 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaskConnect: Connectivity Learning by Gradient Descent
Jul 28, 2018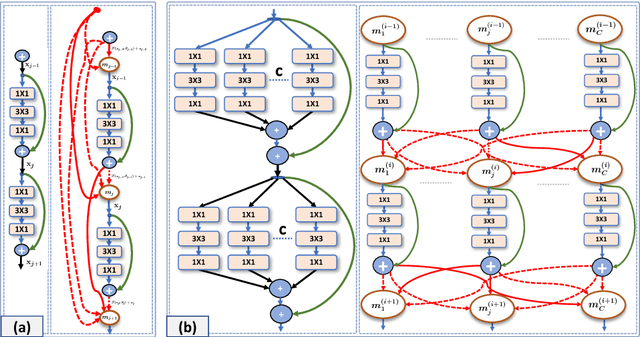

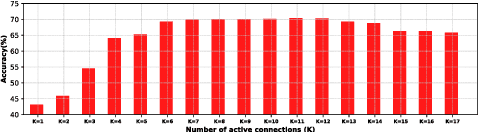
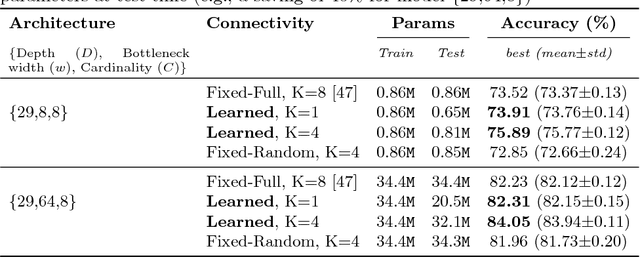
Although deep networks have recently emerged as the model of choice for many computer vision problems, in order to yield good results they often require time-consuming architecture search. To combat the complexity of design choices, prior work has adopted the principle of modularized design which consists in defining the network in terms of a composition of topologically identical or similar building blocks (a.k.a. modules). This reduces architecture search to the problem of determining the number of modules to compose and how to connect such modules. Again, for reasons of design complexity and training cost, previous approaches have relied on simple rules of connectivity, e.g., connecting each module to only the immediately preceding module or perhaps to all of the previous ones. Such simple connectivity rules are unlikely to yield the optimal architecture for the given problem. In this work we remove these predefined choices and propose an algorithm to learn the connections between modules in the network. Instead of being chosen a priori by the human designer, the connectivity is learned simultaneously with the weights of the network by optimizing the loss function of the end task using a modified version of gradient descent. We demonstrate our connectivity learning method on the problem of multi-class image classification using two popular architectures: ResNet and ResNeXt. Experiments on four different datasets show that connectivity learning using our approach yields consistently higher accuracy compared to relying on traditional predefined rules of connectivity. Furthermore, in certain settings it leads to significant savings in number of parameters.
