 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmortised MAP Inference for Image Super-resolution
Feb 21, 2017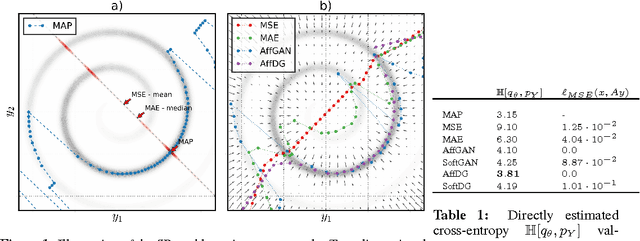
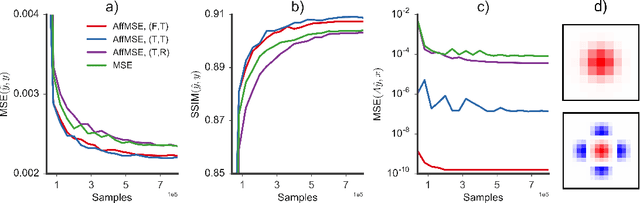


Image super-resolution (SR) is an underdetermined inverse problem, where a large number of plausible high-resolution images can explain the same downsampled image. Most current single image SR methods use empirical risk minimisation, often with a pixel-wise mean squared error (MSE) loss. However, the outputs from such methods tend to be blurry, over-smoothed and generally appear implausible. A more desirable approach would employ Maximum a Posteriori (MAP) inference, preferring solutions that always have a high probability under the image prior, and thus appear more plausible. Direct MAP estimation for SR is non-trivial, as it requires us to build a model for the image prior from samples. Furthermore, MAP inference is often performed via optimisation-based iterative algorithms which don't compare well with the efficiency of neural-network-based alternatives. Here we introduce new methods for amortised MAP inference whereby we calculate the MAP estimate directly using a convolutional neural network. We first introduce a novel neural network architecture that performs a projection to the affine subspace of valid SR solutions ensuring that the high resolution output of the network is always consistent with the low resolution input. We show that, using this architecture, the amortised MAP inference problem reduces to minimising the cross-entropy between two distributions, similar to training generative models. We propose three methods to solve this optimisation problem: (1) Generative Adversarial Networks (GAN) (2) denoiser-guided SR which backpropagates gradient-estimates from denoising to train the network, and (3) a baseline method using a maximum-likelihood-trained image prior. Our experiments show that the GAN based approach performs best on real image data. Lastly, we establish a connection between GANs and amortised variational inference as in e.g. variational autoencoders.
Is the deconvolution layer the same as a convolutional layer?
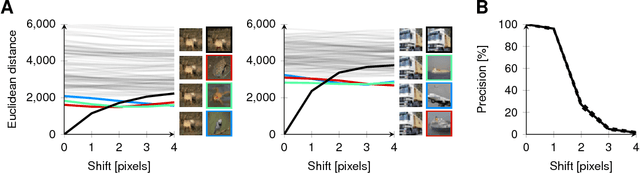
Sep 22, 2016In this note, we want to focus on aspects related to two questions most people asked us at CVPR about the network we presented. Firstly, What is the relationship between our proposed layer and the deconvolution layer? And secondly, why are convolutions in low-resolution (LR) space a better choice? These are key questions we tried to answer in the paper, but we were not able to go into as much depth and clarity as we would have liked in the space allowance. To better answer these questions in this note, we first discuss the relationships between the deconvolution layer in the forms of the transposed convolution layer, the sub-pixel convolutional layer and our efficient sub-pixel convolutional layer. We will refer to our efficient sub-pixel convolutional layer as a convolutional layer in LR space to distinguish it from the common sub-pixel convolutional layer. We will then show that for a fixed computational budget and complexity, a network with convolutions exclusively in LR space has more representation power at the same speed than a network that first upsamples the input in high resolution space.
