 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Reach-Avoid for Bayesian Neural Networks
Oct 03, 2023



Model-based reinforcement learning seeks to simultaneously learn the dynamics of an unknown stochastic environment and synthesise an optimal policy for acting in it. Ensuring the safety and robustness of sequential decisions made through a policy in such an environment is a key challenge for policies intended for safety-critical scenarios. In this work, we investigate two complementary problems: first, computing reach-avoid probabilities for iterative predictions made with dynamical models, with dynamics described by Bayesian neural network (BNN); second, synthesising control policies that are optimal with respect to a given reach-avoid specification (reaching a "target" state, while avoiding a set of "unsafe" states) and a learned BNN model. Our solution leverages interval propagation and backward recursion techniques to compute lower bounds for the probability that a policy's sequence of actions leads to satisfying the reach-avoid specification. Such computed lower bounds provide safety certification for the given policy and BNN model. We then introduce control synthesis algorithms to derive policies maximizing said lower bounds on the safety probability. We demonstrate the effectiveness of our method on a series of control benchmarks characterized by learned BNN dynamics models. On our most challenging benchmark, compared to purely data-driven policies the optimal synthesis algorithm is able to provide more than a four-fold increase in the number of certifiable states and more than a three-fold increase in the average guaranteed reach-avoid probability.
Promises of Deep Kernel Learning for Control Synthesis
Sep 12, 2023



Deep Kernel Learning (DKL) combines the representational power of neural networks with the uncertainty quantification of Gaussian Processes. Hence, it is potentially a promising tool to learn and control complex dynamical systems. In this work, we develop a scalable abstraction-based framework that enables the use of DKL for control synthesis of stochastic dynamical systems against complex specifications. Specifically, we consider temporal logic specifications and create an end-to-end framework that uses DKL to learn an unknown system from data and formally abstracts the DKL model into an Interval Markov Decision Process (IMDP) to perform control synthesis with correctness guarantees. Furthermore, we identify a deep architecture that enables accurate learning and efficient abstraction computation. The effectiveness of our approach is illustrated on various benchmarks, including a 5-D nonlinear stochastic system, showing how control synthesis with DKL can substantially outperform state-of-the-art competitive methods.
Adversarial Robustness Certification for Bayesian Neural Networks
Jun 23, 2023



We study the problem of certifying the robustness of Bayesian neural networks (BNNs) to adversarial input perturbations. Given a compact set of input points $T \subseteq \mathbb{R}^m$ and a set of output points $S \subseteq \mathbb{R}^n$, we define two notions of robustness for BNNs in an adversarial setting: probabilistic robustness and decision robustness. Probabilistic robustness is the probability that for all points in $T$ the output of a BNN sampled from the posterior is in $S$. On the other hand, decision robustness considers the optimal decision of a BNN and checks if for all points in $T$ the optimal decision of the BNN for a given loss function lies within the output set $S$. Although exact computation of these robustness properties is challenging due to the probabilistic and non-convex nature of BNNs, we present a unified computational framework for efficiently and formally bounding them. Our approach is based on weight interval sampling, integration, and bound propagation techniques, and can be applied to BNNs with a large number of parameters, and independently of the (approximate) inference method employed to train the BNN. We evaluate the effectiveness of our methods on various regression and classification tasks, including an industrial regression benchmark, MNIST, traffic sign recognition, and airborne collision avoidance, and demonstrate that our approach enables certification of robustness and uncertainty of BNN predictions.
BNN-DP: Robustness Certification of Bayesian Neural Networks via Dynamic Programming
Jun 19, 2023



In this paper, we introduce BNN-DP, an efficient algorithmic framework for analysis of adversarial robustness of Bayesian Neural Networks (BNNs). Given a compact set of input points $T\subset \mathbb{R}^n$, BNN-DP computes lower and upper bounds on the BNN's predictions for all the points in $T$. The framework is based on an interpretation of BNNs as stochastic dynamical systems, which enables the use of Dynamic Programming (DP) algorithms to bound the prediction range along the layers of the network. Specifically, the method uses bound propagation techniques and convex relaxations to derive a backward recursion procedure to over-approximate the prediction range of the BNN with piecewise affine functions. The algorithm is general and can handle both regression and classification tasks. On a set of experiments on various regression and classification tasks and BNN architectures, we show that BNN-DP outperforms state-of-the-art methods by up to four orders of magnitude in both tightness of the bounds and computational efficiency.
