 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-temporal Tendency Reasoning for Human Body Pose and Shape Estimation from Videos
Oct 10, 2022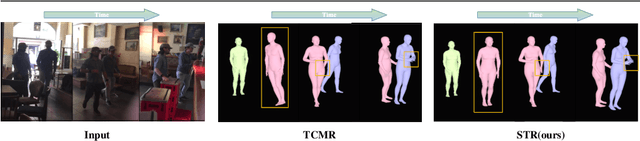
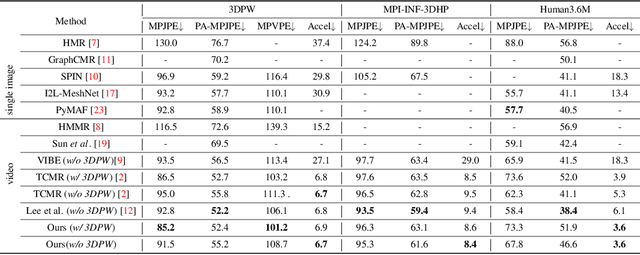
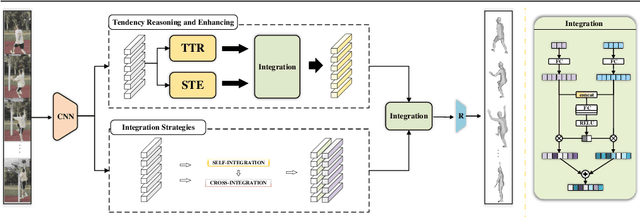
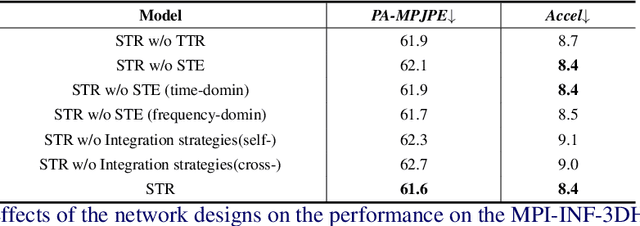
In this paper, we present a spatio-temporal tendency reasoning (STR) network for recovering human body pose and shape from videos. Previous approaches have focused on how to extend 3D human datasets and temporal-based learning to promote accuracy and temporal smoothing. Different from them, our STR aims to learn accurate and natural motion sequences in an unconstrained environment through temporal and spatial tendency and to fully excavate the spatio-temporal features of existing video data. To this end, our STR learns the representation of features in the temporal and spatial dimensions respectively, to concentrate on a more robust representation of spatio-temporal features. More specifically, for efficient temporal modeling, we first propose a temporal tendency reasoning (TTR) module. TTR constructs a time-dimensional hierarchical residual connection representation within a video sequence to effectively reason temporal sequences' tendencies and retain effective dissemination of human information. Meanwhile, for enhancing the spatial representation, we design a spatial tendency enhancing (STE) module to further learns to excite spatially time-frequency domain sensitive features in human motion information representations. Finally, we introduce integration strategies to integrate and refine the spatio-temporal feature representations. Extensive experimental findings on large-scale publically available datasets reveal that our STR remains competitive with the state-of-the-art on three datasets. Our code are available at https://github.com/Changboyang/STR.git.
