 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Illusion of Procedural Reasoning: Measuring Long-Horizon FSM Execution in LLMs
Nov 05, 2025Large language models (LLMs) have achieved remarkable results on tasks framed as reasoning problems, yet their true ability to perform procedural reasoning, executing multi-step, rule-based computations remains unclear. Unlike algorithmic systems, which can deterministically execute long-horizon symbolic procedures, LLMs often degrade under extended reasoning chains, but there is no controlled, interpretable benchmark to isolate and measure this collapse. We introduce Finite-State Machine (FSM) Execution as a minimal, fully interpretable framework for evaluating the procedural reasoning capacity of LLMs. In our setup, the model is given an explicit FSM definition and must execute it step-by-step given input actions, maintaining state consistency over multiple turns. This task requires no world knowledge, only faithful application of deterministic transition rules, making it a direct probe of the model's internal procedural fidelity. We measure both Turn Accuracy and Task Accuracy to disentangle immediate computation from cumulative state maintenance. Empirical results reveal systematic degradation as task horizon or branching complexity increases. Models perform significantly worse when rule retrieval involves high branching factors than when memory span is long. Larger models show improved local accuracy but remain brittle under multi-step reasoning unless explicitly prompted to externalize intermediate steps. FSM-based evaluation offers a transparent, complexity-controlled probe for diagnosing this failure mode and guiding the design of inductive biases that enable genuine long-horizon procedural competence. By grounding reasoning in measurable execution fidelity rather than surface correctness, this work helps establish a rigorous experimental foundation for understanding and improving the algorithmic reliability of LLMs.
MEENA (PersianMMMU): Multimodal-Multilingual Educational Exams for N-level Assessment
Aug 24, 2025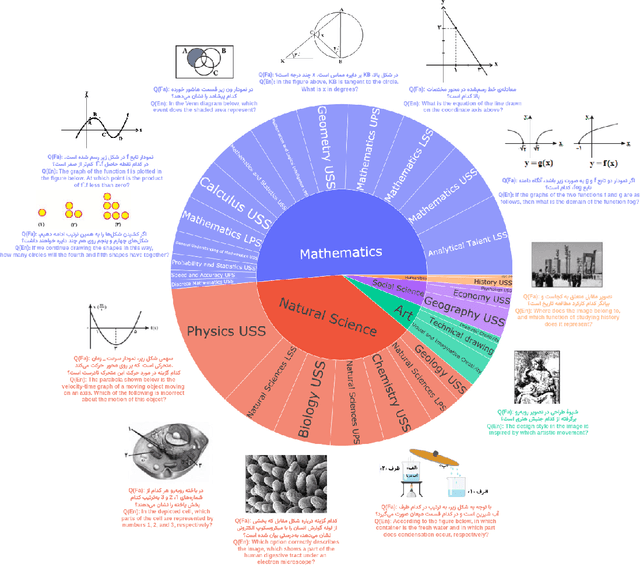

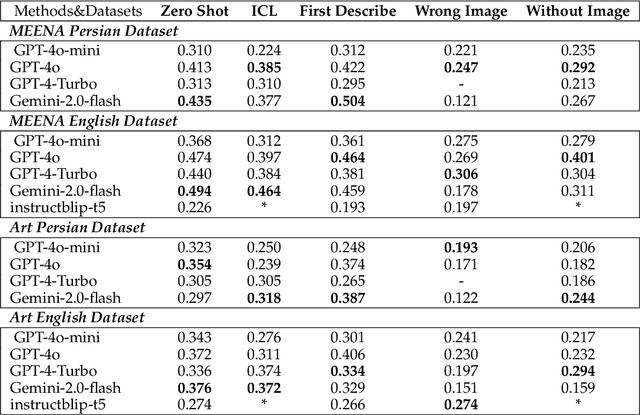
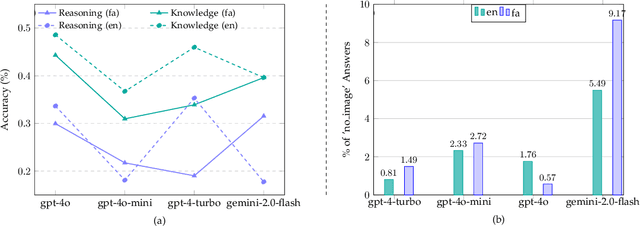
Recent advancements in large vision-language models (VLMs) have primarily focused on English, with limited attention given to other languages. To address this gap, we introduce MEENA (also known as PersianMMMU), the first dataset designed to evaluate Persian VLMs across scientific, reasoning, and human-level understanding tasks. Our dataset comprises approximately 7,500 Persian and 3,000 English questions, covering a wide range of topics such as reasoning, mathematics, physics, diagrams, charts, and Persian art and literature. Key features of MEENA include: (1) diverse subject coverage spanning various educational levels, from primary to upper secondary school, (2) rich metadata, including difficulty levels and descriptive answers, (3) original Persian data that preserves cultural nuances, (4) a bilingual structure to assess cross-linguistic performance, and (5) a series of diverse experiments assessing various capabilities, including overall performance, the model's ability to attend to images, and its tendency to generate hallucinations. We hope this benchmark contributes to enhancing VLM capabilities beyond English.
LLM-Agent-Controller: A Universal Multi-Agent Large Language Model System as a Control Engineer
May 26, 2025This study presents the LLM-Agent-Controller, a multi-agent large language model (LLM) system developed to address a wide range of problems in control engineering (Control Theory). The system integrates a central controller agent with multiple specialized auxiliary agents, responsible for tasks such as controller design, model representation, control analysis, time-domain response, and simulation. A supervisor oversees high-level decision-making and workflow coordination, enhancing the system's reliability and efficiency. The LLM-Agent-Controller incorporates advanced capabilities, including Retrieval-Augmented Generation (RAG), Chain-of-Thought reasoning, self-criticism and correction, efficient memory handling, and user-friendly natural language communication. It is designed to function without requiring users to have prior knowledge of Control Theory, enabling them to input problems in plain language and receive complete, real-time solutions. To evaluate the system, we propose new performance metrics assessing both individual agents and the system as a whole. We test five categories of Control Theory problems and benchmark performance across three advanced LLMs. Additionally, we conduct a comprehensive qualitative conversational analysis covering all key services. Results show that the LLM-Agent-Controller successfully solved 83% of general tasks, with individual agents achieving an average success rate of 87%. Performance improved with more advanced LLMs. This research demonstrates the potential of multi-agent LLM architectures to solve complex, domain-specific problems. By integrating specialized agents, supervisory control, and advanced reasoning, the LLM-Agent-Controller offers a scalable, robust, and accessible solution framework that can be extended to various technical domains.
Generative AI for Character Animation: A Comprehensive Survey of Techniques, Applications, and Future Directions
Apr 27, 2025



