 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGestureDiffuCLIP: Gesture Diffusion Model with CLIP Latents
Mar 28, 2023The automatic generation of stylized co-speech gestures has recently received increasing attention. Previous systems typically allow style control via predefined text labels or example motion clips, which are often not flexible enough to convey user intent accurately. In this work, we present GestureDiffuCLIP, a neural network framework for synthesizing realistic, stylized co-speech gestures with flexible style control. We leverage the power of the large-scale Contrastive-Language-Image-Pre-training (CLIP) model and present a novel CLIP-guided mechanism that extracts efficient style representations from multiple input modalities, such as a piece of text, an example motion clip, or a video. Our system learns a latent diffusion model to generate high-quality gestures and infuses the CLIP representations of style into the generator via an adaptive instance normalization (AdaIN) layer. We further devise a gesture-transcript alignment mechanism that ensures a semantically correct gesture generation based on contrastive learning. Our system can also be extended to allow fine-grained style control of individual body parts. We demonstrate an extensive set of examples showing the flexibility and generalizability of our model to a variety of style descriptions. In a user study, we show that our system outperforms the state-of-the-art approaches regarding human likeness, appropriateness, and style correctness.
2D-Empowered 3D Object Detection on the Edge
Feb 18, 2023



3D object detection has a pivotal role in a wide range of applications, most notably autonomous driving and robotics. These applications are commonly deployed on edge devices to promptly interact with the environment, and often require near real-time response. With limited computation power, it is challenging to execute 3D detection on the edge using highly complex neural networks. Common approaches such as offloading to the cloud brings latency overheads due to the large amount of 3D point cloud data during transmission. To resolve the tension between wimpy edge devices and compute-intensive inference workloads, we explore the possibility of transforming fast 2D detection results to extrapolate 3D bounding boxes. To this end, we present Moby, a novel system that demonstrates the feasibility and potential of our approach. Our main contributions are two-fold: First, we design a 2D-to-3D transformation pipeline that takes as input the point cloud data from LiDAR and 2D bounding boxes from camera that are captured at exactly the same time, and generate 3D bounding boxes efficiently and accurately based on detection results of the previous frames without running 3D detectors. Second, we design a frame offloading scheduler that dynamically launches a 3D detection when the error of 2D-to-3D transformation accumulates to a certain level, so the subsequent transformations can draw upon the latest 3D detection results with better accuracy. Extensive evaluation on NVIDIA Jetson TX2 with the autonomous driving dataset KITTI and real-world 4G/LTE traces shows that, Moby reduces the end-to-end latency by up to 91.9% with mild accuracy drop compared to baselines. Further, Moby shows excellent energy efficiency by saving power consumption and memory footprint up to 75.7% and 48.1%, respectively.
