 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Prediction for CRiSP Inverse Kinematics Learning with Misspecified Robot Models
Mar 01, 2021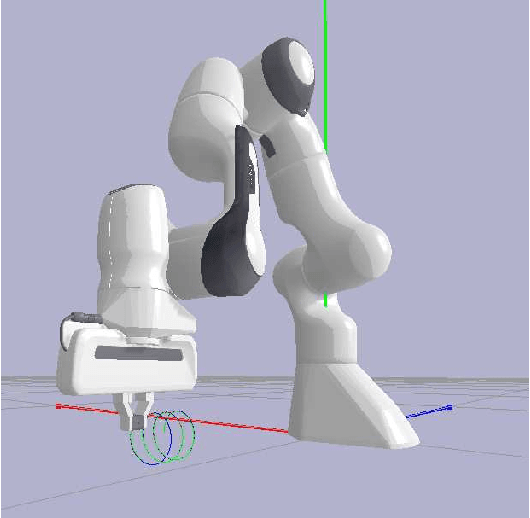
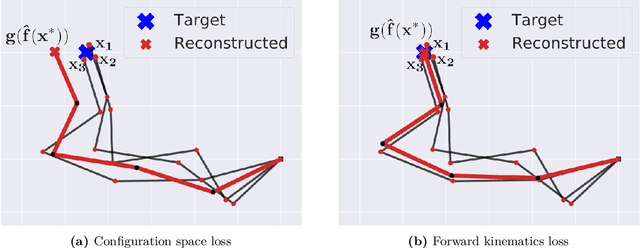
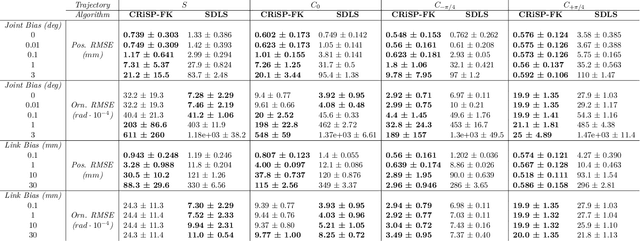
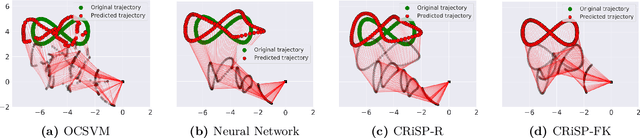
With the recent advances in machine learning, problems that traditionally would require accurate modeling to be solved analytically can now be successfully approached with data-driven strategies. Among these, computing the inverse kinematics of a redundant robot arm poses a significant challenge due to the non-linear structure of the robot, the hard joint constraints and the non-invertible kinematics map. Moreover, most learning algorithms consider a completely data-driven approach, while often useful information on the structure of the robot is available and should be positively exploited. In this work, we present a simple, yet effective, approach for learning the inverse kinematics. We introduce a structured prediction algorithm that combines a data-driven strategy with the model provided by a forward kinematics function -- even when this function is misspeficied -- to accurately solve the problem. The proposed approach ensures that predicted joint configurations are well within the robot's constraints. We also provide statistical guarantees on the generalization properties of our estimator as well as an empirical evaluation of its performance on trajectory reconstruction tasks.