A note on the evaluation of generative models
Apr 24, 2016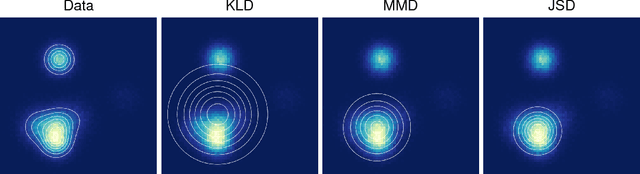
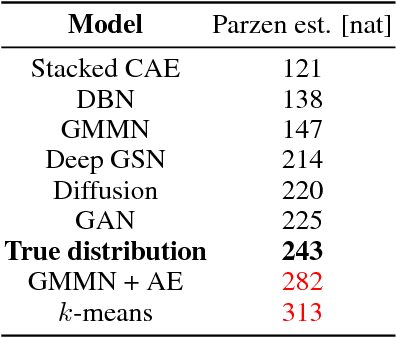
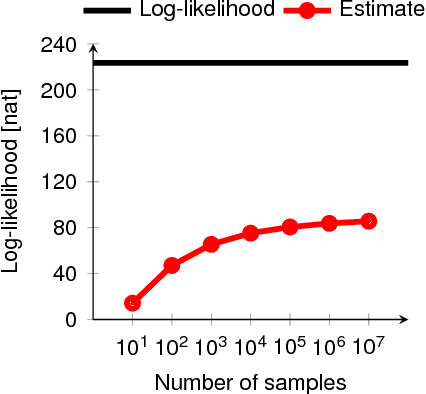
Probabilistic generative models can be used for compression, denoising, inpainting, texture synthesis, semi-supervised learning, unsupervised feature learning, and other tasks. Given this wide range of applications, it is not surprising that a lot of heterogeneity exists in the way these models are formulated, trained, and evaluated. As a consequence, direct comparison between models is often difficult. This article reviews mostly known but often underappreciated properties relating to the evaluation and interpretation of generative models with a focus on image models. In particular, we show that three of the currently most commonly used criteria---average log-likelihood, Parzen window estimates, and visual fidelity of samples---are largely independent of each other when the data is high-dimensional. Good performance with respect to one criterion therefore need not imply good performance with respect to the other criteria. Our results show that extrapolation from one criterion to another is not warranted and generative models need to be evaluated directly with respect to the application(s) they were intended for. In addition, we provide examples demonstrating that Parzen window estimates should generally be avoided.
Inference and Mixture Modeling with the Elliptical Gamma Distribution
Dec 20, 2015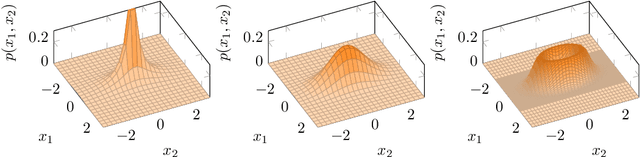
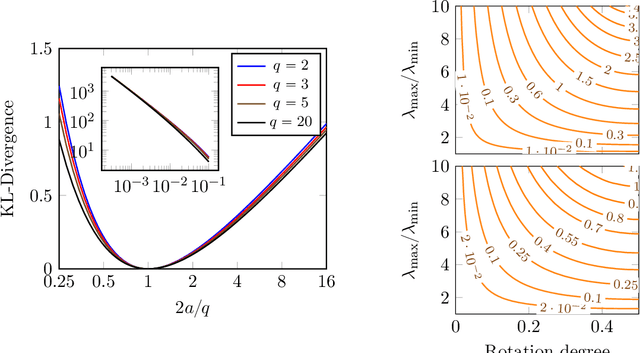
We study modeling and inference with the Elliptical Gamma Distribution (EGD). We consider maximum likelihood (ML) estimation for EGD scatter matrices, a task for which we develop new fixed-point algorithms. Our algorithms are efficient and converge to global optima despite nonconvexity. Moreover, they turn out to be much faster than both a well-known iterative algorithm of Kent & Tyler (1991) and sophisticated manifold optimization algorithms. Subsequently, we invoke our ML algorithms as subroutines for estimating parameters of a mixture of EGDs. We illustrate our methods by applying them to model natural image statistics---the proposed EGD mixture model yields the most parsimonious model among several competing approaches.
