 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAxDafny: Agentic Verified Code Generation in Dafny
Jun 30, 2026We study agentic code generation in Dafny, where a model must generate both executable code and the proof artifacts for verification. We present AxDafny, a verifier-guided repair framework that iteratively generates implementations, invariants, assertions, and termination arguments. We also introduce LiveCodeBench-Pro-Dafny (LCB-Pro-Dafny), a benchmark of 250 competition-style programming problems translated into Dafny with formal specifications and a verifier-based evaluation harness. On LCB-Pro-Dafny, AxDafny substantially improves verification success over baseline GPT-5.5 performance. On DafnyBench, AxDafny achieves 92.7\% verification success, outperforming the strongest previously reported proof-hint baseline by 6.5 percentage points. Lastly, we show that verification success and runtime test performance measure different aspects of generated code.
SorryDB: Can AI Provers Complete Real-World Lean Theorems?
Mar 03, 2026We present SorryDB, a dynamically-updating benchmark of open Lean tasks drawn from 78 real world formalization projects on GitHub. Unlike existing static benchmarks, often composed of competition problems, hillclimbing the SorryDB benchmark will yield tools that are aligned to the community needs, more usable by mathematicians, and more capable of understanding complex dependencies. Moreover, by providing a continuously updated stream of tasks, SorryDB mitigates test-set contamination and offers a robust metric for an agent's ability to contribute to novel formal mathematics projects. We evaluate a collection of approaches, including generalist large language models, agentic approaches, and specialized symbolic provers, over a selected snapshot of 1000 tasks from SorryDB. We show that current approaches are complementary: even though an agentic approach based on Gemini Flash is the most performant, it is not strictly better than other off-the-shelf large-language models, specialized provers, or even a curated list of Lean tactics.
A Minimal Agent for Automated Theorem Proving
Feb 27, 2026We propose a minimal agentic baseline that enables systematic comparison across different AI-based theorem prover architectures. This design implements the core features shared among state-of-the-art systems: iterative proof refinement, library search and context management. We evaluate our baseline using qualitatively different benchmarks and compare various popular models and design choices, and demonstrate competitive performance compared to state-of-the-art approaches, while using a significantly simpler architecture. Our results demonstrate consistent advantages of an iterative approach over multiple single-shot generations, especially in terms of sample efficiency and cost effectiveness. The implementation is released open-source as a candidate reference for future research and as an accessible prover for the community.
From Easy to Hard: Tackling Quantum Problems with Learned Gadgets For Real Hardware
Oct 31, 2024



Building quantum circuits that perform a given task is a notoriously difficult problem. Reinforcement learning has proven to be a powerful approach, but many limitations remain due to the exponential scaling of the space of possible operations on qubits. In this paper, we develop an algorithm that automatically learns composite gates ("$gadgets$") and adds them as additional actions to the reinforcement learning agent to facilitate the search, namely the Gadget Reinforcement Learning (GRL) algorithm. We apply our algorithm to finding parameterized quantum circuits (PQCs) that implement the ground state of a given quantum Hamiltonian, a well-known NP-hard challenge. In particular, we focus on the transverse field Ising model (TFIM), since understanding its ground state is crucial for studying quantum phase transitions and critical behavior, and serves as a benchmark for validating quantum algorithms and simulation techniques. We show that with GRL we can find very compact PQCs that improve the error in estimating the ground state of TFIM by up to $10^7$ fold and make it suitable for implementation on real hardware compared to a pure reinforcement learning approach. Moreover, GRL scales better with increasing difficulty and to larger systems. The generality of the algorithm shows the potential for applications to other settings, including optimization tailored to specific real-world quantum platforms.
Deep Bayesian Experimental Design for Quantum Many-Body Systems
Jun 26, 2023Bayesian experimental design is a technique that allows to efficiently select measurements to characterize a physical system by maximizing the expected information gain. Recent developments in deep neural networks and normalizing flows allow for a more efficient approximation of the posterior and thus the extension of this technique to complex high-dimensional situations. In this paper, we show how this approach holds promise for adaptive measurement strategies to characterize present-day quantum technology platforms. In particular, we focus on arrays of coupled cavities and qubit arrays. Both represent model systems of high relevance for modern applications, like quantum simulations and computing, and both have been realized in platforms where measurement and control can be exploited to characterize and counteract unavoidable disorder. Thus, they represent ideal targets for applications of Bayesian experimental design.
