 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Pre-Training for Plug-and-Play Task-Oriented Dialogue System
Sep 29, 2021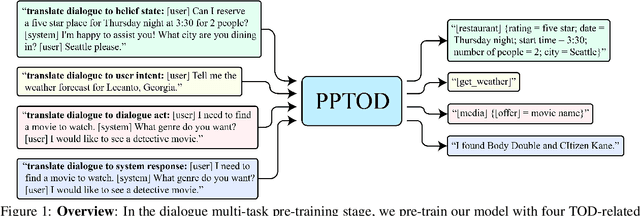
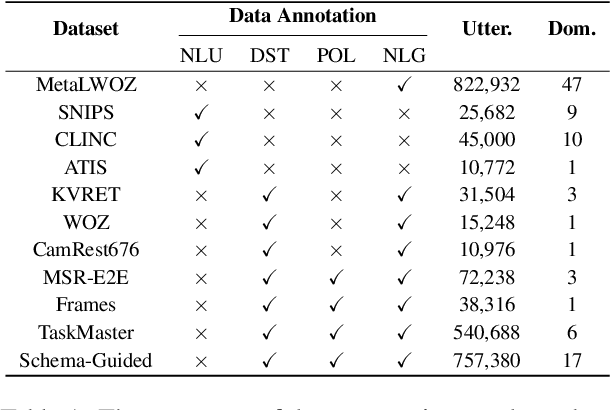
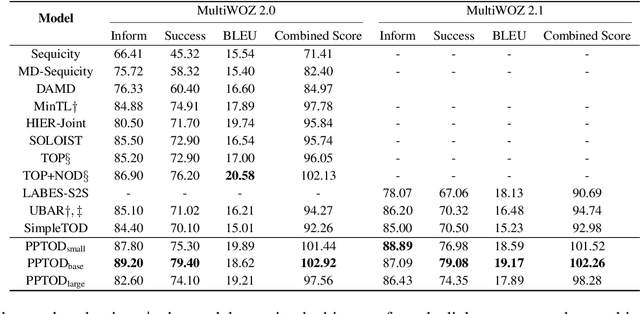
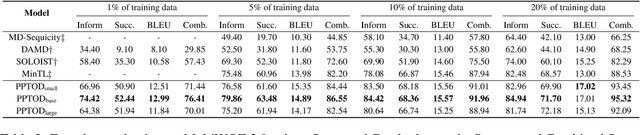
Pre-trained language models have been recently shown to benefit task-oriented dialogue (TOD) systems. Despite their success, existing methods often formulate this task as a cascaded generation problem which can lead to error accumulation across different sub-tasks and greater data annotation overhead. In this study, we present PPTOD, a unified plug-and-play model for task-oriented dialogue. In addition, we introduce a new dialogue multi-task pre-training strategy that allows the model to learn the primary TOD task completion skills from heterogeneous dialog corpora. We extensively test our model on three benchmark TOD tasks, including end-to-end dialogue modelling, dialogue state tracking, and intent classification. Experimental results show that PPTOD achieves new state of the art on all evaluated tasks in both high-resource and low-resource scenarios. Furthermore, comparisons against previous SOTA methods show that the responses generated by PPTOD are more factually correct and semantically coherent as judged by human annotators.
