 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch and Learning for Unsupervised Text Generation
Sep 18, 2023With the advances of deep learning techniques, text generation is attracting increasing interest in the artificial intelligence (AI) community, because of its wide applications and because it is an essential component of AI. Traditional text generation systems are trained in a supervised way, requiring massive labeled parallel corpora. In this paper, I will introduce our recent work on search and learning approaches to unsupervised text generation, where a heuristic objective function estimates the quality of a candidate sentence, and discrete search algorithms generate a sentence by maximizing the search objective. A machine learning model further learns from the search results to smooth out noise and improve efficiency. Our approach is important to the industry for building minimal viable products for a new task; it also has high social impacts for saving human annotation labor and for processing low-resource languages.
Unsupervised Chunking with Hierarchical RNN
Sep 10, 2023



In Natural Language Processing (NLP), predicting linguistic structures, such as parsing and chunking, has mostly relied on manual annotations of syntactic structures. This paper introduces an unsupervised approach to chunking, a syntactic task that involves grouping words in a non-hierarchical manner. We present a two-layer Hierarchical Recurrent Neural Network (HRNN) designed to model word-to-chunk and chunk-to-sentence compositions. Our approach involves a two-stage training process: pretraining with an unsupervised parser and finetuning on downstream NLP tasks. Experiments on the CoNLL-2000 dataset reveal a notable improvement over existing unsupervised methods, enhancing phrase F1 score by up to 6 percentage points. Further, finetuning with downstream tasks results in an additional performance improvement. Interestingly, we observe that the emergence of the chunking structure is transient during the neural model's downstream-task training. This study contributes to the advancement of unsupervised syntactic structure discovery and opens avenues for further research in linguistic theory.
f-Divergence Minimization for Sequence-Level Knowledge Distillation
Jul 27, 2023



Knowledge distillation (KD) is the process of transferring knowledge from a large model to a small one. It has gained increasing attention in the natural language processing community, driven by the demands of compressing ever-growing language models. In this work, we propose an f-DISTILL framework, which formulates sequence-level knowledge distillation as minimizing a generalized f-divergence function. We propose four distilling variants under our framework and show that existing SeqKD and ENGINE approaches are approximations of our f-DISTILL methods. We further derive step-wise decomposition for our f-DISTILL, reducing intractable sequence-level divergence to word-level losses that can be computed in a tractable manner. Experiments across four datasets show that our methods outperform existing KD approaches, and that our symmetric distilling losses can better force the student to learn from the teacher distribution.
Prompt-Based Editing for Text Style Transfer
Jan 27, 2023



Prompting approaches have been recently explored in text style transfer, where a textual prompt is used to query a pretrained language model to generate style-transferred texts word by word in an autoregressive manner. However, such a generation process is less controllable and early prediction errors may affect future word predictions. In this paper, we present a prompt-based editing approach for text style transfer. Specifically, we prompt a pretrained language model for style classification and use the classification probability to compute a style score. Then, we perform discrete search with word-level editing to maximize a comprehensive scoring function for the style-transfer task. In this way, we transform a prompt-based generation problem into a classification one, which is a training-free process and more controllable than the autoregressive generation of sentences. In our experiments, we performed both automatic and human evaluation on three style-transfer benchmark datasets, and show that our approach largely outperforms the state-of-the-art systems that have 20 times more parameters. Additional empirical analyses further demonstrate the effectiveness of our approach.
