 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiving into the Fusion of Monocular Priors for Generalized Stereo Matching
May 20, 2025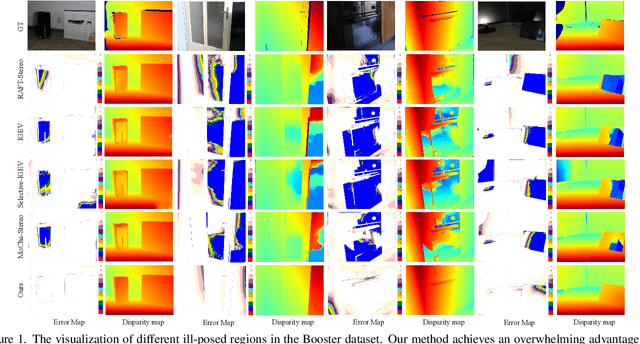
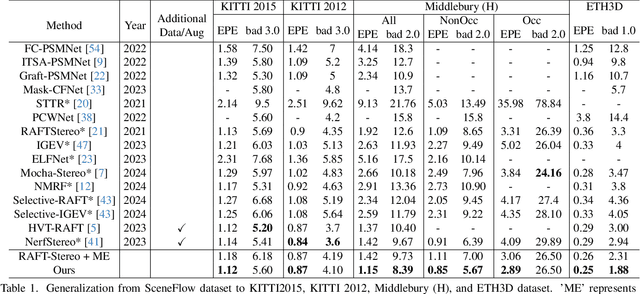
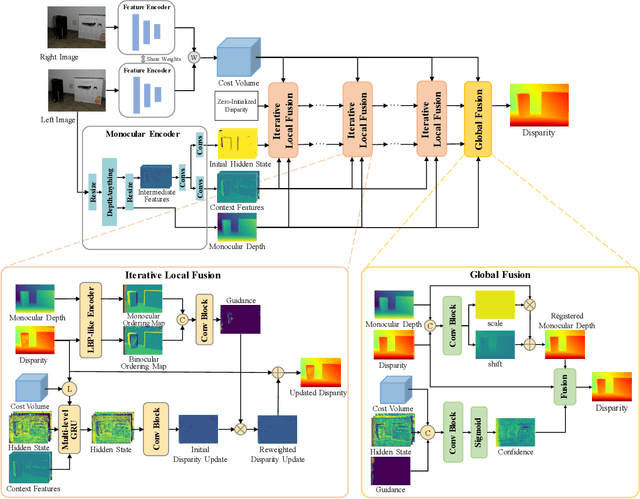
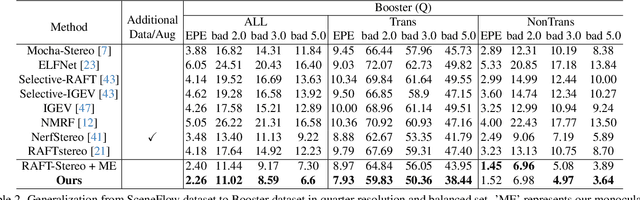
The matching formulation makes it naturally hard for the stereo matching to handle ill-posed regions like occlusions and non-Lambertian surfaces. Fusing monocular priors has been proven helpful for ill-posed matching, but the biased monocular prior learned from small stereo datasets constrains the generalization. Recently, stereo matching has progressed by leveraging the unbiased monocular prior from the vision foundation model (VFM) to improve the generalization in ill-posed regions. We dive into the fusion process and observe three main problems limiting the fusion of the VFM monocular prior. The first problem is the misalignment between affine-invariant relative monocular depth and absolute depth of disparity. Besides, when we use the monocular feature in an iterative update structure, the over-confidence in the disparity update leads to local optima results. A direct fusion of a monocular depth map could alleviate the local optima problem, but noisy disparity results computed at the first several iterations will misguide the fusion. In this paper, we propose a binary local ordering map to guide the fusion, which converts the depth map into a binary relative format, unifying the relative and absolute depth representation. The computed local ordering map is also used to re-weight the initial disparity update, resolving the local optima and noisy problem. In addition, we formulate the final direct fusion of monocular depth to the disparity as a registration problem, where a pixel-wise linear regression module can globally and adaptively align them. Our method fully exploits the monocular prior to support stereo matching results effectively and efficiently. We significantly improve the performance from the experiments when generalizing from SceneFlow to Middlebury and Booster datasets while barely reducing the efficiency.