* 23 pages, 11 figures
Generative Image Modeling Using Spatial LSTMs
Sep 18, 2015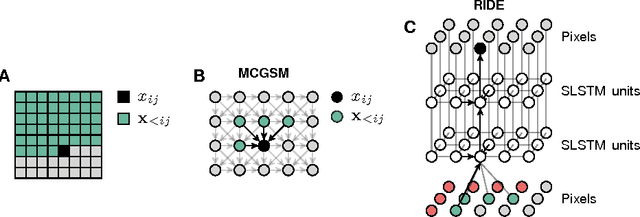
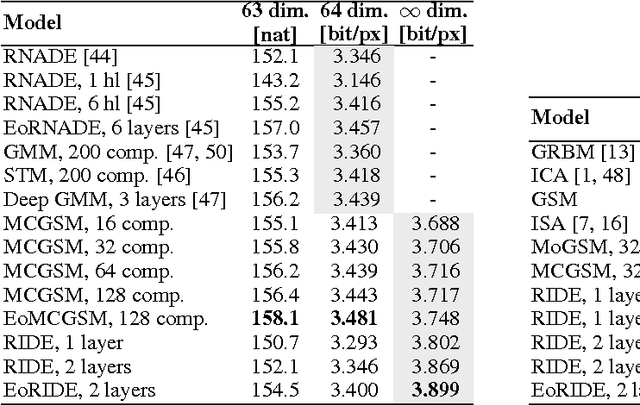
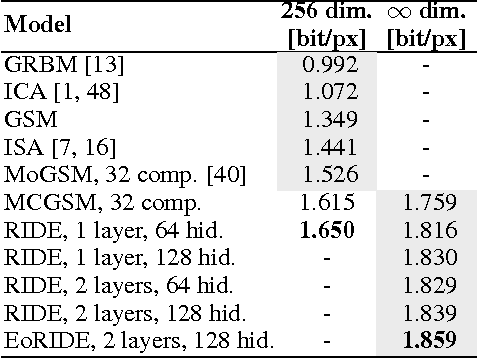
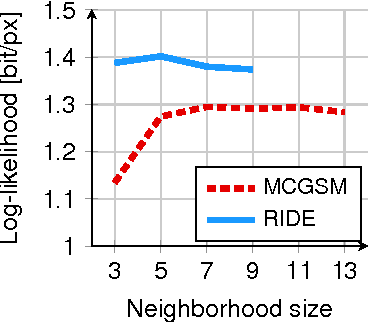
Modeling the distribution of natural images is challenging, partly because of strong statistical dependencies which can extend over hundreds of pixels. Recurrent neural networks have been successful in capturing long-range dependencies in a number of problems but only recently have found their way into generative image models. We here introduce a recurrent image model based on multi-dimensional long short-term memory units which are particularly suited for image modeling due to their spatial structure. Our model scales to images of arbitrary size and its likelihood is computationally tractable. We find that it outperforms the state of the art in quantitative comparisons on several image datasets and produces promising results when used for texture synthesis and inpainting.
A Generative Model of Natural Texture Surrogates
May 28, 2015
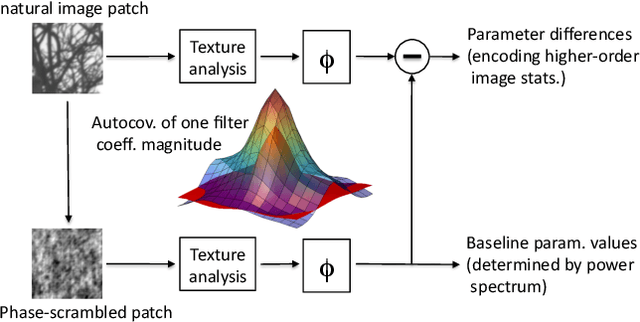
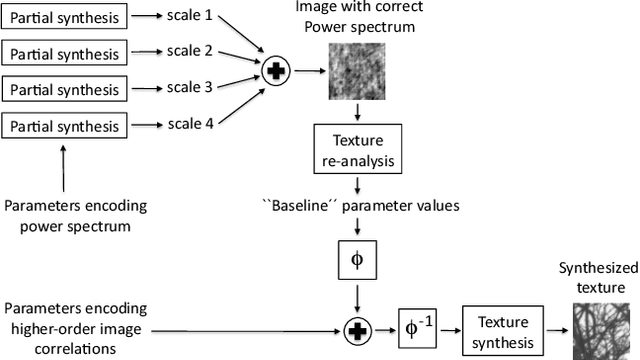

Natural images can be viewed as patchworks of different textures, where the local image statistics is roughly stationary within a small neighborhood but otherwise varies from region to region. In order to model this variability, we first applied the parametric texture algorithm of Portilla and Simoncelli to image patches of 64X64 pixels in a large database of natural images such that each image patch is then described by 655 texture parameters which specify certain statistics, such as variances and covariances of wavelet coefficients or coefficient magnitudes within that patch. To model the statistics of these texture parameters, we then developed suitable nonlinear transformations of the parameters that allowed us to fit their joint statistics with a multivariate Gaussian distribution. We find that the first 200 principal components contain more than 99% of the variance and are sufficient to generate textures that are perceptually extremely close to those generated with all 655 components. We demonstrate the usefulness of the model in several ways: (1) We sample ensembles of texture patches that can be directly compared to samples of patches from the natural image database and can to a high degree reproduce their perceptual appearance. (2) We further developed an image compression algorithm which generates surprisingly accurate images at bit rates as low as 0.14 bits/pixel. Finally, (3) We demonstrate how our approach can be used for an efficient and objective evaluation of samples generated with probabilistic models of natural images.
