 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking in cocktail party: Chain-of-Thought and reinforcement learning for target speaker automatic speech recognition
Sep 19, 2025Target Speaker Automatic Speech Recognition (TS-ASR) aims to transcribe the speech of a specified target speaker from multi-speaker mixtures in cocktail party scenarios. Recent advancement of Large Audio-Language Models (LALMs) has already brought some new insights to TS-ASR. However, significant room for optimization remains for the TS-ASR task within the LALMs architecture. While Chain of Thoughts (CoT) and Reinforcement Learning (RL) have proven effective in certain speech tasks, TS-ASR, which requires the model to deeply comprehend speech signals, differentiate various speakers, and handle overlapping utterances is particularly well-suited to a reasoning-guided approach. Therefore, we propose a novel framework that incorporates CoT and RL training into TS-ASR for performance improvement. A novel CoT dataset of TS-ASR is constructed, and the TS-ASR model is first trained on regular data and then fine-tuned on CoT data. Finally, the model is further trained with RL using selected data to enhance generalized reasoning capabilities. Experiment results demonstrate a significant improvement of TS-ASR performance with CoT and RL training, establishing a state-of-the-art performance compared with previous works of TS-ASR on comparable datasets.
Preference fusion and Condorcet's Paradox under uncertainty
Aug 09, 2017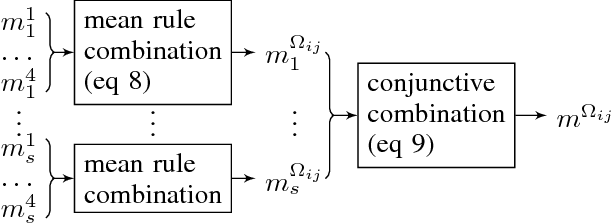
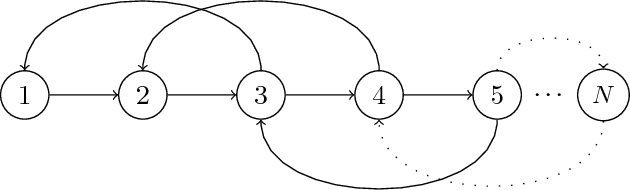
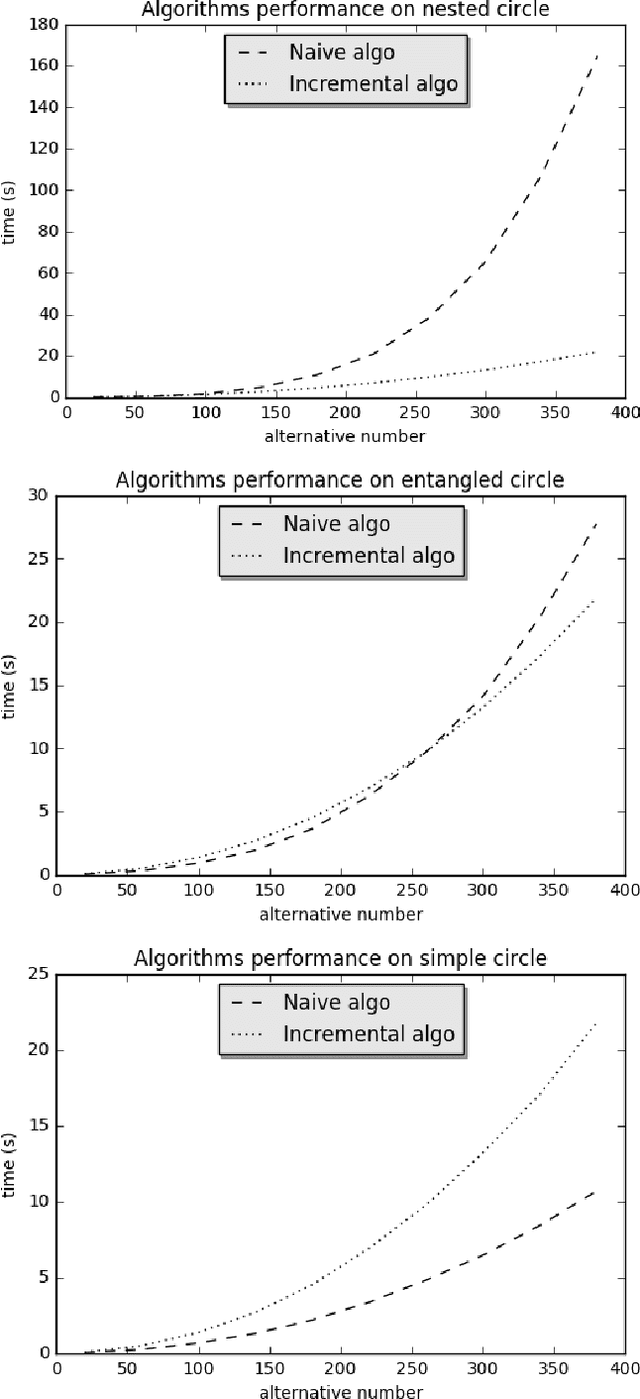
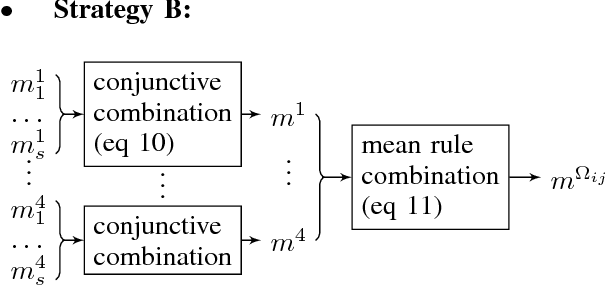
Facing an unknown situation, a person may not be able to firmly elicit his/her preferences over different alternatives, so he/she tends to express uncertain preferences. Given a community of different persons expressing their preferences over certain alternatives under uncertainty, to get a collective representative opinion of the whole community, a preference fusion process is required. The aim of this work is to propose a preference fusion method that copes with uncertainty and escape from the Condorcet paradox. To model preferences under uncertainty, we propose to develop a model of preferences based on belief function theory that accurately describes and captures the uncertainty associated with individual or collective preferences. This work improves and extends the previous results. This work improves and extends the contribution presented in a previous work. The benefits of our contribution are twofold. On the one hand, we propose a qualitative and expressive preference modeling strategy based on belief-function theory which scales better with the number of sources. On the other hand, we propose an incremental distance-based algorithm (using Jousselme distance) for the construction of the collective preference order to avoid the Condorcet Paradox.