 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Sentiment for Sequence-to-sequence Chatbot Response with Performance Analysis
Apr 07, 2018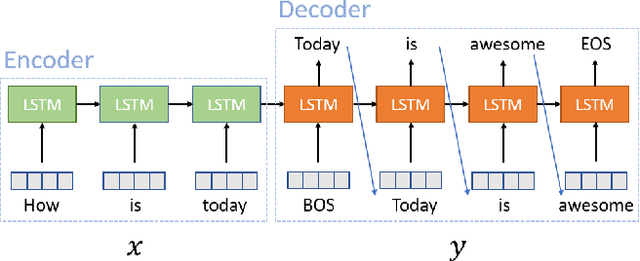
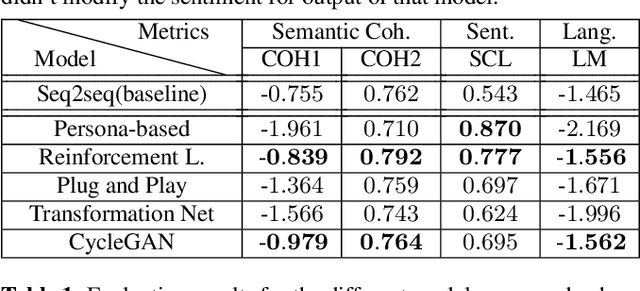
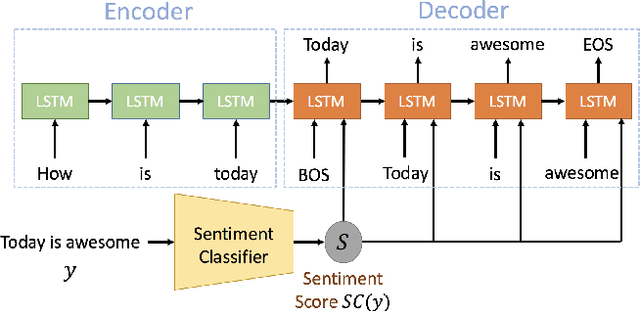
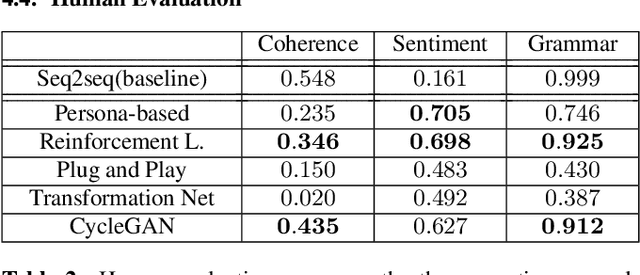
Conventional seq2seq chatbot models only try to find the sentences with the highest probabilities conditioned on the input sequences, without considering the sentiment of the output sentences. Some research works trying to modify the sentiment of the output sequences were reported. In this paper, we propose five models to scale or adjust the sentiment of the chatbot response: persona-based model, reinforcement learning, plug and play model, sentiment transformation network and cycleGAN, all based on the conventional seq2seq model. We also develop two evaluation metrics to estimate if the responses are reasonable given the input. These metrics together with other two popularly used metrics were used to analyze the performance of the five proposed models on different aspects, and reinforcement learning and cycleGAN were shown to be very attractive. The evaluation metrics were also found to be well correlated with human evaluation.