ControlVAE: Model-Based Learning of Generative Controllers for Physics-Based Characters
Oct 12, 2022
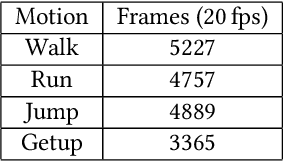
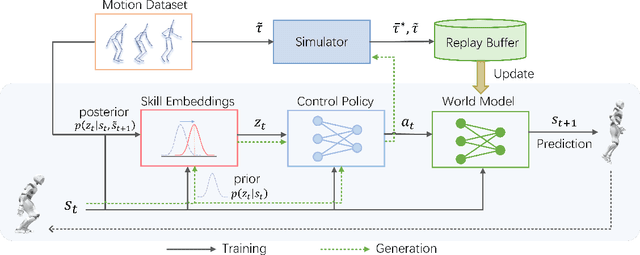
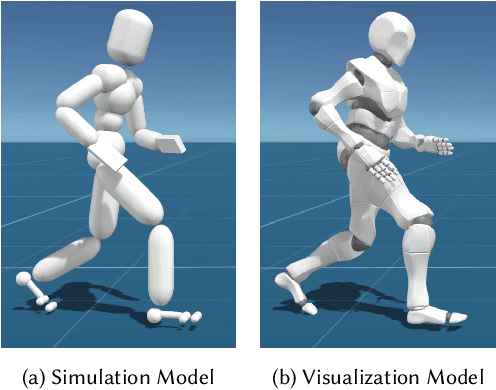
In this paper, we introduce ControlVAE, a novel model-based framework for learning generative motion control policies based on variational autoencoders (VAE). Our framework can learn a rich and flexible latent representation of skills and a skill-conditioned generative control policy from a diverse set of unorganized motion sequences, which enables the generation of realistic human behaviors by sampling in the latent space and allows high-level control policies to reuse the learned skills to accomplish a variety of downstream tasks. In the training of ControlVAE, we employ a learnable world model to realize direct supervision of the latent space and the control policy. This world model effectively captures the unknown dynamics of the simulation system, enabling efficient model-based learning of high-level downstream tasks. We also learn a state-conditional prior distribution in the VAE-based generative control policy, which generates a skill embedding that outperforms the non-conditional priors in downstream tasks. We demonstrate the effectiveness of ControlVAE using a diverse set of tasks, which allows realistic and interactive control of the simulated characters.
MotionBERT: Unified Pretraining for Human Motion Analysis
Oct 12, 2022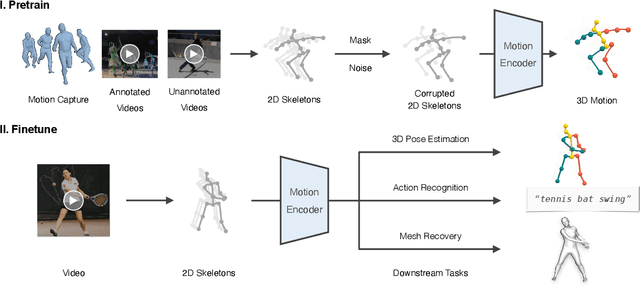
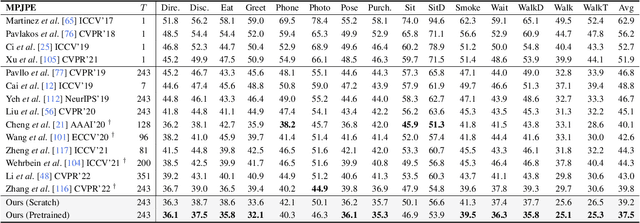
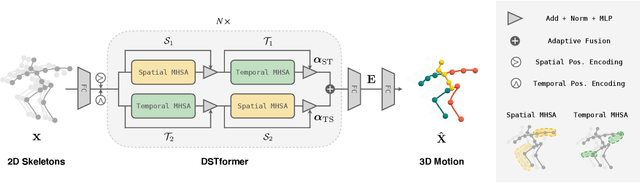
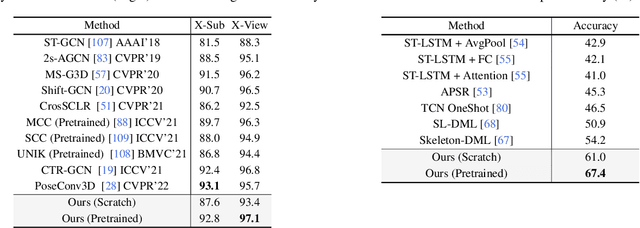
We present MotionBERT, a unified pretraining framework, to tackle different sub-tasks of human motion analysis including 3D pose estimation, skeleton-based action recognition, and mesh recovery. The proposed framework is capable of utilizing all kinds of human motion data resources, including motion capture data and in-the-wild videos. During pretraining, the pretext task requires the motion encoder to recover the underlying 3D motion from noisy partial 2D observations. The pretrained motion representation thus acquires geometric, kinematic, and physical knowledge about human motion and therefore can be easily transferred to multiple downstream tasks. We implement the motion encoder with a novel Dual-stream Spatio-temporal Transformer (DSTformer) neural network. It could capture long-range spatio-temporal relationships among the skeletal joints comprehensively and adaptively, exemplified by the lowest 3D pose estimation error so far when trained from scratch. More importantly, the proposed framework achieves state-of-the-art performance on all three downstream tasks by simply finetuning the pretrained motion encoder with 1-2 linear layers, which demonstrates the versatility of the learned motion representations.