Zero-Shot Open Set Detection by Extending CLIP
Sep 10, 2021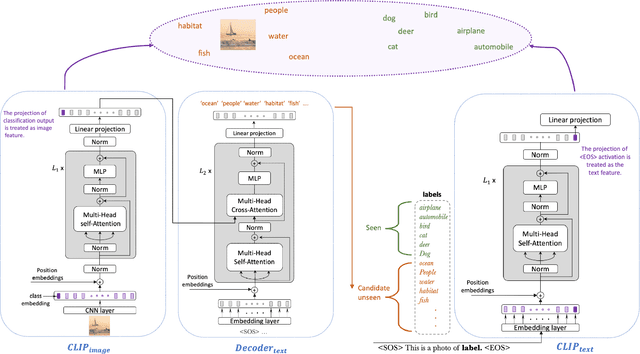
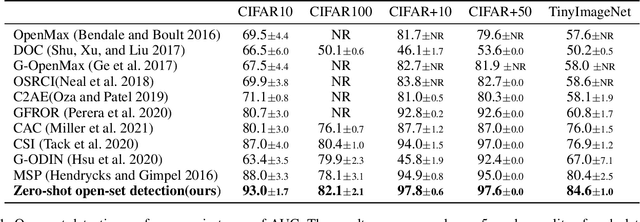
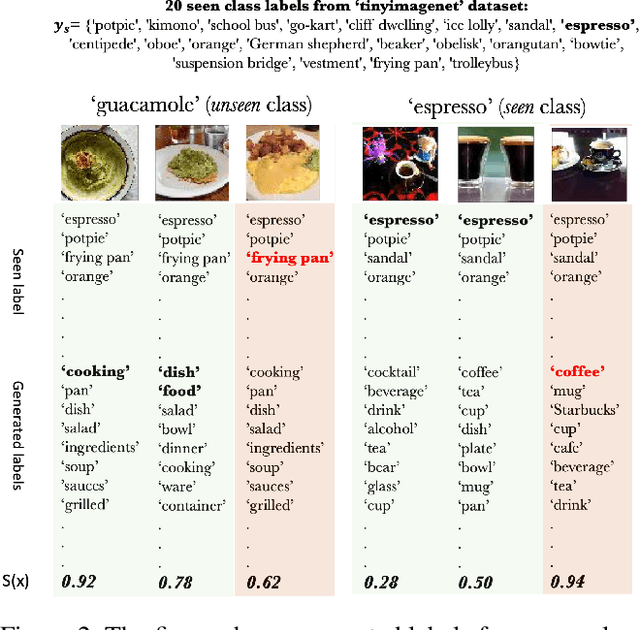
In a regular open set detection problem, samples of known classes (also called closed set classes) are used to train a special classifier. In testing, the classifier can (1) classify the test samples of known classes to their respective classes and (2) also detect samples that do not belong to any of the known classes (we say they belong to some unknown or open set classes). This paper studies the problem of zero-shot open-set detection, which still performs the same two tasks in testing but has no training except using the given known class names. This paper proposes a novel and yet simple method (called ZO-CLIP) to solve the problem. ZO-CLIP builds on top of the recent advances in zero-shot classification through multi-modal representation learning. It first extends the pre-trained multi-modal model CLIP by training a text-based image description generator on top of CLIP. In testing, it uses the extended model to generate some candidate unknown class names for each test sample and computes a confidence score based on both the known class names and candidate unknown class names for zero-shot open set detection. Experimental results on 5 benchmark datasets for open set detection confirm that ZO-CLIP outperforms the baselines by a large margin.
Understanding Pre-trained BERT for Aspect-based Sentiment Analysis
Oct 31, 2020


This paper analyzes the pre-trained hidden representations learned from reviews on BERT for tasks in aspect-based sentiment analysis (ABSA). Our work is motivated by the recent progress in BERT-based language models for ABSA. However, it is not clear how the general proxy task of (masked) language model trained on unlabeled corpus without annotations of aspects or opinions can provide important features for downstream tasks in ABSA. By leveraging the annotated datasets in ABSA, we investigate both the attentions and the learned representations of BERT pre-trained on reviews. We found that BERT uses very few self-attention heads to encode context words (such as prepositions or pronouns that indicating an aspect) and opinion words for an aspect. Most features in the representation of an aspect are dedicated to the fine-grained semantics of the domain (or product category) and the aspect itself, instead of carrying summarized opinions from its context. We hope this investigation can help future research in improving self-supervised learning, unsupervised learning and fine-tuning for ABSA. The pre-trained model and code can be found at https://github.com/howardhsu/BERT-for-RRC-ABSA.