Teacher Forcing Recovers Reward Functions for Text Generation
Oct 17, 2022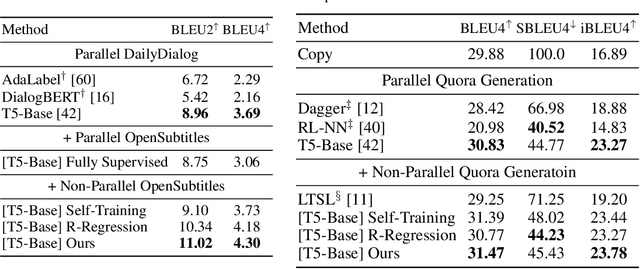
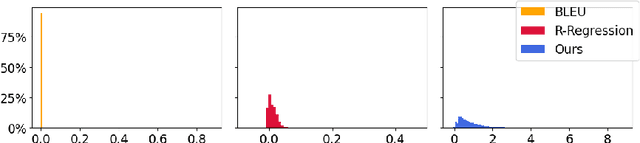

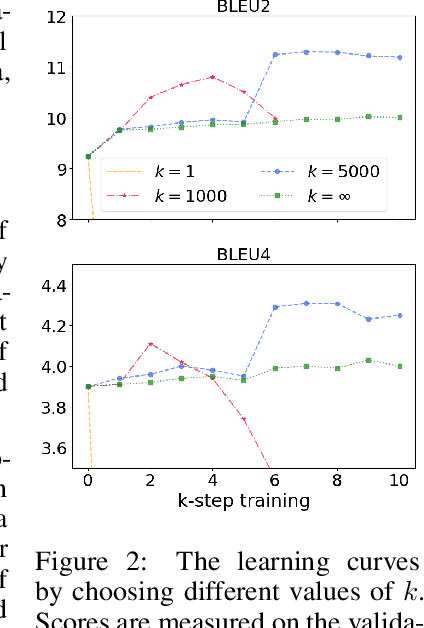
Reinforcement learning (RL) has been widely used in text generation to alleviate the exposure bias issue or to utilize non-parallel datasets. The reward function plays an important role in making RL training successful. However, previous reward functions are typically task-specific and sparse, restricting the use of RL. In our work, we propose a task-agnostic approach that derives a step-wise reward function directly from a model trained with teacher forcing. We additionally propose a simple modification to stabilize the RL training on non-parallel datasets with our induced reward function. Empirical results show that our method outperforms self-training and reward regression methods on several text generation tasks, confirming the effectiveness of our reward function.
An Equal-Size Hard EM Algorithm for Diverse Dialogue Generation
Sep 29, 2022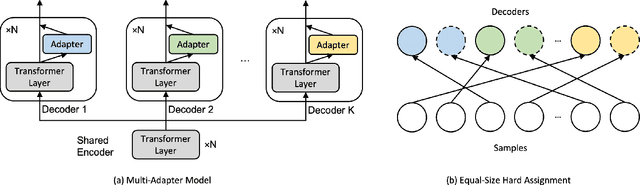
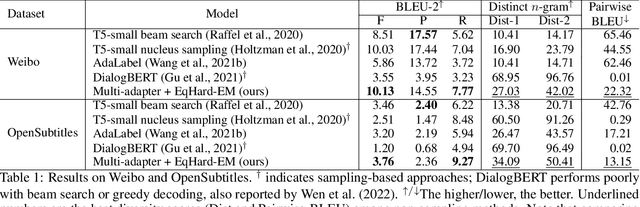
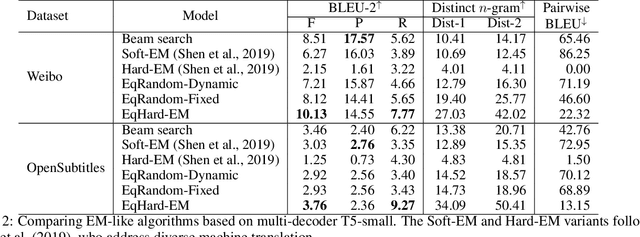
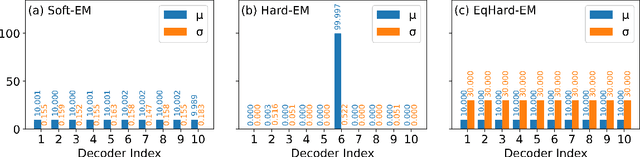
Open-domain dialogue systems aim to interact with humans through natural language texts in an open-ended fashion. However, the widely successful neural networks may not work well for dialogue systems, as they tend to generate generic responses. In this work, we propose an Equal-size Hard Expectation--Maximization (EqHard-EM) algorithm to train a multi-decoder model for diverse dialogue generation. Our algorithm assigns a sample to a decoder in a hard manner and additionally imposes an equal-assignment constraint to ensure that all decoders are well-trained. We provide detailed theoretical analysis to justify our approach. Further, experiments on two large-scale, open-domain dialogue datasets verify that our EqHard-EM algorithm generates high-quality diverse responses.