Generative AI is reshaping art, gaming, and most notably animation. Recent breakthroughs in foundation and diffusion models have reduced the time and cost of producing animated content. Characters are central animation components, involving motion, emotions, gestures, and facial expressions. The pace and breadth of advances in recent months make it difficult to maintain a coherent view of the field, motivating the need for an integrative review. Unlike earlier overviews that treat avatars, gestures, or facial animation in isolation, this survey offers a single, comprehensive perspective on all the main generative AI applications for character animation. We begin by examining the state-of-the-art in facial animation, expression rendering, image synthesis, avatar creation, gesture modeling, motion synthesis, object generation, and texture synthesis. We highlight leading research, practical deployments, commonly used datasets, and emerging trends for each area. To support newcomers, we also provide a comprehensive background section that introduces foundational models and evaluation metrics, equipping readers with the knowledge needed to enter the field. We discuss open challenges and map future research directions, providing a roadmap to advance AI-driven character-animation technologies. This survey is intended as a resource for researchers and developers entering the field of generative AI animation or adjacent fields. Resources are available at: https://github.com/llm-lab-org/Generative-AI-for-Character-Animation-Survey.
ELAB: Extensive LLM Alignment Benchmark in Persian Language
Apr 17, 2025



This paper presents a comprehensive evaluation framework for aligning Persian Large Language Models (LLMs) with critical ethical dimensions, including safety, fairness, and social norms. It addresses the gaps in existing LLM evaluation frameworks by adapting them to Persian linguistic and cultural contexts. This benchmark creates three types of Persian-language benchmarks: (i) translated data, (ii) new data generated synthetically, and (iii) new naturally collected data. We translate Anthropic Red Teaming data, AdvBench, HarmBench, and DecodingTrust into Persian. Furthermore, we create ProhibiBench-fa, SafeBench-fa, FairBench-fa, and SocialBench-fa as new datasets to address harmful and prohibited content in indigenous culture. Moreover, we collect extensive dataset as GuardBench-fa to consider Persian cultural norms. By combining these datasets, our work establishes a unified framework for evaluating Persian LLMs, offering a new approach to culturally grounded alignment evaluation. A systematic evaluation of Persian LLMs is performed across the three alignment aspects: safety (avoiding harmful content), fairness (mitigating biases), and social norms (adhering to culturally accepted behaviors). We present a publicly available leaderboard that benchmarks Persian LLMs with respect to safety, fairness, and social norms at: https://huggingface.co/spaces/MCILAB/LLM_Alignment_Evaluation.
T2I-FineEval: Fine-Grained Compositional Metric for Text-to-Image Evaluation
Mar 14, 2025



Although recent text-to-image generative models have achieved impressive performance, they still often struggle with capturing the compositional complexities of prompts including attribute binding, and spatial relationships between different entities. This misalignment is not revealed by common evaluation metrics such as CLIPScore. Recent works have proposed evaluation metrics that utilize Visual Question Answering (VQA) by decomposing prompts into questions about the generated image for more robust compositional evaluation. Although these methods align better with human evaluations, they still fail to fully cover the compositionality within the image. To address this, we propose a novel metric that breaks down images into components, and texts into fine-grained questions about the generated image for evaluation. Our method outperforms previous state-of-the-art metrics, demonstrating its effectiveness in evaluating text-to-image generative models. Code is available at https://github.com/hadi-hosseini/ T2I-FineEval.
Fine-Grained Alignment and Noise Refinement for Compositional Text-to-Image Generation
Mar 09, 2025