Controllable Text Generation with Focused Variation
Sep 25, 2020
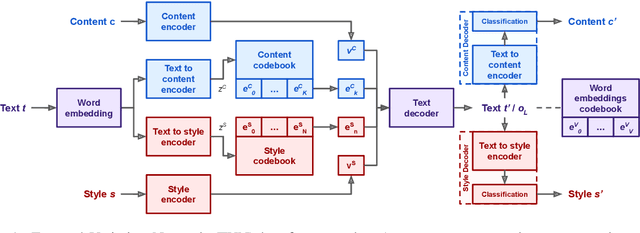
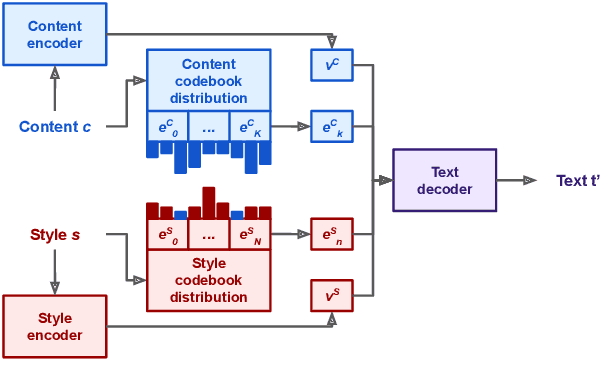
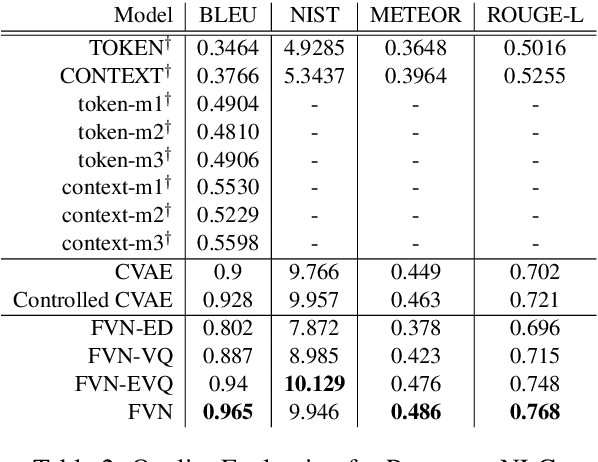
This work introduces Focused-Variation Network (FVN), a novel model to control language generation. The main problems in previous controlled language generation models range from the difficulty of generating text according to the given attributes, to the lack of diversity of the generated texts. FVN addresses these issues by learning disjoint discrete latent spaces for each attribute inside codebooks, which allows for both controllability and diversity, while at the same time generating fluent text. We evaluate FVN on two text generation datasets with annotated content and style, and show state-of-the-art performance as assessed by automatic and human evaluations.
DomBERT: Domain-oriented Language Model for Aspect-based Sentiment Analysis
Apr 28, 2020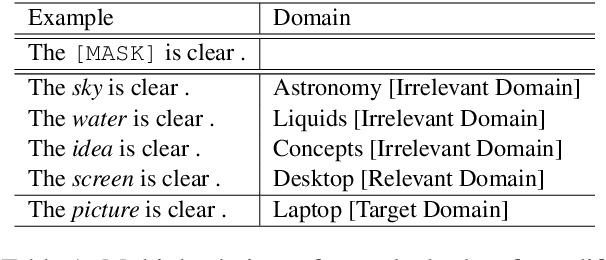
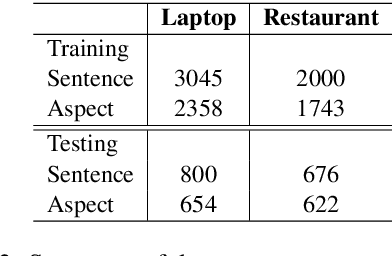
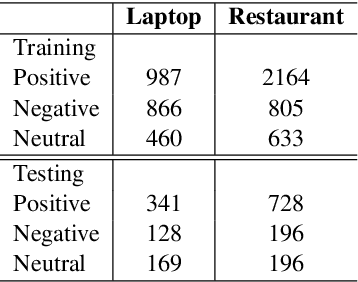
This paper focuses on learning domain-oriented language models driven by end tasks, which aims to combine the worlds of both general-purpose language models (such as ELMo and BERT) and domain-specific language understanding. We propose DomBERT, an extension of BERT to learn from both in-domain corpus and relevant domain corpora. This helps in learning domain language models with low-resources. Experiments are conducted on an assortment of tasks in aspect-based sentiment analysis, demonstrating promising results.
