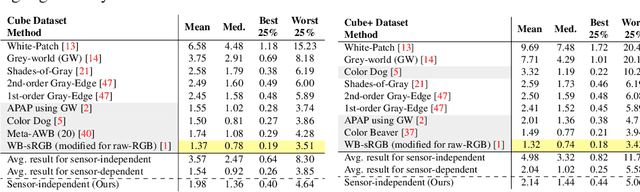
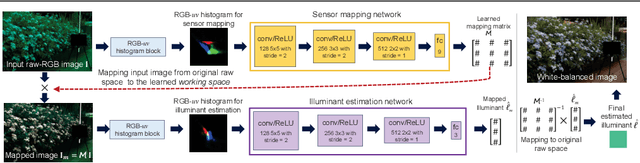
While modern deep neural networks (DNNs) achieve state-of-the-art results for illuminant estimation, it is currently necessary to train a separate DNN for each type of camera sensor. This means when a camera manufacturer uses a new sensor, it is necessary to retrain an existing DNN model with training images captured by the new sensor. This paper addresses this problem by introducing a novel sensor-independent illuminant estimation framework. Our method learns a sensor-independent working space that can be used to canonicalize the RGB values of any arbitrary camera sensor. Our learned space retains the linear property of the original sensor raw-RGB space and allows unseen camera sensors to be used on a single DNN model trained on this working space. We demonstrate the effectiveness of this approach on several different camera sensors and show it provides performance on par with state-of-the-art methods that were trained per sensor.
11K Hands: Gender recognition and biometric identification using a large dataset of hand images
Sep 17, 2018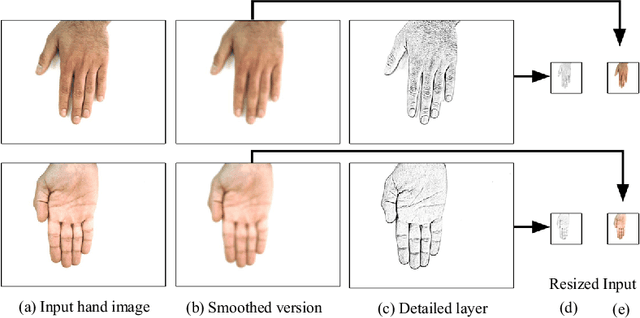
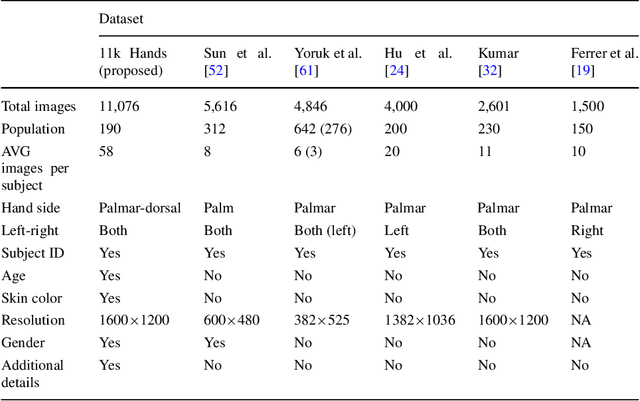
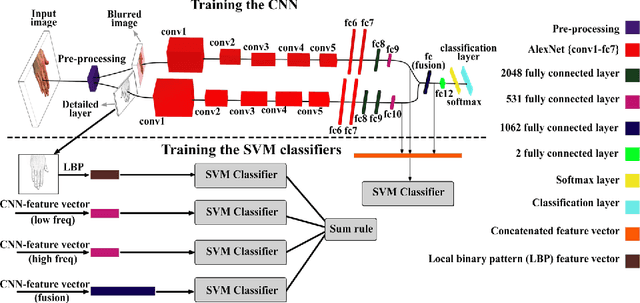
The human hand possesses distinctive features which can reveal gender information. In addition, the hand is considered one of the primary biometric traits used to identify a person. In this work, we propose a large dataset of human hand images (dorsal and palmar sides) with detailed ground-truth information for gender recognition and biometric identification. Using this dataset, a convolutional neural network (CNN) can be trained effectively for the gender recognition task. Based on this, we design a two-stream CNN to tackle the gender recognition problem. This trained model is then used as a feature extractor to feed a set of support vector machine classifiers for the biometric identification task. We show that the dorsal side of hand images, captured by a regular digital camera, convey effective distinctive features similar to, if not better, those available in the palmar hand images. To facilitate access to the proposed dataset and replication of our experiments, the dataset, trained CNN models, and Matlab source code are available at (https://goo.gl/rQJndd).
The Achievement of Higher Flexibility in Multiple Choice-based Tests Using Image Classification Techniques
Aug 04, 2018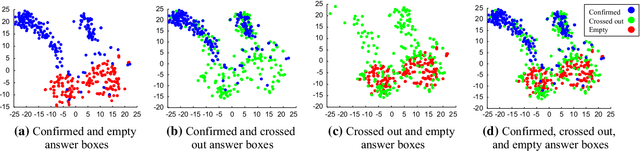
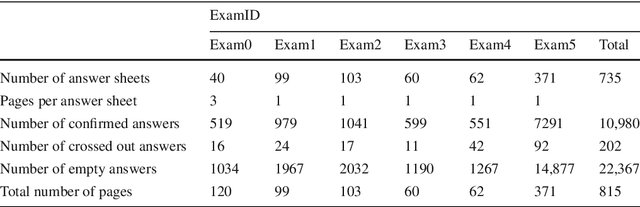
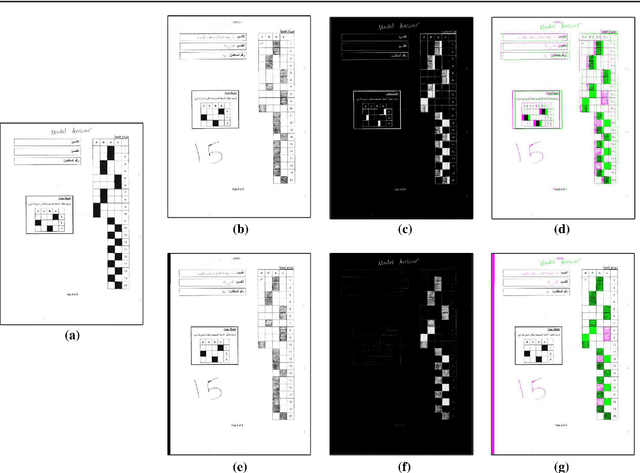
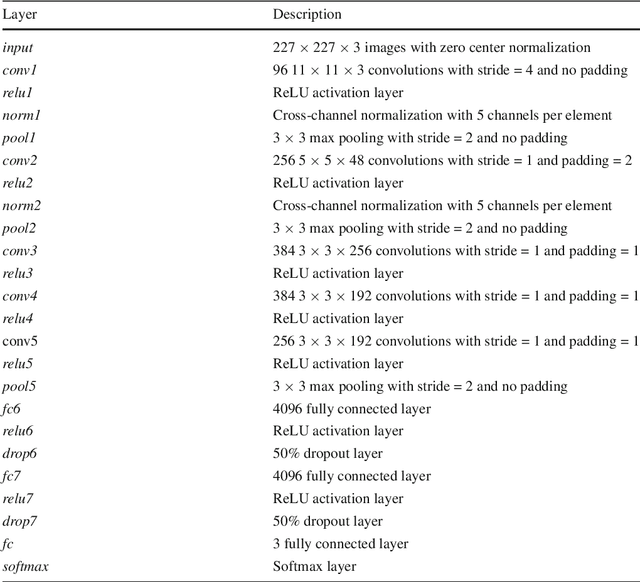
In spite of the high accuracy of the existing optical mark reading (OMR) systems and devices, a few restrictions remain existent. In this work, we aim to reduce the restrictions of multiple choice questions (MCQ) within tests. We use an image registration technique to extract the answer boxes from the answer sheets. Unlike other systems that rely on simple image processing steps to recognize the extracted answer boxes, we address the problem from another perspective by training a classifier to recognize the class of each answer box (i.e., confirmed, crossed out, and blank answer). This gives us the ability to deal with a variety of shading and mark patterns, and distinguish between chosen and canceled answers. All existing machine learning techniques require a large number of examples in order to train the classifier, therefore we present a dataset that consists of six real MCQ assessments that have different answer sheet templates. We evaluate two strategies of classification: a straight-forward approach and a two-stage classifier approach. We test two handcrafted feature methods and a convolutional neural network. At the end, we present an easy-to-use graphical user interface of the proposed system. Compared with existing OMR systems, the proposed system has a higher accuracy and the least constraints. We believe that the presented work will further direct the development of OMR systems towards reducing the restrictions of the MCQ tests.
Semantic White Balance: Semantic Color Constancy Using Convolutional Neural Network
Jul 11, 2018
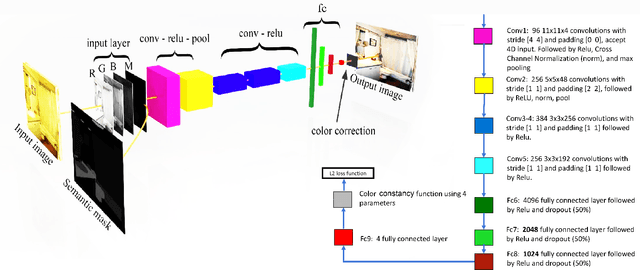