A trust-region method for stochastic variational inference with applications to streaming data
May 28, 2015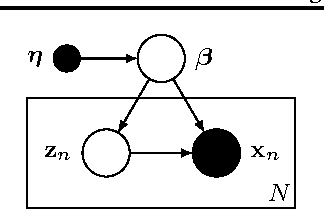
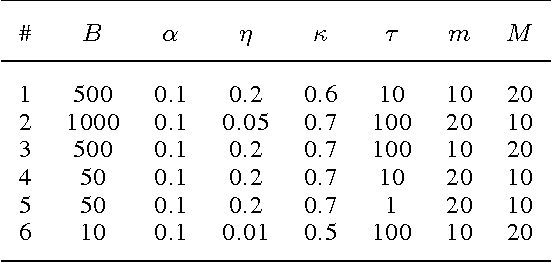
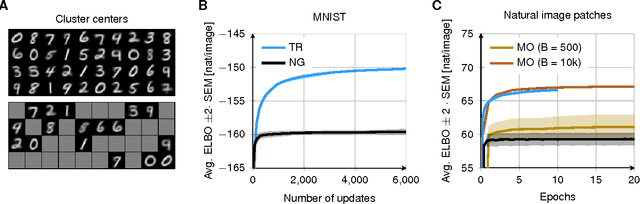
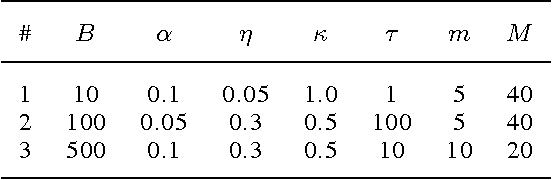
Stochastic variational inference allows for fast posterior inference in complex Bayesian models. However, the algorithm is prone to local optima which can make the quality of the posterior approximation sensitive to the choice of hyperparameters and initialization. We address this problem by replacing the natural gradient step of stochastic varitional inference with a trust-region update. We show that this leads to generally better results and reduced sensitivity to hyperparameters. We also describe a new strategy for variational inference on streaming data and show that here our trust-region method is crucial for getting good performance.
