 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Machine Learning Development and Deployment for Edge Devices
Jun 20, 2018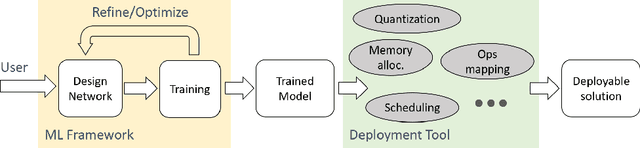
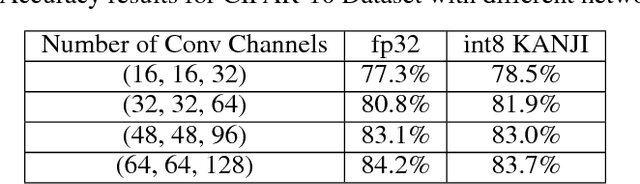
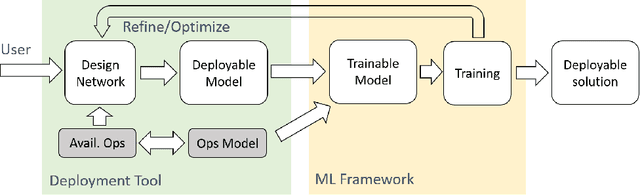
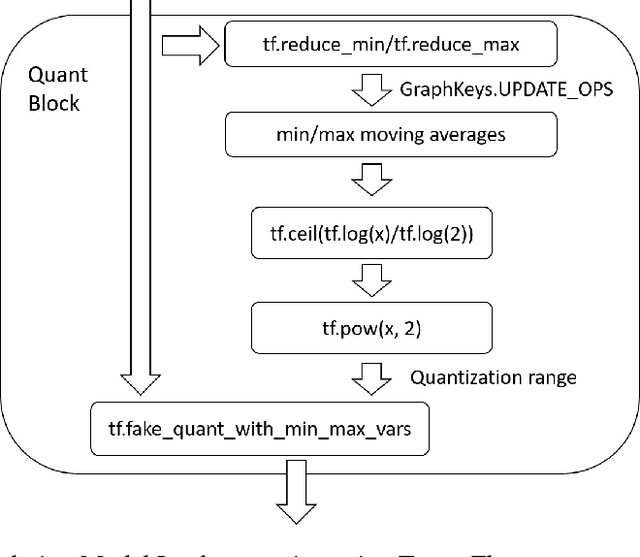
Machine learning (ML), especially deep learning is made possible by the availability of big data, enormous compute power and, often overlooked, development tools or frameworks. As the algorithms become mature and efficient, more and more ML inference is moving out of datacenters/cloud and deployed on edge devices. This model deployment process can be challenging as the deployment environment and requirements can be substantially different from those during model development. In this paper, we propose a new ML development and deployment approach that is specially designed and optimized for inference-only deployment on edge devices. We build a prototype and demonstrate that this approach can address all the deployment challenges and result in more efficient and high-quality solutions.
Federated Learning with Non-IID Data
Jun 02, 2018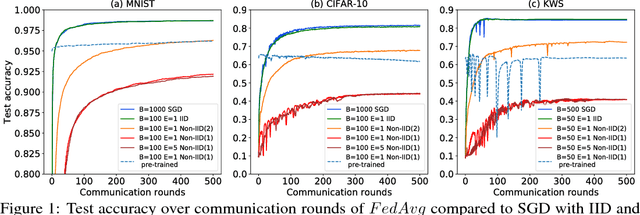
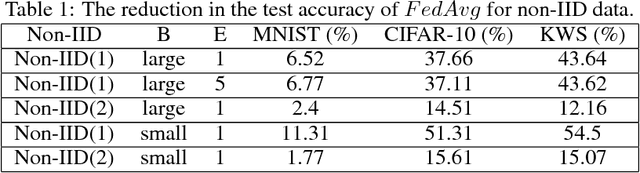
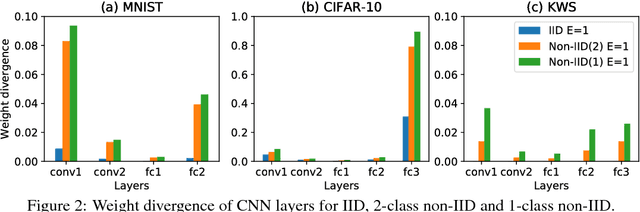
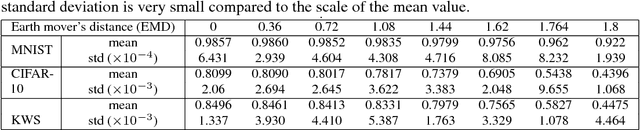
Federated learning enables resource-constrained edge compute devices, such as mobile phones and IoT devices, to learn a shared model for prediction, while keeping the training data local. This decentralized approach to train models provides privacy, security, regulatory and economic benefits. In this work, we focus on the statistical challenge of federated learning when local data is non-IID. We first show that the accuracy of federated learning reduces significantly, by up to 55% for neural networks trained for highly skewed non-IID data, where each client device trains only on a single class of data. We further show that this accuracy reduction can be explained by the weight divergence, which can be quantified by the earth mover's distance (EMD) between the distribution over classes on each device and the population distribution. As a solution, we propose a strategy to improve training on non-IID data by creating a small subset of data which is globally shared between all the edge devices. Experiments show that accuracy can be increased by 30% for the CIFAR-10 dataset with only 5% globally shared data.
