 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReMoE: Boosting Expert Reuse through Router Fine-Tuning in Memory-Constrained MoE LLM Inference
May 26, 2026Fine-grained Mixture-of-Experts (MoE) models sparsely activate only a subset of experts per token, reducing activated computation while maintaining high model capacity. However, in memory-constrained inference scenarios, only a small set of experts can be cached. Experts not in the cache must be fetched from slow external storage (e.g., UFS), leading to frequent evictions and substantial I/O overhead. We propose ReMoE, a router fine-tuning framework designed to boost token-wise expert reuse. ReMoE biases the router toward recently selected experts, producing temporally stable routing that better matches cache locality constraints. By increasing short-horizon expert reuse, ReMoE reduces expert fetches from storage without adding inference-time computation. Experiments on DeepSeek and Qwen models show that ReMoE improves expert reuse by 26% while maintaining downstream task performance. Real-system evaluations further confirm these benefits, improving output throughput by 8.4% under vLLM GPU-CPU expert offloading and reducing TPOT by 43.6-49.8% under llama.cpp on Jetson Orin NX, corresponding to a 1.77-1.99$\times$ decode speedup across diverse workloads. Checkpoints and usage instructions are available at https://github.com/BUAA-OSCAR/ReMoE.
CaMDN: Enhancing Cache Efficiency for Multi-tenant DNNs on Integrated NPUs
May 10, 2025With the rapid development of DNN applications, multi-tenant execution, where multiple DNNs are co-located on a single SoC, is becoming a prevailing trend. Although many methods are proposed in prior works to improve multi-tenant performance, the impact of shared cache is not well studied. This paper proposes CaMDN, an architecture-scheduling co-design to enhance cache efficiency for multi-tenant DNNs on integrated NPUs. Specifically, a lightweight architecture is proposed to support model-exclusive, NPU-controlled regions inside shared cache to eliminate unexpected cache contention. Moreover, a cache scheduling method is proposed to improve shared cache utilization. In particular, it includes a cache-aware mapping method for adaptability to the varying available cache capacity and a dynamic allocation algorithm to adjust the usage among co-located DNNs at runtime. Compared to prior works, CaMDN reduces the memory access by 33.4% on average and achieves a model speedup of up to 2.56$\times$ (1.88$\times$ on average).
FineQ: Software-Hardware Co-Design for Low-Bit Fine-Grained Mixed-Precision Quantization of LLMs
Apr 28, 2025Large language models (LLMs) have significantly advanced the natural language processing paradigm but impose substantial demands on memory and computational resources. Quantization is one of the most effective ways to reduce memory consumption of LLMs. However, advanced single-precision quantization methods experience significant accuracy degradation when quantizing to ultra-low bits. Existing mixed-precision quantization methods are quantized by groups with coarse granularity. Employing high precision for group data leads to substantial memory overhead, whereas low precision severely impacts model accuracy. To address this issue, we propose FineQ, software-hardware co-design for low-bit fine-grained mixed-precision quantization of LLMs. First, FineQ partitions the weights into finer-grained clusters and considers the distribution of outliers within these clusters, thus achieving a balance between model accuracy and memory overhead. Then, we propose an outlier protection mechanism within clusters that uses 3 bits to represent outliers and introduce an encoding scheme for index and data concatenation to enable aligned memory access. Finally, we introduce an accelerator utilizing temporal coding that effectively supports the quantization algorithm while simplifying the multipliers in the systolic array. FineQ achieves higher model accuracy compared to the SOTA mixed-precision quantization algorithm at a close average bit-width. Meanwhile, the accelerator achieves up to 1.79x energy efficiency and reduces the area of the systolic array by 61.2%.
Is Intelligence the Right Direction in New OS Scheduling for Multiple Resources in Cloud Environments?
Apr 21, 2025



Making it intelligent is a promising way in System/OS design. This paper proposes OSML+, a new ML-based resource scheduling mechanism for co-located cloud services. OSML+ intelligently schedules the cache and main memory bandwidth resources at the memory hierarchy and the computing core resources simultaneously. OSML+ uses a multi-model collaborative learning approach during its scheduling and thus can handle complicated cases, e.g., avoiding resource cliffs, sharing resources among applications, enabling different scheduling policies for applications with different priorities, etc. OSML+ can converge faster using ML models than previous studies. Moreover, OSML+ can automatically learn on the fly and handle dynamically changing workloads accordingly. Using transfer learning technologies, we show our design can work well across various cloud servers, including the latest off-the-shelf large-scale servers. Our experimental results show that OSML+ supports higher loads and meets QoS targets with lower overheads than previous studies.