Controlling Perceived Emotion in Symbolic Music Generation with Monte Carlo Tree Search
Sep 01, 2022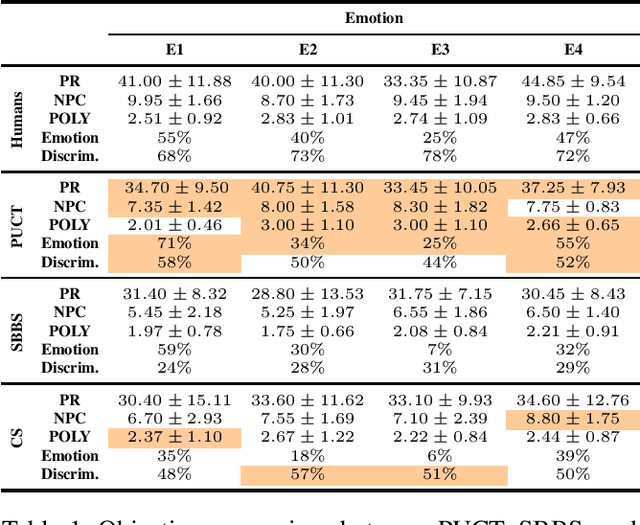


This paper presents a new approach for controlling emotion in symbolic music generation with Monte Carlo Tree Search. We use Monte Carlo Tree Search as a decoding mechanism to steer the probability distribution learned by a language model towards a given emotion. At every step of the decoding process, we use Predictor Upper Confidence for Trees (PUCT) to search for sequences that maximize the average values of emotion and quality as given by an emotion classifier and a discriminator, respectively. We use a language model as PUCT's policy and a combination of the emotion classifier and the discriminator as its value function. To decode the next token in a piece of music, we sample from the distribution of node visits created during the search. We evaluate the quality of the generated samples with respect to human-composed pieces using a set of objective metrics computed directly from the generated samples. We also perform a user study to evaluate how human subjects perceive the generated samples' quality and emotion. We compare PUCT against Stochastic Bi-Objective Beam Search (SBBS) and Conditional Sampling (CS). Results suggest that PUCT outperforms SBBS and CS in almost all metrics of music quality and emotion.