Rhythmic Gesticulator: Rhythm-Aware Co-Speech Gesture Synthesis with Hierarchical Neural Embeddings
Oct 05, 2022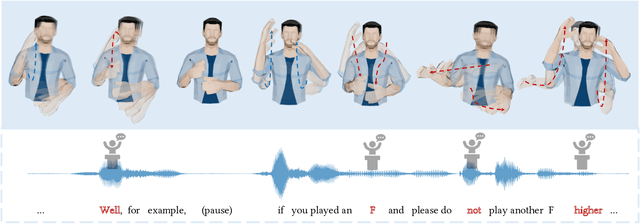
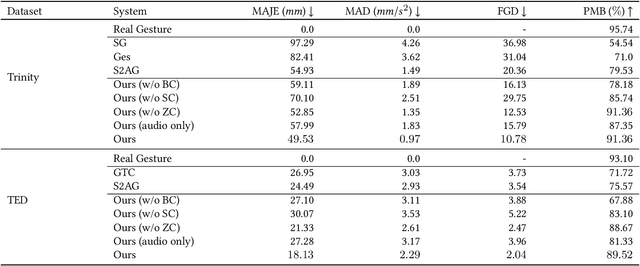
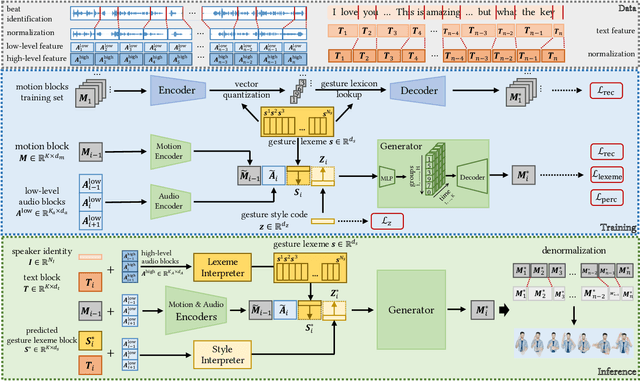
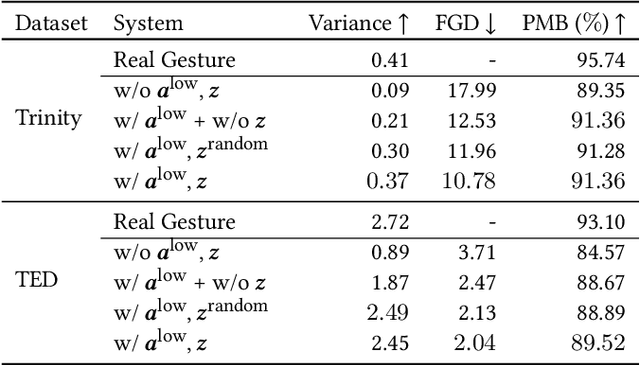
Automatic synthesis of realistic co-speech gestures is an increasingly important yet challenging task in artificial embodied agent creation. Previous systems mainly focus on generating gestures in an end-to-end manner, which leads to difficulties in mining the clear rhythm and semantics due to the complex yet subtle harmony between speech and gestures. We present a novel co-speech gesture synthesis method that achieves convincing results both on the rhythm and semantics. For the rhythm, our system contains a robust rhythm-based segmentation pipeline to ensure the temporal coherence between the vocalization and gestures explicitly. For the gesture semantics, we devise a mechanism to effectively disentangle both low- and high-level neural embeddings of speech and motion based on linguistic theory. The high-level embedding corresponds to semantics, while the low-level embedding relates to subtle variations. Lastly, we build correspondence between the hierarchical embeddings of the speech and the motion, resulting in rhythm- and semantics-aware gesture synthesis. Evaluations with existing objective metrics, a newly proposed rhythmic metric, and human feedback show that our method outperforms state-of-the-art systems by a clear margin.
