 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Zero to Hero: Advancing Zero-Shot Foundation Models for Tabular Outlier Detection
Feb 03, 2026Outlier detection (OD) is widely used in practice; but its effective deployment on new tasks is hindered by lack of labeled outliers, which makes algorithm and hyperparameter selection notoriously hard. Foundation models (FMs) have transformed ML, and OD is no exception: Shen et. al. (2025) introduced FoMo-0D, the first FM for OD, achieving remarkable performance against numerous baselines. This work introduces OUTFORMER, which advances FoMo-0D with (1) a mixture of synthetic priors and (2) self-evolving curriculum training. OUTFORMER is pretrained solely on synthetic labeled datasets and infers test labels of a new task by using its training data as in-context input. Inference is fast and zero-shot, requiring merely forward pass and no labeled outliers. Thanks to in-context learning, it requires zero additional work-no OD model training or bespoke model selection-enabling truly plug-and-play deployment. OUTFORMER achieves state-of-the-art performance on the prominent AdBench, as well as two new large-scale OD benchmarks that we introduce, comprising over 1,500 datasets, while maintaining speedy inference.
Hierarchical Token Prepending: Enhancing Information Flow in Decoder-based LLM Embeddings
Nov 18, 2025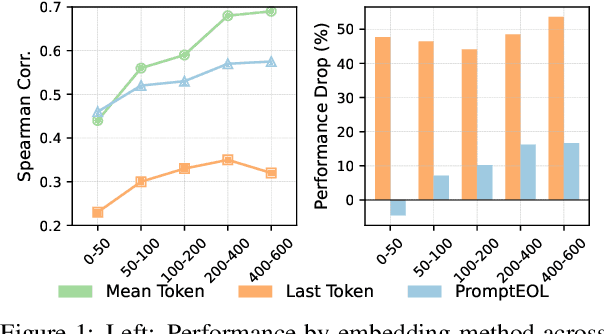
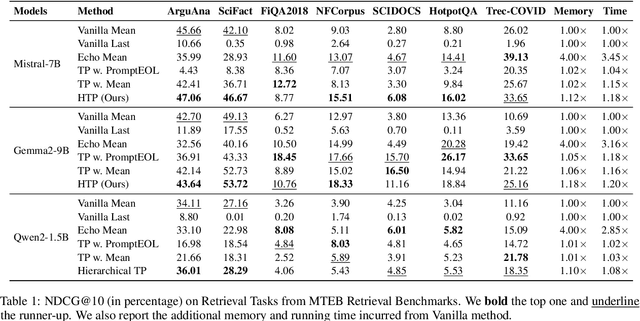
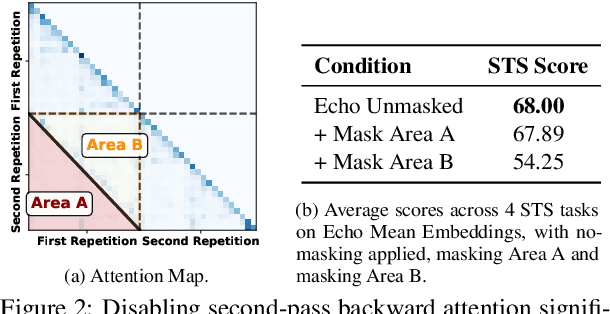
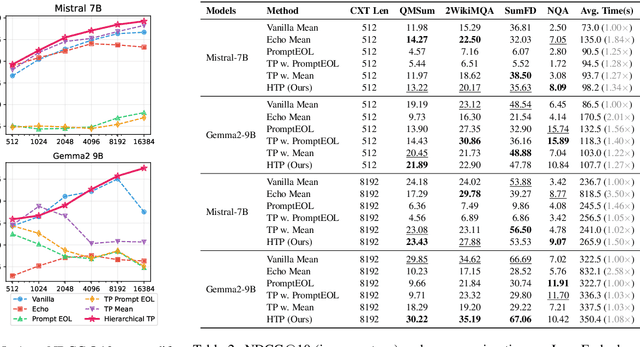
Large language models produce powerful text embeddings, but their causal attention mechanism restricts the flow of information from later to earlier tokens, degrading representation quality. While recent methods attempt to solve this by prepending a single summary token, they over-compress information, hence harming performance on long documents. We propose Hierarchical Token Prepending (HTP), a method that resolves two critical bottlenecks. To mitigate attention-level compression, HTP partitions the input into blocks and prepends block-level summary tokens to subsequent blocks, creating multiple pathways for backward information flow. To address readout-level over-squashing, we replace last-token pooling with mean-pooling, a choice supported by theoretical analysis. HTP achieves consistent performance gains across 11 retrieval datasets and 30 general embedding benchmarks, especially in long-context settings. As a simple, architecture-agnostic method, HTP enhances both zero-shot and finetuned models, offering a scalable route to superior long-document embeddings.
Uncertainty-aware Human Mobility Modeling and Anomaly Detection
Oct 02, 2024Given the GPS coordinates of a large collection of human agents over time, how can we model their mobility behavior toward effective anomaly detection (e.g. for bad-actor or malicious behavior detection) without any labeled data? Human mobility and trajectory modeling have been studied extensively with varying capacity to handle complex input, and performance-efficiency trade-offs. With the arrival of more expressive models in machine learning, we attempt to model GPS data as a sequence of stay-point events, each with a set of characterizing spatiotemporal features, and leverage modern sequence models such as Transformers for un/self-supervised training and inference. Notably, driven by the inherent stochasticity of certain individuals' behavior, we equip our model with aleatoric/data uncertainty estimation. In addition, to handle data sparsity of a large variety of behaviors, we incorporate epistemic/model uncertainty into our model. Together, aleatoric and epistemic uncertainty enable a robust loss and training dynamics, as well as uncertainty-aware decision making in anomaly scoring. Experiments on large expert-simulated datasets with tens of thousands of agents demonstrate the effectiveness of our model against both forecasting and anomaly detection baselines.
Zero-shot Outlier Detection via Prior-data Fitted Networks: Model Selection Bygone!
Sep 09, 2024Outlier detection (OD) has a vast literature as it finds numerous applications in environmental monitoring, cybersecurity, finance, and medicine to name a few. Being an inherently unsupervised task, model selection is a key bottleneck for OD (both algorithm and hyperparameter selection) without label supervision. There is a long list of techniques to choose from -- both classical algorithms and deep neural architectures -- and while several studies report their hyperparameter sensitivity, the literature is quite slim on unsupervised model selection -- limiting the effective use of OD in practice. In this paper we present FoMo-0D, for zero/0-shot OD exploring a transformative new direction that bypasses the hurdle of model selection altogether (!), thus breaking new ground. The fundamental idea behind FoMo-0D is the Prior-data Fitted Networks, recently introduced by Muller et al.(2022), which trains a Transformer model on a large body of synthetically generated data from a prior data distribution. In essence, FoMo-0D is a pretrained Foundation Model for zero/0-shot OD on tabular data, which can directly predict the (outlier/inlier) label of any test data at inference time, by merely a single forward pass -- making obsolete the need for choosing an algorithm/architecture, tuning its associated hyperparameters, and even training any model parameters when given a new OD dataset. Extensive experiments on 57 public benchmark datasets against 26 baseline methods show that FoMo-0D performs statistically no different from the top 2nd baseline, while significantly outperforming the majority of the baselines, with an average inference time of 7.7 ms per test sample.
Outlier Detection Bias Busted: Understanding Sources of Algorithmic Bias through Data-centric Factors
Aug 24, 2024



