 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving $\ell^p\!$-norm regularization with tensor kernels
Oct 18, 2017
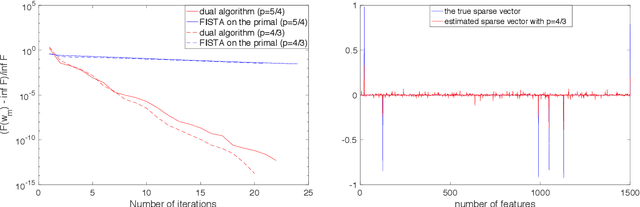
In this paper, we discuss how a suitable family of tensor kernels can be used to efficiently solve nonparametric extensions of $\ell^p$ regularized learning methods. Our main contribution is proposing a fast dual algorithm, and showing that it allows to solve the problem efficiently. Our results contrast recent findings suggesting kernel methods cannot be extended beyond Hilbert setting. Numerical experiments confirm the effectiveness of the method.
Consistent Multitask Learning with Nonlinear Output Relations
Aug 10, 2017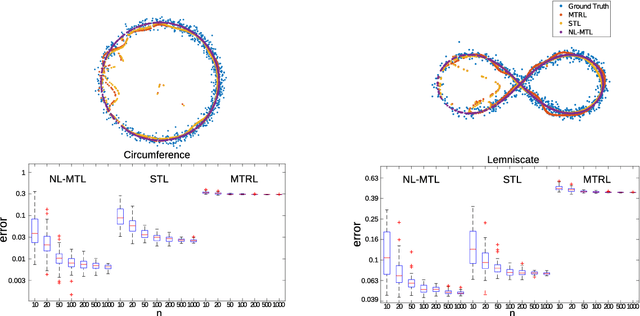


Key to multitask learning is exploiting relationships between different tasks to improve prediction performance. If the relations are linear, regularization approaches can be used successfully. However, in practice assuming the tasks to be linearly related might be restrictive, and allowing for nonlinear structures is a challenge. In this paper, we tackle this issue by casting the problem within the framework of structured prediction. Our main contribution is a novel algorithm for learning multiple tasks which are related by a system of nonlinear equations that their joint outputs need to satisfy. We show that the algorithm is consistent and can be efficiently implemented. Experimental results show the potential of the proposed method.
Convergence of the Forward-Backward Algorithm: Beyond the Worst Case with the Help of Geometry
Aug 01, 2017
We provide a comprehensive study of the convergence of forward-backward algorithm under suitable geometric conditions leading to fast rates. We present several new results and collect in a unified view a variety of results scattered in the literature, often providing simplified proofs. Novel contributions include the analysis of infinite dimensional convex minimization problems, allowing the case where minimizers might not exist. Further, we analyze the relation between different geometric conditions, and discuss novel connections with a priori conditions in linear inverse problems, including source conditions, restricted isometry properties and partial smoothness.
A Consistent Regularization Approach for Structured Prediction
Jul 28, 2017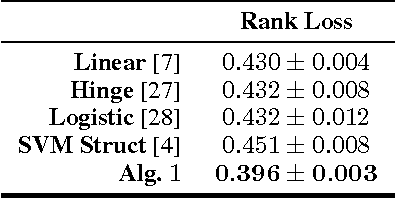

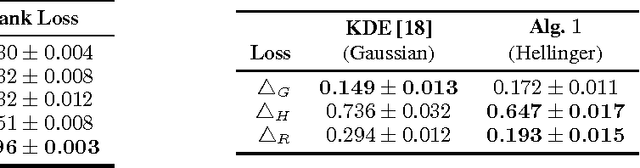
We propose and analyze a regularization approach for structured prediction problems. We characterize a large class of loss functions that allows to naturally embed structured outputs in a linear space. We exploit this fact to design learning algorithms using a surrogate loss approach and regularization techniques. We prove universal consistency and finite sample bounds characterizing the generalization properties of the proposed methods. Experimental results are provided to demonstrate the practical usefulness of the proposed approach.
