 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDIT: Scalable and Diverse Cross-domain Image Translation
Aug 19, 2019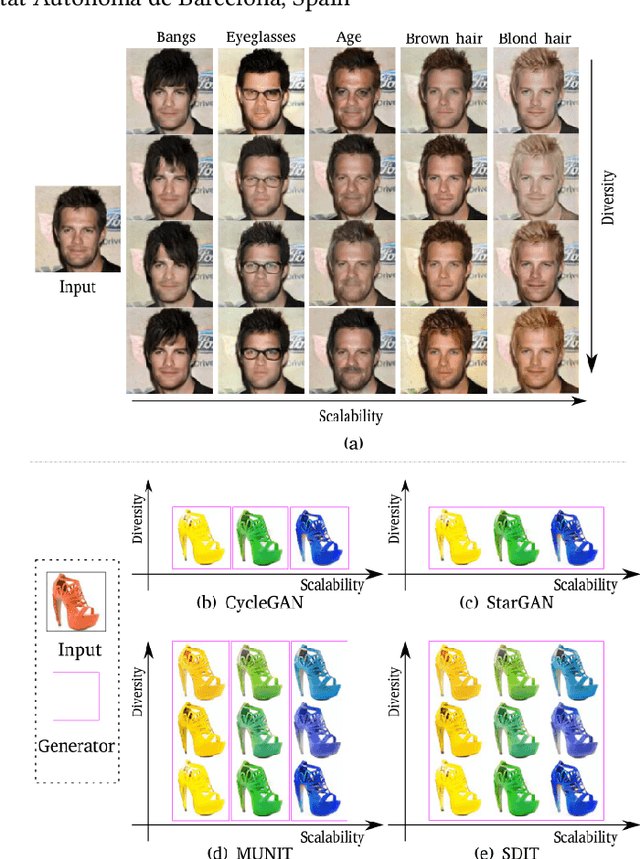
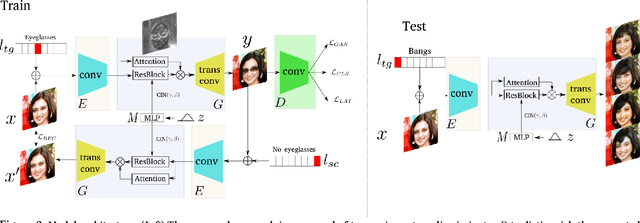

Recently, image-to-image translation research has witnessed remarkable progress. Although current approaches successfully generate diverse outputs or perform scalable image transfer, these properties have not been combined into a single method. To address this limitation, we propose SDIT: Scalable and Diverse image-to-image translation. These properties are combined into a single generator. The diversity is determined by a latent variable which is randomly sampled from a normal distribution. The scalability is obtained by conditioning the network on the domain attributes. Additionally, we also exploit an attention mechanism that permits the generator to focus on the domain-specific attribute. We empirically demonstrate the performance of the proposed method on face mapping and other datasets beyond faces.
Controlling biases and diversity in diverse image-to-image translation
Jul 23, 2019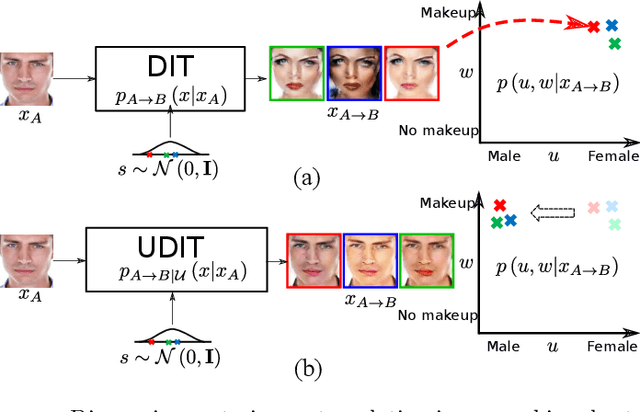



The task of unpaired image-to-image translation is highly challenging due to the lack of explicit cross-domain pairs of instances. We consider here diverse image translation (DIT), an even more challenging setting in which an image can have multiple plausible translations. This is normally achieved by explicitly disentangling content and style in the latent representation and sampling different styles codes while maintaining the image content. Despite the success of current DIT models, they are prone to suffer from bias. In this paper, we study the problem of bias in image-to-image translation. Biased datasets may add undesired changes (e.g. change gender or race in face images) to the output translations as a consequence of the particular underlying visual distribution in the target domain. In order to alleviate the effects of this problem we propose the use of semantic constraints that enforce the preservation of desired image properties. Our proposed model is a step towards unbiased diverse image-to-image translation (UDIT), and results in less unwanted changes in the translated images while still performing the wanted transformation. Experiments on several heavily biased datasets show the effectiveness of the proposed techniques in different domains such as faces, objects, and scenes.