Object Detection in Video with Spatiotemporal Sampling Networks
Jul 24, 2018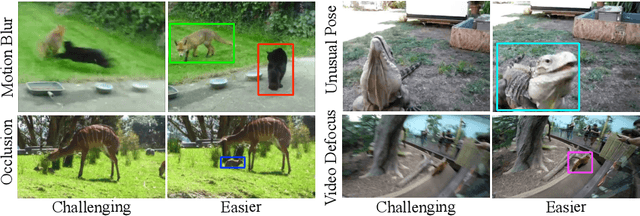

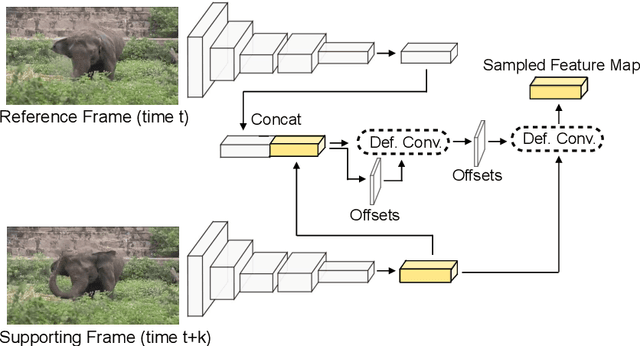
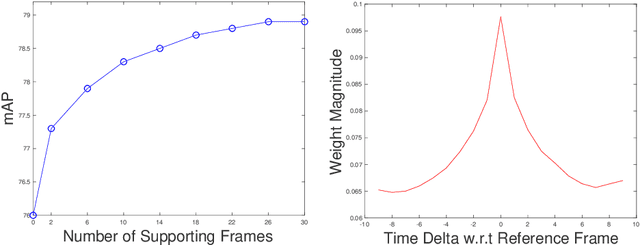
We propose a Spatiotemporal Sampling Network (STSN) that uses deformable convolutions across time for object detection in videos. Our STSN performs object detection in a video frame by learning to spatially sample features from the adjacent frames. This naturally renders the approach robust to occlusion or motion blur in individual frames. Our framework does not require additional supervision, as it optimizes sampling locations directly with respect to object detection performance. Our STSN outperforms the state-of-the-art on the ImageNet VID dataset and compared to prior video object detection methods it uses a simpler design, and does not require optical flow data for training.
Co-Training of Audio and Video Representations from Self-Supervised Temporal Synchronization
Jun 30, 2018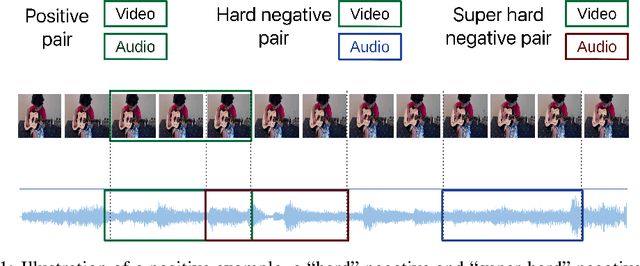

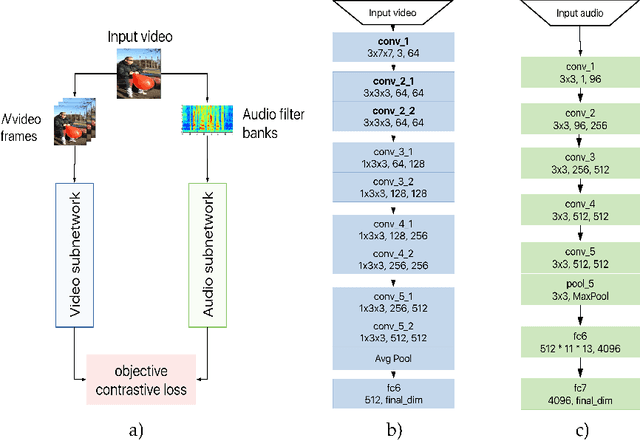
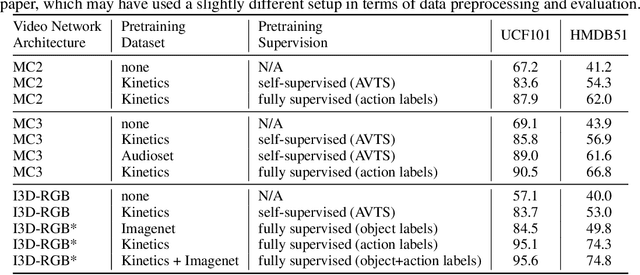
There is a natural correlation between the visual and auditive elements of a video. In this work we leverage this connection to learn general and effective features for both audio and video analysis from self-supervised temporal synchronization. We demonstrate that a calibrated curriculum learning scheme, a careful choice of negative examples, and the use of a contrastive loss are critical ingredients to obtain powerful multi-sensory representations from models optimized to discern temporal synchronization of audio-video pairs. Without further finetuning, the resulting audio features achieve performance superior or comparable to the state-of-the-art on established audio classification benchmarks (DCASE2014 and ESC-50). At the same time, our visual subnet provides a very effective initialization to improve the accuracy of video-based action recognition models: compared to learning from scratch, our self-supervised pretraining yields a remarkable gain of +16.7% in action recognition accuracy on UCF101 and a boost of +13.0% on HMDB51.