CoServe: Efficient Collaboration-of-Experts (CoE) Model Inference with Limited Memory
Mar 04, 2025



Large language models like GPT-4 are resource-intensive, but recent advancements suggest that smaller, specialized experts can outperform the monolithic models on specific tasks. The Collaboration-of-Experts (CoE) approach integrates multiple expert models, improving the accuracy of generated results and offering great potential for precision-critical applications, such as automatic circuit board quality inspection. However, deploying CoE serving systems presents challenges to memory capacity due to the large number of experts required, which can lead to significant performance overhead from frequent expert switching across different memory and storage tiers. We propose CoServe, an efficient CoE model serving system on heterogeneous CPU and GPU with limited memory. CoServe reduces unnecessary expert switching by leveraging expert dependency, a key property of CoE inference. CoServe introduces a dependency-aware request scheduler and dependency-aware expert management for efficient inference. It also introduces an offline profiler to automatically find optimal resource allocation on various processors and devices. In real-world intelligent manufacturing workloads, CoServe achieves 4.5$\times$ to 12$\times$ higher throughput compared to state-of-the-art systems.
* Accepted to ASPLOS '25
Perspective, Survey and Trends: Public Driving Datasets and Toolsets for Autonomous Driving Virtual Test
Apr 20, 2021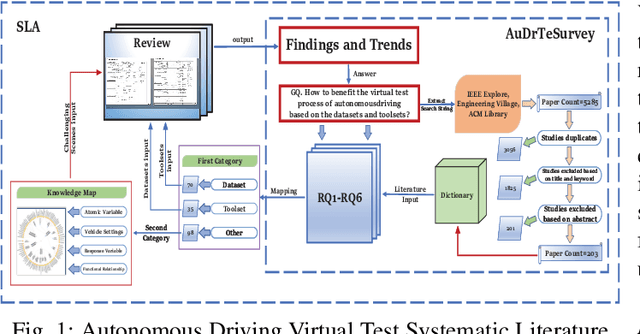
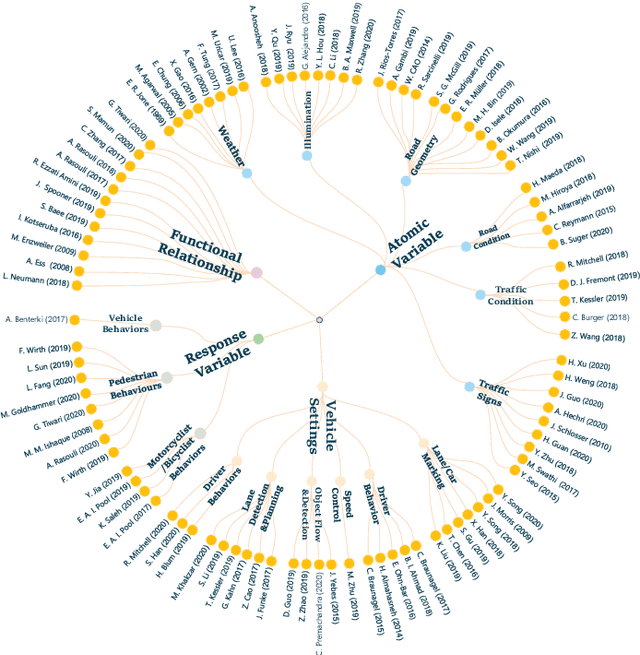
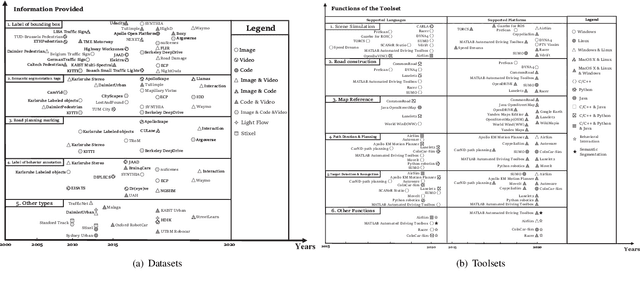
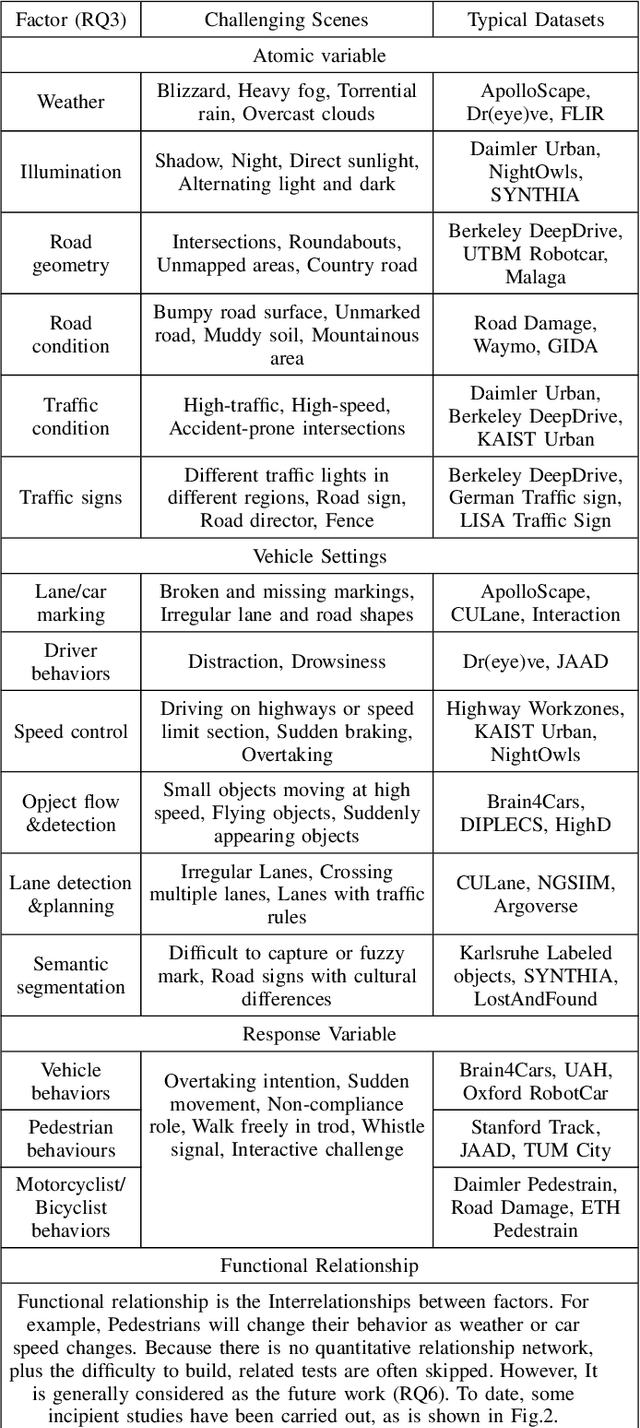
Owing to the merits of early safety and reliability guarantee, autonomous driving virtual testing has recently gains increasing attention compared with closed-loop testing in real scenarios. Although the availability and quality of autonomous driving datasets and toolsets are the premise to diagnose the autonomous driving system bottlenecks and improve the system performance, due to the diversity and privacy of the datasets and toolsets, collecting and featuring the perspective and quality of them become not only time-consuming but also increasingly challenging. This paper first proposes a Systematic Literature review approach for Autonomous driving tests (SLA), then presents an overview of existing publicly available datasets and toolsets from 2000 to 2020. Quantitative findings with the scenarios concerned, perspectives and trend inferences and suggestions with 35 automated driving test tool sets and 70 test data sets are also presented. To the best of our knowledge, we are the first to perform such recent empirical survey on both the datasets and toolsets using a SLA based survey approach. Our multifaceted analyses and new findings not only reveal insights that we believe are useful for system designers, practitioners and users, but also can promote more researches on a systematic survey analysis in autonomous driving surveys on dataset and toolsets.