 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Your AI-Generated Code Really Safe? Evaluating Large Language Models on Secure Code Generation with CodeSecEval
Jul 04, 2024



Large language models (LLMs) have brought significant advancements to code generation and code repair, benefiting both novice and experienced developers. However, their training using unsanitized data from open-source repositories, like GitHub, raises the risk of inadvertently propagating security vulnerabilities. Despite numerous studies investigating the safety of code LLMs, there remains a gap in comprehensively addressing their security features. In this work, we aim to present a comprehensive study aimed at precisely evaluating and enhancing the security aspects of code LLMs. To support our research, we introduce CodeSecEval, a meticulously curated dataset designed to address 44 critical vulnerability types with 180 distinct samples. CodeSecEval serves as the foundation for the automatic evaluation of code models in two crucial tasks: code generation and code repair, with a strong emphasis on security. Our experimental results reveal that current models frequently overlook security issues during both code generation and repair processes, resulting in the creation of vulnerable code. In response, we propose different strategies that leverage vulnerability-aware information and insecure code explanations to mitigate these security vulnerabilities. Furthermore, our findings highlight that certain vulnerability types particularly challenge model performance, influencing their effectiveness in real-world applications. Based on these findings, we believe our study will have a positive impact on the software engineering community, inspiring the development of improved methods for training and utilizing LLMs, thereby leading to safer and more trustworthy model deployment.
Is Your AI-Generated Code Really Secure? Evaluating Large Language Models on Secure Code Generation with CodeSecEval
Jul 02, 2024Large language models (LLMs) have brought significant advancements to code generation and code repair, benefiting both novice and experienced developers. However, their training using unsanitized data from open-source repositories, like GitHub, raises the risk of inadvertently propagating security vulnerabilities. Despite numerous studies investigating the safety of code LLMs, there remains a gap in comprehensively addressing their security features. In this work, we aim to present a comprehensive study aimed at precisely evaluating and enhancing the security aspects of code LLMs. To support our research, we introduce CodeSecEval, a meticulously curated dataset designed to address 44 critical vulnerability types with 180 distinct samples. CodeSecEval serves as the foundation for the automatic evaluation of code models in two crucial tasks: code generation and code repair, with a strong emphasis on security. Our experimental results reveal that current models frequently overlook security issues during both code generation and repair processes, resulting in the creation of vulnerable code. In response, we propose different strategies that leverage vulnerability-aware information and insecure code explanations to mitigate these security vulnerabilities. Furthermore, our findings highlight that certain vulnerability types particularly challenge model performance, influencing their effectiveness in real-world applications. Based on these findings, we believe our study will have a positive impact on the software engineering community, inspiring the development of improved methods for training and utilizing LLMs, thereby leading to safer and more trustworthy model deployment.
Enhancing Large Language Models for Secure Code Generation: A Dataset-driven Study on Vulnerability Mitigation
Oct 25, 2023



Large language models (LLMs) have brought significant advancements to code generation, benefiting both novice and experienced developers. However, their training using unsanitized data from open-source repositories, like GitHub, introduces the risk of inadvertently propagating security vulnerabilities. To effectively mitigate this concern, this paper presents a comprehensive study focused on evaluating and enhancing code LLMs from a software security perspective. We introduce SecuCoGen\footnote{SecuCoGen has been uploaded as supplemental material and will be made publicly available after publication.}, a meticulously curated dataset targeting 21 critical vulnerability types. SecuCoGen comprises 180 samples and serves as the foundation for conducting experiments on three crucial code-related tasks: code generation, code repair and vulnerability classification, with a strong emphasis on security. Our experimental results reveal that existing models often overlook security concerns during code generation, leading to the generation of vulnerable code. To address this, we propose effective approaches to mitigate the security vulnerabilities and enhance the overall robustness of code generated by LLMs. Moreover, our study identifies weaknesses in existing models' ability to repair vulnerable code, even when provided with vulnerability information. Additionally, certain vulnerability types pose challenges for the models, hindering their performance in vulnerability classification. Based on these findings, we believe our study will have a positive impact on the software engineering community, inspiring the development of improved methods for training and utilizing LLMs, thereby leading to safer and more trustworthy model deployment.
A Label Dependence-aware Sequence Generation Model for Multi-level Implicit Discourse Relation Recognition
Dec 22, 2021
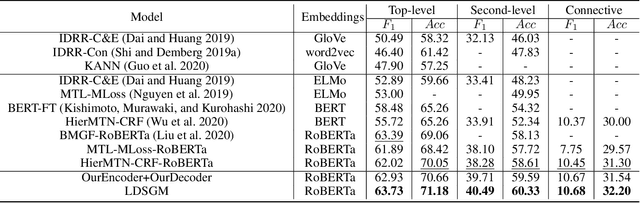
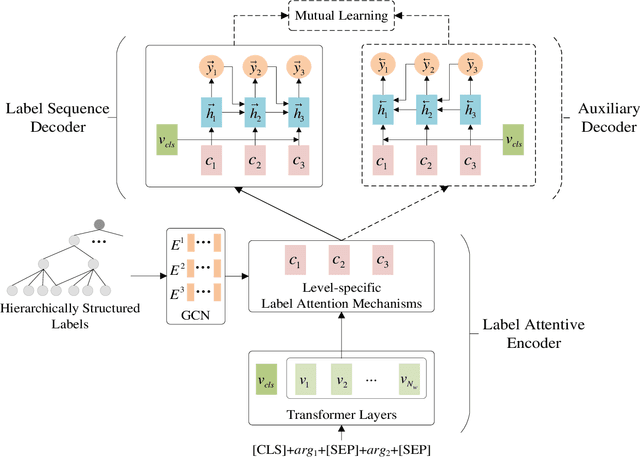
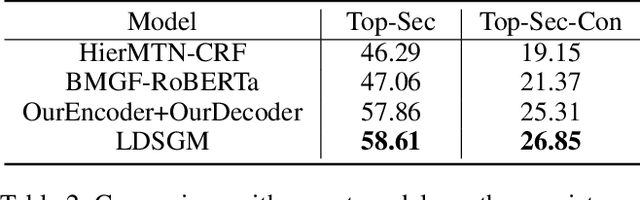
Implicit discourse relation recognition (IDRR) is a challenging but crucial task in discourse analysis. Most existing methods train multiple models to predict multi-level labels independently, while ignoring the dependence between hierarchically structured labels. In this paper, we consider multi-level IDRR as a conditional label sequence generation task and propose a Label Dependence-aware Sequence Generation Model (LDSGM) for it. Specifically, we first design a label attentive encoder to learn the global representation of an input instance and its level-specific contexts, where the label dependence is integrated to obtain better label embeddings. Then, we employ a label sequence decoder to output the predicted labels in a top-down manner, where the predicted higher-level labels are directly used to guide the label prediction at the current level. We further develop a mutual learning enhanced training method to exploit the label dependence in a bottomup direction, which is captured by an auxiliary decoder introduced during training. Experimental results on the PDTB dataset show that our model achieves the state-of-the-art performance on multi-level IDRR. We will release our code at https://github.com/nlpersECJTU/LDSGM.