The astonishing successes of ML have raised growing concern for the fairness of modern methods when deployed in real world settings. However, studies on fairness have mostly focused on supervised ML, while unsupervised outlier detection (OD), with numerous applications in finance, security, etc., have attracted little attention. While a few studies proposed fairness-enhanced OD algorithms, they remain agnostic to the underlying driving mechanisms or sources of unfairness. Even within the supervised ML literature, there exists debate on whether unfairness stems solely from algorithmic biases (i.e. design choices) or from the biases encoded in the data on which they are trained. To close this gap, this work aims to shed light on the possible sources of unfairness in OD by auditing detection models under different data-centric factors. By injecting various known biases into the input data -- as pertain to sample size disparity, under-representation, feature measurement noise, and group membership obfuscation -- we find that the OD algorithms under the study all exhibit fairness pitfalls, although differing in which types of data bias they are more susceptible to. Most notable of our study is to demonstrate that OD algorithm bias is not merely a data bias problem. A key realization is that the data properties that emerge from bias injection could as well be organic -- as pertain to natural group differences w.r.t. sparsity, base rate, variance, and multi-modality. Either natural or biased, such data properties can give rise to unfairness as they interact with certain algorithmic design choices.
End-To-End Self-tuning Self-supervised Time Series Anomaly Detection
Apr 03, 2024