Neural Novel Actor: Learning a Generalized Animatable Neural Representation for Human Actors
Aug 25, 2022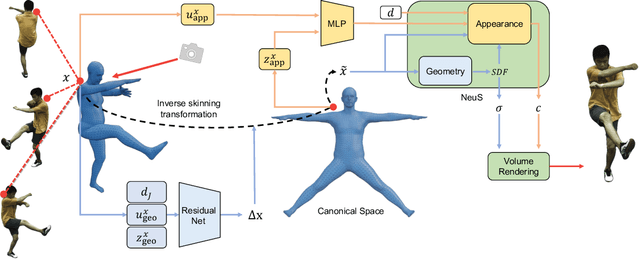

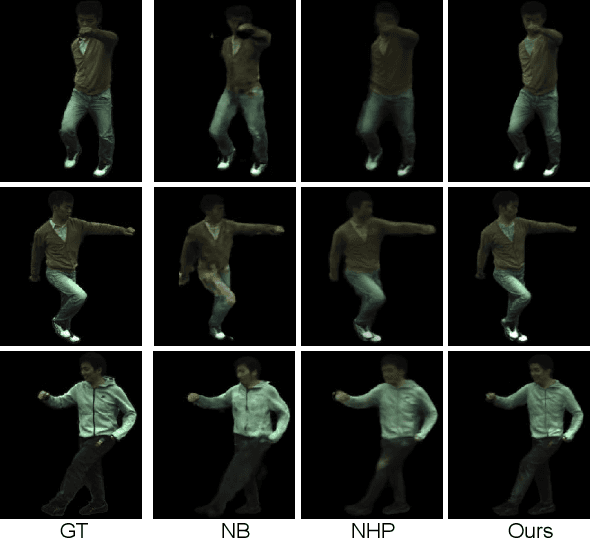

We propose a new method for learning a generalized animatable neural human representation from a sparse set of multi-view imagery of multiple persons. The learned representation can be used to synthesize novel view images of an arbitrary person from a sparse set of cameras, and further animate them with the user's pose control. While existing methods can either generalize to new persons or synthesize animations with user control, none of them can achieve both at the same time. We attribute this accomplishment to the employment of a 3D proxy for a shared multi-person human model, and further the warping of the spaces of different poses to a shared canonical pose space, in which we learn a neural field and predict the person- and pose-dependent deformations, as well as appearance with the features extracted from input images. To cope with the complexity of the large variations in body shapes, poses, and clothing deformations, we design our neural human model with disentangled geometry and appearance. Furthermore, we utilize the image features both at the spatial point and on the surface points of the 3D proxy for predicting person- and pose-dependent properties. Experiments show that our method significantly outperforms the state-of-the-arts on both tasks. The video and code are available at https://talegqz.github.io/neural_novel_actor.