Unlocking the Power of Representations in Long-term Novelty-based Exploration
May 02, 2023



We introduce Robust Exploration via Clustering-based Online Density Estimation (RECODE), a non-parametric method for novelty-based exploration that estimates visitation counts for clusters of states based on their similarity in a chosen embedding space. By adapting classical clustering to the nonstationary setting of Deep RL, RECODE can efficiently track state visitation counts over thousands of episodes. We further propose a novel generalization of the inverse dynamics loss, which leverages masked transformer architectures for multi-step prediction; which in conjunction with RECODE achieves a new state-of-the-art in a suite of challenging 3D-exploration tasks in DM-Hard-8. RECODE also sets new state-of-the-art in hard exploration Atari games, and is the first agent to reach the end screen in "Pitfall!".
Renormalized Mutual Information for Artificial Scientific Discovery
Jun 04, 2020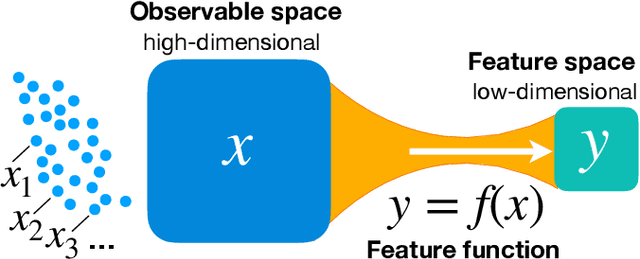
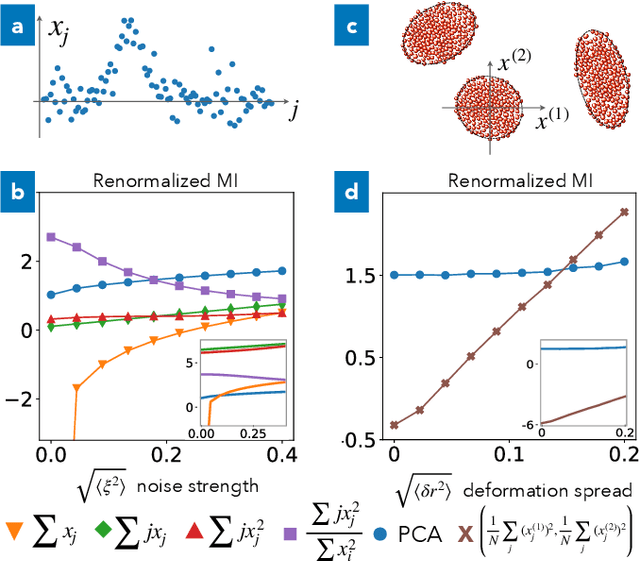
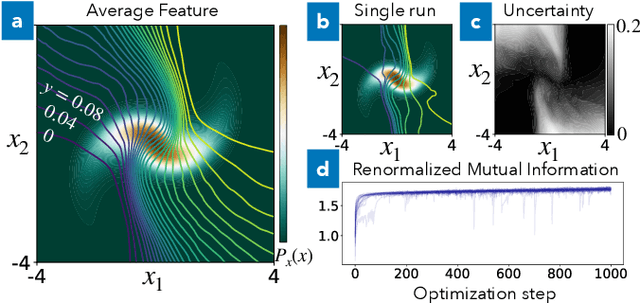
We derive a well-defined renormalized version of mutual information that allows to estimate the dependence between continuous random variables in the important case when one is deterministically dependent on the other. This is the situation relevant for feature extraction, where the goal is to produce a low-dimensional effective description of a high-dimensional system. Our approach enables the discovery of collective variables in physical systems, thus adding to the toolbox of artificial scientific discovery, while also aiding the analysis of information flow in artificial neural networks.