Bit Fusion: Bit-Level Dynamically Composable Architecture for Accelerating Deep Neural Networks
May 30, 2018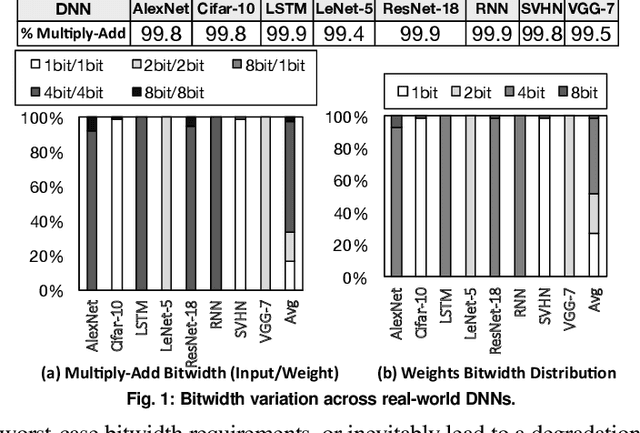
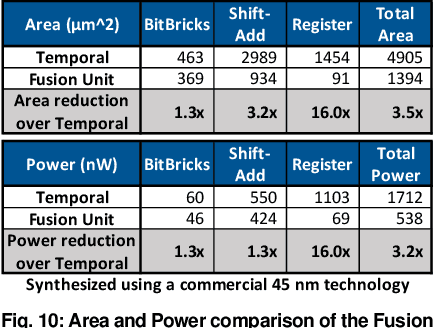
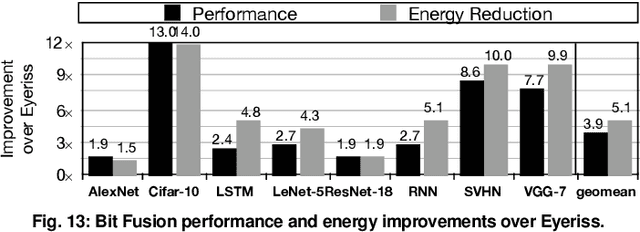
Fully realizing the potential of acceleration for Deep Neural Networks (DNNs) requires understanding and leveraging algorithmic properties. This paper builds upon the algorithmic insight that bitwidth of operations in DNNs can be reduced without compromising their classification accuracy. However, to prevent accuracy loss, the bitwidth varies significantly across DNNs and it may even be adjusted for each layer. Thus, a fixed-bitwidth accelerator would either offer limited benefits to accommodate the worst-case bitwidth requirements, or lead to a degradation in final accuracy. To alleviate these deficiencies, this work introduces dynamic bit-level fusion/decomposition as a new dimension in the design of DNN accelerators. We explore this dimension by designing Bit Fusion, a bit-flexible accelerator, that constitutes an array of bit-level processing elements that dynamically fuse to match the bitwidth of individual DNN layers. This flexibility in the architecture enables minimizing the computation and the communication at the finest granularity possible with no loss in accuracy. We evaluate the benefits of BitFusion using eight real-world feed-forward and recurrent DNNs. The proposed microarchitecture is implemented in Verilog and synthesized in 45 nm technology. Using the synthesis results and cycle accurate simulation, we compare the benefits of Bit Fusion to two state-of-the-art DNN accelerators, Eyeriss and Stripes. In the same area, frequency, and process technology, BitFusion offers 3.9x speedup and 5.1x energy savings over Eyeriss. Compared to Stripes, BitFusion provides 2.6x speedup and 3.9x energy reduction at 45 nm node when BitFusion area and frequency are set to those of Stripes. Scaling to GPU technology node of 16 nm, BitFusion almost matches the performance of a 250-Watt Titan Xp, which uses 8-bit vector instructions, while BitFusion merely consumes 895 milliwatts of power.