A Character-Level Length-Control Algorithm for Non-Autoregressive Sentence Summarization
May 28, 2022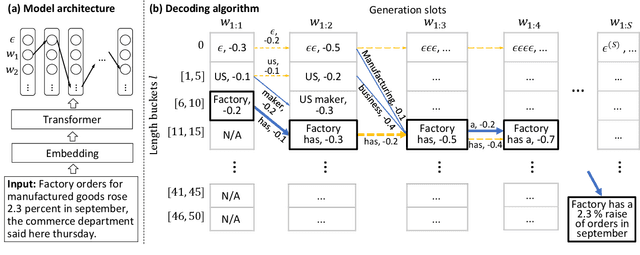
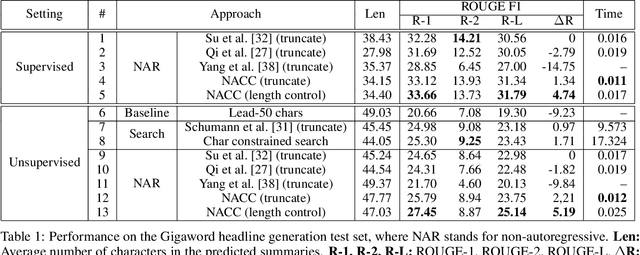
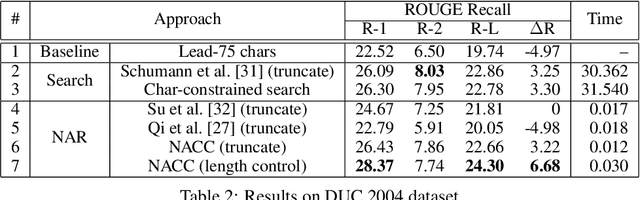
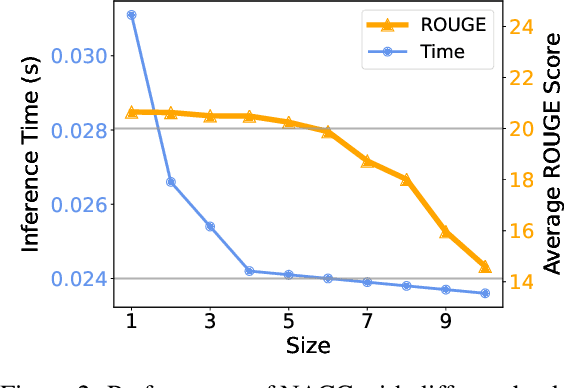
Sentence summarization aims at compressing a long sentence into a short one that keeps the main gist, and has extensive real-world applications such as headline generation. In previous work, researchers have developed various approaches to improve the ROUGE score, which is the main evaluation metric for summarization, whereas controlling the summary length has not drawn much attention. In our work, we address a new problem of explicit character-level length control for summarization, and propose a dynamic programming algorithm based on the Connectionist Temporal Classification (CTC) model. Results show that our approach not only achieves higher ROUGE scores but also yields more complete sentences.
Learning Non-Autoregressive Models from Search for Unsupervised Sentence Summarization
May 28, 2022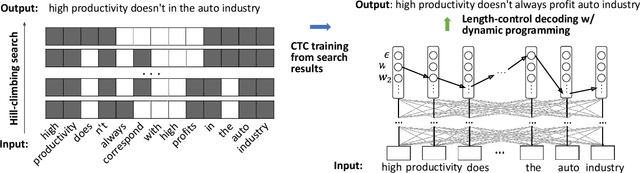
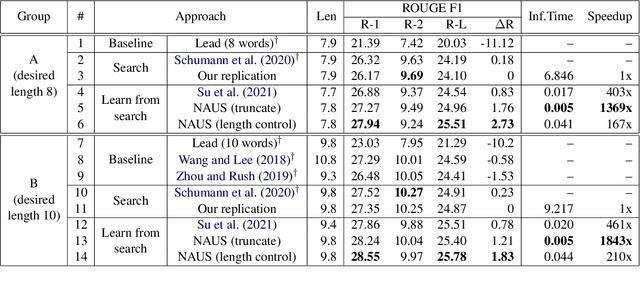

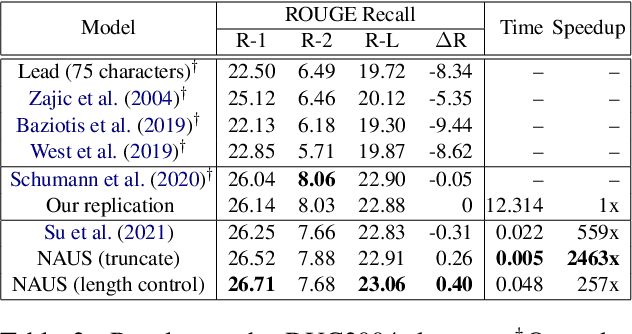
Text summarization aims to generate a short summary for an input text. In this work, we propose a Non-Autoregressive Unsupervised Summarization (NAUS) approach, which does not require parallel data for training. Our NAUS first performs edit-based search towards a heuristically defined score, and generates a summary as pseudo-groundtruth. Then, we train an encoder-only non-autoregressive Transformer based on the search result. We also propose a dynamic programming approach for length-control decoding, which is important for the summarization task. Experiments on two datasets show that NAUS achieves state-of-the-art performance for unsupervised summarization, yet largely improving inference efficiency. Further, our algorithm is able to perform explicit length-transfer summary generation.