Completely Unsupervised Phoneme Recognition by Adversarially Learning Mapping Relationships from Audio Embeddings
Apr 01, 2018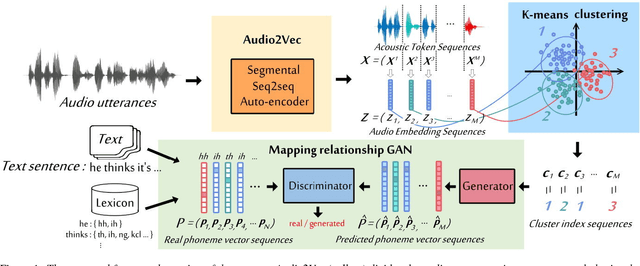

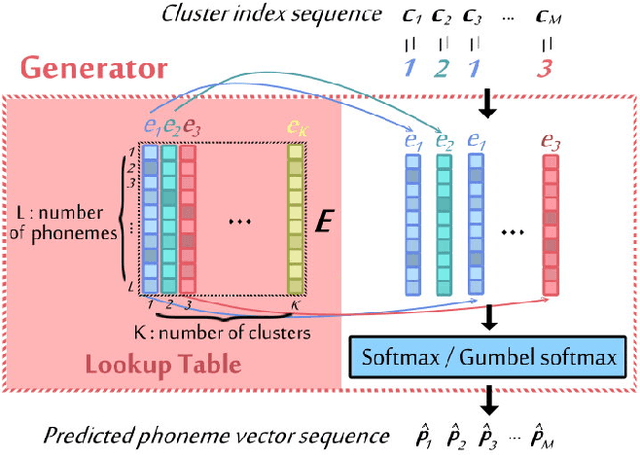
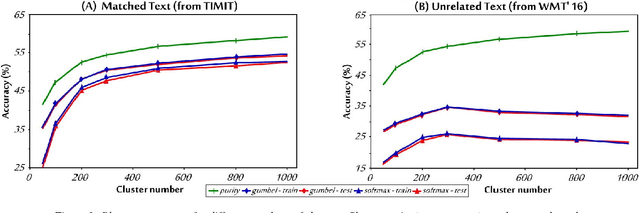
Unsupervised discovery of acoustic tokens from audio corpora without annotation and learning vector representations for these tokens have been widely studied. Although these techniques have been shown successful in some applications such as query-by-example Spoken Term Detection (STD), the lack of mapping relationships between these discovered tokens and real phonemes have limited the down-stream applications. This paper represents probably the first attempt towards the goal of completely unsupervised phoneme recognition, or mapping audio signals to phoneme sequences without phoneme-labeled audio data. The basic idea is to cluster the embedded acoustic tokens and learn the mapping between the cluster sequences and the unknown phoneme sequences with a Generative Adversarial Network (GAN). An unsupervised phoneme recognition accuracy of 36% was achieved in the preliminary experiments.
Order-Preserving Abstractive Summarization for Spoken Content Based on Connectionist Temporal Classification
Nov 16, 2017

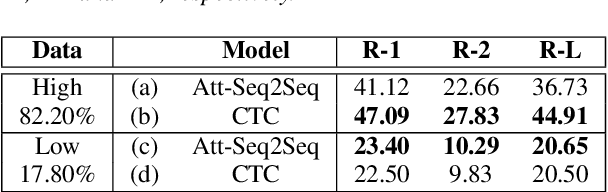
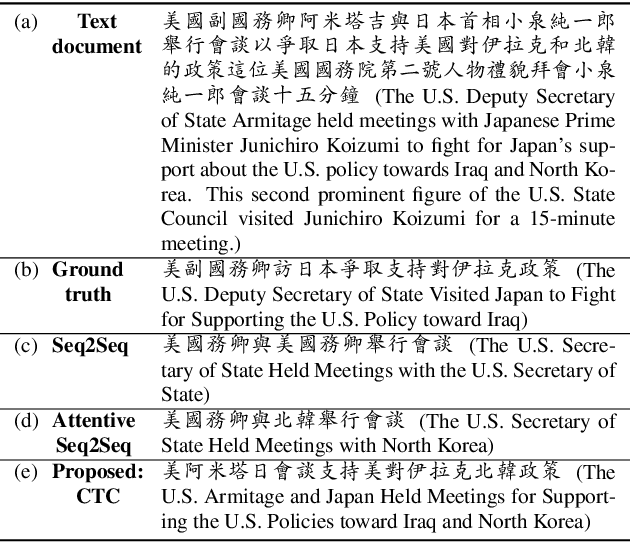
Connectionist temporal classification (CTC) is a powerful approach for sequence-to-sequence learning, and has been popularly used in speech recognition. The central ideas of CTC include adding a label "blank" during training. With this mechanism, CTC eliminates the need of segment alignment, and hence has been applied to various sequence-to-sequence learning problems. In this work, we applied CTC to abstractive summarization for spoken content. The "blank" in this case implies the corresponding input data are less important or noisy; thus it can be ignored. This approach was shown to outperform the existing methods in term of ROUGE scores over Chinese Gigaword and MATBN corpora. This approach also has the nice property that the ordering of words or characters in the input documents can be better preserved in the generated summaries.