Don't relax: early stopping for convex regularization
Jul 18, 2017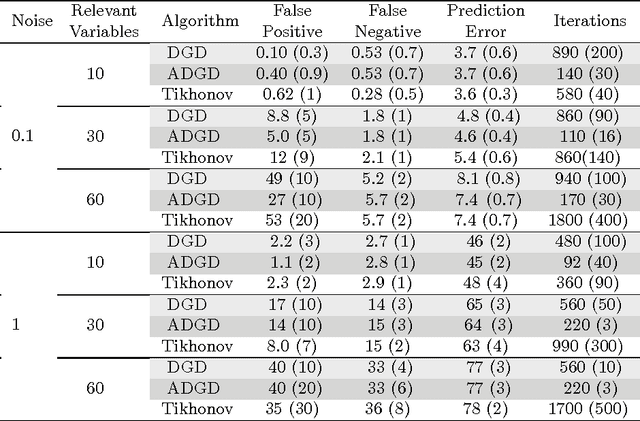

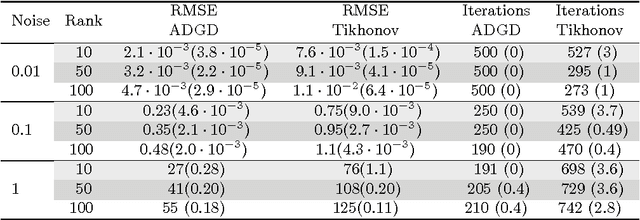
We consider the problem of designing efficient regularization algorithms when regularization is encoded by a (strongly) convex functional. Unlike classical penalization methods based on a relaxation approach, we propose an iterative method where regularization is achieved via early stopping. Our results show that the proposed procedure achieves the same recovery accuracy as penalization methods, while naturally integrating computational considerations. An empirical analysis on a number of problems provides promising results with respect to the state of the art.
Incremental Robot Learning of New Objects with Fixed Update Time
Feb 28, 2017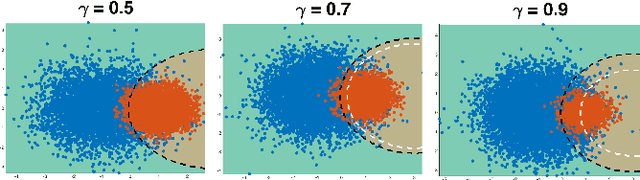
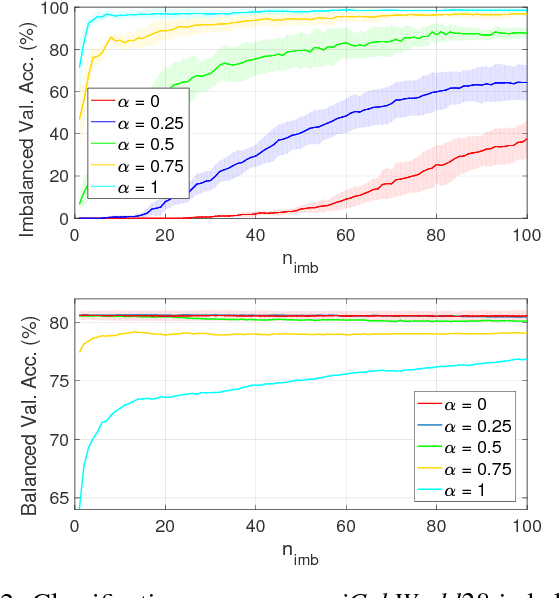
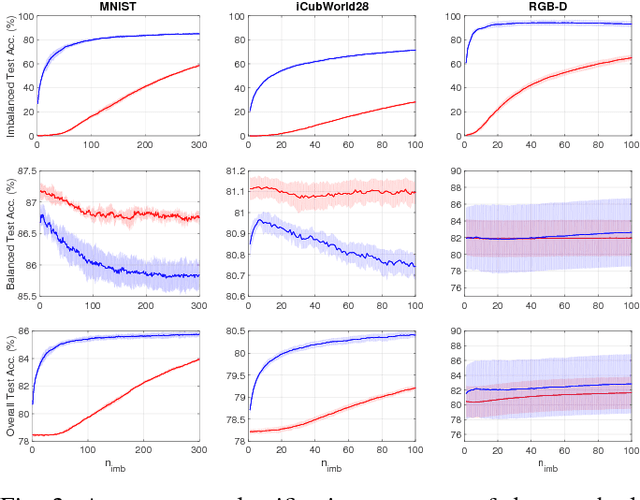
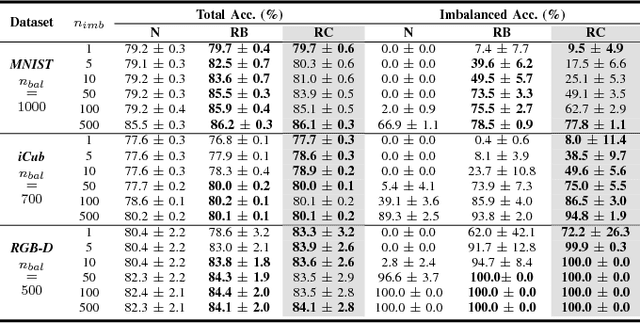
We consider object recognition in the context of lifelong learning, where a robotic agent learns to discriminate between a growing number of object classes as it accumulates experience about the environment. We propose an incremental variant of