Multifaceted Analysis of Fine-Tuning in Deep Model for Visual Recognition
Jul 11, 2019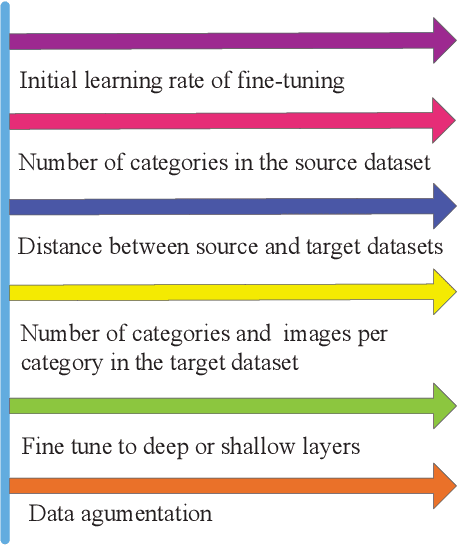
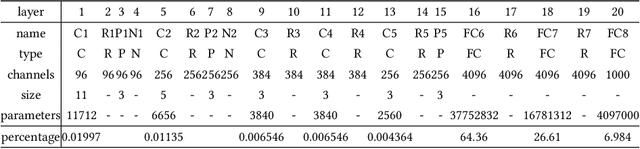

In recent years, convolutional neural networks (CNNs) have achieved impressive performance for various visual recognition scenarios. CNNs trained on large labeled datasets can not only obtain significant performance on most challenging benchmarks but also provide powerful representations, which can be used to a wide range of other tasks. However, the requirement of massive amounts of data to train deep neural networks is a major drawback of these models, as the data available is usually limited or imbalanced. Fine-tuning (FT) is an effective way to transfer knowledge learned in a source dataset to a target task. In this paper, we introduce and systematically investigate several factors that influence the performance of fine-tuning for visual recognition. These factors include parameters for the retraining procedure (e.g., the initial learning rate of fine-tuning), the distribution of the source and target data (e.g., the number of categories in the source dataset, the distance between the source and target datasets) and so on. We quantitatively and qualitatively analyze these factors, evaluate their influence, and present many empirical observations. The results reveal insights into what fine-tuning changes CNN parameters and provide useful and evidence-backed intuitions about how to implement fine-tuning for computer vision tasks.
Mix and match networks: multi-domain alignment for unpaired image-to-image translation
Mar 08, 2019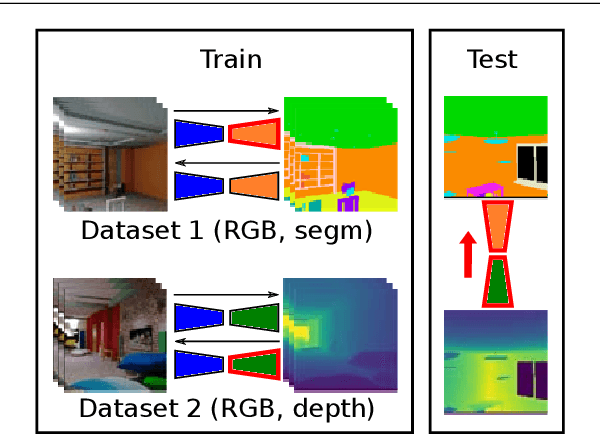
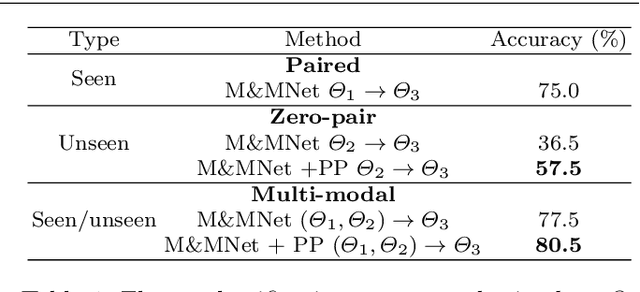

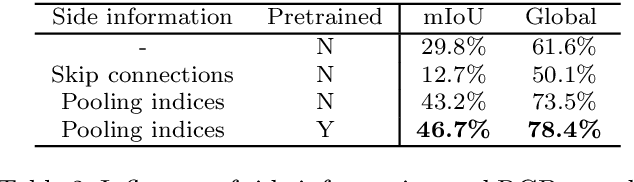
This paper addresses the problem of inferring unseen cross-domain and cross-modal image-to-image translations between multiple domains and modalities. We assume that only some of the pairwise translations have been seen (i.e. trained) and infer the remaining unseen translations (where training pairs are not available). We propose mix and match networks, an approach where multiple encoders and decoders are