Abstractive Headline Generation for Spoken Content by Attentive Recurrent Neural Networks with ASR Error Modeling
Dec 26, 2016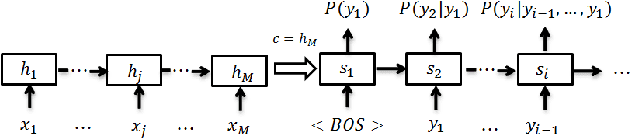
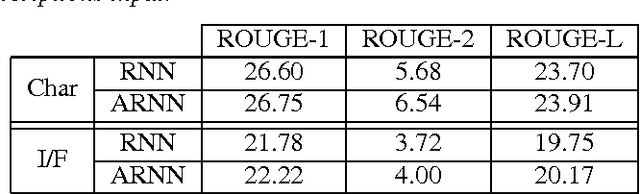
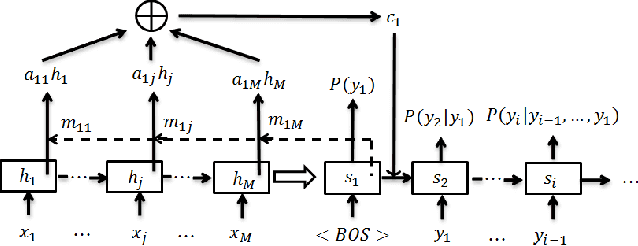
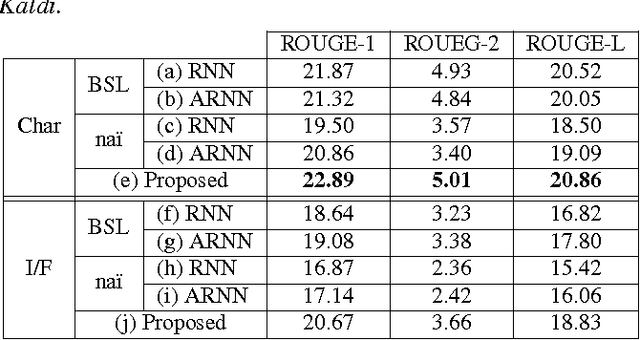
Headline generation for spoken content is important since spoken content is difficult to be shown on the screen and browsed by the user. It is a special type of abstractive summarization, for which the summaries are generated word by word from scratch without using any part of the original content. Many deep learning approaches for headline generation from text document have been proposed recently, all requiring huge quantities of training data, which is difficult for spoken document summarization. In this paper, we propose an ASR error modeling approach to learn the underlying structure of ASR error patterns and incorporate this model in an Attentive Recurrent Neural Network (ARNN) architecture. In this way, the model for abstractive headline generation for spoken content can be learned from abundant text data and the ASR data for some recognizers. Experiments showed very encouraging results and verified that the proposed ASR error model works well even when the input spoken content is recognized by a recognizer very different from the one the model learned from.
An Iterative Deep Learning Framework for Unsupervised Discovery of Speech Features and Linguistic Units with Applications on Spoken Term Detection
Feb 01, 2016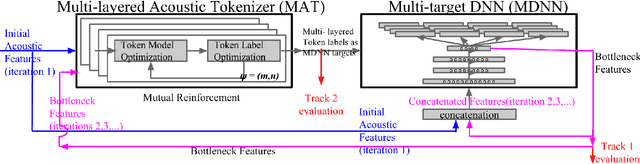
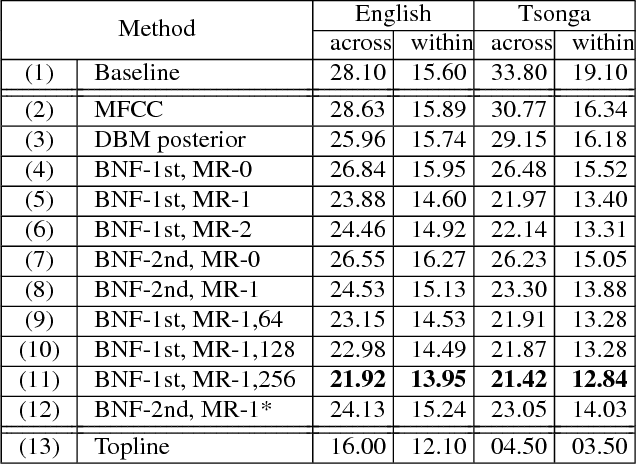
In this work we aim to discover high quality speech features and linguistic units directly from unlabeled speech data in a zero resource scenario. The results are evaluated using the metrics and corpora proposed in the Zero Resource Speech Challenge organized at Interspeech 2015. A Multi-layered Acoustic Tokenizer (MAT) was proposed for automatic discovery of multiple sets of acoustic tokens from the given corpus. Each acoustic token set is specified by a set of hyperparameters that describe the model configuration. These sets of acoustic tokens carry different characteristics fof the given corpus and the language behind, thus can be mutually reinforced. The multiple sets of token labels are then used as the targets of a Multi-target Deep Neural Network (MDNN) trained on low-level acoustic features. Bottleneck features extracted from the MDNN are then used as the feedback input to the MAT and the MDNN itself in the next iteration. We call this iterative deep learning framework the Multi-layered Acoustic Tokenizing Deep Neural Network (MAT-DNN), which generates both high quality speech features for the Track 1 of the Challenge and acoustic tokens for the Track 2 of the Challenge. In addition, we performed extra experiments on the same corpora on the application of query-by-example spoken term detection. The experimental results showed the iterative deep learning framework of MAT-DNN improved the detection performance due to better underlying speech features and acoustic tokens.