A Failure of Aspect Sentiment Classifiers and an Adaptive Re-weighting Solution
Nov 04, 2019
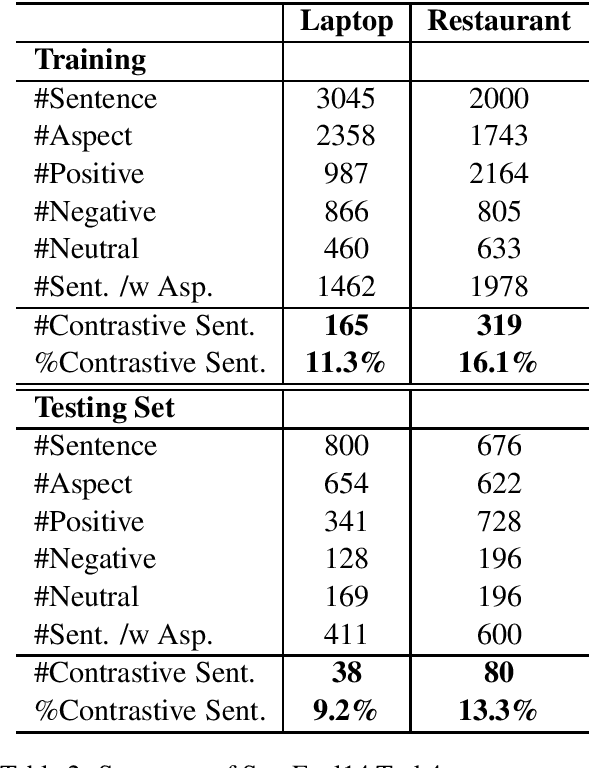
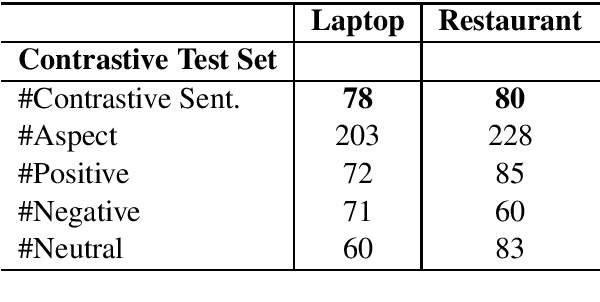
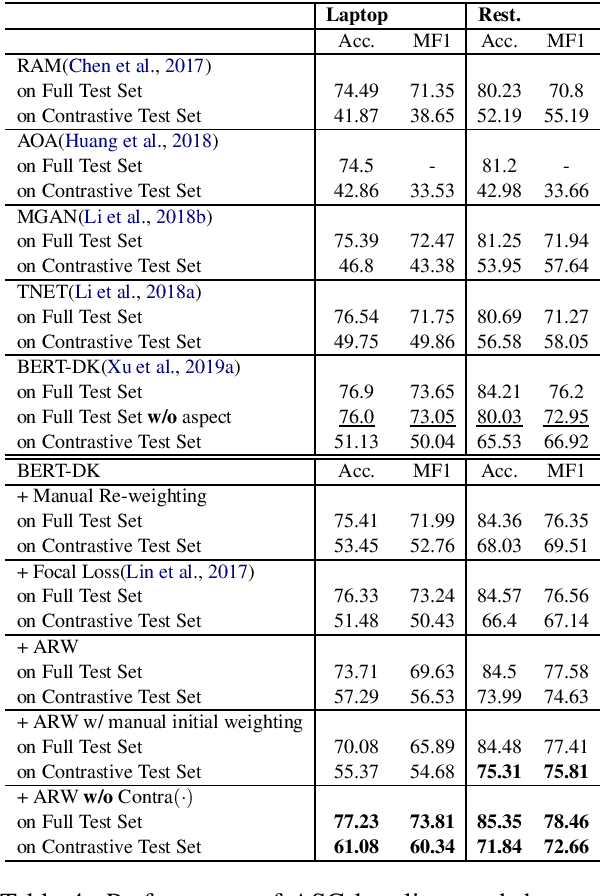
Aspect-based sentiment classification (ASC) is an important task in fine-grained sentiment analysis.~Deep supervised ASC approaches typically model this task as a pair-wise classification task that takes an aspect and a sentence containing the aspect and outputs the polarity of the aspect in that sentence. However, we discovered that many existing approaches fail to learn an effective ASC classifier but more like a sentence-level sentiment classifier because they have difficulty to handle sentences with different polarities for different aspects.~This paper first demonstrates this problem using several state-of-the-art ASC models. It then proposes a novel and general adaptive re-weighting (ARW) scheme to adjust the training to dramatically improve ASC for such complex sentences. Experimental results show that the proposed framework is effective \footnote{The dataset and code are available at \url{https://github.com/howardhsu/ASC_failure}.}.
