 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeted Separation and Convergence with Kernel Discrepancies
Sep 26, 2022Maximum mean discrepancies (MMDs) like the kernel Stein discrepancy (KSD) have grown central to a wide range of applications, including hypothesis testing, sampler selection, distribution approximation, and variational inference. In each setting, these kernel-based discrepancy measures are required to (i) separate a target P from other probability measures or even (ii) control weak convergence to P. In this article we derive new sufficient and necessary conditions to ensure (i) and (ii). For MMDs on separable metric spaces, we characterize those kernels that separate Bochner embeddable measures and introduce simple conditions for separating all measures with unbounded kernels and for controlling convergence with bounded kernels. We use these results on $\mathbb{R}^d$ to substantially broaden the known conditions for KSD separation and convergence control and to develop the first KSDs known to exactly metrize weak convergence to P. Along the way, we highlight the implications of our results for hypothesis testing, measuring and improving sample quality, and sampling with Stein variational gradient descent.
Adaptive Bias Correction for Improved Subseasonal Forecasting
Sep 21, 2022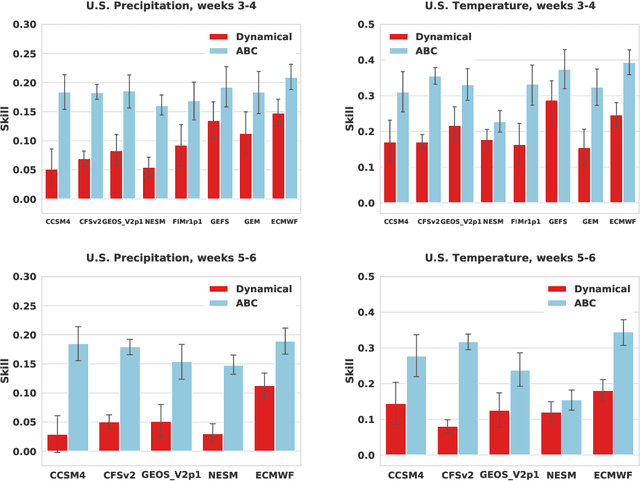
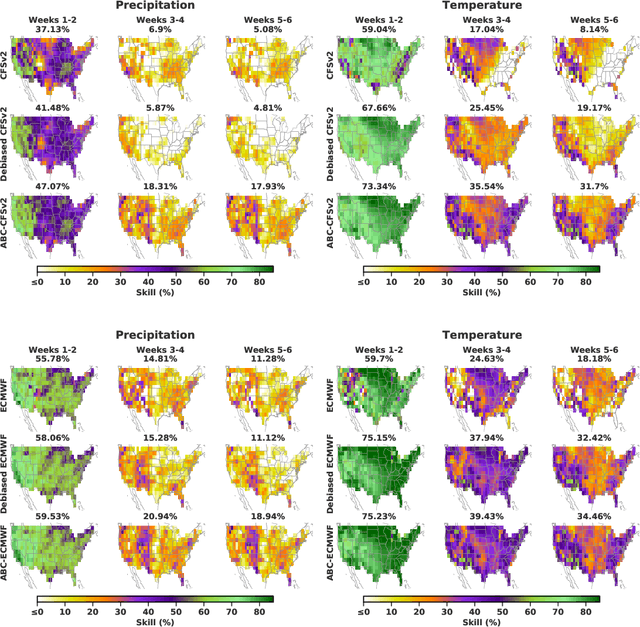
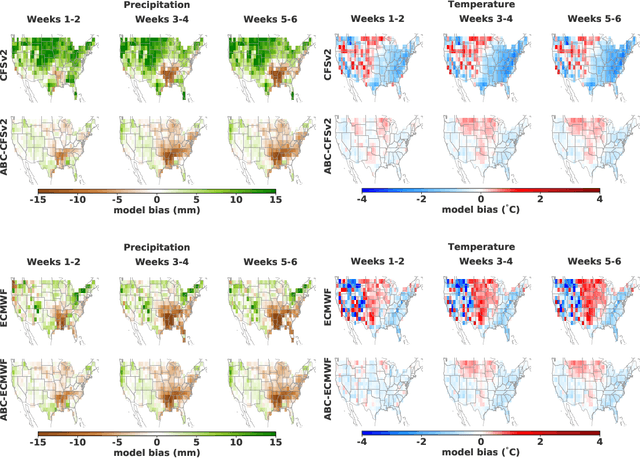
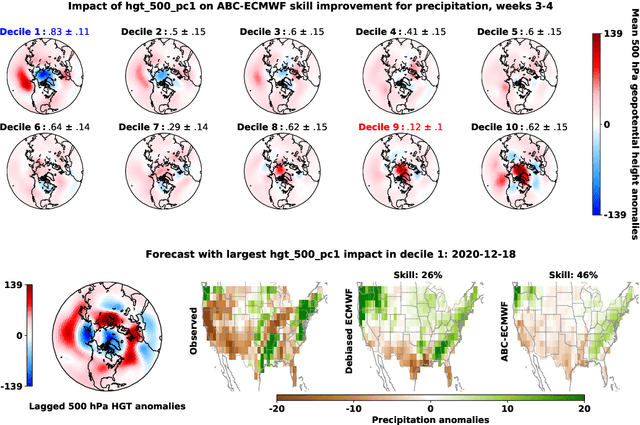
Subseasonal forecasting $\unicode{x2013}$ predicting temperature and precipitation 2 to 6 weeks $\unicode{x2013}$ ahead is critical for effective water allocation, wildfire management, and drought and flood mitigation. Recent international research efforts have advanced the subseasonal capabilities of operational dynamical models, yet temperature and precipitation prediction skills remains poor, partly due to stubborn errors in representing