Towards Structured Deep Neural Network for Automatic Speech Recognition
Nov 08, 2015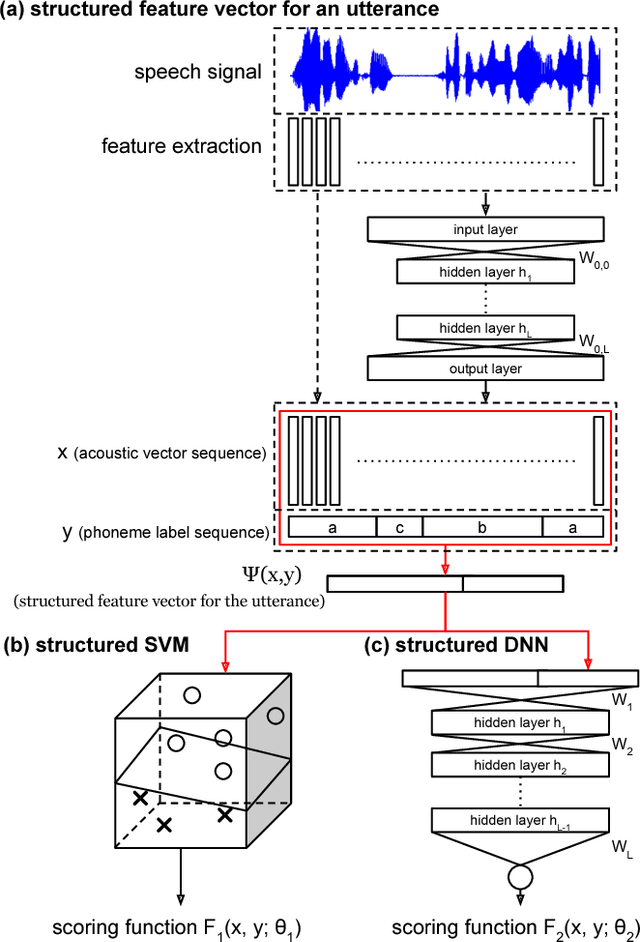

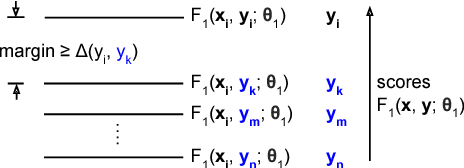
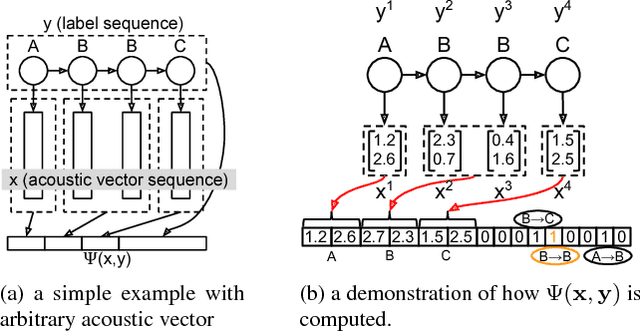
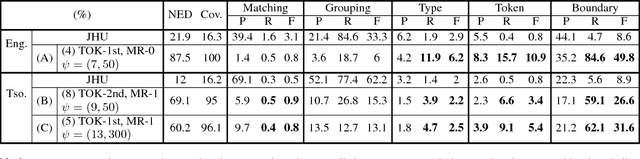
In this paper we propose the Structured Deep Neural Network (structured DNN) as a structured and deep learning framework. This approach can learn to find the best structured object (such as a label sequence) given a structured input (such as a vector sequence) by globally considering the mapping relationships between the structures rather than item by item. When automatic speech recognition is viewed as a special case of such a structured learning problem, where we have the acoustic vector sequence as the input and the phoneme label sequence as the output, it becomes possible to comprehensively learn utterance by utterance as a whole, rather than frame by frame. Structured Support Vector Machine (structured SVM) was proposed to perform ASR with structured learning previously, but limited by the linear nature of SVM. Here we propose structured DNN to use nonlinear transformations in multi-layers as a structured and deep learning approach. This approach was shown to beat structured SVM in preliminary experiments on TIMIT.