Detect-and-Track: Efficient Pose Estimation in Videos
May 02, 2018

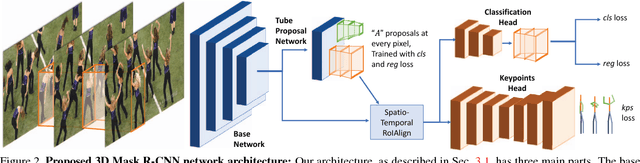

This paper addresses the problem of estimating and tracking human body keypoints in complex, multi-person video. We propose an extremely lightweight yet highly effective approach that builds upon the latest advancements in human detection and video understanding. Our method operates in two-stages: keypoint estimation in frames or short clips, followed by lightweight tracking to generate keypoint predictions linked over the entire video. For frame-level pose estimation we experiment with Mask R-CNN, as well as our own proposed 3D extension of this model, which leverages temporal information over small clips to generate more robust frame predictions. We conduct extensive ablative experiments on the newly released multi-person video pose estimation benchmark, PoseTrack, to validate various design choices of our model. Our approach achieves an accuracy of 55.2% on the validation and 51.8% on the test set using the Multi-Object Tracking Accuracy (MOTA) metric, and achieves state of the art performance on the ICCV 2017 PoseTrack keypoint tracking challenge.
A Closer Look at Spatiotemporal Convolutions for Action Recognition
Apr 12, 2018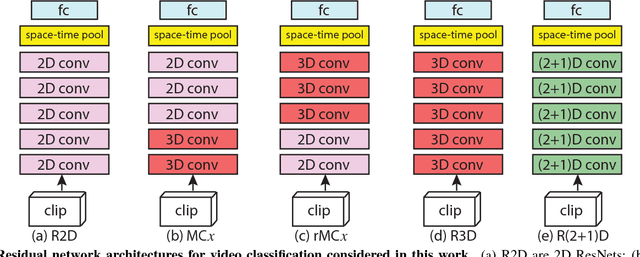
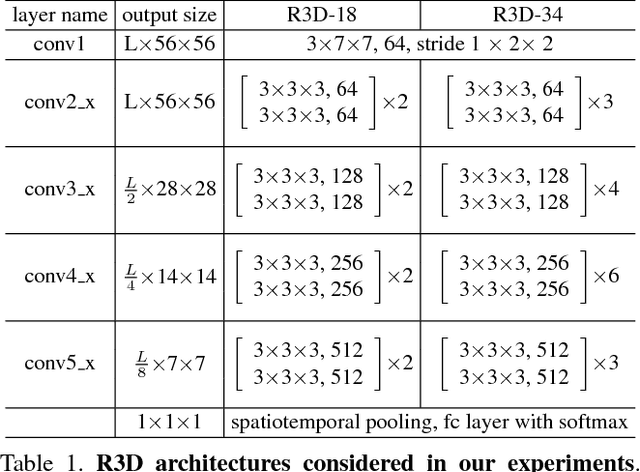
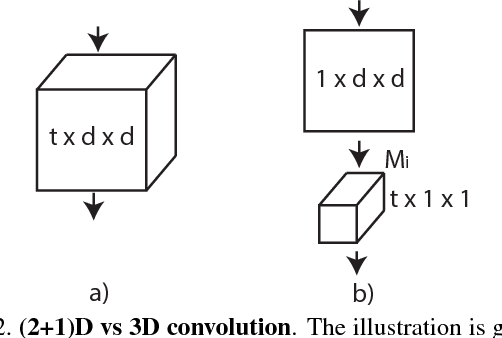
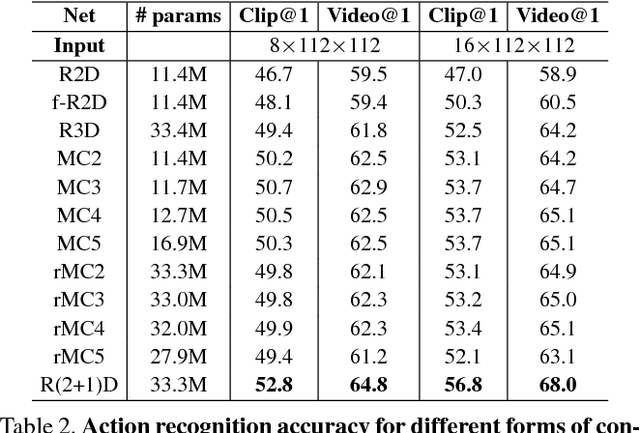
In this paper we discuss several forms of spatiotemporal convolutions for video analysis and study their effects on action recognition. Our motivation stems from the observation that 2D CNNs applied to individual frames of the video have remained solid performers in action recognition. In this work we empirically demonstrate the accuracy advantages of 3D CNNs over 2D CNNs within the framework of residual learning. Furthermore, we show that factorizing the 3D convolutional filters into separate spatial and temporal components yields significantly advantages in accuracy. Our empirical study leads to the design of a new spatiotemporal convolutional block "R(2+1)D" which gives rise to CNNs that achieve results comparable or superior to the state-of-the-art on Sports-1M, Kinetics, UCF101 and HMDB51.