Learning to Use Chopsticks in Diverse Styles
May 28, 2022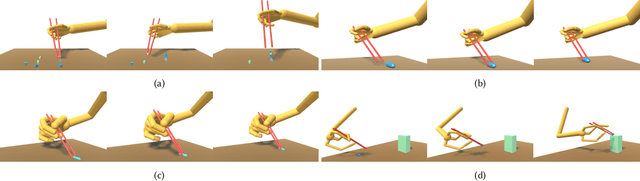

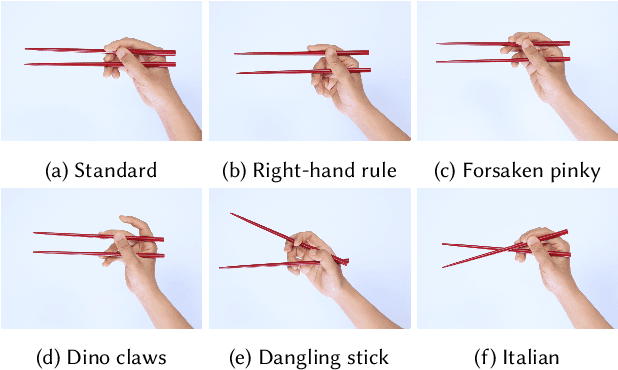

Learning dexterous manipulation skills is a long-standing challenge in computer graphics and robotics, especially when the task involves complex and delicate interactions between the hands, tools and objects. In this paper, we focus on chopsticks-based object relocation tasks, which are common yet demanding. The key to successful chopsticks skills is steady gripping of the sticks that also supports delicate maneuvers. We automatically discover physically valid chopsticks holding poses by Bayesian Optimization (BO) and Deep Reinforcement Learning (DRL), which works for multiple gripping styles and hand morphologies without the need of example data. Given as input the discovered gripping poses and desired objects to be moved, we build physics-based hand controllers to accomplish relocation tasks in two stages. First, kinematic trajectories are synthesized for the chopsticks and hand in a motion planning stage. The key components of our motion planner include a grasping model to select suitable chopsticks configurations for grasping the object, and a trajectory optimization module to generate collision-free chopsticks trajectories. Then we train physics-based hand controllers through DRL again to track the desired kinematic trajectories produced by the motion planner. We demonstrate the capabilities of our framework by relocating objects of various shapes and sizes, in diverse gripping styles and holding positions for multiple hand morphologies. Our system achieves faster learning speed and better control robustness, when compared to vanilla systems that attempt to learn chopstick-based skills without a gripping pose optimization module and/or without a kinematic motion planner.
Unsupervised Co-part Segmentation through Assembly
Jun 10, 2021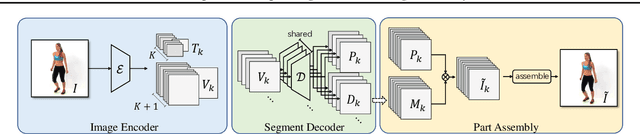
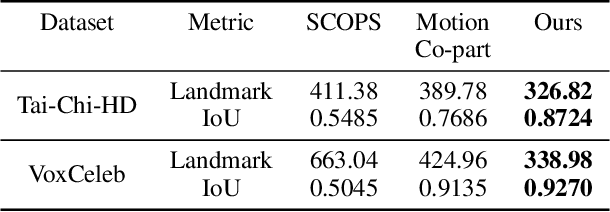
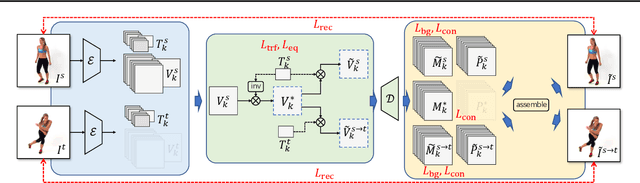
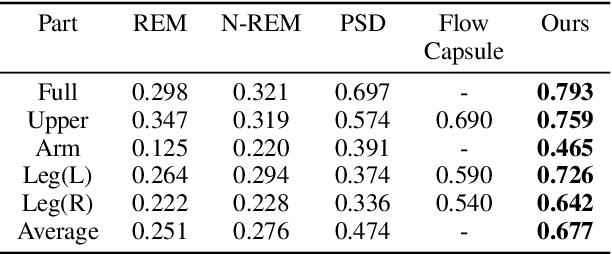
Co-part segmentation is an important problem in computer vision for its rich applications. We propose an unsupervised learning approach for co-part segmentation from images. For the training stage, we leverage motion information embedded in videos and explicitly extract latent representations to segment meaningful object parts. More importantly, we introduce a dual procedure of part-assembly to form a closed loop with part-segmentation, enabling an effective self-supervision. We demonstrate the effectiveness of our approach with a host of extensive experiments, ranging from human bodies, hands, quadruped, and robot arms. We show that our approach can achieve meaningful and compact part segmentation, outperforming state-of-the-art approaches on diverse benchmarks.
