 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Formal Verification via Autoencoder Latent Space Abstraction
Dec 16, 2025Finite Abstraction methods provide a powerful formal framework for proving that systems satisfy their specifications. However, these techniques face scalability challenges for high-dimensional systems, as they rely on state-space discretization which grows exponentially with dimension. Learning-based approaches to dimensionality reduction, utilizing neural networks and autoencoders, have shown great potential to alleviate this problem. However, ensuring the correctness of the resulting verification results remains an open question. In this work, we provide a formal approach to reduce the dimensionality of systems via convex autoencoders and learn the dynamics in the latent space through a kernel-based method. We then construct a finite abstraction from the learned model in the latent space and guarantee that the abstraction contains the true behaviors of the original system. We show that the verification results in the latent space can be mapped back to the original system. Finally, we demonstrate the effectiveness of our approach on multiple systems, including a 26D system controlled by a neural network, showing significant scalability improvements without loss of rigor.
Learning-Based Shielding for Safe Autonomy under Unknown Dynamics
Oct 07, 2024



Shielding is a common method used to guarantee the safety of a system under a black-box controller, such as a neural network controller from deep reinforcement learning (DRL), with simpler, verified controllers. Existing shielding methods rely on formal verification through Markov Decision Processes (MDPs), assuming either known or finite-state models, which limits their applicability to DRL settings with unknown, continuous-state systems. This paper addresses these limitations by proposing a data-driven shielding methodology that guarantees safety for unknown systems under black-box controllers. The approach leverages Deep Kernel Learning to model the systems' one-step evolution with uncertainty quantification and constructs a finite-state abstraction as an Interval MDP (IMDP). By focusing on safety properties expressed in safe linear temporal logic (safe LTL), we develop an algorithm that computes the maximally permissive set of safe policies on the IMDP, ensuring avoidance of unsafe states. The algorithms soundness and computational complexity are demonstrated through theoretical proofs and experiments on nonlinear systems, including a high-dimensional autonomous spacecraft scenario.
Error Bounds For Gaussian Process Regression Under Bounded Support Noise With Applications To Safety Certification
Aug 16, 2024



Gaussian Process Regression (GPR) is a powerful and elegant method for learning complex functions from noisy data with a wide range of applications, including in safety-critical domains. Such applications have two key features: (i) they require rigorous error quantification, and (ii) the noise is often bounded and non-Gaussian due to, e.g., physical constraints. While error bounds for applying GPR in the presence of non-Gaussian noise exist, they tend to be overly restrictive and conservative in practice. In this paper, we provide novel error bounds for GPR under bounded support noise. Specifically, by relying on concentration inequalities and assuming that the latent function has low complexity in the reproducing kernel Hilbert space (RKHS) corresponding to the GP kernel, we derive both probabilistic and deterministic bounds on the error of the GPR. We show that these errors are substantially tighter than existing state-of-the-art bounds and are particularly well-suited for GPR with neural network kernels, i.e., Deep Kernel Learning (DKL). Furthermore, motivated by applications in safety-critical domains, we illustrate how these bounds can be combined with stochastic barrier functions to successfully quantify the safety probability of an unknown dynamical system from finite data. We validate the efficacy of our approach through several benchmarks and comparisons against existing bounds. The results show that our bounds are consistently smaller, and that DKLs can produce error bounds tighter than sample noise, significantly improving the safety probability of control systems.
Shielded Deep Reinforcement Learning for Complex Spacecraft Tasking
Mar 14, 2024
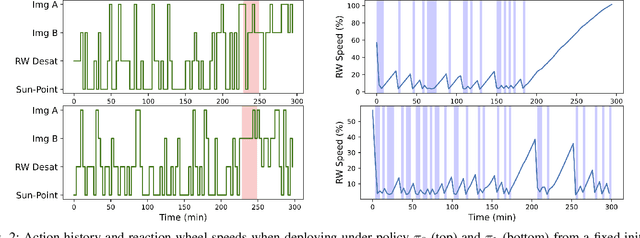


Autonomous spacecraft control via Shielded Deep Reinforcement Learning (SDRL) has become a rapidly growing research area. However, the construction of shields and the definition of tasking remains informal, resulting in policies with no guarantees on safety and ambiguous goals for the RL agent. In this paper, we first explore the use of formal languages, namely Linear Temporal Logic (LTL), to formalize spacecraft tasks and safety requirements. We then define a manner in which to construct a reward function from a co-safe LTL specification automatically for effective training in SDRL framework. We also investigate methods for constructing a shield from a safe LTL specification for spacecraft applications and propose three designs that provide probabilistic guarantees. We show how these shields interact with different policies and the flexibility of the reward structure through several experiments.
Promises of Deep Kernel Learning for Control Synthesis
Sep 12, 2023



Deep Kernel Learning (DKL) combines the representational power of neural networks with the uncertainty quantification of Gaussian Processes. Hence, it is potentially a promising tool to learn and control complex dynamical systems. In this work, we develop a scalable abstraction-based framework that enables the use of DKL for control synthesis of stochastic dynamical systems against complex specifications. Specifically, we consider temporal logic specifications and create an end-to-end framework that uses DKL to learn an unknown system from data and formally abstracts the DKL model into an Interval Markov Decision Process (IMDP) to perform control synthesis with correctness guarantees. Furthermore, we identify a deep architecture that enables accurate learning and efficient abstraction computation. The effectiveness of our approach is illustrated on various benchmarks, including a 5-D nonlinear stochastic system, showing how control synthesis with DKL can substantially outperform state-of-the-art competitive methods.