SLAC: A Sparsely Labeled Dataset for Action Classification and Localization
Dec 26, 2017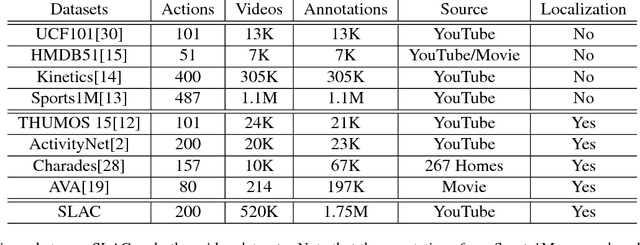
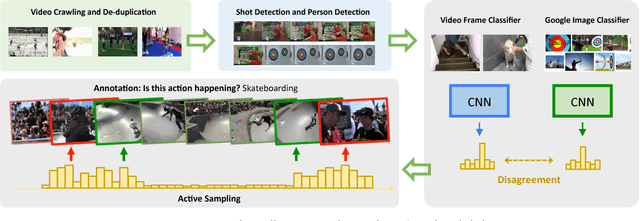


This paper describes a procedure for the creation of large-scale video datasets for action classification and localization from unconstrained, realistic web data. The scalability of the proposed procedure is demonstrated by building a novel video benchmark, named SLAC (Sparsely Labeled ACtions), consisting of over 520K untrimmed videos and 1.75M clip annotations spanning 200 action categories. Using our proposed framework, annotating a clip takes merely 8.8 seconds on average. This represents a saving in labeling time of over 95% compared to the traditional procedure of manual trimming and localization of actions. Our approach dramatically reduces the amount of human labeling by automatically identifying hard clips, i.e., clips that contain coherent actions but lead to prediction disagreement between action classifiers. A human annotator can disambiguate whether such a clip truly contains the hypothesized action in a handful of seconds, thus generating labels for highly informative samples at little cost. We show that our large-scale dataset can be used to effectively pre-train action recognition models, significantly improving final metrics on smaller-scale benchmarks after fine-tuning. On Kinetics, UCF-101 and HMDB-51, models pre-trained on SLAC outperform baselines trained from scratch, by 2.0%, 20.1% and 35.4% in top-1 accuracy, respectively when RGB input is used. Furthermore, we introduce a simple procedure that leverages the sparse labels in SLAC to pre-train action localization models. On THUMOS14 and ActivityNet-v1.3, our localization model improves the mAP of baseline model by 8.6% and 2.5%, respectively.