aligned in such a way that the desired translation can be obtained by simply cascading the source encoder and the target decoder, even when they have not interacted during the training stage (i.e. unseen). The main challenge lies in the alignment of the latent representations at the bottlenecks of encoder-decoder pairs. We propose an architecture with several tools to encourage alignment, including autoencoders and robust side information and latent consistency losses. We show the benefits of our approach in terms of effectiveness and scalability compared with other pairwise image-to-image translation approaches. We also propose zero-pair cross-modal image translation, a challenging setting where the objective is inferring semantic segmentation from depth (and vice-versa) without explicit segmentation-depth pairs, and only from two (disjoint) segmentation-RGB and depth-segmentation training sets. We observe that certain part of the shared information between unseen domains might not be reachable, so we further propose a variant that leverages pseudo-pairs to exploit all shared information.
Cross-Modulation Networks for Few-Shot Learning
Dec 01, 2018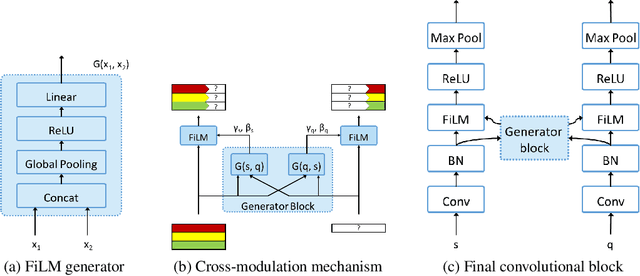
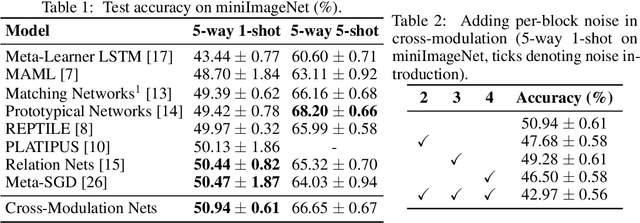
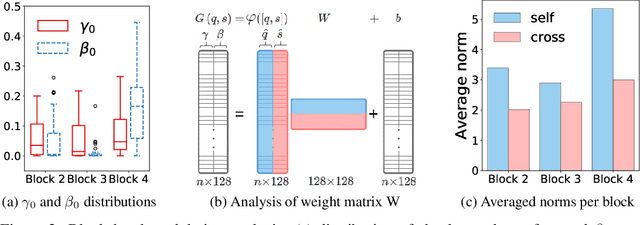
A family of recent successful approaches to few-shot learning relies on learning an embedding space in which predictions are made by computing similarities between examples. This corresponds to combining information between support and query examples at a very late stage of the prediction pipeline. Inspired by this observation, we hypothesize that there may be benefits to combining the information at various levels of abstraction along the pipeline. We present an architecture called Cross-Modulation Networks which allows support and query examples to interact throughout the feature extraction process via a feature-wise modulation mechanism. We adapt the Matching Networks architecture to take advantage of these interactions and show encouraging initial results on miniImageNet in the 5-way, 1-shot setting, where we close the gap with state-of-the-art.