atmospheric dynamics and physics inside dynamical models. To counter these errors, we introduce an adaptive bias correction (ABC) method that combines state-of-the-art dynamical forecasts with observations using machine learning. When applied to the leading subseasonal model from the European Centre for Medium-Range Weather Forecasts (ECMWF), ABC improves temperature forecasting skill by 60-90% and precipitation forecasting skill by 40-69% in the contiguous U.S. We couple these performance improvements with a practical workflow, based on Cohort Shapley, for explaining ABC skill gains and identifying higher-skill windows of opportunity based on specific climate conditions.
Scalable Spike-and-Slab
Apr 04, 2022
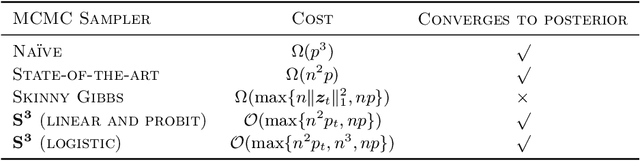

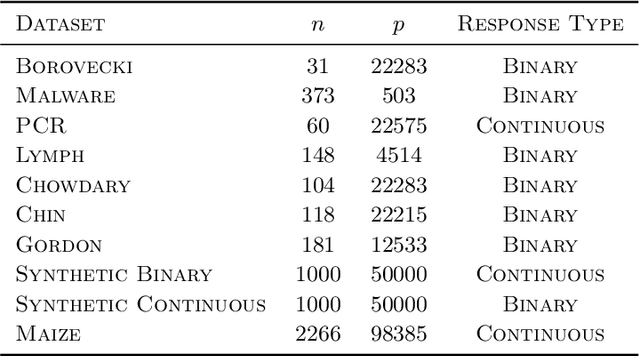
Spike-and-slab priors are commonly used for Bayesian variable selection, due to their interpretability and favorable statistical properties. However, existing samplers for spike-and-slab posteriors incur prohibitive computational costs when the number of variables is large. In this article, we propose Scalable Spike-and-Slab ($S^3$), a scalable Gibbs sampling implementation for high-dimensional Bayesian regression with the continuous spike-and-slab prior of George and McCulloch (1993). For a dataset with $n$ observations and $p$ covariates, $S^3$ has order $\max\{ n^2 p_t, np \}$ computational cost at iteration $t$ where $p_t$ never exceeds the number of covariates switching spike-and-slab states between iterations $t$ and $t-1$ of the Markov chain. This improves upon the order $n^2 p$ per-iteration cost of state-of-the-art implementations as, typically, $p_t$ is substantially smaller than $p$. We apply $S^3$ on synthetic and real-world datasets, demonstrating orders of magnitude speed-ups over existing exact samplers and significant gains in inferential quality over approximate samplers with comparable cost.