Time series anomaly detection (TSAD) finds many applications such as monitoring environmental sensors, industry KPIs, patient biomarkers, etc. A two-fold challenge for TSAD is a versatile and unsupervised model that can detect various different types of time series anomalies (spikes, discontinuities, trend shifts, etc.) without any labeled data. Modern neural networks have outstanding ability in modeling complex time series. Self-supervised models in particular tackle unsupervised TSAD by transforming the input via various augmentations to create pseudo anomalies for training. However, their performance is sensitive to the choice of augmentation, which is hard to choose in practice, while there exists no effort in the literature on data augmentation tuning for TSAD without labels. Our work aims to fill this gap. We introduce TSAP for TSA "on autoPilot", which can (self-)tune augmentation hyperparameters end-to-end. It stands on two key components: a differentiable augmentation architecture and an unsupervised validation loss to effectively assess the alignment between augmentation type and anomaly type. Case studies show TSAP's ability to effectively select the (discrete) augmentation type and associated (continuous) hyperparameters. In turn, it outperforms established baselines, including SOTA self-supervised models, on diverse TSAD tasks exhibiting different anomaly types.
On the Detection of Reviewer-Author Collusion Rings From Paper Bidding
Feb 12, 2024A major threat to the peer-review systems of computer science conferences is the existence of "collusion rings" between reviewers. In such collusion rings, reviewers who have also submitted their own papers to the conference work together to manipulate the conference's paper assignment, with the aim of being assigned to review each other's papers. The most straightforward way that colluding reviewers can manipulate the paper assignment is by indicating their interest in each other's papers through strategic paper bidding. One potential approach to solve this important problem would be to detect the colluding reviewers from their manipulated bids, after which the conference can take appropriate action. While prior work has has developed effective techniques to detect other kinds of fraud, no research has yet established that detecting collusion rings is even possible. In this work, we tackle the question of whether it is feasible to detect collusion rings from the paper bidding. To answer this question, we conduct empirical analysis of two realistic conference bidding datasets, including evaluations of existing algorithms for fraud detection in other applications. We find that collusion rings can achieve considerable success at manipulating the paper assignment while remaining hidden from detection: for example, in one dataset, undetected colluders are able to achieve assignment to up to 30% of the papers authored by other colluders. In addition, when 10 colluders bid on all of each other's papers, no detection algorithm outputs a group of reviewers with more than 31% overlap with the true colluders. These results suggest that collusion cannot be effectively detected from the bidding, demonstrating the need to develop more complex detection algorithms that leverage additional metadata.
Descriptive Kernel Convolution Network with Improved Random Walk Kernel
Feb 08, 2024



Graph kernels used to be the dominant approach to feature engineering for structured data, which are superseded by modern GNNs as the former lacks learnability. Recently, a suite of Kernel Convolution Networks (KCNs) successfully revitalized graph kernels by introducing learnability, which convolves input with learnable hidden graphs using a certain graph kernel. The random walk kernel (RWK) has been used as the default kernel in many KCNs, gaining increasing attention. In this paper, we first revisit the RWK and its current usage in KCNs, revealing several shortcomings of the existing designs, and propose an improved graph kernel RWK+, by introducing color-matching random walks and deriving its efficient computation. We then propose RWK+CN, a KCN that uses RWK+ as the core kernel to learn descriptive graph features with an unsupervised objective, which can not be achieved by GNNs. Further, by unrolling RWK+, we discover its connection with a regular GCN layer, and propose a novel GNN layer RWK+Conv. In the first part of experiments, we demonstrate the descriptive learning ability of RWK+CN with the improved random walk kernel RWK+ on unsupervised pattern mining tasks; in the second part, we show the effectiveness of RWK+ for a variety of KCN architectures and supervised graph learning tasks, and demonstrate the expressiveness of RWK+Conv layer, especially on the graph-level tasks. RWK+ and RWK+Conv adapt to various real-world applications, including web applications such as bot detection in a web-scale Twitter social network, and community classification in Reddit social interaction networks.
Pard: Permutation-Invariant Autoregressive Diffusion for Graph Generation
Feb 06, 2024



Graph generation has been dominated by autoregressive models due to their simplicity and effectiveness, despite their sensitivity to ordering. Yet diffusion models have garnered increasing attention, as they offer comparable performance while being permutation-invariant. Current graph diffusion models generate graphs in a one-shot fashion, but they require extra features and thousands of denoising steps to achieve optimal performance. We introduce PARD, a Permutation-invariant Auto Regressive Diffusion model that integrates diffusion models with autoregressive methods. PARD harnesses the effectiveness and efficiency of the autoregressive model while maintaining permutation invariance without ordering sensitivity. Specifically, we show that contrary to sets, elements in a graph are not entirely unordered and there is a unique partial order for nodes and edges. With this partial order, PARD generates a graph in a block-by-block, autoregressive fashion, where each block's probability is conditionally modeled by a shared diffusion model with an equivariant network. To ensure efficiency while being expressive, we further propose a higher-order graph transformer, which integrates transformer with PPGN. Like GPT, we extend the higher-order graph transformer to support parallel training of all blocks. Without any extra features, PARD achieves state-of-the-art performance on molecular and non-molecular datasets, and scales to large datasets like MOSES containing 1.9M molecules.
Improving and Unifying Discrete&Continuous-time Discrete Denoising Diffusion
Feb 06, 2024



Discrete diffusion models have seen a surge of attention with applications on naturally discrete data such as language and graphs. Although discrete-time discrete diffusion has been established for a while, only recently Campbell et al. (2022) introduced the first framework for continuous-time discrete diffusion. However, their training and sampling processes differ significantly from the discrete-time version, necessitating nontrivial approximations for tractability. In this paper, we first present a series of mathematical simplifications of the variational lower bound that enable more accurate and easy-to-optimize training for discrete diffusion. In addition, we derive a simple formulation for backward denoising that enables exact and accelerated sampling, and importantly, an elegant unification of discrete-time and continuous-time discrete diffusion. Thanks to simpler analytical formulations, both forward and now also backward probabilities can flexibly accommodate any noise distribution, including different noise distributions for multi-element objects. Experiments show that our proposed USD3 (for Unified Simplified Discrete Denoising Diffusion) outperform all SOTA baselines on established datasets. We open-source our unified code at https://github.com/LingxiaoShawn/USD3.