Unsupervised Spoken Term Detection with Spoken Queries by Multi-level Acoustic Patterns with Varying Model Granularity
Sep 07, 2015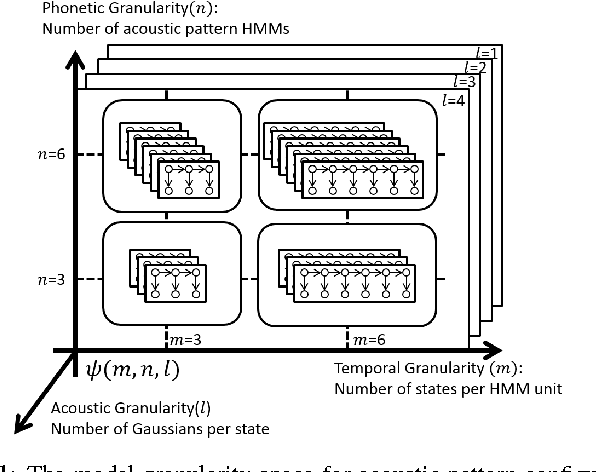
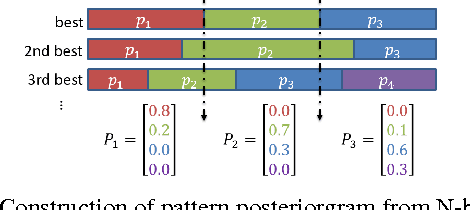
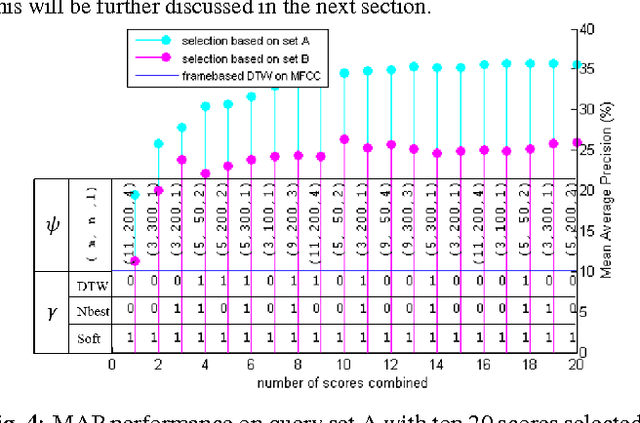
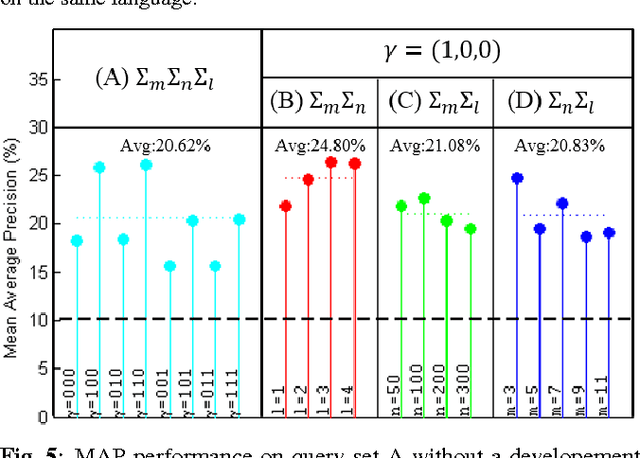
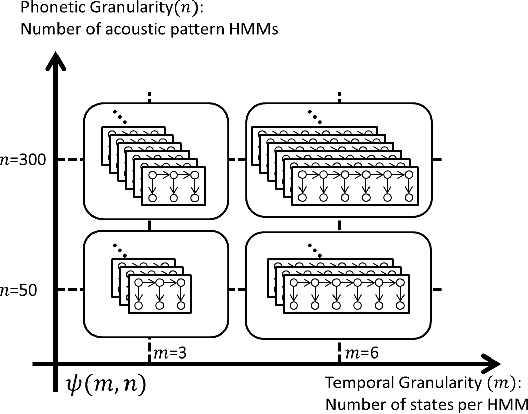
This paper presents a new approach for unsupervised Spoken Term Detection with spoken queries using multiple sets of acoustic patterns automatically discovered from the target corpus. The different pattern HMM configurations(number of states per model, number of distinct models, number of Gaussians per state)form a three-dimensional model granularity space. Different sets of acoustic patterns automatically discovered on different points properly distributed over this three-dimensional space are complementary to one another, thus can jointly capture the characteristics of the spoken terms. By representing the spoken content and spoken query as sequences of acoustic patterns, a series of approaches for matching the pattern index sequences while considering the signal variations are developed. In this way, not only the on-line computation load can be reduced, but the signal distributions caused by different speakers and acoustic conditions can be reasonably taken care of. The results indicate that this approach significantly outperformed the unsupervised feature-based DTW baseline by 16.16\% in mean average precision on the TIMIT corpus.
Unsupervised Discovery of Linguistic Structure Including Two-level Acoustic Patterns Using Three Cascaded Stages of Iterative Optimization
Sep 07, 2015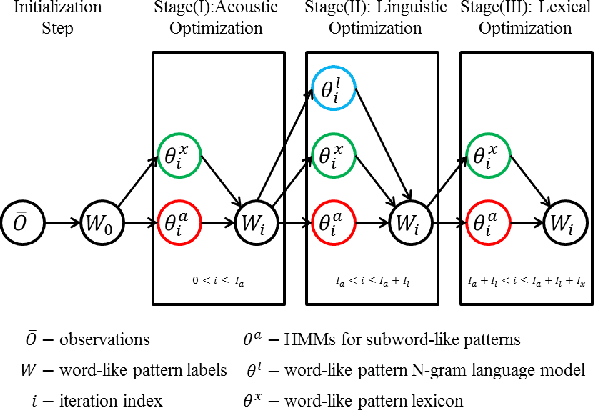