Individual Fairness in Bayesian Neural Networks
Apr 21, 2023

We study Individual Fairness (IF) for Bayesian neural networks (BNNs). Specifically, we consider the $\epsilon$-$\delta$-individual fairness notion, which requires that, for any pair of input points that are $\epsilon$-similar according to a given similarity metrics, the output of the BNN is within a given tolerance $\delta>0.$ We leverage bounds on statistical sampling over the input space and the relationship between adversarial robustness and individual fairness to derive a framework for the systematic estimation of $\epsilon$-$\delta$-IF, designing Fair-FGSM and Fair-PGD as global,fairness-aware extensions to gradient-based attacks for BNNs. We empirically study IF of a variety of approximately inferred BNNs with different architectures on fairness benchmarks, and compare against deterministic models learnt using frequentist techniques. Interestingly, we find that BNNs trained by means of approximate Bayesian inference consistently tend to be markedly more individually fair than their deterministic counterparts.
Interval Markov Decision Processes with Continuous Action-Spaces
Nov 02, 2022

Interval Markov Decision Processes (IMDPs) are uncertain Markov models, where the transition probabilities belong to intervals. Recently, there has been a surge of research on employing IMDPs as abstractions of stochastic systems for control synthesis. However, due to the absence of algorithms for synthesis over IMDPs with continuous action-spaces, the action-space is assumed discrete a-priori, which is a restrictive assumption for many applications. Motivated by this, we introduce continuous-action IMDPs (caIMDPs), where the bounds on transition probabilities are functions of the action variables, and study value iteration for maximizing expected cumulative rewards. Specifically, we show that solving the max-min problem associated to value iteration is equivalent to solving $|\mathcal{Q}|$ max problems, where $|\mathcal{Q}|$ is the number of states of the caIMDP. Then, exploiting the simple form of these max problems, we identify cases where value iteration over caIMDPs can be solved efficiently (e.g., with linear or convex programming). We also gain other interesting insights: e.g., in the case where the action set $\mathcal{A}$ is a polytope and the transition bounds are linear, synthesizing over a discrete-action IMDP, where the actions are the vertices of $\mathcal{A}$, is sufficient for optimality. We demonstrate our results on a numerical example. Finally, we include a short discussion on employing caIMDPs as abstractions for control synthesis.
