 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Particle Seeking: Solving Diffusion Inverse Problems with Just Forward Passes
Mar 02, 2026Diffusion models have gained prominence as powerful generative tools for solving inverse problems due to their ability to model complex data distributions. However, existing methods typically rely on complete knowledge of the forward observation process to compute gradients for guided sampling, limiting their applicability in scenarios where such information is unavailable. In this work, we introduce \textbf{\emph{Constrained Particle Seeking (CPS)}}, a novel gradient-free approach that leverages all candidate particle information to actively search for the optimal particle while incorporating constraints aligned with high-density regions of the unconditional prior. Unlike previous methods that passively select promising candidates, CPS reformulates the inverse problem as a constrained optimization task, enabling more flexible and efficient particle seeking. We demonstrate that CPS can effectively solve both image and scientific inverse problems, achieving results comparable to gradient-based methods while significantly outperforming gradient-free alternatives. Code is available at https://github.com/deng-ai-lab/CPS.
You Only Look One Step: Accelerating Backpropagation in Diffusion Sampling with Gradient Shortcuts
May 12, 2025Diffusion models (DMs) have recently demonstrated remarkable success in modeling large-scale data distributions. However, many downstream tasks require guiding the generated content based on specific differentiable metrics, typically necessitating backpropagation during the generation process. This approach is computationally expensive, as generating with DMs often demands tens to hundreds of recursive network calls, resulting in high memory usage and significant time consumption. In this paper, we propose a more efficient alternative that approaches the problem from the perspective of parallel denoising. We show that full backpropagation throughout the entire generation process is unnecessary. The downstream metrics can be optimized by retaining the computational graph of only one step during generation, thus providing a shortcut for gradient propagation. The resulting method, which we call Shortcut Diffusion Optimization (SDO), is generic, high-performance, and computationally lightweight, capable of optimizing all parameter types in diffusion sampling. We demonstrate the effectiveness of SDO on several real-world tasks, including controlling generation by optimizing latent and aligning the DMs by fine-tuning network parameters. Compared to full backpropagation, our approach reduces computational costs by $\sim 90\%$ while maintaining superior performance. Code is available at https://github.com/deng-ai-lab/SDO.
Physics-aligned Schrödinger bridge
Sep 26, 2024



The reconstruction of physical fields from sparse measurements is pivotal in both scientific research and engineering applications. Traditional methods are increasingly supplemented by deep learning models due to their efficacy in extracting features from data. However, except for the low accuracy on complex physical systems, these models often fail to comply with essential physical constraints, such as governing equations and boundary conditions. To overcome this limitation, we introduce a novel data-driven field reconstruction framework, termed the Physics-aligned Schr\"{o}dinger Bridge (PalSB). This framework leverages a diffusion Schr\"{o}dinger bridge mechanism that is specifically tailored to align with physical constraints. The PalSB approach incorporates a dual-stage training process designed to address both local reconstruction mapping and global physical principles. Additionally, a boundary-aware sampling technique is implemented to ensure adherence to physical boundary conditions. We demonstrate the effectiveness of PalSB through its application to three complex nonlinear systems: cylinder flow from Particle Image Velocimetry experiments, two-dimensional turbulence, and a reaction-diffusion system. The results reveal that PalSB not only achieves higher accuracy but also exhibits enhanced compliance with physical constraints compared to existing methods. This highlights PalSB's capability to generate high-quality representations of intricate physical interactions, showcasing its potential for advancing field reconstruction techniques.
Breast Tumor Classification Based on Decision Information Genes and Inverse Projection Sparse Representation
Apr 17, 2018



Microarray gene expression data-based breast tumor classification is an active and challenging issue. In this paper, a robust framework of breast tumor recognition is presented aiming at reducing clinical misdiagnosis rate and exploiting available information in existing samples. A wrapper gene selection method is established from a new perspective of reducing clinical misdiagnosis rate. The further feature selection of information genes is achieved using the modified NMF model, which is rooted in the use of hierarchical learning and layer-wise pre-training strategy in deep learning. For completing the classification, an inverse projection sparse representation (IPSR) model is constructed to exploit information embedded in existing samples, especially in the test ones. Moreover, the IPSR model is optimized through generalized ADMM and the corresponding convergence is analyzed. Extensive experiments on public microarray gene expression datasets show that the proposed method is stable and effective for breast tumor classification. Compared to the latest open literature, there is 14% higher in classification accuracy. Specificity and sensitivity achieve 94.17% and 97.5%, respectively.