Gradient Estimation with Discrete Stein Operators
Feb 19, 2022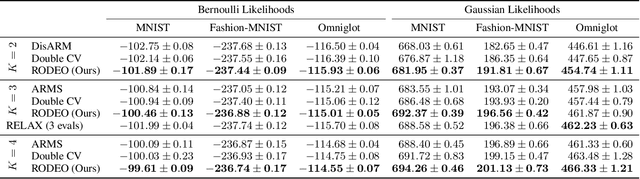
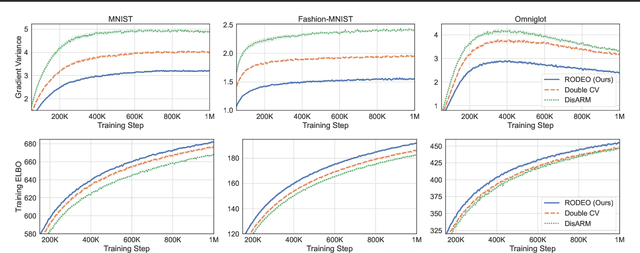
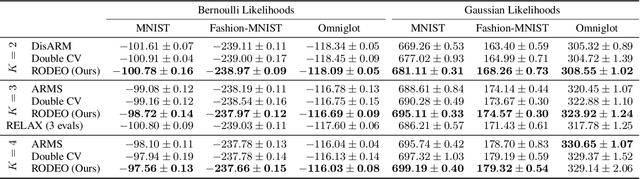
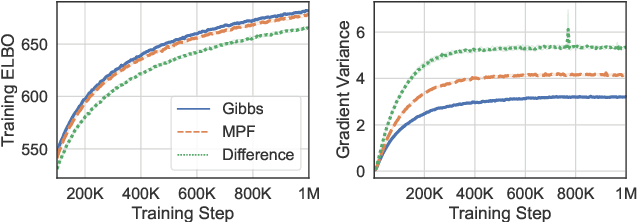
Gradient estimation -- approximating the gradient of an expectation with respect to the parameters of a distribution -- is central to the solution of many machine learning problems. However, when the distribution is discrete, most common gradient estimators suffer from excessive variance. To improve the quality of gradient estimation, we introduce a variance reduction technique based on Stein operators for discrete distributions. We then use this technique to build flexible control variates for the REINFORCE leave-one-out estimator. Our control variates can be adapted online to minimize the variance and do not require extra evaluations of the target function. In benchmark generative modeling tasks such as training binary variational autoencoders, our gradient estimator achieves substantially lower variance than state-of-the-art estimators with the same number of function evaluations.
Bounding Wasserstein distance with couplings
Dec 29, 2021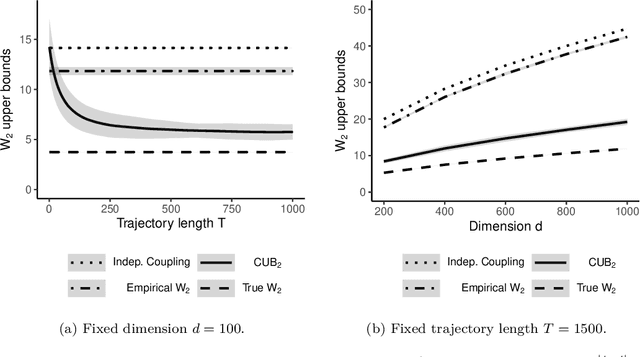
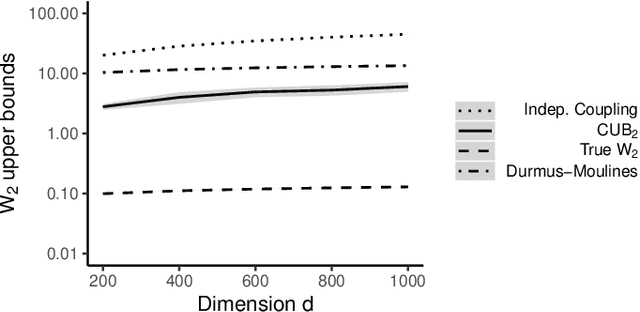
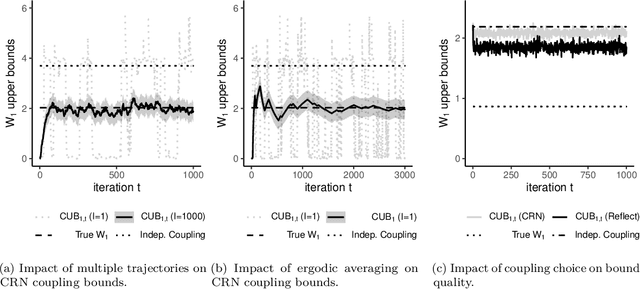
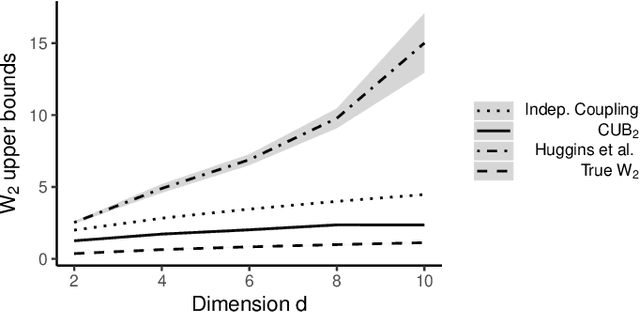
Markov chain Monte Carlo (MCMC) provides asymptotically consistent estimates of intractable posterior expectations as the number of iterations tends to infinity. However, in large data applications, MCMC can be computationally expensive per iteration. This has catalyzed interest in sampling methods such as approximate MCMC, which trade off asymptotic consistency for improved computational speed. In this article, we propose estimators based on couplings of Markov chains to assess the quality of such asymptotically biased sampling methods. The estimators give empirical upper bounds of the Wassertein distance between the limiting