 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWomen also Snowboard: Overcoming Bias in Captioning Models (Extended Abstract)
Jul 02, 2018
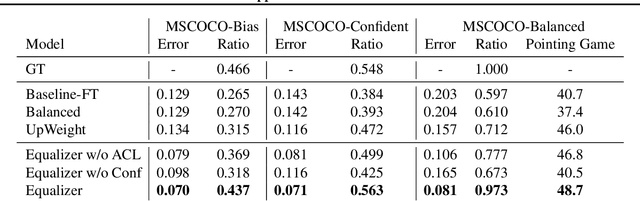
Most machine learning methods are known to capture and exploit biases of the training data. While some biases are beneficial for learning, others are harmful. Specifically, image captioning models tend to exaggerate biases present in training data. This can lead to incorrect captions in domains where unbiased captions are desired, or required, due to over reliance on the learned prior and image context. We investigate generation of gender specific caption words (e.g. man, woman) based on the person's appearance or the image context. We introduce a new Equalizer model that ensures equal gender probability when gender evidence is occluded in a scene and confident predictions when gender evidence is present. The resulting model is forced to look at a person rather than use contextual cues to make a gender specific prediction. The losses that comprise our model, the Appearance Confusion Loss and the Confident Loss, are general, and can be added to any description model in order to mitigate impacts of unwanted bias in a description dataset. Our proposed model has lower error than prior work when describing images with people and mentioning their gender and more closely matches the ground truth ratio of sentences including women to sentences including men.
Generating Counterfactual Explanations with Natural Language
Jun 26, 2018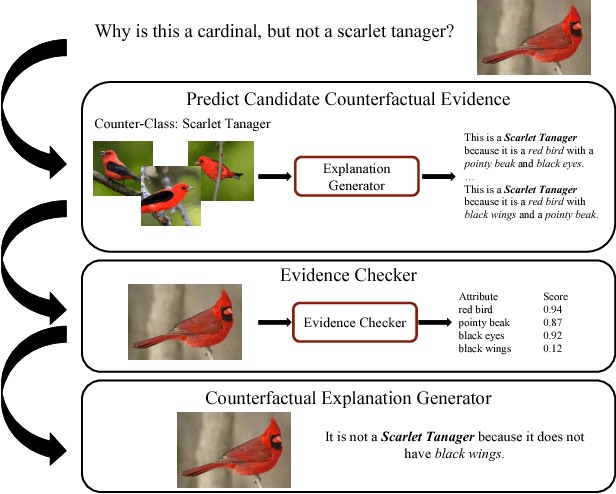


Natural language explanations of deep neural network decisions provide an intuitive way for a AI agent to articulate a reasoning process. Current textual explanations learn to discuss class discriminative features in an image. However, it is also helpful to understand which attributes might change a classification decision if present in an image (e.g., "This is not a Scarlet Tanager because it does not have black wings.") We call such textual explanations counterfactual explanations, and propose an intuitive method to generate counterfactual explanations by inspecting which evidence in an input is missing, but might contribute to a different classification decision if present in the image. To demonstrate our method we consider a fine-grained image classification task in which we take as input an image and a counterfactual class and output text which explains why the image does not belong to a counterfactual class. We then analyze our generated counterfactual explanations both qualitatively and quantitatively using proposed automatic metrics.
Women also Snowboard: Overcoming Bias in Captioning Models
Jun 18, 2018Most machine learning methods are known to capture and exploit biases of the training data. While some biases are beneficial for learning, others are harmful. Specifically, image captioning models tend to exaggerate biases present in training data (e.g., if a word is present in 60% of training sentences, it might be predicted in 70% of sentences at test time). This can lead to incorrect captions in domains where unbiased captions are desired, or required, due to over-reliance on the learned prior and image context. In this work we investigate generation of gender-specific caption words (e.g. man, woman) based on the person's appearance or the image context. We introduce a new Equalizer model that ensures equal gender probability when gender evidence is occluded in a scene and confident predictions when gender evidence is present. The resulting model is forced to look at a person rather than use contextual cues to make a gender-specific predictions. The losses that comprise our model, the Appearance Confusion Loss and the Confident Loss, are general, and can be added to any description model in order to mitigate impacts of unwanted bias in a description dataset. Our proposed model has lower error than prior work when describing images with people and mentioning their gender and more closely matches the ground truth ratio of sentences including women to sentences including men. We also show that unlike other approaches, our model is indeed more often looking at people when predicting their gender.