Connectivity Learning in Multi-Branch Networks
Dec 07, 2017
While much of the work in the design of convolutional networks over the last five years has revolved around the empirical investigation of the importance of depth, filter sizes, and number of feature channels, recent studies have shown that branching, i.e., splitting the computation along parallel but distinct threads and then aggregating their outputs, represents a new promising dimension for significant improvements in performance. To combat the complexity of design choices in multi-branch architectures, prior work has adopted simple strategies, such as a fixed branching factor, the same input being fed to all parallel branches, and an additive combination of the outputs produced by all branches at aggregation points. In this work we remove these predefined choices and propose an algorithm to learn the connections between branches in the network. Instead of being chosen a priori by the human designer, the multi-branch connectivity is learned simultaneously with the weights of the network by optimizing a single loss function defined with respect to the end task. We demonstrate our approach on the problem of multi-class image classification using three different datasets where it yields consistently higher accuracy compared to the state-of-the-art "ResNeXt" multi-branch network given the same learning capacity.
Learning to Inpaint for Image Compression
Nov 10, 2017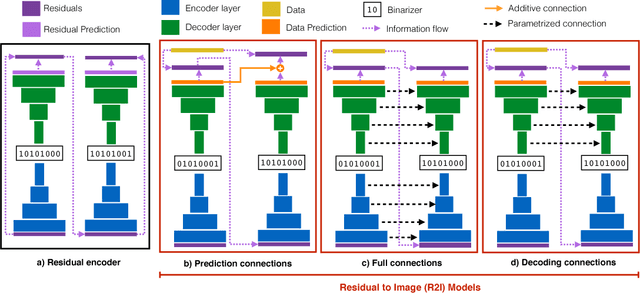

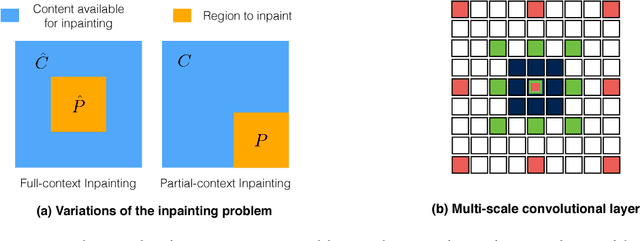
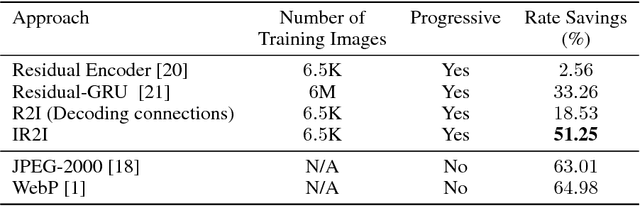
We study the design of deep architectures for lossy image compression. We present two architectural recipes in the context of multi-stage progressive encoders and empirically demonstrate their importance on compression performance. Specifically, we show that: (a) predicting the original image data from residuals in a multi-stage progressive architecture facilitates learning and leads to improved performance at approximating the original content and (b) learning to inpaint (from neighboring image pixels) before performing compression reduces the amount of information that must be stored to achieve a high-quality approximation. Incorporating these design choices in a baseline progressive encoder yields an average reduction of over $60\%$ in file size with similar quality compared to the original residual encoder.