Data-efficient Weakly-supervised Learning for On-line Object Detection under Domain Shift in Robotics
Dec 28, 2020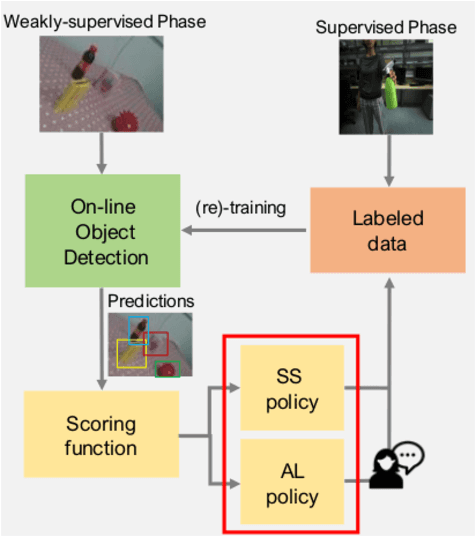
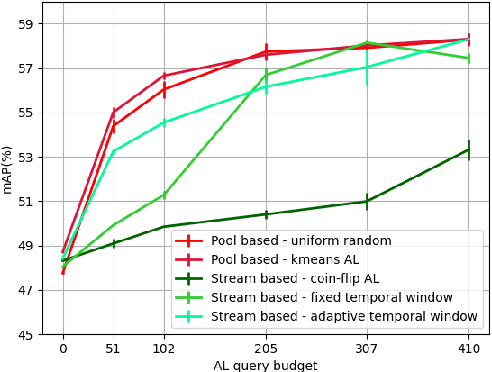

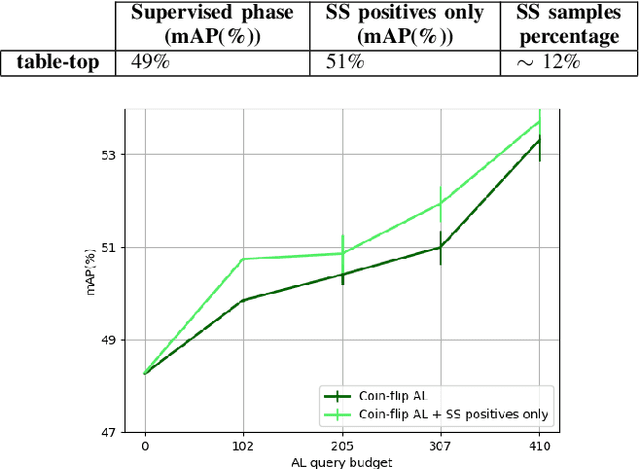
Several object detection methods have recently been proposed in the literature, the vast majority based on Deep Convolutional Neural Networks (DCNNs). Such architectures have been shown to achieve remarkable performance, at the cost of computationally expensive batch training and extensive labeling. These methods have important limitations for robotics: Learning solely on off-line data may introduce biases (the so-called domain shift), and prevents adaptation to novel tasks. In this work, we investigate how weakly-supervised learning can cope with these problems. We compare several techniques for weakly-supervised learning in detection pipelines to reduce model (re)training costs without compromising accuracy. In particular, we show that diversity sampling for constructing active learning queries and strong positives selection for self-supervised learning enable significant annotation savings and improve domain shift adaptation. By integrating our strategies into a hybrid DCNN/FALKON on-line detection pipeline [1], our method is able to be trained and updated efficiently with few labels, overcoming limitations of previous work. We experimentally validate and benchmark our method on challenging robotic object detection tasks under domain shift.
Fast Object Segmentation Learning with Kernel-based Methods for Robotics
Nov 25, 2020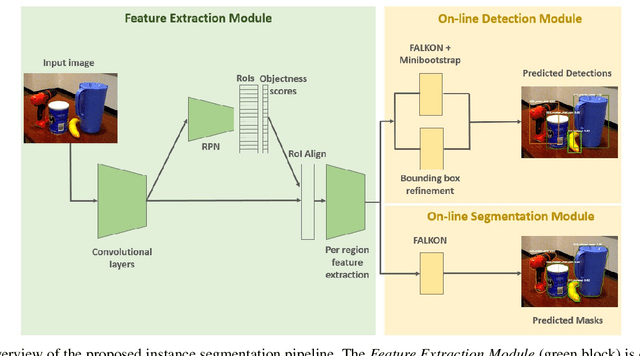

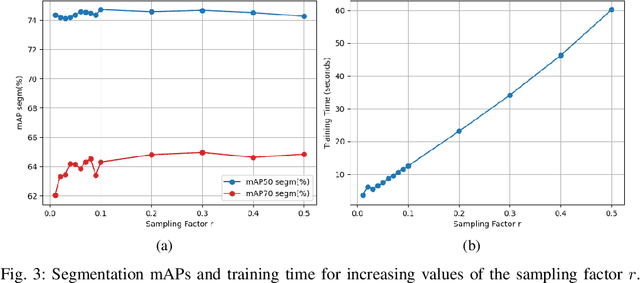

Object segmentation is a key component in the visual system of a robot that performs tasks like grasping and object manipulation, especially in presence of occlusions. Like many other Computer Vision tasks, the adoption of deep architectures has made available algorithms that perform this task with remarkable performance. However, adoption of such algorithms in robotics is hampered by the fact that training requires large amount of computing time and it cannot be performed on-line. In this work, we propose a novel architecture for object segmentation, that overcomes this problem and provides comparable performance in a fraction of the time required by the state-of-the-art methods. Our approach is based on a pre-trained Mask R-CNN, in which various layers have been replaced with a set of classifiers and regressors that are retrained for a new task. We employ an efficient Kernel-based method that allows for fast training on large scale problems. Our approach is validated on the YCB-Video dataset which is widely adopted in the Computer Vision and Robotics community, demonstrating that we can achieve and even surpass performance of the state-of-the-art, with a significant reduction (${\sim}6\times$) of the training time. The code will be released upon acceptance.