Text-to-image generative models have made significant advancements in recent years; however, accurately capturing intricate details in textual prompts, such as entity missing, attribute binding errors, and incorrect relationships remains a formidable challenge. In response, we present an innovative, training-free method that directly addresses these challenges by incorporating tailored objectives to account for textual constraints. Unlike layout-based approaches that enforce rigid structures and limit diversity, our proposed approach offers a more flexible arrangement of the scene by imposing just the extracted constraints from the text, without any unnecessary additions. These constraints are formulated as losses-entity missing, entity mixing, attribute binding, and spatial relationships, integrated into a unified loss that is applied in the first generation stage. Furthermore, we introduce a feedback-driven system for fine-grained initial noise refinement. This system integrates a verifier that evaluates the generated image, identifies inconsistencies, and provides corrective feedback. Leveraging this feedback, our refinement method first targets the unmet constraints by refining the faulty attention maps caused by initial noise, through the optimization of selective losses associated with these constraints. Subsequently, our unified loss function is reapplied to proceed the second generation phase. Experimental results demonstrate that our method, relying solely on our proposed objective functions, significantly enhances compositionality, achieving a 24% improvement in human evaluation and a 25% gain in spatial relationships. Furthermore, our fine-grained noise refinement proves effective, boosting performance by up to 5%. Code is available at https://github.com/hadi-hosseini/noise-refinement.
VQEL: Enabling Self-Developed Symbolic Language in Agents through Vector Quantization in Emergent Language Games
Mar 06, 2025



In the field of emergent language, efforts have traditionally focused on developing communication protocols through interactions between agents in referential games. However, the aspect of internal language learning, where language serves not only as a communicative tool with others but also as a means for individual thinking, self-reflection, and problem-solving remains underexplored. Developing a language through self-play, without another agent's involvement, poses a unique challenge. It requires an agent to craft symbolic representations and train them using direct gradient methods. The challenge here is that if an agent attempts to learn symbolic representations through self-play using conventional modeling and techniques such as REINFORCE, the solution will offer no advantage over previous multi-agent approaches. We introduce VQEL, a novel method that incorporates Vector Quantization into the agents' architecture, enabling them to autonomously invent and develop discrete symbolic representations in a self-play referential game. Following the self-play phase, agents can enhance their language through reinforcement learning and interactions with other agents in the mutual-play phase. Our experiments across various datasets demonstrate that VQEL not only outperforms the traditional REINFORCE method but also benefits from improved control and reduced susceptibility to collapse, thanks to the incorporation of vector quantization.
Analyzing CLIP's Performance Limitations in Multi-Object Scenarios: A Controlled High-Resolution Study
Feb 27, 2025



Contrastive Language-Image Pre-training (CLIP) models have demonstrated remarkable performance in zero-shot classification tasks, yet their efficacy in handling complex multi-object scenarios remains challenging. This study presents a comprehensive analysis of CLIP's performance limitations in multi-object contexts through controlled experiments. We introduce two custom datasets, SimCO and CompCO, to evaluate CLIP's image and text encoders in various multi-object configurations. Our findings reveal significant biases in both encoders: the image encoder favors larger objects, while the text encoder prioritizes objects mentioned first in descriptions. We hypothesize these biases originate from CLIP's training process and provide evidence through analyses of the COCO dataset and CLIP's training progression. Additionally, we extend our investigation to Stable Diffusion models, revealing that biases in the CLIP text encoder significantly impact text-to-image generation tasks. Our experiments demonstrate how these biases affect CLIP's performance in image-caption matching and generation tasks, particularly when manipulating object sizes and their order in captions. This work contributes valuable insights into CLIP's behavior in complex visual environments and highlights areas for improvement in future vision-language models.
CLIP Under the Microscope: A Fine-Grained Analysis of Multi-Object Representation
Feb 27, 2025



Contrastive Language-Image Pre-training (CLIP) models excel in zero-shot classification, yet face challenges in complex multi-object scenarios. This study offers a comprehensive analysis of CLIP's limitations in these contexts using a specialized dataset, ComCO, designed to evaluate CLIP's encoders in diverse multi-object scenarios. Our findings reveal significant biases: the text encoder prioritizes first-mentioned objects, and the image encoder favors larger objects. Through retrieval and classification tasks, we quantify these biases across multiple CLIP variants and trace their origins to CLIP's training process, supported by analyses of the LAION dataset and training progression. Our image-text matching experiments show substantial performance drops when object size or token order changes, underscoring CLIP's instability with rephrased but semantically similar captions. Extending this to longer captions and text-to-image models like Stable Diffusion, we demonstrate how prompt order influences object prominence in generated images. For more details and access to our dataset and analysis code, visit our project repository: https://clip-analysis.github.io.