VideoMCC: a New Benchmark for Video Comprehension
Jun 16, 2017

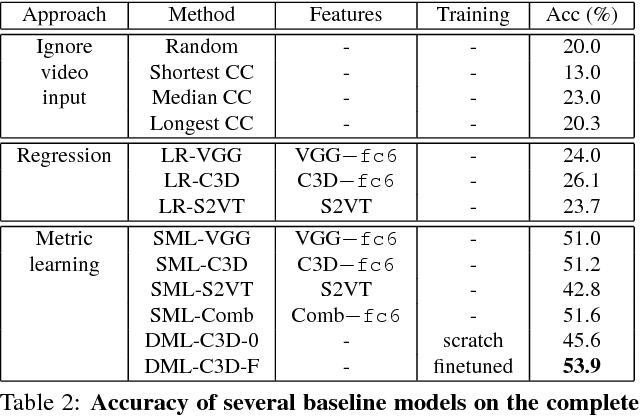
While there is overall agreement that future technology for organizing, browsing and searching videos hinges on the development of methods for high-level semantic understanding of video, so far no consensus has been reached on the best way to train and assess models for this task. Casting video understanding as a form of action or event categorization is problematic as it is not fully clear what the semantic classes or abstractions in this domain should be. Language has been exploited to sidestep the problem of defining video categories, by formulating video understanding as the task of captioning or description. However, language is highly complex, redundant and sometimes ambiguous. Many different captions may express the same semantic concept. To account for this ambiguity, quantitative evaluation of video description requires sophisticated metrics, whose performance scores are typically hard to interpret by humans. This paper provides four contributions to this problem. First, we formulate Video Multiple Choice Caption (VideoMCC) as a new well-defined task with an easy-to-interpret performance measure. Second, we describe a general semi-automatic procedure to create benchmarks for this task. Third, we publicly release a large-scale video benchmark created with an implementation of this procedure and we include a human study that assesses human performance on our dataset. Finally, we propose and test a varied collection of approaches on this benchmark for the purpose of gaining a better understanding of the new challenges posed by video comprehension.
Convolutional Random Walk Networks for Semantic Image Segmentation
May 08, 2017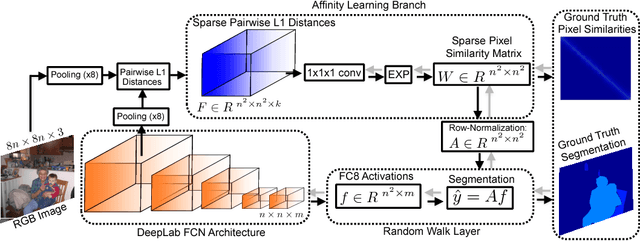


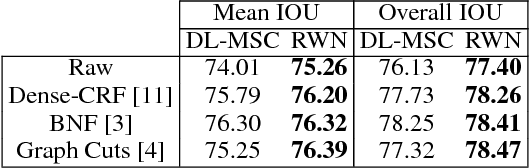
Most current semantic segmentation methods rely on fully convolutional networks (FCNs). However, their use of large receptive fields and many pooling layers cause low spatial resolution inside the deep layers. This leads to predictions with poor localization around the boundaries. Prior work has attempted to address this issue by post-processing predictions with CRFs or MRFs. But such models often fail to capture semantic relationships between objects, which causes spatially disjoint predictions. To overcome these problems, recent methods integrated CRFs or MRFs into an FCN framework. The downside of these new models is that they have much higher complexity than traditional FCNs, which renders training and testing more challenging. In this work we introduce a simple, yet effective Convolutional Random Walk Network (RWN) that addresses the issues of poor boundary localization and spatially fragmented predictions with very little increase in model complexity. Our proposed RWN jointly optimizes the objectives of pixelwise affinity and semantic segmentation. It combines these two objectives via a novel random walk layer that enforces consistent spatial grouping in the deep layers of the network. Our RWN is implemented using standard convolution and matrix multiplication. This allows an easy integration into existing FCN frameworks and it enables end-to-end training of the whole network via standard back-propagation. Our implementation of RWN requires just $131$ additional parameters compared to the traditional FCNs, and yet it consistently produces an improvement over the FCNs on semantic segmentation and scene labeling.