distribution of the asymptotically biased sampling method and the original target distribution of interest. We establish theoretical guarantees for our upper bounds and show that our estimators can remain effective in high dimensions. We apply our quality measures to stochastic gradient MCMC, variational Bayes, and Laplace approximations for tall data and to approximate MCMC for Bayesian logistic regression in 4500 dimensions and Bayesian linear regression in 50000 dimensions.
Distribution Compression in Near-linear Time
Nov 17, 2021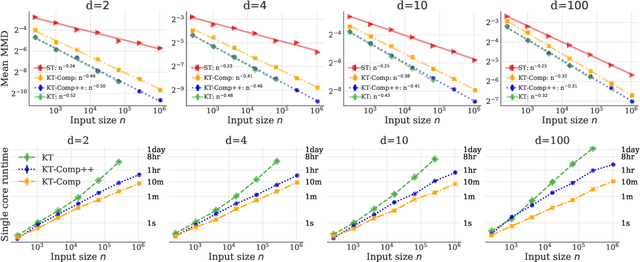
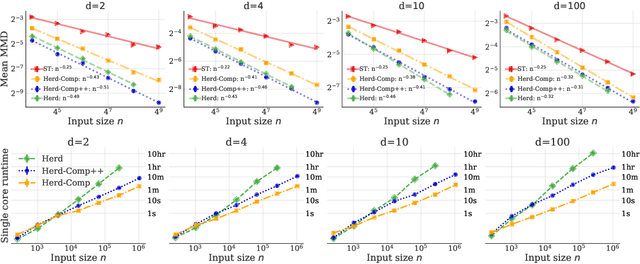
In distribution compression, one aims to accurately summarize a probability distribution $\mathbb{P}$ using a small number of representative points. Near-optimal thinning procedures achieve this goal by sampling $n$ points from a Markov chain and identifying $\sqrt{n}$ points with $\widetilde{\mathcal{O}}(1/\sqrt{n})$ discrepancy to $\mathbb{P}$. Unfortunately, these algorithms suffer from quadratic or super-quadratic runtime in the sample size $n$. To address this deficiency, we introduce Compress++, a simple meta-procedure for speeding up any thinning algorithm while suffering at most a factor of $4$ in error. When combined with the quadratic-time kernel halving and kernel thinning algorithms of Dwivedi and Mackey (2021), Compress++ delivers $\sqrt{n}$ points with $\mathcal{O}(\sqrt{\log n/n})$ integration error and better-than-Monte-Carlo maximum mean discrepancy in $\mathcal{O}(n \log^3 n)$ time and $\mathcal{O}( \sqrt{n} \log^2 n )$ space. Moreover, Compress++ enjoys the same near-linear runtime given any quadratic-time input and reduces the runtime of super-quadratic algorithms by a square-root factor. In our benchmarks with high-dimensional Monte Carlo samples and Markov chains targeting challenging differential equation posteriors, Compress++ matches or nearly matches the accuracy of its input algorithm in orders of magnitude less time.