Memory Replay GANs: learning to generate images from new categories without forgetting
Oct 29, 2018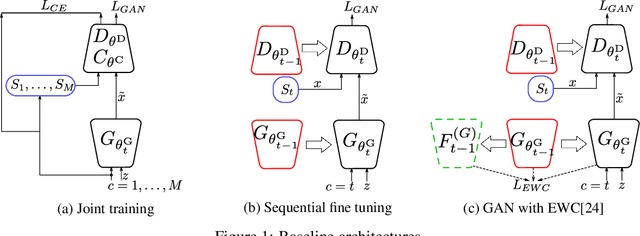

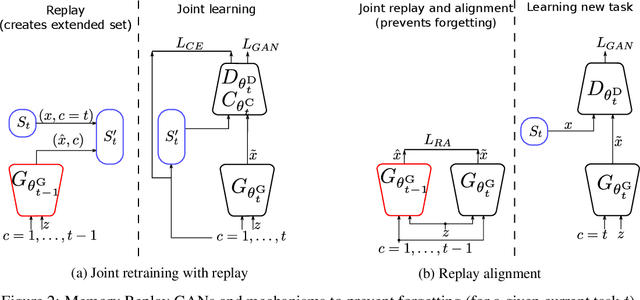

Previous works on sequential learning address the problem of forgetting in discriminative models. In this paper we consider the case of generative models. In particular, we investigate generative adversarial networks (GANs) in the task of learning new categories in a sequential fashion. We first show that sequential fine tuning renders the network unable to properly generate images from previous categories (i.e. forgetting). Addressing this problem, we propose Memory Replay GANs (MeRGANs), a conditional GAN framework that integrates a memory replay generator. We study two methods to prevent forgetting by leveraging these replays, namely joint training with replay and replay alignment. Qualitative and quantitative experimental results in MNIST, SVHN and LSUN datasets show that our memory replay approach can generate competitive images while significantly mitigating the forgetting of previous categories.
Transferring GANs: generating images from limited data
Oct 02, 2018
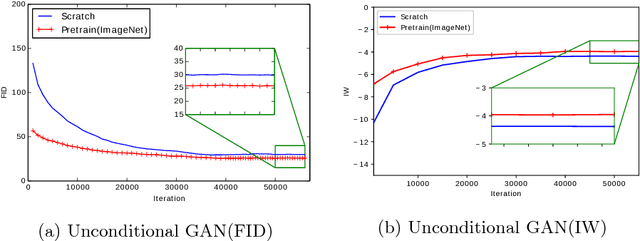

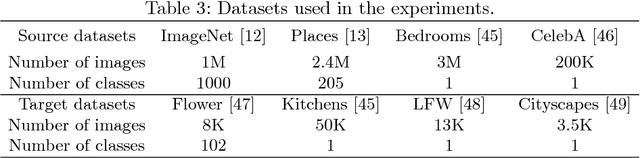
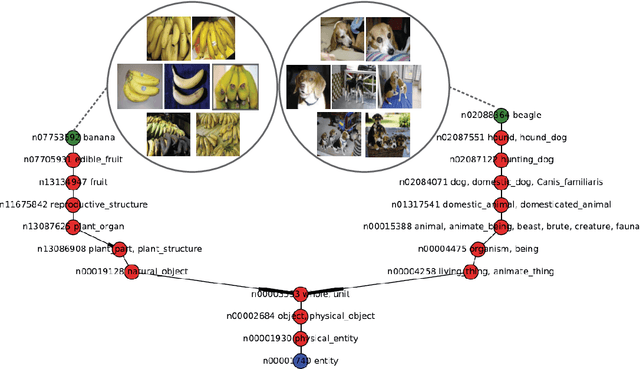
Transferring the knowledge of pretrained networks to new domains by means of finetuning is a widely used practice for applications based on discriminative models. To the best of our knowledge this practice has not been studied within the context of generative deep networks. Therefore, we study domain adaptation applied to image generation with generative adversarial networks. We evaluate several aspects of domain adaptation, including the impact of target domain size, the relative distance between source and target domain, and the initialization of conditional GANs. Our results show that using knowledge from pretrained networks can shorten the convergence time and can significantly improve the quality of the generated images, especially when the target data is limited. We show that these conclusions can also be drawn for conditional GANs even when the pretrained model was trained without conditioning. Our results also suggest that density may be more important than diversity and a dataset with one or few densely sampled classes may be a better source model than more diverse datasets such as ImageNet or Places.