the Regularized Least Squares for Classification (RLSC) algorithm, and exploit its structure to seamlessly add new classes to the learned model. The presented algorithm addresses the problem of having an unbalanced proportion of training examples per class, which occurs when new objects are presented to the system for the first time. We evaluate our algorithm on both a machine learning benchmark dataset and two challenging object recognition tasks in a robotic setting. Empirical evidence shows that our approach achieves comparable or higher classification performance than its batch counterpart when classes are unbalanced, while being significantly faster.
Why and When Can Deep -- but Not Shallow -- Networks Avoid the Curse of Dimensionality: a Review
Feb 04, 2017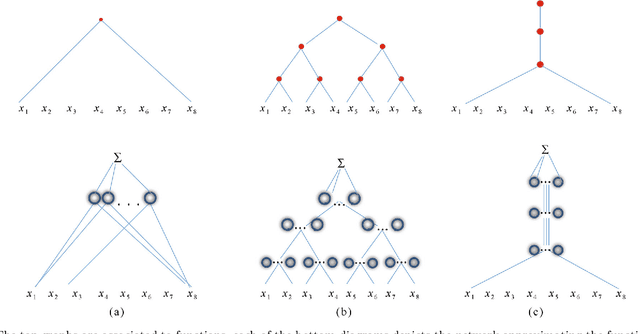
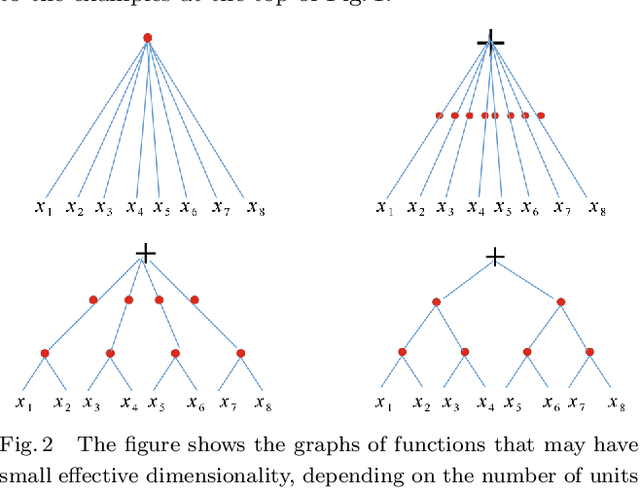
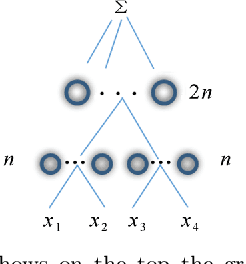
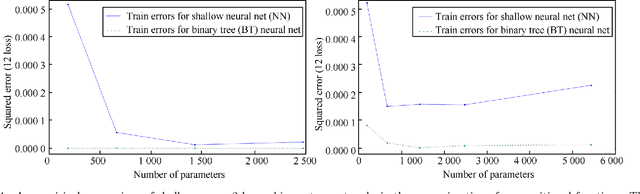
The paper characterizes classes of functions for which deep learning can be exponentially better than shallow learning. Deep convolutional networks are a special case of these conditions, though weight sharing is not the main reason for their exponential advantage.