Hello Edge: Keyword Spotting on Microcontrollers
Feb 14, 2018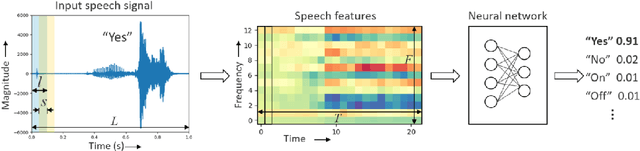

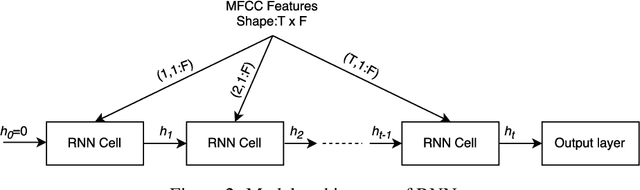
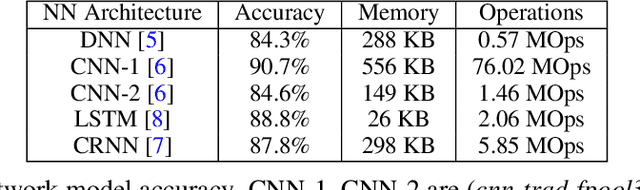
Keyword spotting (KWS) is a critical component for enabling speech based user interactions on smart devices. It requires real-time response and high accuracy for good user experience. Recently, neural networks have become an attractive choice for KWS architecture because of their superior accuracy compared to traditional speech processing algorithms. Due to its always-on nature, KWS application has highly constrained power budget and typically runs on tiny microcontrollers with limited memory and compute capability. The design of neural network architecture for KWS must consider these constraints. In this work, we perform neural network architecture evaluation and exploration for running KWS on resource-constrained microcontrollers. We train various neural network architectures for keyword spotting published in literature to compare their accuracy and memory/compute requirements. We show that it is possible to optimize these neural network architectures to fit within the memory and compute constraints of microcontrollers without sacrificing accuracy. We further explore the depthwise separable convolutional neural network (DS-CNN) and compare it against other neural network architectures. DS-CNN achieves an accuracy of 95.4%, which is ~10% higher than the DNN model with similar number of parameters.
Not All Ops Are Created Equal!
Jan 29, 2018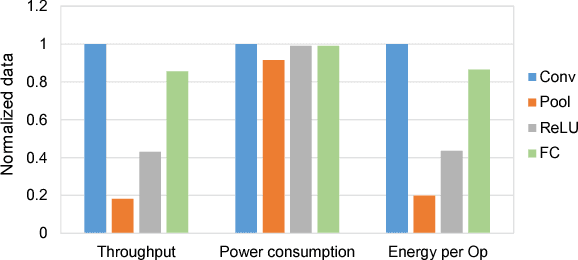
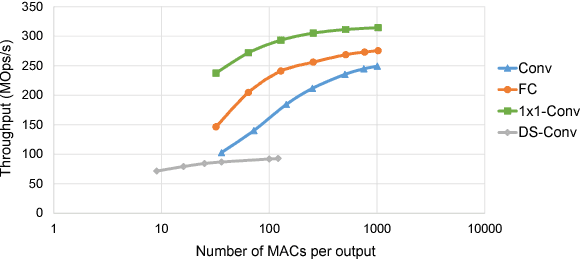


Efficient and compact neural network models are essential for enabling the deployment on mobile and embedded devices. In this work, we point out that typical design metrics for gauging the efficiency of neural network architectures -- total number of operations and parameters -- are not sufficient. These metrics may not accurately correlate with the actual deployment metrics such as energy and memory footprint. We show that throughput and energy varies by up to 5X across different neural network operation types on an off-the-shelf Arm Cortex-M7 microcontroller. Furthermore, we show that the memory required for activation data also need to be considered, apart from the model parameters, for network architecture exploration studies.