Learning Effective RGB-D Representations for Scene Recognition
Sep 17, 2018
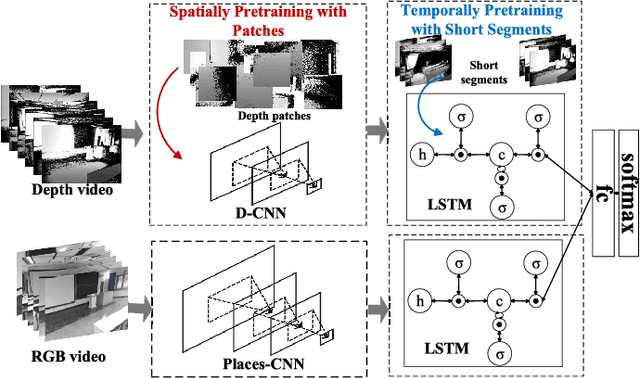
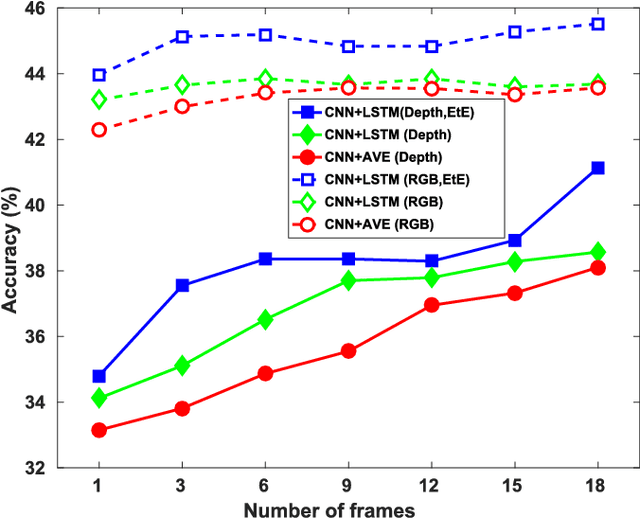
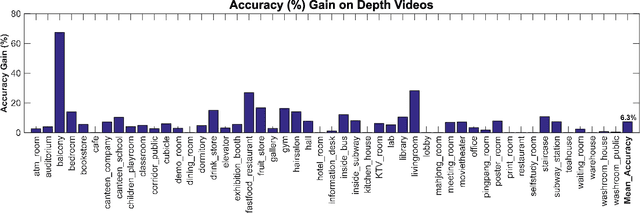
Deep convolutional networks (CNN) can achieve impressive results on RGB scene recognition thanks to large datasets such as Places. In contrast, RGB-D scene recognition is still underdeveloped in comparison, due to two limitations of RGB-D data we address in this paper. The first limitation is the lack of depth data for training deep learning models. Rather than fine tuning or transferring RGB-specific features, we address this limitation by proposing an architecture and a two-step training approach that directly learns effective depth-specific features using weak supervision via patches. The resulting RGB-D model also benefits from more complementary multimodal features. Another limitation is the short range of depth sensors (typically 0.5m to 5.5m), resulting in depth images not capturing distant objects in the scenes that RGB images can. We show that this limitation can be addressed by using RGB-D videos, where more comprehensive depth information is accumulated as the camera travels across the scene. Focusing on this scenario, we introduce the ISIA RGB-D video dataset to evaluate RGB-D scene recognition with videos. Our video recognition architecture combines convolutional and recurrent neural networks (RNNs) that are trained in three steps with increasingly complex data to learn effective features (i.e. patches, frames and sequences). Our approach obtains state-of-the-art performances on RGB-D image (NYUD2 and SUN RGB-D) and video (ISIA RGB-D) scene recognition.
* Accepted at IEEE Transactions on Image Processing
LIUM-CVC Submissions for WMT18 Multimodal Translation Task
Sep 01, 2018
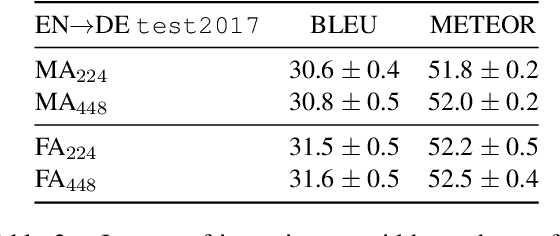
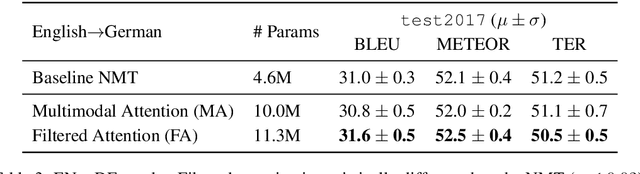
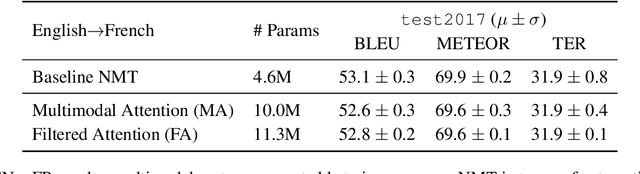
This paper describes the multimodal Neural Machine Translation systems developed by LIUM and CVC for WMT18 Shared Task on Multimodal Translation. This year we propose several modifications to our previous multimodal attention architecture in order to better integrate convolutional features and refine them using encoder-side information. Our final constrained submissions ranked first for English-French and second for English-German language pairs among the constrained submissions according to the automatic evaluation metric METEOR.