Generalization Properties and Implicit Regularization for Multiple Passes SGM
May 26, 2016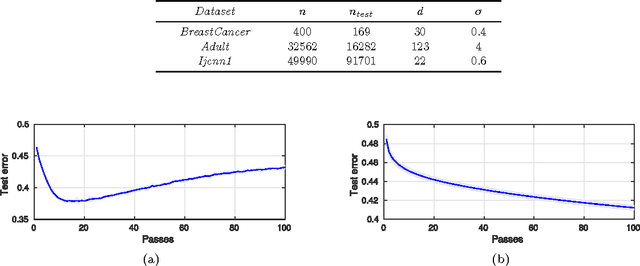
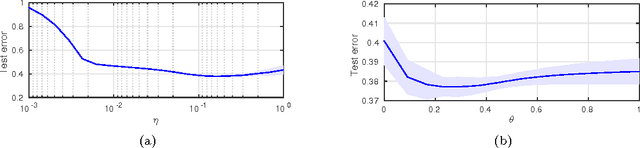
We study the generalization properties of stochastic gradient methods for learning with convex loss functions and linearly parameterized functions. We show that, in the absence of penalizations or constraints, the stability and approximation properties of the algorithm can be controlled by tuning either the step-size or the number of passes over the data. In this view, these parameters can be seen to control a form of implicit regularization. Numerical results complement the theoretical findings.
Less is More: Nyström Computational Regularization
Mar 17, 2016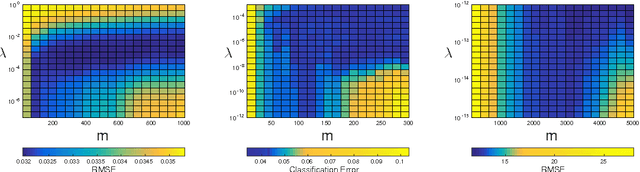

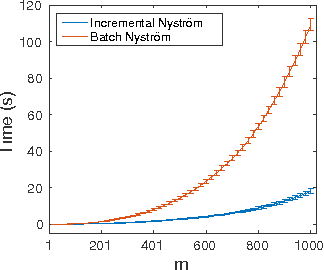
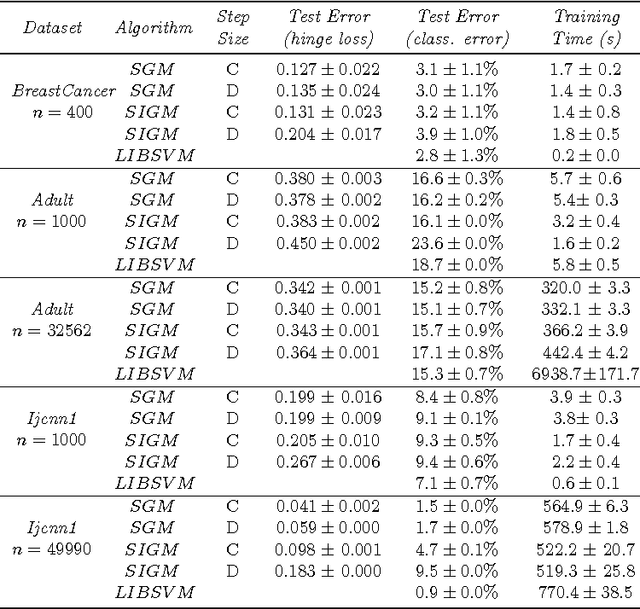
We study Nystr\"om type subsampling approaches to large scale kernel methods, and prove learning bounds in the statistical learning setting, where random sampling and high probability estimates are considered. In particular, we prove that these approaches can achieve optimal learning bounds, provided the subsampling level is suitably chosen. These results suggest a simple incremental variant of Nystr\"om Kernel Regularized Least Squares, where the subsampling level implements a form of computational regularization, in the sense that it controls at the same time regularization and computations. Extensive experimental analysis shows that the considered approach achieves state of the art performances on benchmark large scale datasets.