Modeling Multi-Action Policy for Task-Oriented Dialogues
Aug 30, 2019
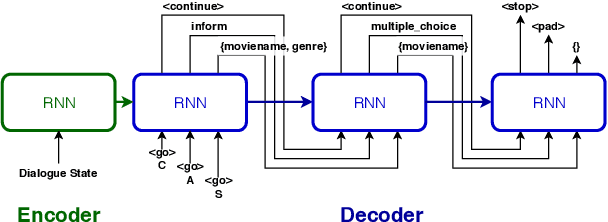
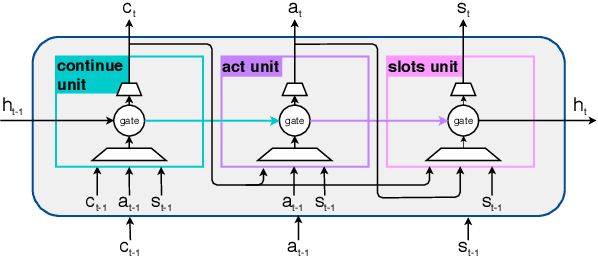

Dialogue management (DM) plays a key role in the quality of the interaction with the user in a task-oriented dialogue system. In most existing approaches, the agent predicts only one DM policy action per turn. This significantly limits the expressive power of the conversational agent and introduces unwanted turns of interactions that may challenge users' patience. Longer conversations also lead to more errors and the system needs to be more robust to handle them. In this paper, we compare the performance of several models on the task of predicting multiple acts for each turn. A novel policy model is proposed based on a recurrent cell called gated Continue-Act-Slots (gCAS) that overcomes the limitations of the existing models. Experimental results show that gCAS outperforms other approaches. The code is available at https://leishu02.github.io/
Flexibly-Structured Model for Task-Oriented Dialogues
Aug 06, 2019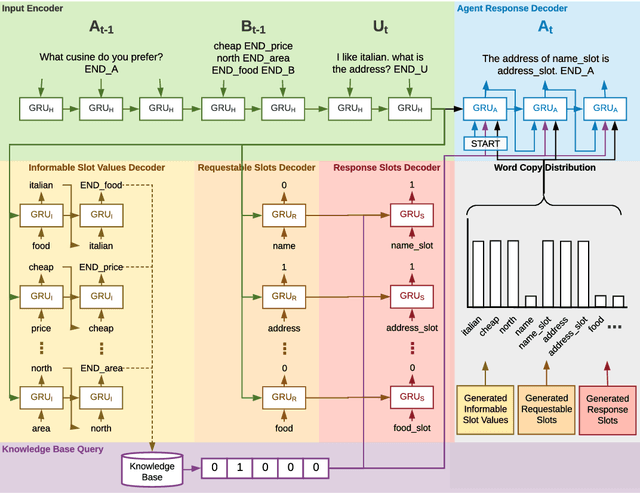
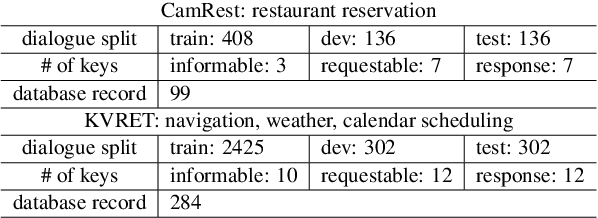

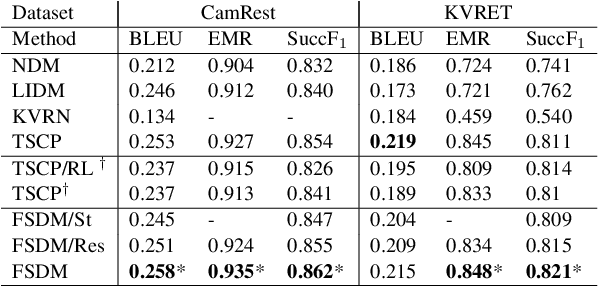
This paper proposes a novel end-to-end architecture for task-oriented dialogue systems. It is based on a simple and practical yet very effective sequence-to-sequence approach, where language understanding and state tracking tasks are modeled jointly with a structured copy-augmented sequential decoder and a multi-label decoder for each slot. The policy engine and language generation tasks are modeled jointly following that. The copy-augmented sequential decoder deals with new or unknown values in the conversation, while the multi-label decoder combined with the sequential decoder ensures the explicit assignment of values to slots. On the generation part, slot binary classifiers are used to improve performance. This architecture is scalable to real-world scenarios and is shown through an empirical evaluation to achieve state-of-the-art performance on both the Cambridge Restaurant dataset and the Stanford in-car assistant dataset\footnote{The code is available at \url{https://github.com/uber-research/FSDM}}
Controlled CNN-based Sequence Labeling for Aspect Extraction
May 29, 2019
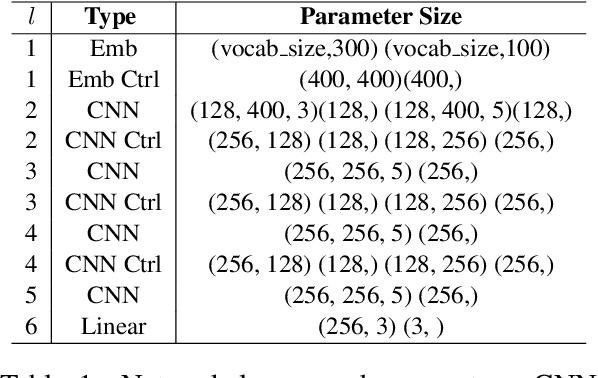
One key task of fine-grained sentiment analysis on reviews is to extract aspects or features that users have expressed opinions on. This paper focuses on supervised aspect extraction using a modified CNN called controlled CNN (Ctrl). The modified CNN has two types of control modules. Through asynchronous parameter updating, it prevents over-fitting and boosts CNN's performance significantly. This model achieves state-of-the-art results on standard aspect extraction datasets. To the best of our knowledge, this is the first paper to apply control modules to aspect extraction.