Document-Level Relation Extraction with Sentences Importance Estimation and Focusing
Apr 27, 2022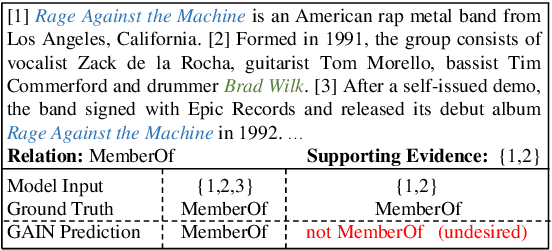
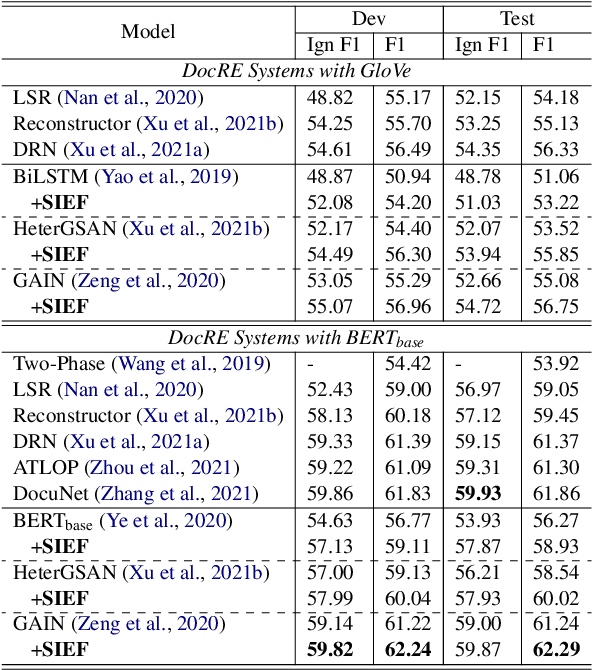
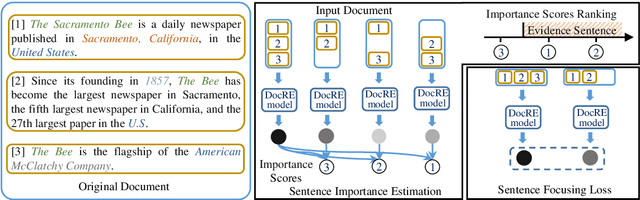
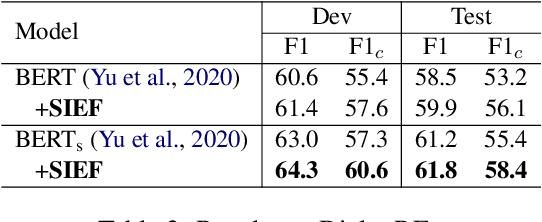
Document-level relation extraction (DocRE) aims to determine the relation between two entities from a document of multiple sentences. Recent studies typically represent the entire document by sequence- or graph-based models to predict the relations of all entity pairs. However, we find that such a model is not robust and exhibits bizarre behaviors: it predicts correctly when an entire test document is fed as input, but errs when non-evidence sentences are removed. To this end, we propose a Sentence Importance Estimation and Focusing (SIEF) framework for DocRE, where we design a sentence importance score and a sentence focusing loss, encouraging DocRE models to focus on evidence sentences. Experimental results on two domains show that our SIEF not only improves overall performance, but also makes DocRE models more robust. Moreover, SIEF is a general framework, shown to be effective when combined with a variety of base DocRE models.