Fast Region Proposal Learning for Object Detection for Robotics
Nov 25, 2020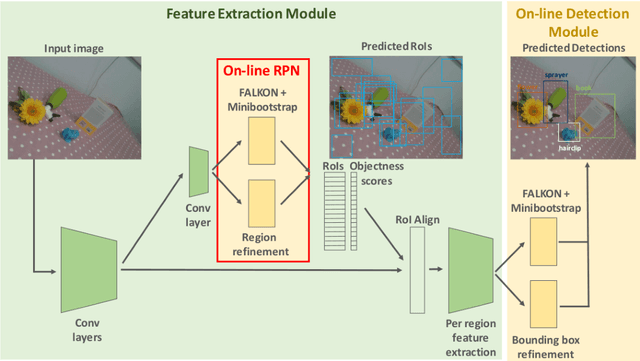
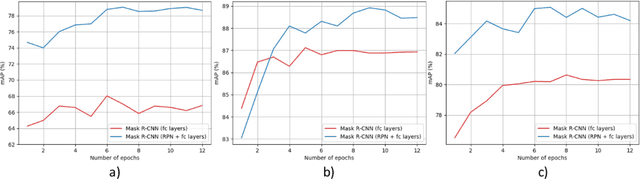
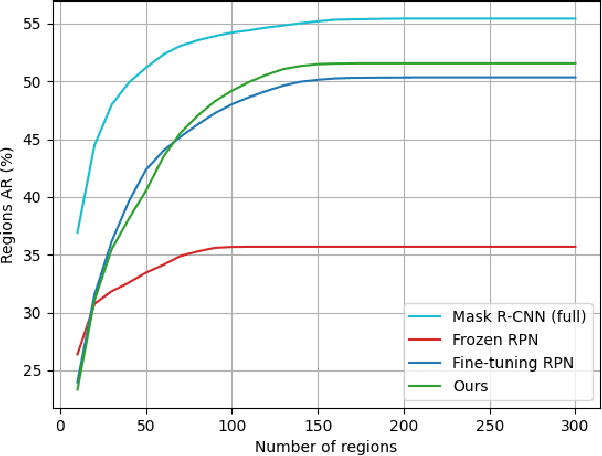
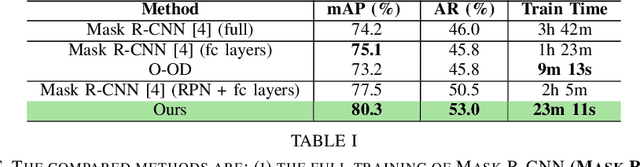
Object detection is a fundamental task for robots to operate in unstructured environments. Today, there are several deep learning algorithms that solve this task with remarkable performance. Unfortunately, training such systems requires several hours of GPU time. For robots, to successfully adapt to changes in the environment or learning new objects, it is also important that object detectors can be re-trained in a short amount of time. A recent method [1] proposes an architecture that leverages on the powerful representation of deep learning descriptors, while permitting fast adaptation time. Leveraging on the natural decomposition of the task in (i) regions candidate generation, (ii) feature extraction and (iii) regions classification, this method performs fast adaptation of the detector, by only re-training the classification layer. This shortens training time while maintaining state-of-the-art performance. In this paper, we firstly demonstrate that a further boost in accuracy can be obtained by adapting, in addition, the regions candidate generation on the task at hand. Secondly, we extend the object detection system presented in [1] with the proposed fast learning approach, showing experimental evidence on the improvement provided in terms of speed and accuracy on two different robotics datasets. The code to reproduce the experiments is publicly available on GitHub.