On the Robustness of Bayesian Neural Networks to Adversarial Attacks
Jul 13, 2022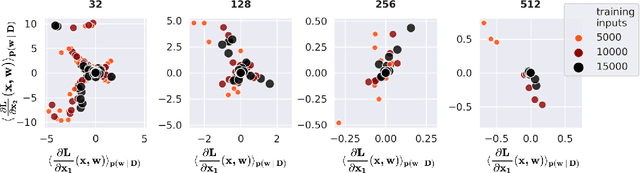
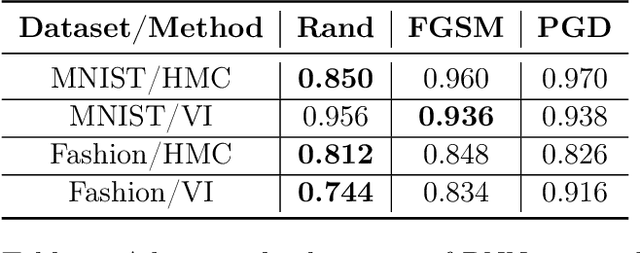
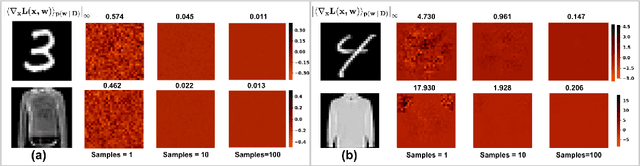
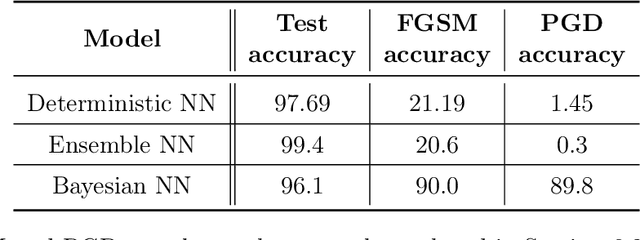
Vulnerability to adversarial attacks is one of the principal hurdles to the adoption of deep learning in safety-critical applications. Despite significant efforts, both practical and theoretical, training deep learning models robust to adversarial attacks is still an open problem. In this paper, we analyse the geometry of adversarial attacks in the large-data, overparameterized limit for Bayesian Neural Networks (BNNs). We show that, in the limit, vulnerability to gradient-based attacks arises as a result of degeneracy in the data distribution, i.e., when the data lies on a lower-dimensional submanifold of the ambient space. As a direct consequence, we demonstrate that in this limit BNN posteriors are robust to gradient-based adversarial attacks. Crucially, we prove that the expected gradient of the loss with respect to the BNN posterior distribution is vanishing, even when each neural network sampled from the posterior is vulnerable to gradient-based attacks. Experimental results on the MNIST, Fashion MNIST, and half moons datasets, representing the finite data regime, with BNNs trained with Hamiltonian Monte Carlo and Variational Inference, support this line of arguments, showing that BNNs can display both high accuracy on clean data and robustness to both gradient-based and gradient-free based adversarial attacks.
Safety Guarantees for Neural Network Dynamic Systems via Stochastic Barrier Functions
Jun 26, 2022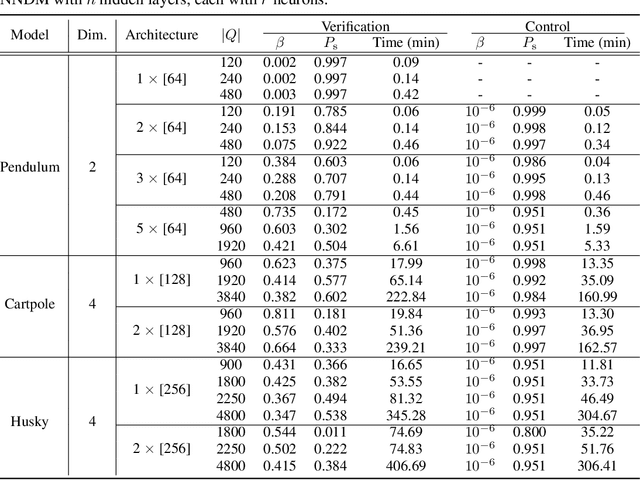
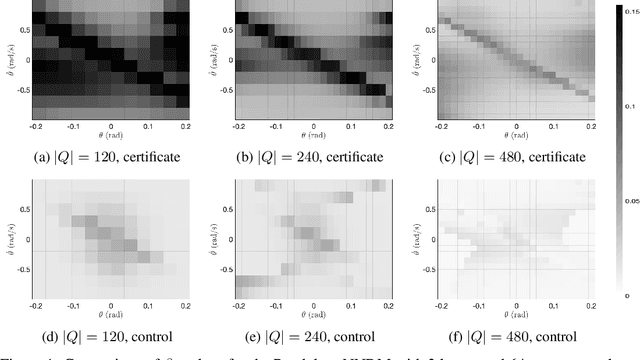
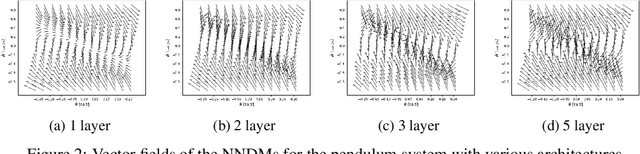
Neural Networks (NNs) have been successfully employed to represent the state evolution of complex dynamical systems. Such models, referred to as NN dynamic models (NNDMs), use iterative noisy predictions of NN to estimate a distribution of system trajectories over time. Despite their accuracy, safety analysis of NNDMs is known to be a challenging problem and remains largely unexplored. To address this issue, in this paper, we introduce a method of providing safety guarantees for NNDMs. Our approach is based on stochastic barrier functions, whose relation with safety are analogous to that of Lyapunov functions with stability. We first show a method of synthesizing stochastic barrier functions for NNDMs via a convex optimization problem, which in turn provides a lower bound on