Generalized Kernel Thinning
Oct 18, 2021
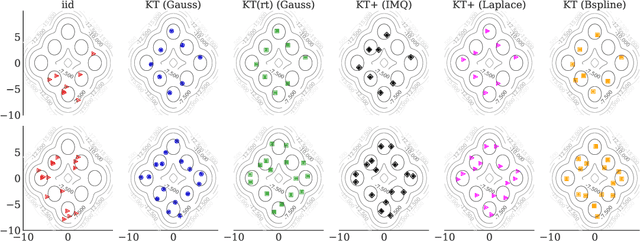

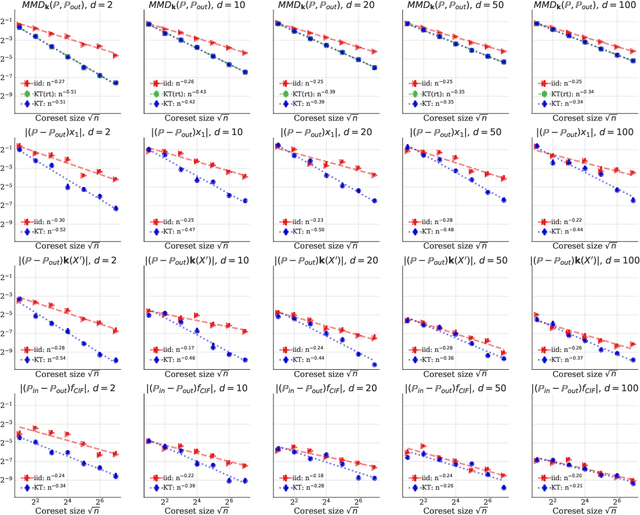
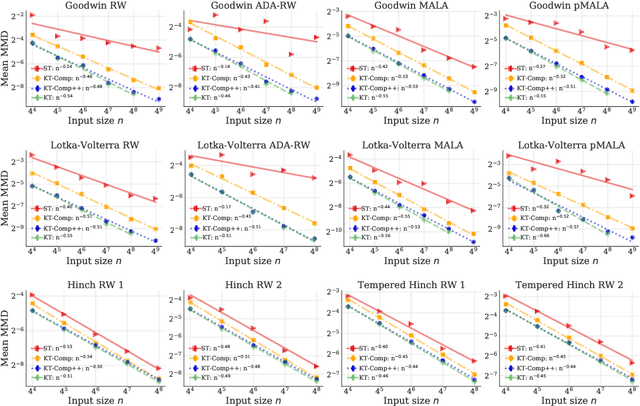
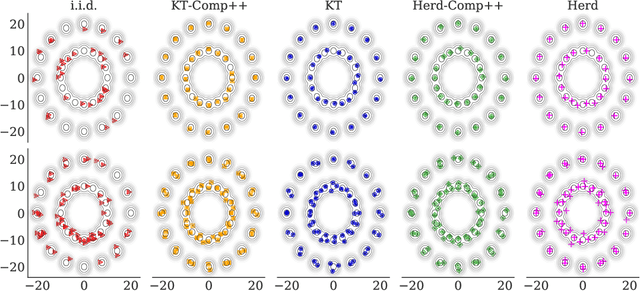
The kernel thinning (KT) algorithm of Dwivedi and Mackey (2021) compresses a probability distribution more effectively than independent sampling by targeting a reproducing kernel Hilbert space (RKHS) and leveraging a less smooth square-root kernel. Here we provide four improvements. First, we show that KT applied directly to the target RKHS yields tighter, dimension-free guarantees for any kernel, any distribution, and any fixed function in the RKHS. Second, we show that, for analytic kernels like Gaussian, inverse multiquadric, and sinc, target KT admits maximum mean discrepancy (MMD) guarantees comparable to or better than those of square-root KT without making explicit use of a square-root kernel. Third, we prove that KT with a fractional power kernel yields better-than-Monte-Carlo MMD guarantees for non-smooth kernels, like Laplace and Mat\'ern, that do not have square-roots. Fourth, we establish that KT applied to a sum of the target and power kernels (a procedure we call KT+) simultaneously inherits the improved MMD guarantees of power KT and the tighter individual function guarantees of target KT. In our experiments with target KT and KT+, we witness significant improvements in integration error even in $100$ dimensions and when compressing challenging differential equation posteriors.