Extend natural neighbor: a novel classification method with self-adaptive neighborhood parameters in different stages
Dec 07, 2016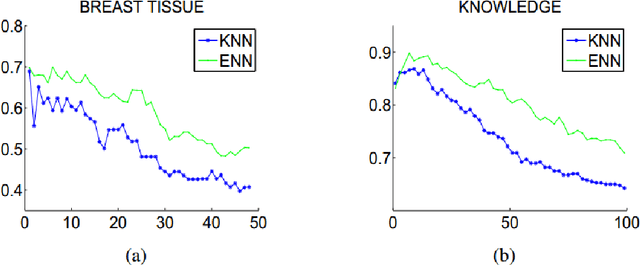
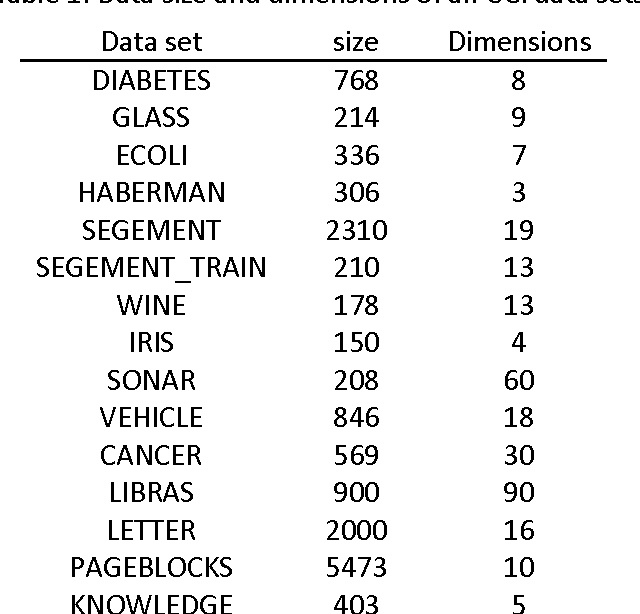
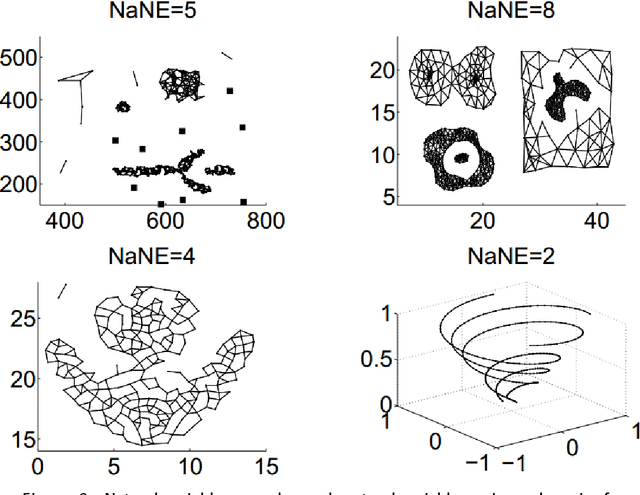
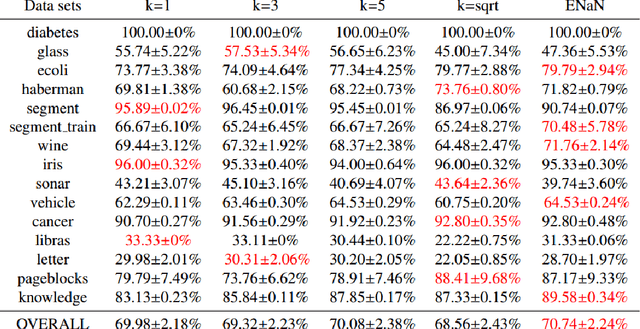
Various kinds of k-nearest neighbor (KNN) based classification methods are the bases of many well-established and high-performance pattern-recognition techniques, but both of them are vulnerable to their parameter choice. Essentially, the challenge is to detect the neighborhood of various data sets, while utterly ignorant of the data characteristic. This article introduces a new supervised classification method: the extend natural neighbor (ENaN) method, and shows that it provides a better classification result without choosing the neighborhood parameter artificially. Unlike the original KNN based method which needs a prior k, the ENaNE method predicts different k in different stages. Therefore, the ENaNE method is able to learn more from flexible neighbor information both in training stage and testing stage, and provide a better classification result.