3D Visual Illusion Depth Estimation
May 19, 20253D visual illusion is a perceptual phenomenon where a two-dimensional plane is manipulated to simulate three-dimensional spatial relationships, making a flat artwork or object look three-dimensional in the human visual system. In this paper, we reveal that the machine visual system is also seriously fooled by 3D visual illusions, including monocular and binocular depth estimation. In order to explore and analyze the impact of 3D visual illusion on depth estimation, we collect a large dataset containing almost 3k scenes and 200k images to train and evaluate SOTA monocular and binocular depth estimation methods. We also propose a robust depth estimation framework that uses common sense from a vision-language model to adaptively select reliable depth from binocular disparity and monocular depth. Experiments show that SOTA monocular, binocular, and multi-view depth estimation approaches are all fooled by various 3D visual illusions, while our method achieves SOTA performance.
DRL-Based Trajectory Tracking for Motion-Related Modules in Autonomous Driving
Aug 30, 2023



Autonomous driving systems are always built on motion-related modules such as the planner and the controller. An accurate and robust trajectory tracking method is indispensable for these motion-related modules as a primitive routine. Current methods often make strong assumptions about the model such as the context and the dynamics, which are not robust enough to deal with the changing scenarios in a real-world system. In this paper, we propose a Deep Reinforcement Learning (DRL)-based trajectory tracking method for the motion-related modules in autonomous driving systems. The representation learning ability of DL and the exploration nature of RL bring strong robustness and improve accuracy. Meanwhile, it enhances versatility by running the trajectory tracking in a model-free and data-driven manner. Through extensive experiments, we demonstrate both the efficiency and effectiveness of our method compared to current methods.
Content-Aware Inter-Scale Cost Aggregation for Stereo Matching
Jun 05, 2020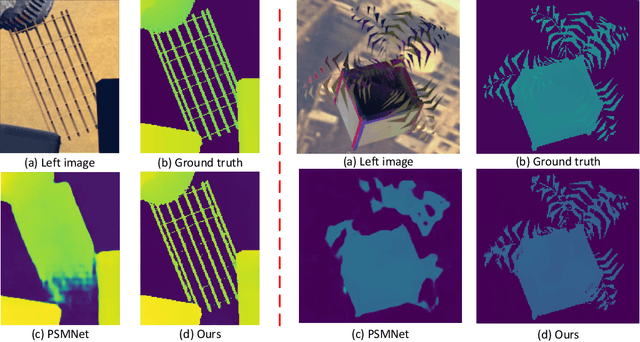

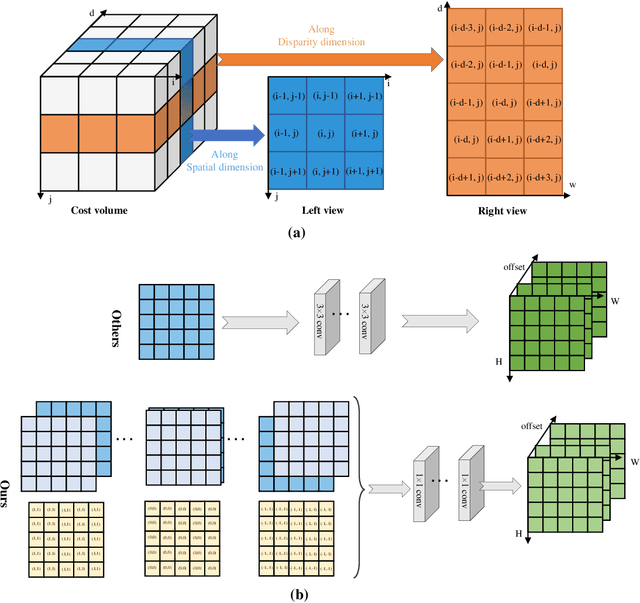

Cost aggregation is a key component of stereo matching for high-quality depth estimation. Most methods use multi-scale processing to downsample cost volume for proper context information, but will cause loss of details when upsampling. In this paper, we present a content-aware inter-scale cost aggregation method that adaptively aggregates and upsamples the cost volume from coarse-scale to fine-scale by learning dynamic filter weights according to the content of the left and right views on the two scales. Our method achieves reliable detail recovery when upsampling through the aggregation of information across different scales. Furthermore, a novel decomposition strategy is proposed to efficiently construct the 3D filter weights and aggregate the 3D cost volume, which greatly reduces the computation cost. We first learn the 2D similarities via the feature maps on the two scales, and then build the 3D filter weights based on the 2D similarities from the left and right views. After that, we split the aggregation in a full 3D spatial-disparity space into the aggregation in 1D disparity space and 2D spatial space. Experiment results on Scene Flow dataset, KITTI2015 and Middlebury demonstrate the effectiveness of our method.