Decentralised Learning with Random Features and Distributed Gradient Descent
Jul 01, 2020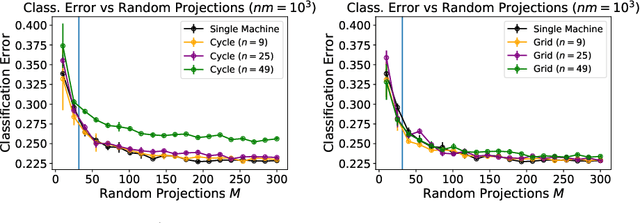
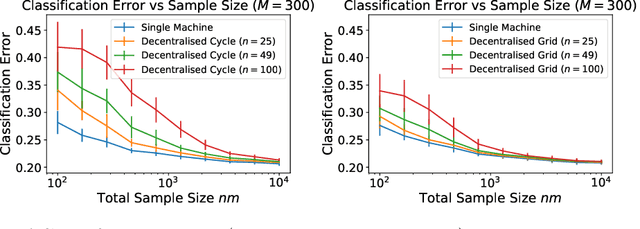
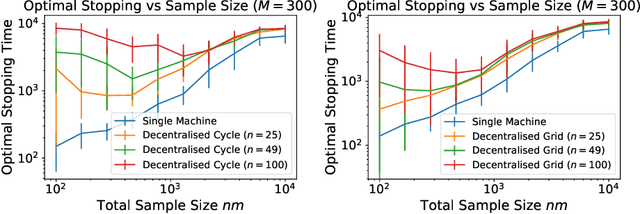
We investigate the generalisation performance of Distributed Gradient Descent with Implicit Regularisation and Random Features in the homogenous setting where a network of agents are given data sampled independently from the same unknown distribution. Along with reducing the memory footprint, Random Features are particularly convenient in this setting as they provide a common parameterisation across agents that allows to overcome previous difficulties in implementing Decentralised Kernel Regression. Under standard source and capacity assumptions, we establish high probability bounds on the predictive performance for each agent as a function of the step size, number of iterations, inverse spectral gap of the communication matrix and number of Random Features. By tuning these parameters, we obtain statistical rates that are minimax optimal with respect to the total number of samples in the network. The algorithm provides a linear improvement over single machine Gradient Descent in memory cost and, when agents hold enough data with respect to the network size and inverse spectral gap, a linear speed-up in computational runtime for any network topology. We present simulations that show how the number of Random Features, iterations and samples impact predictive performance.
For interpolating kernel machines, the minimum norm ERM solution is the most stable
Jun 28, 2020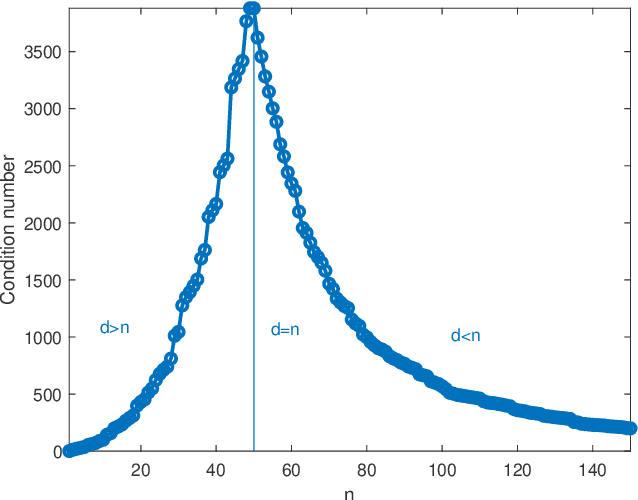
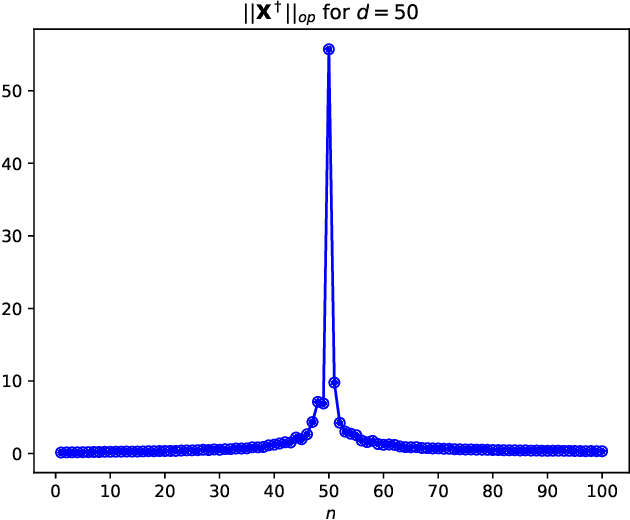
We study the average $\mbox{CV}_{loo}$ stability of kernel ridge-less regression and derive corresponding risk bounds. We show that the interpolating solution with minimum norm has the best $\mbox{CV}_{loo}$ stability, which in turn is controlled by the condition number of the empirical kernel matrix. The latter can be characterized in the asymptotic regime where both the dimension and cardinality of the data go to infinity. Under the assumption of random kernel matrices, the corresponding test error follows a double descent curve.