CMSIS-NN: Efficient Neural Network Kernels for Arm Cortex-M CPUs
Jan 19, 2018
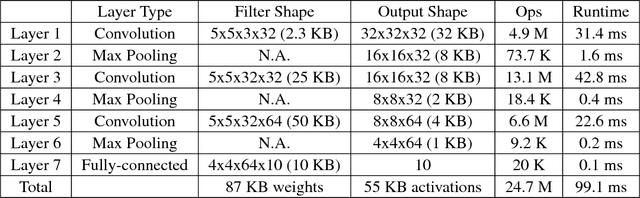
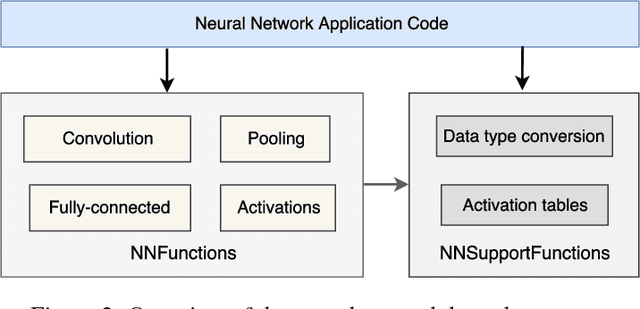

Deep Neural Networks are becoming increasingly popular in always-on IoT edge devices performing data analytics right at the source, reducing latency as well as energy consumption for data communication. This paper presents CMSIS-NN, efficient kernels developed to maximize the performance and minimize the memory footprint of neural network (NN) applications on Arm Cortex-M processors targeted for intelligent IoT edge devices. Neural network inference based on CMSIS-NN kernels achieves 4.6X improvement in runtime/throughput and 4.9X improvement in energy efficiency.
PrivyNet: A Flexible Framework for Privacy-Preserving Deep Neural Network Training
Jan 12, 2018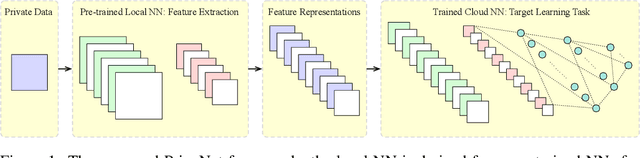

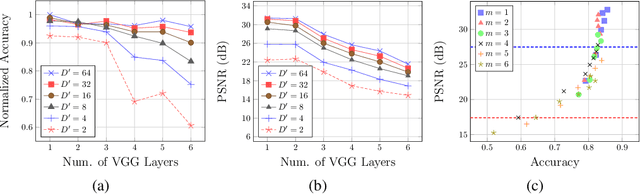
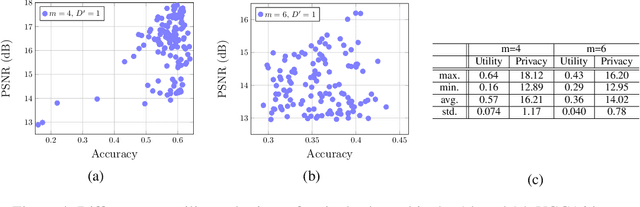
Massive data exist among user local platforms that usually cannot support deep neural network (DNN) training due to computation and storage resource constraints. Cloud-based training schemes provide beneficial services but suffer from potential privacy risks due to excessive user data collection. To enable cloud-based DNN training while protecting the data privacy simultaneously, we propose to leverage the intermediate representations of the data, which is achieved by splitting the DNNs and deploying them separately onto local platforms and the cloud. The local neural network (NN) is used to generate the feature representations. To avoid local training and protect data privacy, the local NN is derived from pre-trained NNs. The cloud NN is then trained based on the extracted intermediate representations for the target learning task. We validate the idea of DNN splitting by characterizing the dependency of privacy loss and classification accuracy on the local NN topology for a convolutional NN (CNN) based image classification task. Based on the characterization, we further propose PrivyNet to determine the local NN topology, which optimizes the accuracy of the target learning task under the constraints on privacy loss, local computation, and storage. The efficiency and effectiveness of PrivyNet are demonstrated with the CIFAR-10 dataset.