Deep Stereo Matching with Explicit Cost Aggregation Sub-Architecture
Jan 12, 2018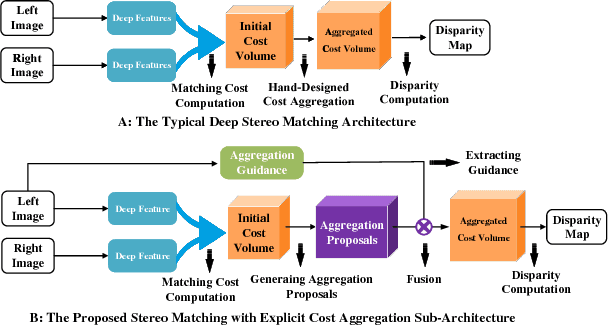

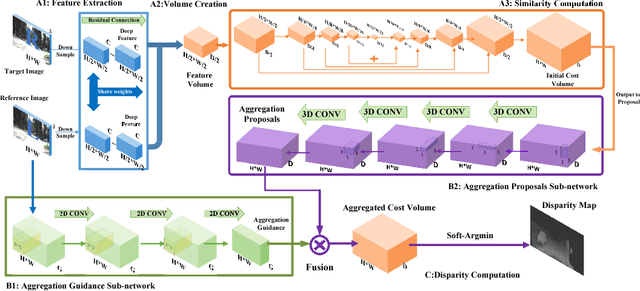
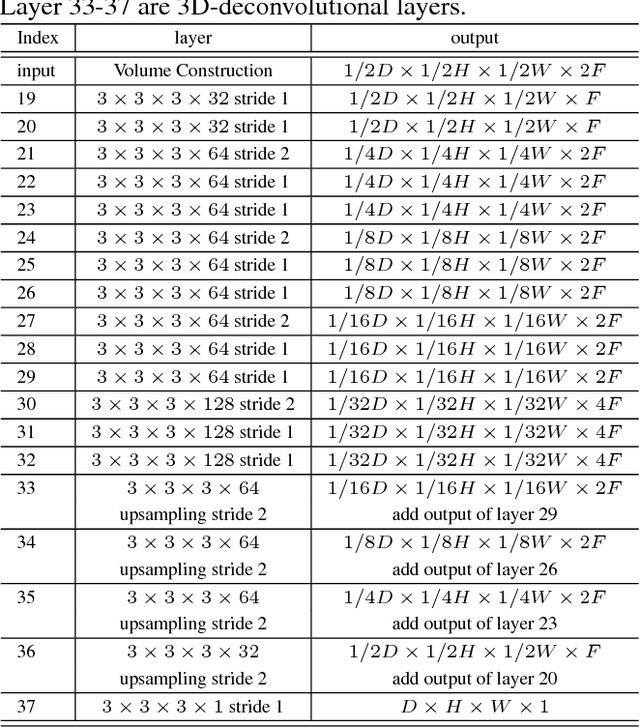
Deep neural networks have shown excellent performance for stereo matching. Many efforts focus on the feature extraction and similarity measurement of the matching cost computation step while less attention is paid on cost aggregation which is crucial for stereo matching. In this paper, we present a learning-based cost aggregation method for stereo matching by a novel sub-architecture in the end-to-end trainable pipeline. We reformulate the cost aggregation as a learning process of the generation and selection of cost aggregation proposals which indicate the possible cost aggregation results. The cost aggregation sub-architecture is realized by a two-stream network: one for the generation of cost aggregation proposals, the other for the selection of the proposals. The criterion for the selection is determined by the low-level structure information obtained from a light convolutional network. The two-stream network offers a global view guidance for the cost aggregation to rectify the mismatching value stemming from the limited view of the matching cost computation. The comprehensive experiments on challenge datasets such as KITTI and Scene Flow show that our method outperforms the state-of-the-art methods.