Learned Benchmarks for Subseasonal Forecasting
Sep 21, 2021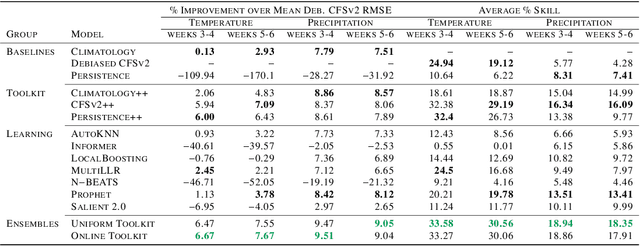
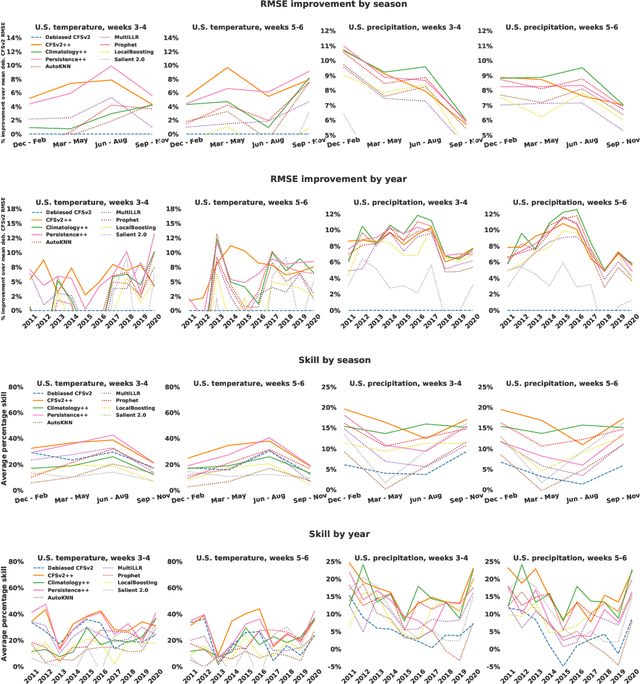
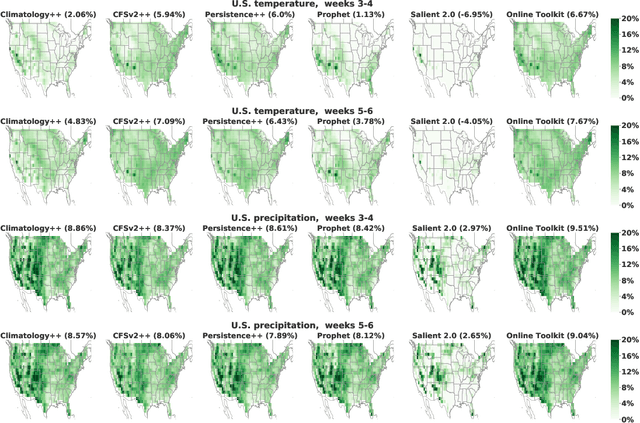
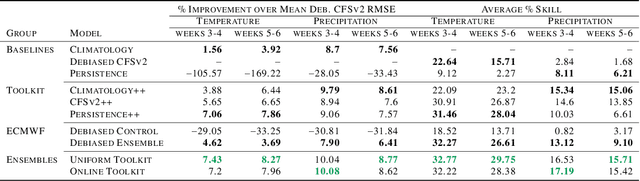
We develop a subseasonal forecasting toolkit of simple learned benchmark models that outperform both operational practice and state-of-the-art machine learning and deep learning methods. Our new models include (a) Climatology++, an adaptive alternative to climatology that, for precipitation, is 9% more accurate and 250% more skillful than the United States operational Climate Forecasting System (CFSv2); (b) CFSv2++, a learned CFSv2 correction that improves temperature and precipitation accuracy by 7-8% and skill by 50-275%; and (c) Persistence++, an augmented persistence model that combines CFSv2 forecasts with lagged measurements to improve temperature and precipitation accuracy by 6-9% and skill by 40-130%. Across the contiguous U.S., our Climatology++, CFSv2++, and Persistence++ toolkit consistently outperforms standard meteorological baselines, state-of-the-art machine and deep learning methods, and the European Centre for Medium-Range Weather Forecasts ensemble. Overall, we find that augmenting traditional forecasting approaches with learned enhancements yields an effective and computationally inexpensive strategy for building the next generation of subseasonal forecasting benchmarks.