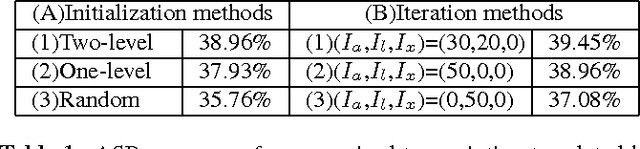
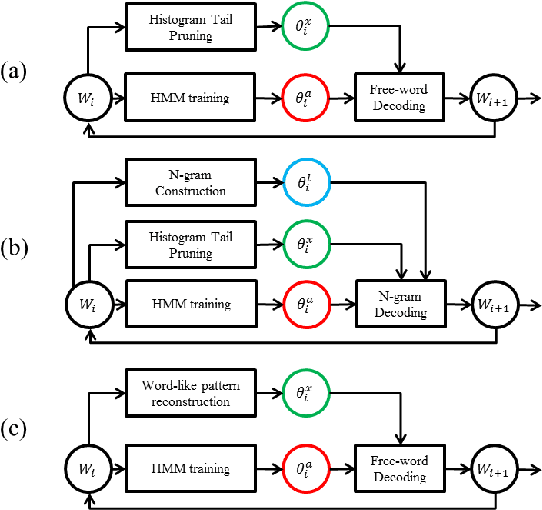

Techniques for unsupervised discovery of acoustic patterns are getting increasingly attractive, because huge quantities of speech data are becoming available but manual annotations remain hard to acquire. In this paper, we propose an approach for unsupervised discovery of linguistic structure for the target spoken language given raw speech data. This linguistic structure includes two-level (subword-like and word-like) acoustic patterns, the lexicon of word-like patterns in terms of subword-like patterns and the N-gram language model based on word-like patterns. All patterns, models, and parameters can be automatically learned from the unlabelled speech corpus. This is achieved by an initialization step followed by three cascaded stages for acoustic, linguistic, and lexical iterative optimization. The lexicon of word-like patterns defines allowed consecutive sequence of HMMs for subword-like patterns. In each iteration, model training and decoding produces updated labels from which the lexicon and HMMs can be further updated. In this way, model parameters and decoded labels are respectively optimized in each iteration, and the knowledge about the linguistic structure is learned gradually layer after layer. The proposed approach was tested in preliminary experiments on a corpus of Mandarin broadcast news, including a task of spoken term detection with performance compared to a parallel test using models trained in a supervised way. Results show that the proposed system not only yields reasonable performance on its own, but is also complimentary to existing large vocabulary ASR systems.