Multimodal Explanations: Justifying Decisions and Pointing to the Evidence
Feb 15, 2018
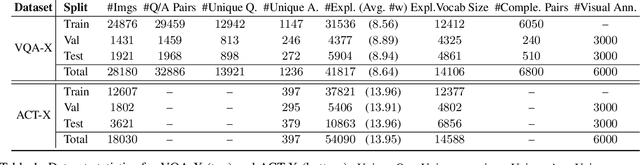

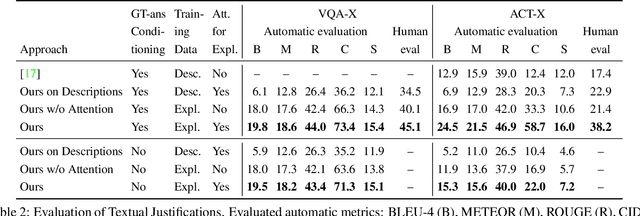
Deep models that are both effective and explainable are desirable in many settings; prior explainable models have been unimodal, offering either image-based visualization of attention weights or text-based generation of post-hoc justifications. We propose a multimodal approach to explanation, and argue that the two modalities provide complementary explanatory strengths. We collect two new datasets to define and evaluate this task, and propose a novel model which can provide joint textual rationale generation and attention visualization. Our datasets define visual and textual justifications of a classification decision for activity recognition tasks (ACT-X) and for visual question answering tasks (VQA-X). We quantitatively show that training with the textual explanations not only yields better textual justification models, but also better localizes the evidence that supports the decision. We also qualitatively show cases where visual explanation is more insightful than textual explanation, and vice versa, supporting our thesis that multimodal explanation models offer significant benefits over unimodal approaches.
Attentive Explanations: Justifying Decisions and Pointing to the Evidence (Extended Abstract)
Nov 17, 2017
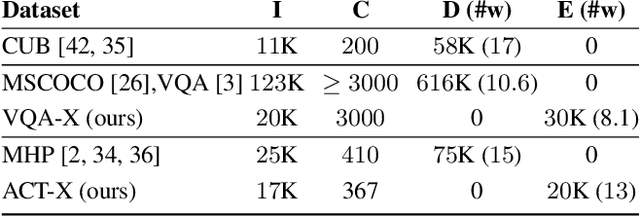

Deep models are the defacto standard in visual decision problems due to their impressive performance on a wide array of visual tasks. On the other hand, their opaqueness has led to a surge of interest in explainable systems. In this work, we emphasize the importance of model explanation in various forms such as visual pointing and textual justification. The lack of data with justification annotations is one of the bottlenecks of generating multimodal explanations. Thus, we propose two large-scale datasets with annotations that visually and textually justify a classification decision for various activities, i.e. ACT-X, and for question answering, i.e. VQA-X. We also introduce a multimodal methodology for generating visual and textual explanations simultaneously. We quantitatively show that training with the textual explanations not only yields better textual justification models, but also models that better localize the evidence that support their decision.
Grounding Visual Explanations
Nov 17, 2017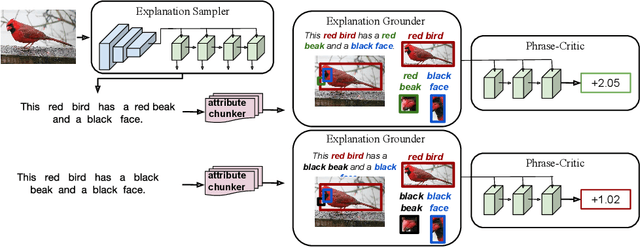

Existing models which generate textual explanations enforce task relevance through a discriminative term loss function, but such mechanisms only weakly constrain mentioned object parts to actually be present in the image. In this paper, a new model is proposed for generating explanations by utilizing localized grounding of constituent phrases in generated explanations to ensure image relevance. Specifically, we introduce a phrase-critic model to refine (re-score/re-rank) generated candidate explanations and employ a relative-attribute inspired ranking loss using "flipped" phrases as negative examples for training. At test time, our phrase-critic model takes an image and a candidate explanation as input and outputs a score indicating how well the candidate explanation is grounded in the image.