The goal of computational color constancy is to preserve the perceptive colors of objects under different lighting conditions by removing the effect of color casts caused by the scene's illumination. With the rapid development of deep learning based techniques, significant progress has been made in image semantic segmentation. In this work, we exploit the semantic information together with the color and spatial information of the input image in order to remove color casts. We train a convolutional neural network (CNN) model that learns to estimate the illuminant color and gamma correction parameters based on the semantic information of the given image. Experimental results show that feeding the CNN with the semantic information leads to a significant improvement in the results by reducing the error by more than 40%.
Image Posterization Using Fuzzy Logic and Bilateral Filter
Feb 03, 2018

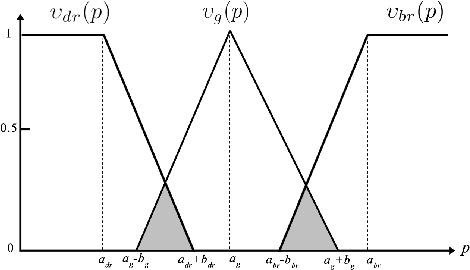

Image posterization is converting images with a large number of tones into synthetic images with distinct flat areas and a fewer number of tones. In this technical report, we present the implementation and results of using fuzzy logic in order to generate a posterized image in a simple and fast way. The image filter is based on fuzzy logic and bilateral filtering; where, the given image is blurred to remove small details. Then, the fuzzy logic is used to classify each pixel into one of three specific categories in order to reduce the number of colors. This filter was developed during building the Specs on Face dataset in order to add a new level of difficulty to the original face images in the dataset. This filter does not hurt the human detection performance; however, it is considered a hindrance evading the face detection process. This filter can be used generally for posterizing images, especially those have a high contrast to get images with vivid colors.