Social Norm Bias: Residual Harms of Fairness-Aware Algorithms
Aug 29, 2021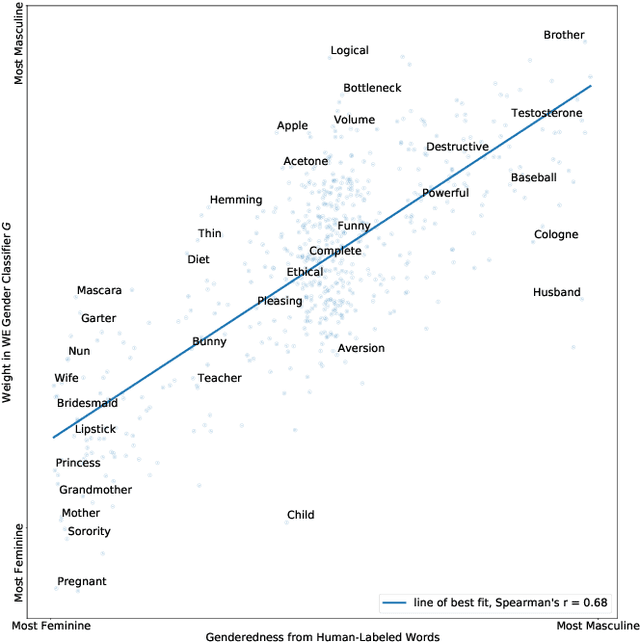
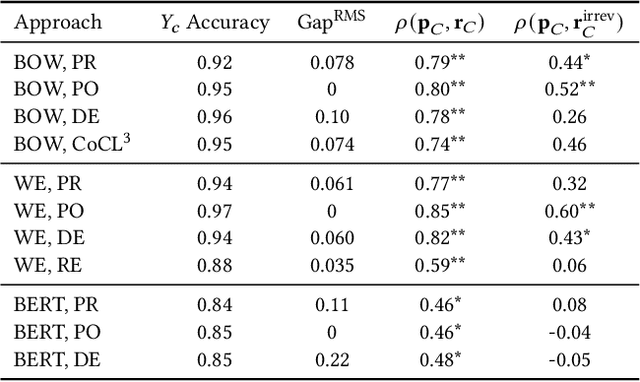
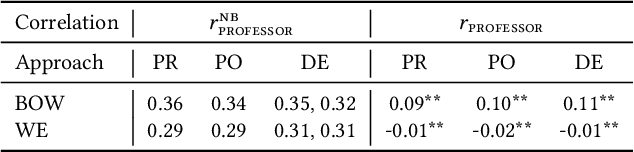
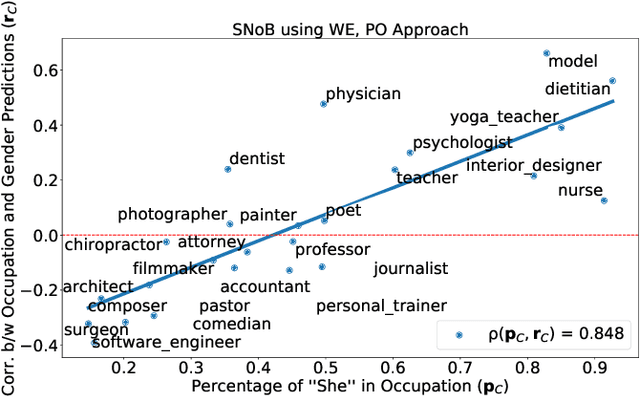
Many modern learning algorithms mitigate bias by enforcing fairness across coarsely-defined groups related to a sensitive attribute like gender or race. However, the same algorithms seldom account for the within-group biases that arise due to the heterogeneity of group members. In this work, we characterize Social Norm Bias (SNoB), a subtle but consequential type of discrimination that may be exhibited by automated decision-making systems, even when these systems achieve group fairness objectives. We study this issue through the lens of gender bias in occupation classification from biographies. We quantify SNoB by measuring how an algorithm's predictions are associated with conformity to gender norms, which is measured using a machine learning approach. This framework reveals that for classification tasks related to male-dominated occupations, fairness-aware classifiers favor biographies written in ways that align with masculine gender norms. We compare SNoB across fairness intervention techniques and show that post-processing interventions do not mitigate this type of bias at all.