the system's safety probability. A key step in our method is the employment of the recent convex approximation results for NNs to find piece-wise linear bounds, which allow the formulation of the barrier function synthesis problem as a sum-of-squares optimization program. If the obtained safety probability is above the desired threshold, the system is certified. Otherwise, we introduce a method of generating controls for the system that robustly maximizes the safety probability in a minimally-invasive manner. We exploit the convexity property of the barrier function to formulate the optimal control synthesis problem as a linear program. Experimental results illustrate the efficacy of the method. Namely, they show that the method can scale to multi-dimensional NNDMs with multiple layers and hundreds of neurons per layer, and that the controller can significantly improve the safety probability.
Safety Certification for Stochastic Systems via Neural Barrier Functions
Jun 03, 2022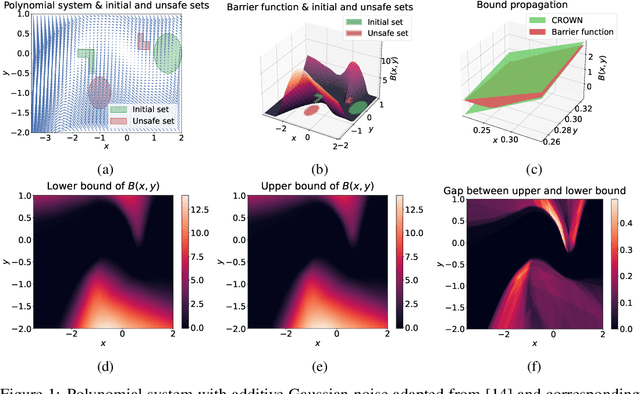
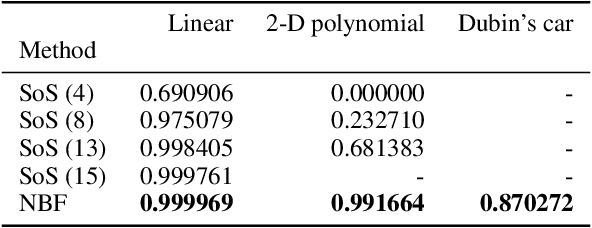
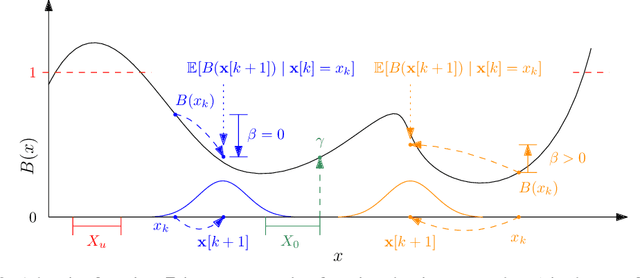
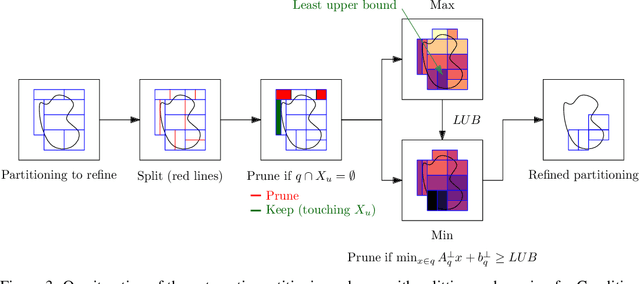
Providing non-trivial certificates of safety for non-linear stochastic systems is an important open problem that limits the wider adoption of autonomous systems in safety-critical applications. One promising solution to address this problem is barrier functions. The composition of a barrier function with a stochastic system forms a supermartingale, thus enabling the computation of the probability that the system stays in a safe set over a finite time horizon via martingale inequalities. However, existing approaches to find barrier functions for stochastic systems generally rely on convex optimization programs that restrict the search of a barrier to a small class of functions such as low degree SoS polynomials and can be computationally expensive. In this paper, we parameterize a barrier function as a neural network and show that techniques for robust training of neural networks can be successfully employed to find neural barrier functions. Specifically, we leverage bound propagation techniques to certify that a neural network satisfies the conditions to be a barrier function via linear programming and then employ the resulting bounds at training time to enforce the satisfaction of these conditions. We also present a branch-and-bound scheme that makes the certification framework scalable. We show that our approach outperforms existing methods in several case studies and often returns certificates of safety that are orders of magnitude larger.
