 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Subquadratic Architectures: From Applications to Principles
Jun 10, 2026Transformers dominate modern sequence modeling, but their quadratic attention incurs substantial computational cost. Subquadratic architectures offer a scalable alternative. However, it remains unclear which designs yield the most effective sequence models. We compare three leading approaches: xLSTM, Mamba-2, and Gated DeltaNet. We evaluate these models on tasks with complex dependencies: (1) code-model pre-training, (2) distillation of code models from large language models, and (3) pre-training of time-series foundation models. Across these settings, xLSTM delivers the strongest overall performance. To explain xLSTM's advantage, we present a unified formulation and analyze the underlying architectural mechanisms, focusing on state tracking and memory dynamics. Our results show that xLSTM enables more flexible and stable memory correction via its gating scheme. We corroborate these findings on controlled synthetic length-generalization tasks. Overall, our findings indicate that xLSTM's gains on complex tasks stem from robust state tracking and accumulation.
Effective Distillation to Hybrid xLSTM Architectures
Mar 16, 2026There have been numerous attempts to distill quadratic attention-based large language models (LLMs) into sub-quadratic linearized architectures. However, despite extensive research, such distilled models often fail to match the performance of their teacher LLMs on various downstream tasks. We set out the goal of lossless distillation, which we define in terms of tolerance-corrected Win-and-Tie rates between student and teacher on sets of tasks. To this end, we introduce an effective distillation pipeline for xLSTM-based students. We propose an additional merging stage, where individually linearized experts are combined into a single model. We show the effectiveness of this pipeline by distilling base and instruction-tuned models from the Llama, Qwen, and Olmo families. In many settings, our xLSTM-based students recover most of the teacher's performance, and even exceed it on some downstream tasks. Our contributions are an important step towards more energy-efficient and cost-effective replacements for transformer-based LLMs.
One Initialization to Rule them All: Fine-tuning via Explained Variance Adaptation
Oct 09, 2024



Foundation models (FMs) are pre-trained on large-scale datasets and then fine-tuned on a downstream task for a specific application. The most successful and most commonly used fine-tuning method is to update the pre-trained weights via a low-rank adaptation (LoRA). LoRA introduces new weight matrices that are usually initialized at random with a uniform rank distribution across model weights. Recent works focus on weight-driven initialization or learning of adaptive ranks during training. Both approaches have only been investigated in isolation, resulting in slow convergence or a uniform rank distribution, in turn leading to sub-optimal performance. We propose to enhance LoRA by initializing the new weights in a data-driven manner by computing singular value decomposition on minibatches of activation vectors. Then, we initialize the LoRA matrices with the obtained right-singular vectors and re-distribute ranks among all weight matrices to explain the maximal amount of variance and continue the standard LoRA fine-tuning procedure. This results in our new method Explained Variance Adaptation (EVA). We apply EVA to a variety of fine-tuning tasks ranging from language generation and understanding to image classification and reinforcement learning. EVA exhibits faster convergence than competitors and attains the highest average score across a multitude of tasks per domain.
Parameter Efficient Diff Pruning for Bias Mitigation
May 30, 2022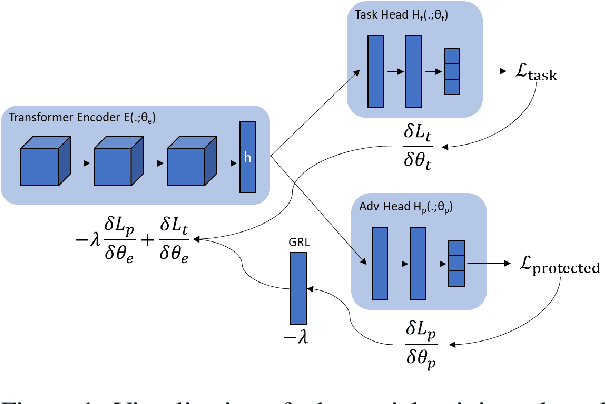
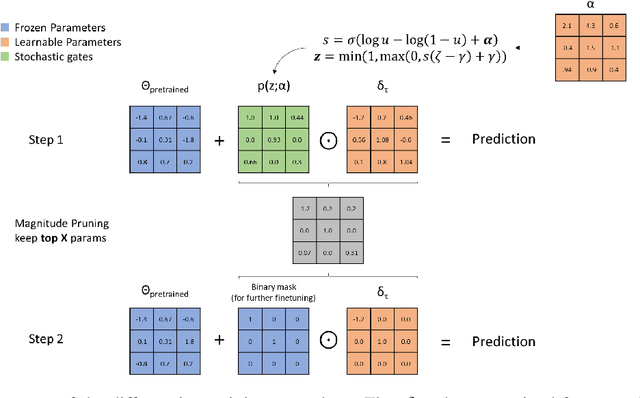
In recent years language models have achieved state of the art performance on a wide variety of natural language processing tasks. As these models are continuously growing in size it becomes increasingly important to explore methods to make them more storage efficient. At the same time their increase cognitive abilities increase the danger that societal bias existing in datasets are implicitly encoded in the model weights. We propose an architecture which deals with these two challenges at the same time using two techniques: DiffPruning and Adverserial Training. The result is a modular architecture which extends the original DiffPurning setup with and additional sparse subnetwork applied as a mask to diminish the effects of a predefined protected attribute at inference time.