Kernel methods through the roof: handling billions of points efficiently
Jun 18, 2020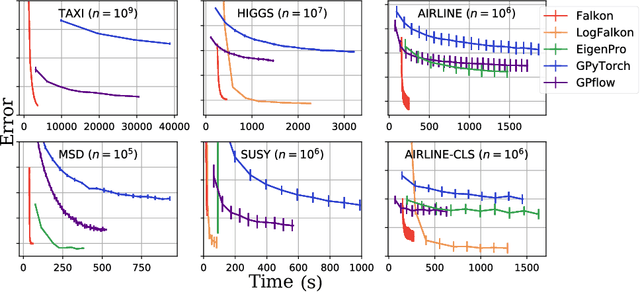
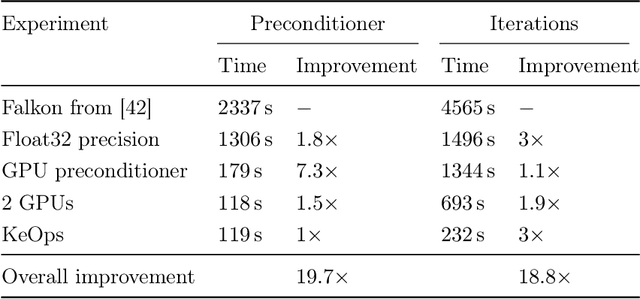

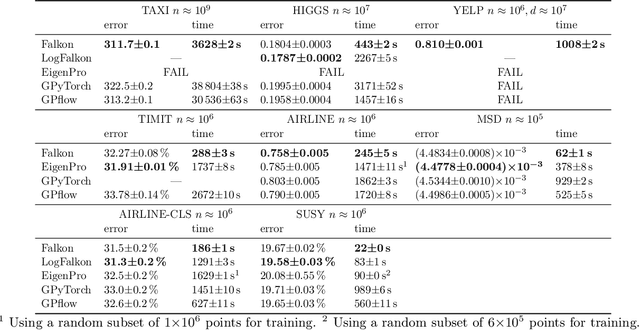
Kernel methods provide an elegant and principled approach to nonparametric learning, but so far could hardly be used in large scale problems, since na\"ive implementations scale poorly with data size. Recent advances have shown the benefits of a number of algorithmic ideas, for example combining optimization, numerical linear algebra and random projections. Here, we push these efforts further to develop and test a solver that takes full advantage of GPU hardware. Towards this end, we designed a preconditioned gradient solver for kernel methods exploiting both GPU acceleration and parallelization with multiple GPUs, implementing out-of-core variants of common linear algebra operations to guarantee optimal hardware utilization. Further, we optimize the numerical precision of different operations and maximize efficiency of matrix-vector multiplications. As a result we can experimentally show dramatic speedups on datasets with billions of points, while still guaranteeing state of the art performance. Additionally, we make our software available as an easy to use library.