Speaking the Same Language: Matching Machine to Human Captions by Adversarial Training
Nov 06, 2017
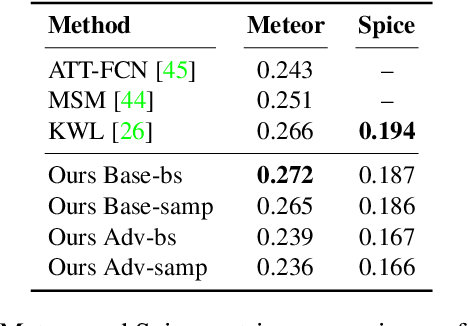
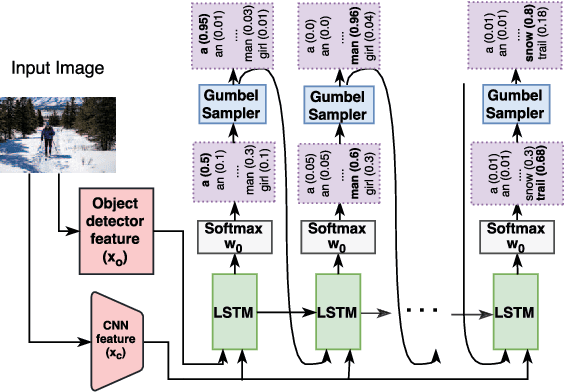
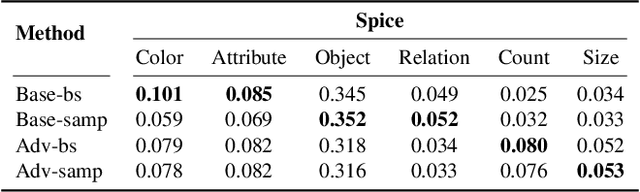
While strong progress has been made in image captioning over the last years, machine and human captions are still quite distinct. A closer look reveals that this is due to the deficiencies in the generated word distribution, vocabulary size, and strong bias in the generators towards frequent captions. Furthermore, humans -- rightfully so -- generate multiple, diverse captions, due to the inherent ambiguity in the captioning task which is not considered in today's systems. To address these challenges, we change the training objective of the caption generator from reproducing groundtruth captions to generating a set of captions that is indistinguishable from human generated captions. Instead of handcrafting such a learning target, we employ adversarial training in combination with an approximate Gumbel sampler to implicitly match the generated distribution to the human one. While our method achieves comparable performance to the state-of-the-art in terms of the correctness of the captions, we generate a set of diverse captions, that are significantly less biased and match the word statistics better in several aspects.
Localizing Moments in Video with Natural Language
Aug 04, 2017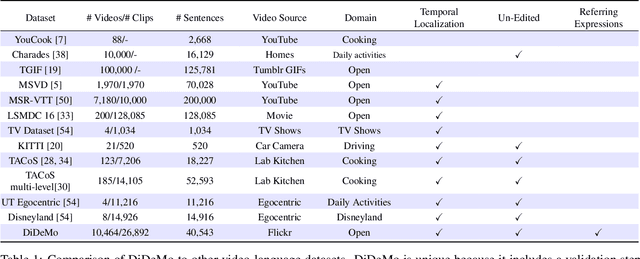
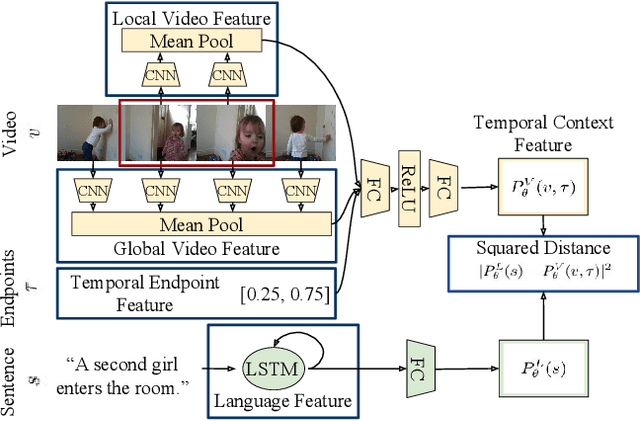
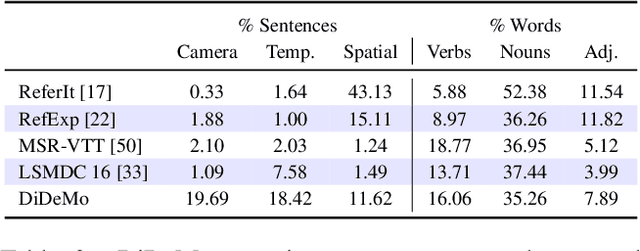
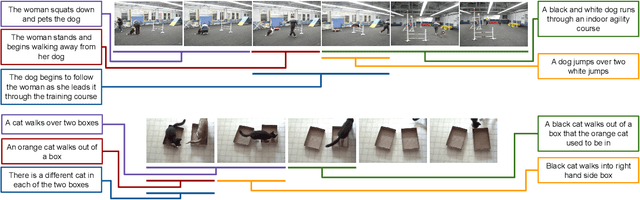
We consider retrieving a specific temporal segment, or moment, from a video given a natural language text description. Methods designed to retrieve whole video clips with natural language determine what occurs in a video but not when. To address this issue, we propose the Moment Context Network (MCN) which effectively localizes natural language queries in videos by integrating local and global video features over time. A key obstacle to training our MCN model is that current video datasets do not include pairs of localized video segments and referring expressions, or text descriptions which uniquely identify a corresponding moment. Therefore, we collect the Distinct Describable Moments (DiDeMo) dataset which consists of over 10,000 unedited, personal videos in diverse visual settings with pairs of localized video segments and referring expressions. We demonstrate that MCN outperforms several baseline methods and believe that our initial results together with the release of DiDeMo will inspire further research on localizing video moments with natural language.