Incremental Semiparametric Inverse Dynamics Learning
Jan 18, 2016
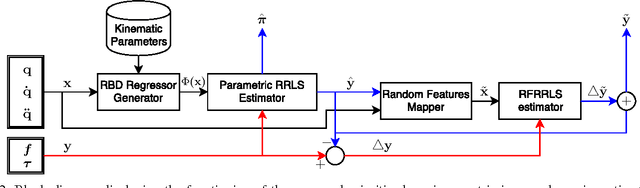
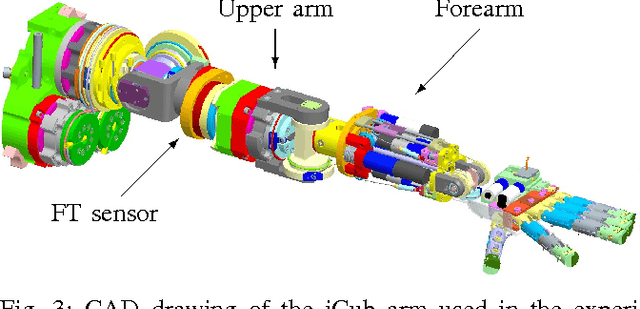
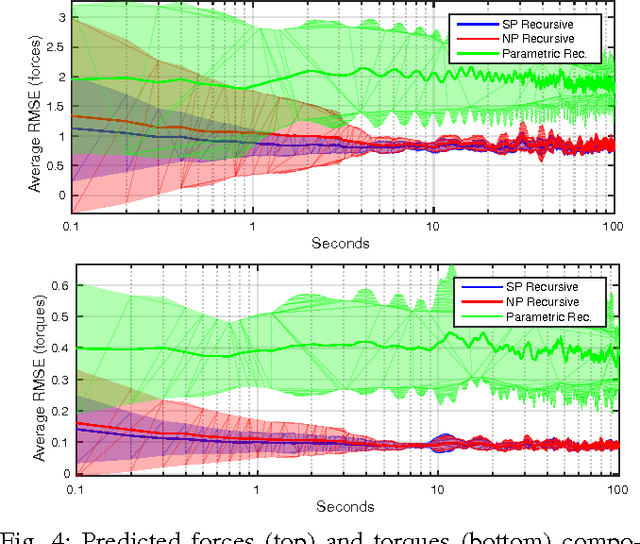
This paper presents a novel approach for incremental semiparametric inverse dynamics learning. In particular, we consider the mixture of two approaches: Parametric modeling based on rigid body dynamics equations and nonparametric modeling based on incremental kernel methods, with no prior information on the mechanical properties of the system. This yields to an incremental semiparametric approach, leveraging the advantages of both the parametric and nonparametric models. We validate the proposed technique learning the dynamics of one arm of the iCub humanoid robot.