Near-optimal inference in adaptive linear regression
Jul 14, 2021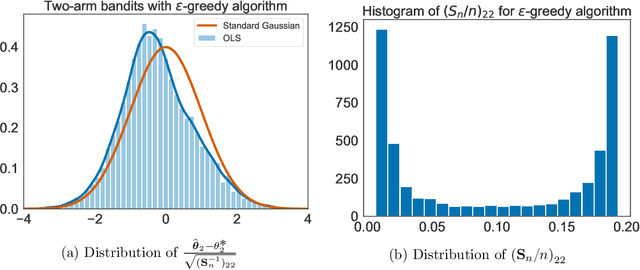
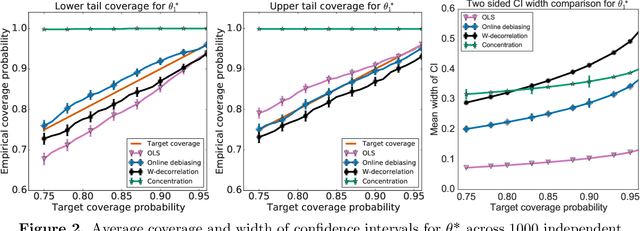
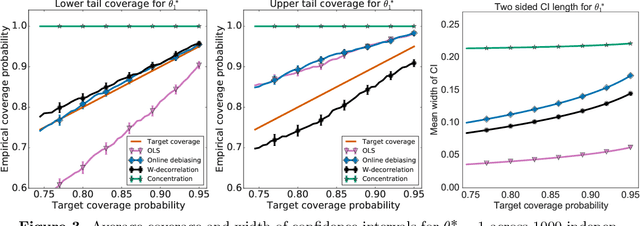
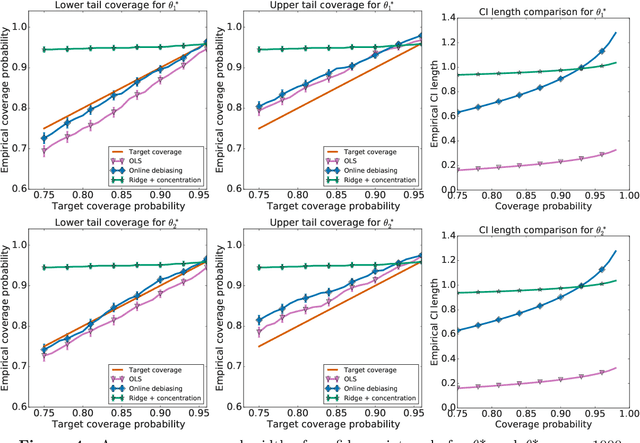
When data is collected in an adaptive manner, even simple methods like ordinary least squares can exhibit non-normal asymptotic behavior. As an undesirable consequence, hypothesis tests and confidence intervals based on asymptotic normality can lead to erroneous results. We propose an online debiasing estimator to correct these distributional anomalies in least squares estimation. Our proposed method takes advantage of the covariance structure present in the dataset and provides sharper estimates in directions for which more information has accrued. We establish an asymptotic normality property for our proposed online debiasing estimator under mild conditions on the data collection process, and provide asymptotically exact confidence intervals. We additionally prove a minimax lower bound for the adaptive linear regression problem, thereby providing a baseline by which to compare estimators. There are various conditions under which our proposed estimator achieves the minimax lower bound up to logarithmic factors. We demonstrate the usefulness of our theory via applications to multi-armed bandit, autoregressive time series estimation, and active learning with exploration.