Deep Convolutional Neural Network Inference with Floating-point Weights and Fixed-point Activations
Mar 08, 2017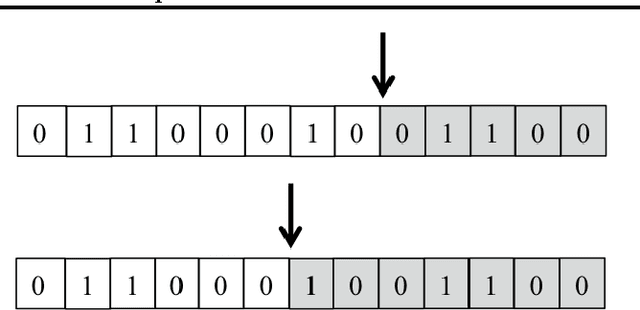
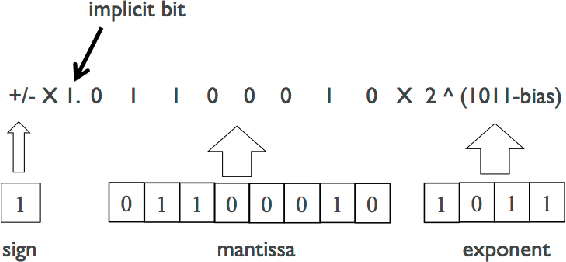
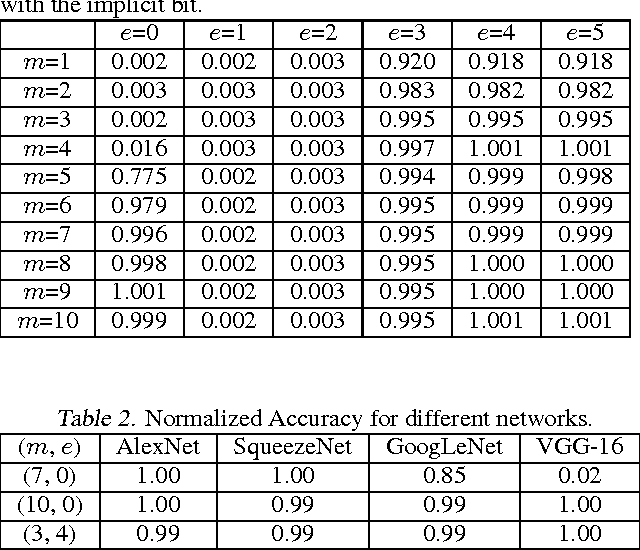
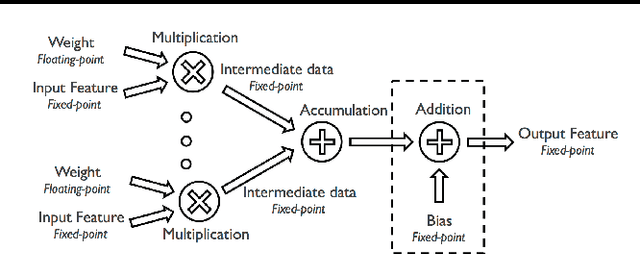
Deep convolutional neural network (CNN) inference requires significant amount of memory and computation, which limits its deployment on embedded devices. To alleviate these problems to some extent, prior research utilize low precision fixed-point numbers to represent the CNN weights and activations. However, the minimum required data precision of fixed-point weights varies across different networks and also across different layers of the same network. In this work, we propose using floating-point numbers for representing the weights and fixed-point numbers for representing the activations. We show that using floating-point representation for weights is more efficient than fixed-point representation for the same bit-width and demonstrate it on popular large-scale CNNs such as AlexNet, SqueezeNet, GoogLeNet and VGG-16. We also show that such a representation scheme enables compact hardware multiply-and-accumulate (MAC) unit design. Experimental results show that the proposed scheme reduces the weight storage by up to 36% and power consumption of the hardware multiplier by up to 50%.