Individual Fairness Guarantees for Neural Networks
May 11, 2022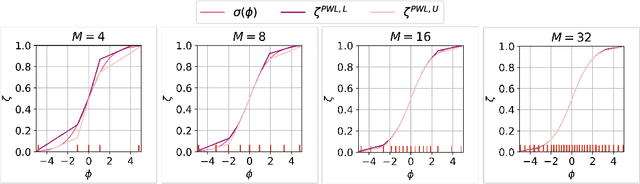
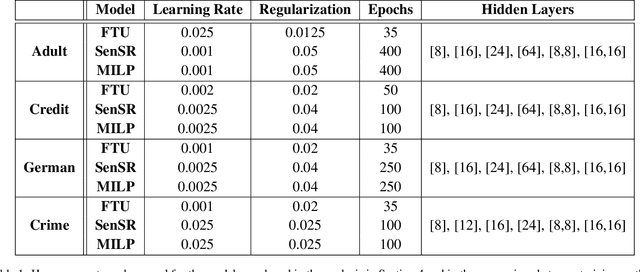
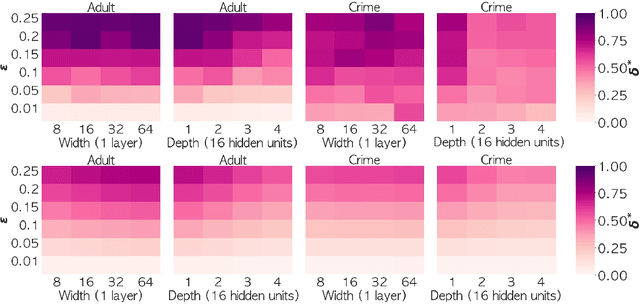
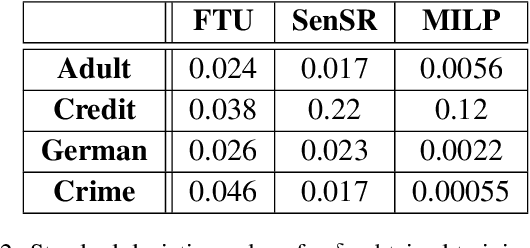
We consider the problem of certifying the individual fairness (IF) of feed-forward neural networks (NNs). In particular, we work with the $\epsilon$-$\delta$-IF formulation, which, given a NN and a similarity metric learnt from data, requires that the output difference between any pair of $\epsilon$-similar individuals is bounded by a maximum decision tolerance $\delta \geq 0$. Working with a range of metrics, including the Mahalanobis distance, we propose a method to overapproximate the resulting optimisation problem using piecewise-linear functions to lower and upper bound the NN's non-linearities globally over the input space. We encode this computation as the solution of a Mixed-Integer Linear Programming problem and demonstrate that it can be used to compute IF guarantees on four datasets widely used for fairness benchmarking. We show how this formulation can be used to encourage models' fairness at training time by modifying the NN loss, and empirically confirm our approach yields NNs that are orders of magnitude fairer than state-of-the-art methods.