BERT Post-Training for Review Reading Comprehension and Aspect-based Sentiment Analysis
May 04, 2019
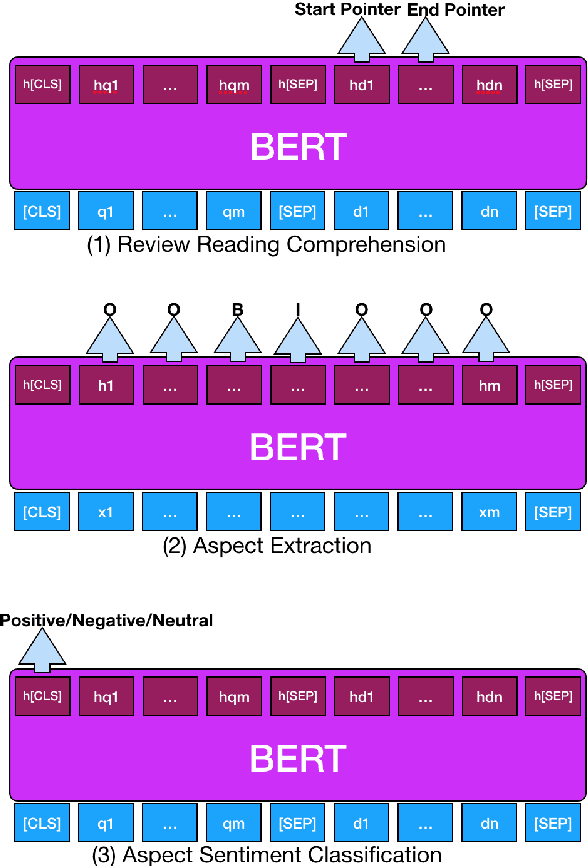
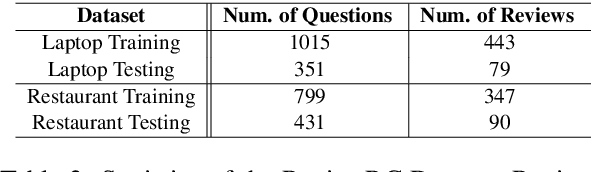
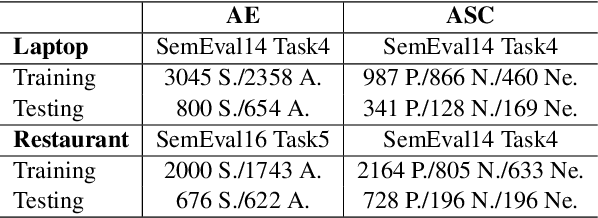
Question-answering plays an important role in e-commerce as it allows potential customers to actively seek crucial information about products or services to help their purchase decision making. Inspired by the recent success of machine reading comprehension (MRC) on formal documents, this paper explores the potential of turning customer reviews into a large source of knowledge that can be exploited to answer user questions.~We call this problem Review Reading Comprehension (RRC). To the best of our knowledge, no existing work has been done on RRC. In this work, we first build an RRC dataset called ReviewRC based on a popular benchmark for aspect-based sentiment analysis. Since ReviewRC has limited training examples for RRC (and also for aspect-based sentiment analysis), we then explore a novel post-training approach on the popular language model BERT to enhance the performance of fine-tuning of BERT for RRC. To show the generality of the approach, the proposed post-training is also applied to some other review-based tasks such as aspect extraction and aspect sentiment classification in aspect-based sentiment analysis. Experimental results demonstrate that the proposed post-training is highly effective. The datasets and code are available at https://www.cs.uic.edu/~hxu/.