Attentive Explanations: Justifying Decisions and Pointing to the Evidence
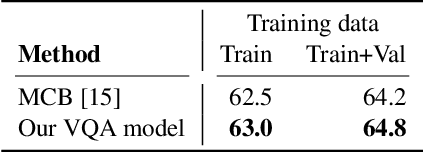
Jul 25, 2017Deep models are the defacto standard in visual decision models due to their impressive performance on a wide array of visual tasks. However, they are frequently seen as opaque and are unable to explain their decisions. In contrast, humans can justify their decisions with natural language and point to the evidence in the visual world which led to their decisions. We postulate that deep models can do this as well and propose our Pointing and Justification (PJ-X) model which can justify its decision with a sentence and point to the evidence by introspecting its decision and explanation process using an attention mechanism. Unfortunately there is no dataset available with reference explanations for visual decision making. We thus collect two datasets in two domains where it is interesting and challenging to explain decisions. First, we extend the visual question answering task to not only provide an answer but also a natural language explanation for the answer. Second, we focus on explaining human activities which is traditionally more challenging than object classification. We extensively evaluate our PJ-X model, both on the justification and pointing tasks, by comparing it to prior models and ablations using both automatic and human evaluations.
Captioning Images with Diverse Objects
Jul 20, 2017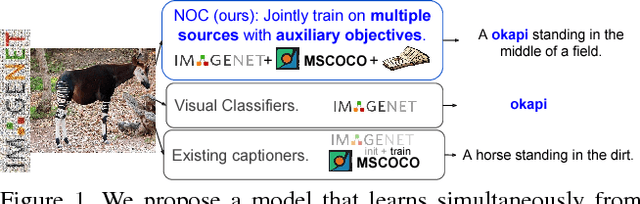

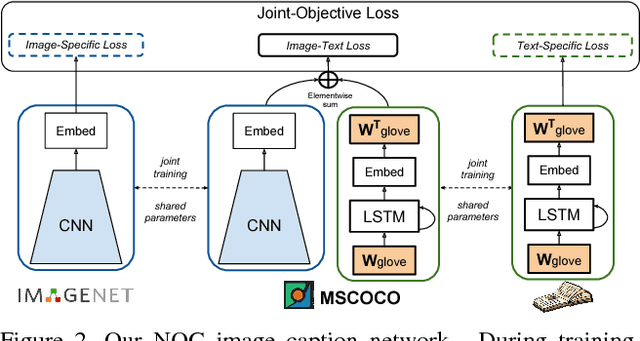
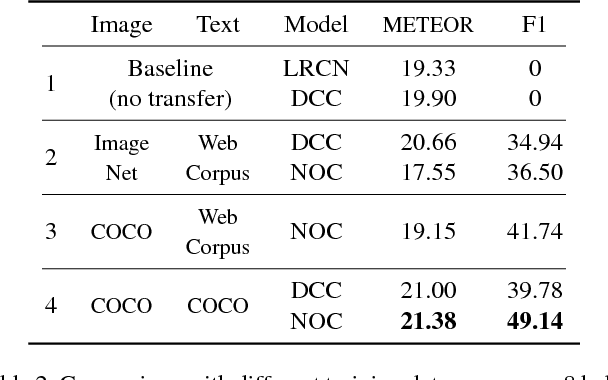
Recent captioning models are limited in their ability to scale and describe concepts unseen in paired image-text corpora. We propose the Novel Object Captioner (NOC), a deep visual semantic captioning model that can describe a large number of object categories not present in existing image-caption datasets. Our model takes advantage of external sources -- labeled images from object recognition datasets, and semantic knowledge extracted from unannotated text. We propose minimizing a joint objective which can learn from these diverse data sources and leverage distributional semantic embeddings, enabling the model to generalize and describe novel objects outside of image-caption datasets. We demonstrate that our model exploits semantic information to generate captions for hundreds of object categories in the ImageNet object recognition dataset that are not observed in MSCOCO image-caption training data, as well as many categories that are observed very rarely. Both automatic evaluations and human judgements show that our model considerably outperforms prior work in being able to describe many more categories of objects.