Deep Gaze I: Boosting Saliency Prediction with Feature Maps Trained on ImageNet
Apr 09, 2015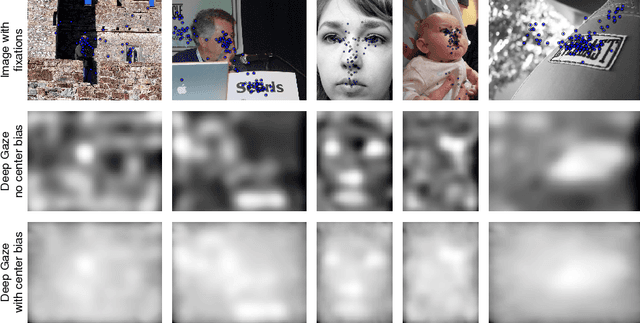
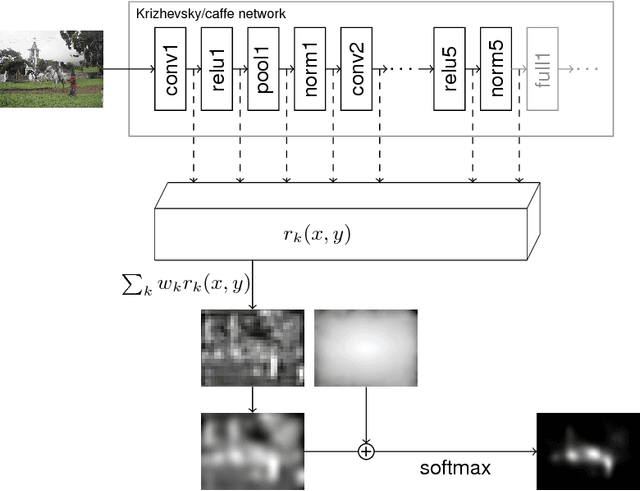
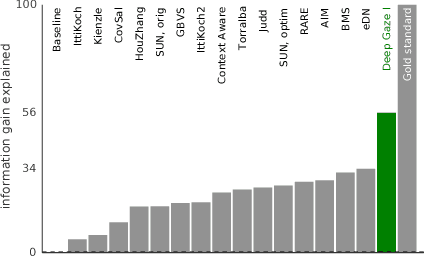

Recent results suggest that state-of-the-art saliency models perform far from optimal in predicting fixations. This lack in performance has been attributed to an inability to model the influence of high-level image features such as objects. Recent seminal advances in applying deep neural networks to tasks like object recognition suggests that they are able to capture this kind of structure. However, the enormous amount of training data necessary to train these networks makes them difficult to apply directly to saliency prediction. We present a novel way of reusing existing neural networks that have been pretrained on the task of object recognition in models of fixation prediction. Using the well-known network of Krizhevsky et al. (2012), we come up with a new saliency model that significantly outperforms all state-of-the-art models on the MIT Saliency Benchmark. We show that the structure of this network allows new insights in the psychophysics of fixation selection and potentially their neural implementation. To train our network, we build on recent work on the modeling of saliency as point processes.
Supervised learning sets benchmark for robust spike detection from calcium imaging signals
Feb 28, 2015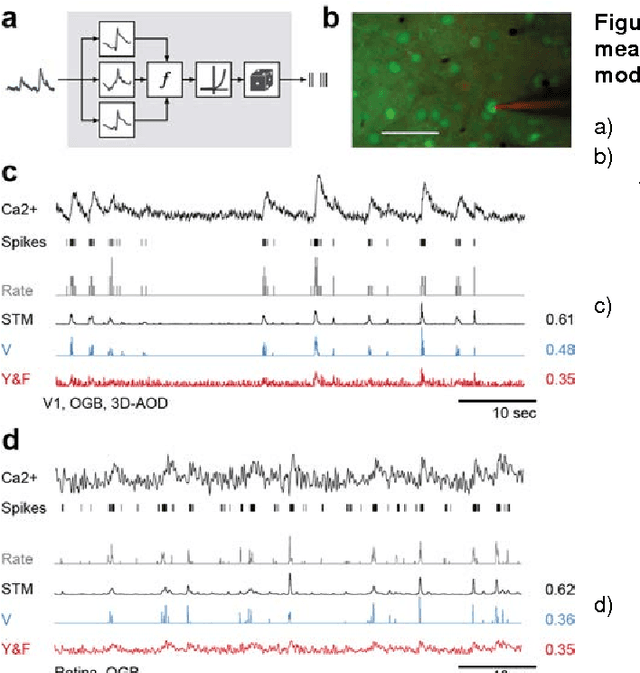

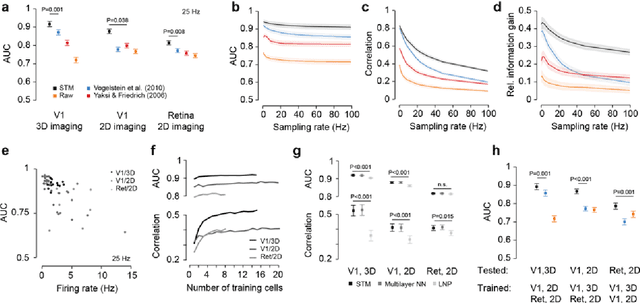
A fundamental challenge in calcium imaging has been to infer the timing of action potentials from the measured noisy calcium fluorescence traces. We systematically evaluate a range of spike inference algorithms on a large benchmark dataset recorded from varying neural tissue (V1 and retina) using different calcium indicators (OGB-1 and GCamp6). We show that a new algorithm based on supervised learning in flexible probabilistic models outperforms all previously published techniques, setting a new standard for spike inference from calcium signals. Importantly, it performs better than other algorithms even on datasets not seen during training. Future data acquired in new experimental conditions can easily be used to further improve its spike prediction accuracy and generalization performance. Finally, we show that comparing algorithms on artificial data is not informative about performance on real population imaging data, suggesting that a benchmark dataset may greatly facilitate future algorithmic developments.