Rotate your Networks: Better Weight Consolidation and Less Catastrophic Forgetting
Jul 12, 2018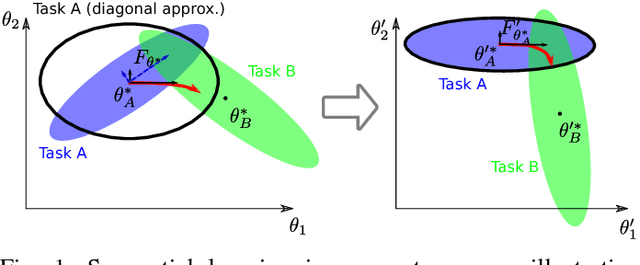
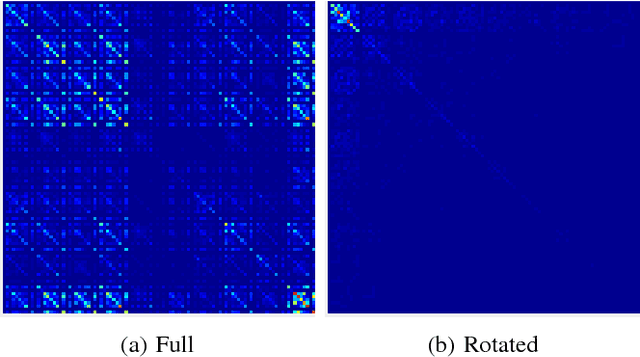
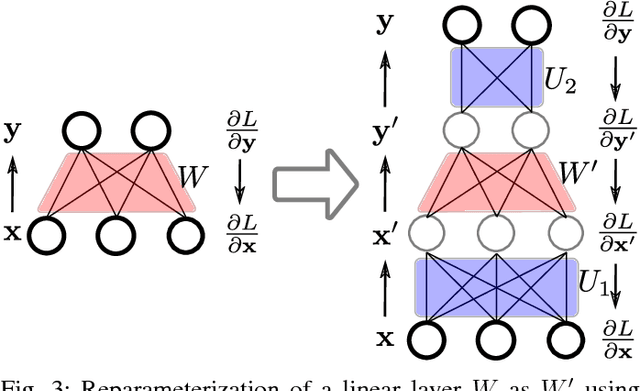
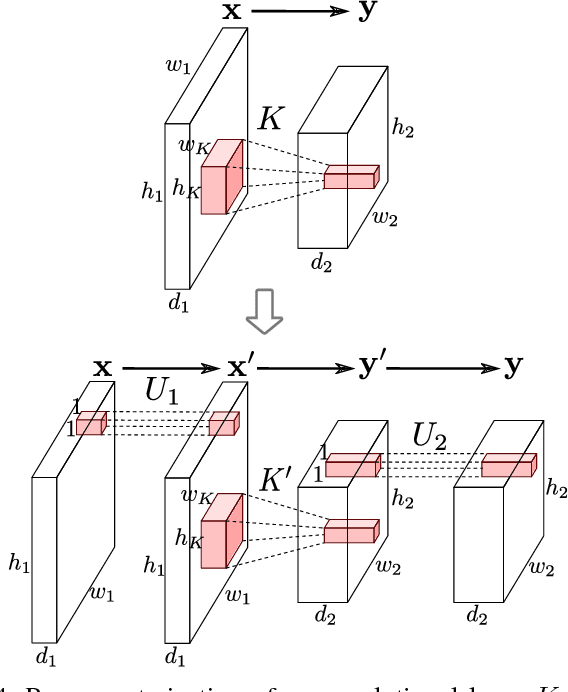
In this paper we propose an approach to avoiding catastrophic forgetting in sequential task learning scenarios. Our technique is based on a network reparameterization that approximately diagonalizes the Fisher Information Matrix of the network parameters. This reparameterization takes the form of a factorized rotation of parameter space which, when used in conjunction with Elastic Weight Consolidation (which assumes a diagonal Fisher Information Matrix), leads to significantly better performance on lifelong learning of sequential tasks. Experimental results on the MNIST, CIFAR-100, CUB-200 and Stanford-40 datasets demonstrate that we significantly improve the results of standard elastic weight consolidation, and that we obtain competitive results when compared to other state-of-the-art in lifelong learning without forgetting.