Learning Skeletal Articulations with Neural Blend Shapes
May 06, 2021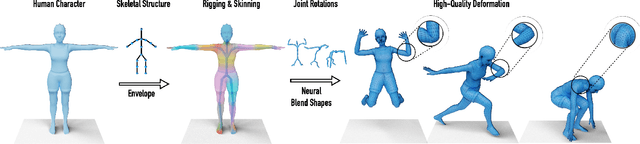
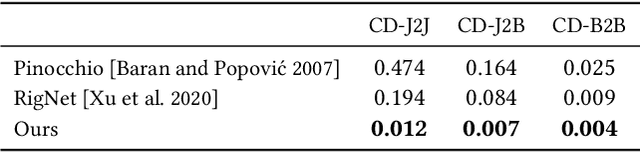
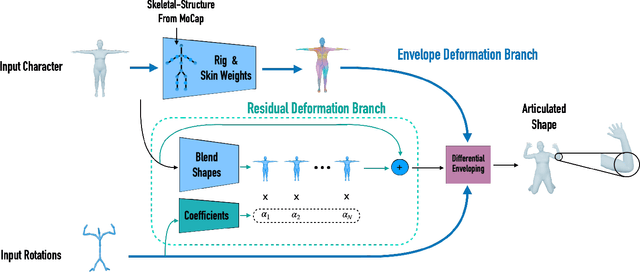
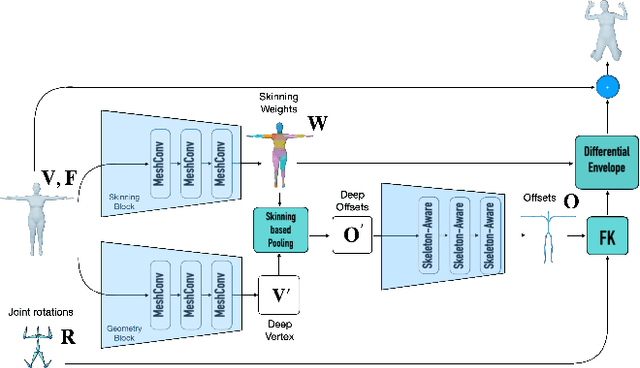
Animating a newly designed character using motion capture (mocap) data is a long standing problem in computer animation. A key consideration is the skeletal structure that should correspond to the available mocap data, and the shape deformation in the joint regions, which often requires a tailored, pose-specific refinement. In this work, we develop a neural technique for articulating 3D characters using enveloping with a pre-defined skeletal structure which produces high quality pose dependent deformations. Our framework learns to rig and skin characters with the same articulation structure (e.g., bipeds or quadrupeds), and builds the desired skeleton hierarchy into the network architecture. Furthermore, we propose neural blend shapes--a set of corrective pose-dependent shapes which improve the deformation quality in the joint regions in order to address the notorious artifacts resulting from standard rigging and skinning. Our system estimates neural blend shapes for input meshes with arbitrary connectivity, as well as weighting coefficients which are conditioned on the input joint rotations. Unlike recent deep learning techniques which supervise the network with ground-truth rigging and skinning parameters, our approach does not assume that the training data has a specific underlying deformation model. Instead, during training, the network observes deformed shapes and learns to infer the corresponding rig, skin and blend shapes using indirect supervision. During inference, we demonstrate that our network generalizes to unseen characters with arbitrary mesh connectivity, including unrigged characters built by 3D artists. Conforming to standard skeletal animation models enables direct plug-and-play in standard animation software, as well as game engines.