 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeGenBench: A Multidimensional Diagnostic Benchmark towards Text-to-Image Model Optimization
Jun 18, 2026Recent text-to-image generation models have demonstrated remarkable capabilities in synthesizing highly realistic images from text inputs alone. Although existing benchmarks can evaluate the generation capabilities of various models to some extent, they struggle to comprehensively and accurately measure performance across multiple dimensions, often failing to reveal the inherent deficiencies of models in specific categories. To address these limitations, we propose WeGenBench, a novel benchmark designed for the comprehensive, multi-perspective evaluation of text-to-image generation capabilities. Our benchmark comprises a total of 4,000 test prompts across two primary categories, meticulously balanced between Chinese and English to evaluate bilingual and cross-cultural generation capabilities. Beyond macroscopic scene classification, we annotate each prompt with multi-dimensional tags tailored to the distinct content and challenges of each language, thereby refining the generation tasks into more specific sub-categories. Through a cross-dimensional evaluation mechanism leveraging both scene classifications and multi-dimensional tags, WeGenBench can precisely pinpoint model shortcomings in specific generation categories. Furthermore, to measure generation quality more accurately, we design and validate several novel evaluation metrics by integrating Vision-Language Models (VLMs), which assess model performance on domain-specific tasks from three core aspects. Crucially, our approach yields both the assessment outcomes and the detailed reasoning trajectories, facilitating a rigorous verification of the accuracy and soundness of the evaluation results. Finally, we conduct systematic benchmarking on current state-of-the-art methods and provide an in-depth analysis of the limitations present in existing models.
Robust Gait Recognition by Integrating Inertial and RGBD Sensors
Oct 31, 2016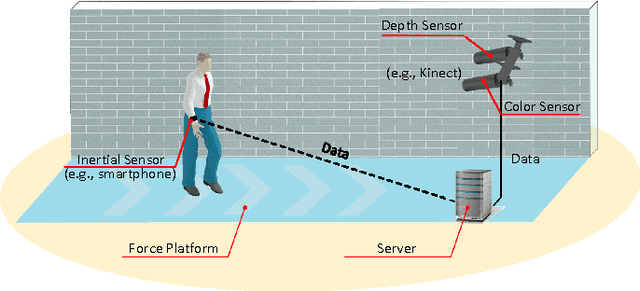
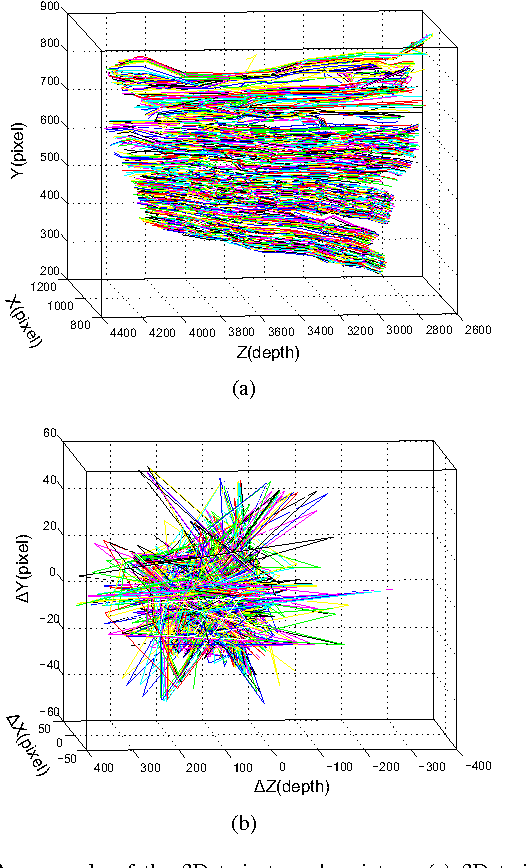
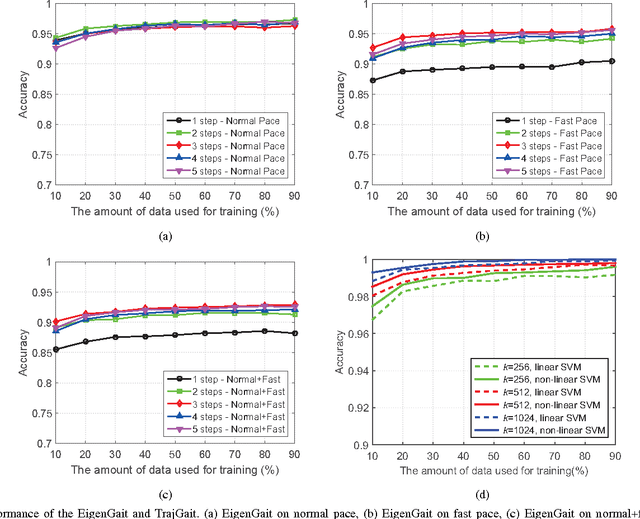
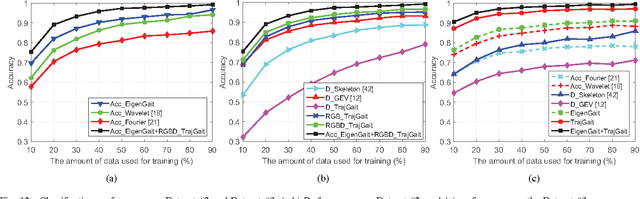
Gait has been considered as a promising and unique biometric for person identification. Traditionally, gait data are collected using either color sensors, such as a CCD camera, depth sensors, such as a Microsoft Kinect, or inertial sensors, such as an accelerometer. However, a single type of sensors may only capture part of the dynamic gait features and make the gait recognition sensitive to complex covariate conditions, leading to fragile gait-based person identification systems. In this paper, we propose to combine all three types of sensors for gait data collection and gait recognition, which can be used for important identification applications, such as identity recognition to access a restricted building or area. We propose two new algorithms, namely EigenGait and TrajGait, to extract gait features from the inertial data and the RGBD (color and depth) data, respectively. Specifically, EigenGait extracts general gait dynamics from the accelerometer readings in the eigenspace and TrajGait extracts more detailed sub-dynamics by analyzing 3D dense trajectories. Finally, both extracted features are fed into a supervised classifier for gait recognition and person identification. Experiments on 50 subjects, with comparisons to several other state-of-the-art gait-recognition approaches, show that the proposed approach can achieve higher recognition accuracy and robustness.