Regularized ERM on random subspaces
Jun 17, 2020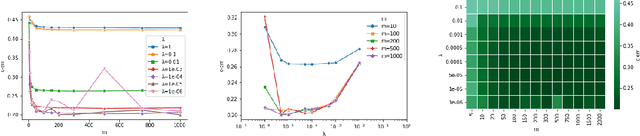
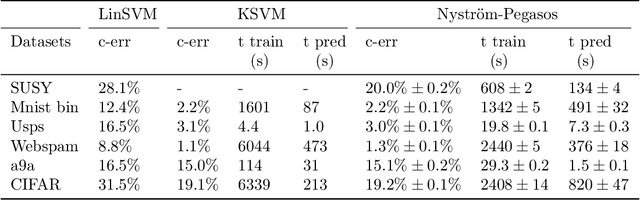
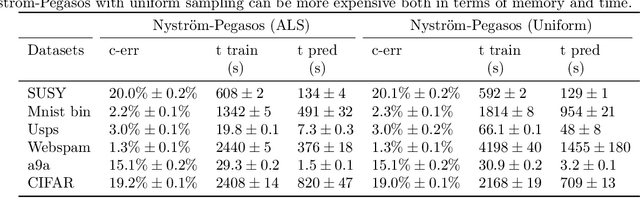
We study a natural extension of classical empirical risk minimization, where the hypothesis space is a random subspace of a given space. In particular, we consider possibly data dependent subspaces spanned by a random subset of the data. This approach naturally leads to computational savings, but the question is whether the corresponding learning accuracy is degraded. These statistical-computational tradeoffs have been recently explored for the least squares loss and self-concordant loss functions, such as the logistic loss. Here, we work to extend these results to convex Lipschitz loss functions, that might not be smooth, such as the hinge loss used in support vector machines. Our main results show the existence of different regimes, depending on how hard the learning problem is, for which computational efficiency can be improved with no loss in performance. Theoretical results are complemented with numerical experiments on large scale benchmark data sets.
Interpolation and Learning with Scale Dependent Kernels
Jun 17, 2020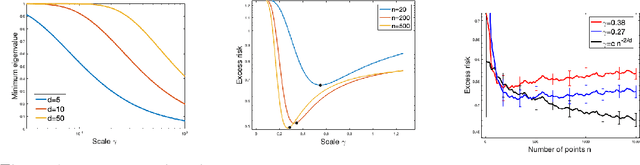
We study the learning properties of nonparametric ridge-less least squares. In particular, we consider the common case of estimators defined by scale dependent kernels, and focus on the role of the scale. These estimators interpolate the data and the scale can be shown to control their stability through the condition number. Our analysis shows that are different regimes depending on the interplay between the sample size, its dimensions, and the smoothness of the problem. Indeed, when the sample size is less than exponential in the data dimension, then the scale can be chosen so that the learning error decreases. As the sample size becomes larger, the overall error stop decreasing but interestingly the scale can be chosen in such a way that the variance due to noise remains bounded. Our analysis combines, probabilistic results with a number of analytic techniques from interpolation theory.
Implicit regularization for convex regularizers
Jun 17, 2020
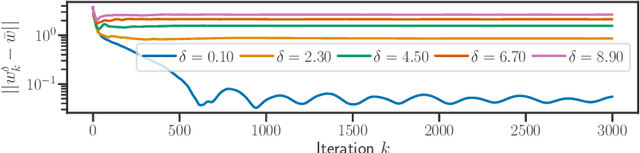
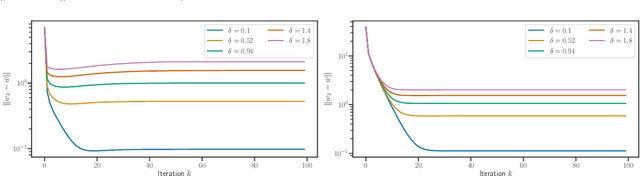
We study implicit regularization for over-parameterized linear models, when the bias is convex but not necessarily strongly convex. We characterize the regularization property of a primal-dual gradient based approach, analyzing convergence and especially stability in the presence of worst case deterministic noise. As a main example, we specialize and illustrate the results for the problem of robust sparse recovery. Key to our analysis is a combination of ideas from regularization theory and optimization in the presence of errors. Theoretical results are complemented by experiments showing that state-of-the-art performances are achieved with considerable computational speed-ups.