A Multi-layered Acoustic Tokenizing Deep Neural Network (MAT-DNN) for Unsupervised Discovery of Linguistic Units and Generation of High Quality Features
Jun 07, 2015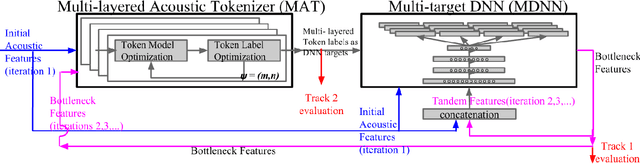
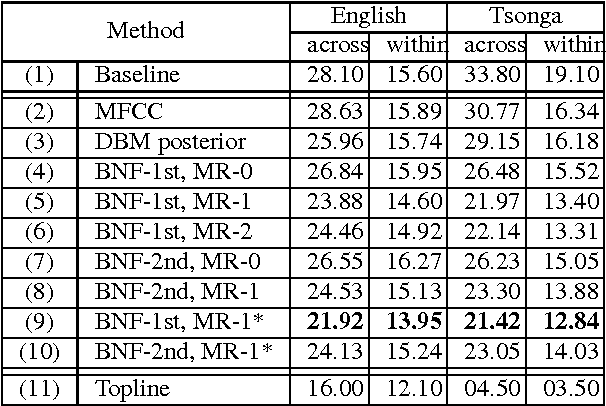
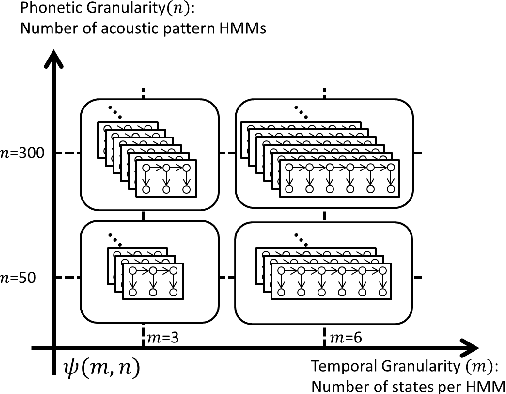
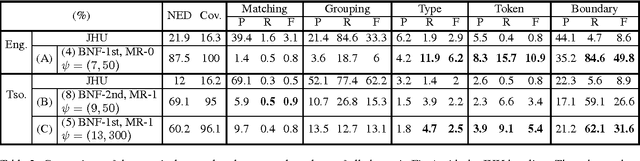
This paper summarizes the work done by the authors for the Zero Resource Speech Challenge organized in the technical program of Interspeech 2015. The goal of the challenge is to discover linguistic units directly from unlabeled speech data. The Multi-layered Acoustic Tokenizer (MAT) proposed in this work automatically discovers multiple sets of acoustic tokens from the given corpus. Each acoustic token set is specified by a set of hyperparameters that describe the model configuration. These sets of acoustic tokens carry different characteristics of the given corpus and the language behind thus can be mutually reinforced. The multiple sets of token labels are then used as the targets of a Multi-target DNN (MDNN) trained on low-level acoustic features. Bottleneck features extracted from the MDNN are used as feedback for the MAT and the MDNN itself. We call this iterative system the Multi-layered Acoustic Tokenizing Deep Neural Network (MAT-DNN) which generates high quality features for track 1 of the challenge and acoustic tokens for track 2 of the challenge.