Mixtures of conditional Gaussian scale mixtures applied to multiscale image representations
Sep 20, 2011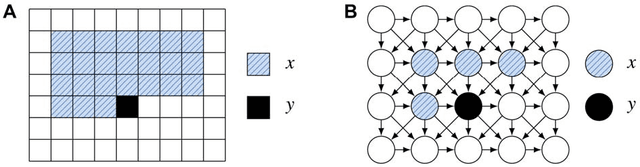
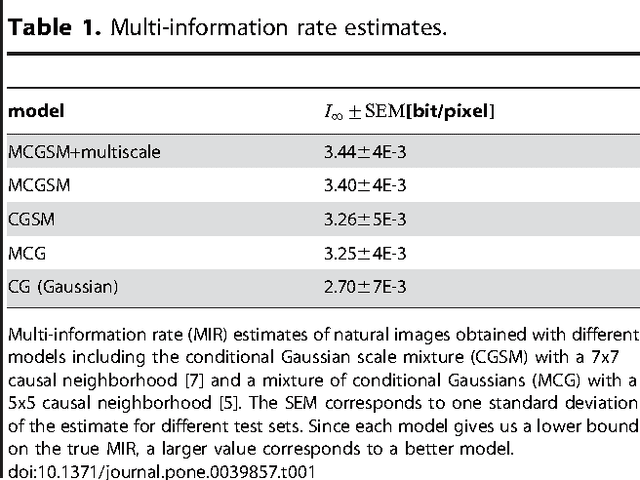
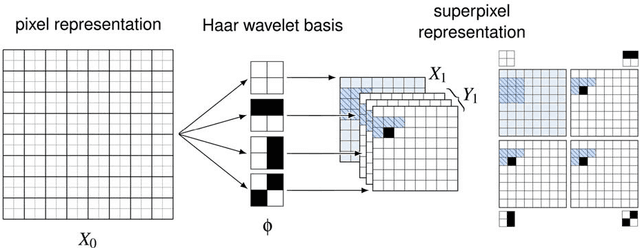

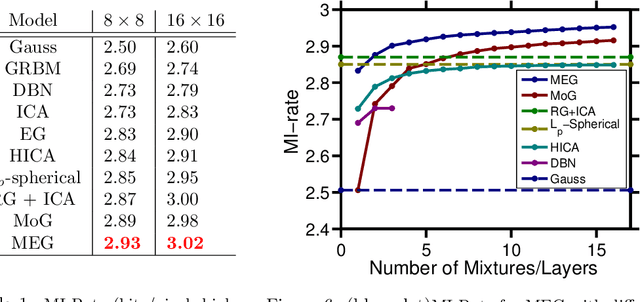
We present a probabilistic model for natural images which is based on Gaussian scale mixtures and a simple multiscale representation. In contrast to the dominant approach to modeling whole images focusing on Markov random fields, we formulate our model in terms of a directed graphical model. We show that it is able to generate images with interesting higher-order correlations when trained on natural images or samples from an occlusion based model. More importantly, the directed model enables us to perform a principled evaluation. While it is easy to generate visually appealing images, we demonstrate that our model also yields the best performance reported to date when evaluated with respect to the cross-entropy rate, a measure tightly linked to the average log-likelihood.