Network-wide Multi-step Traffic Volume Prediction using Graph Convolutional Gated Recurrent Neural Network
Nov 22, 2021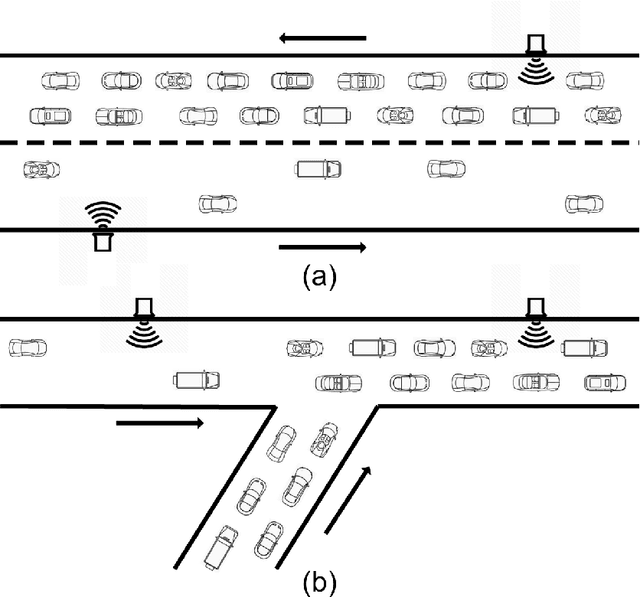
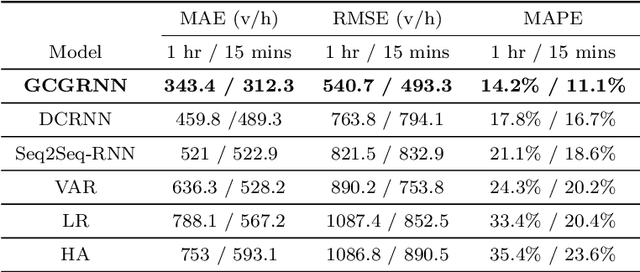
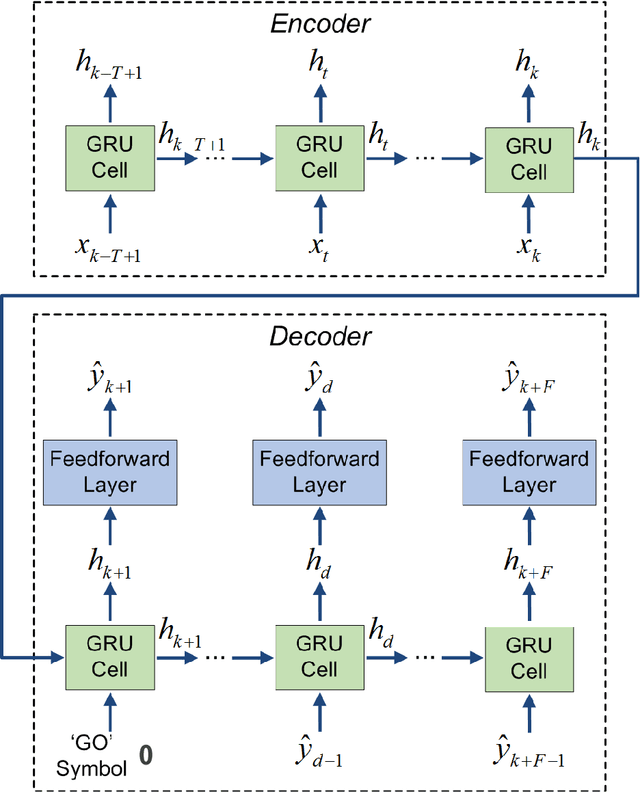
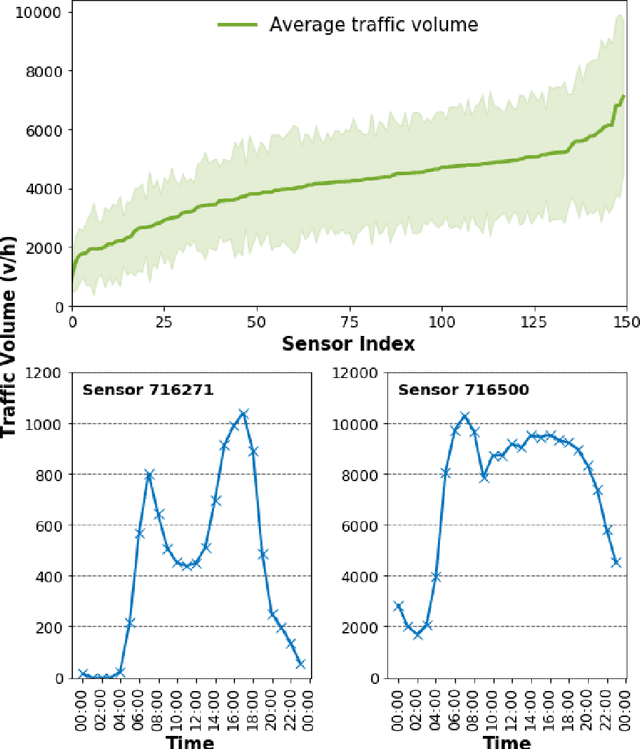
Accurate prediction of network-wide traffic conditions is essential for intelligent transportation systems. In the last decade, machine learning techniques have been widely used for this task, resulting in state-of-the-art performance. We propose a novel deep learning model, Graph Convolutional Gated Recurrent Neural Network (GCGRNN), to predict network-wide, multi-step traffic volume. GCGRNN can automatically capture spatial correlations between traffic sensors and temporal dependencies in historical traffic data. We have evaluated our model using two traffic datasets extracted from 150 sensors in Los Angeles, California, at the time resolutions one hour and 15 minutes, respectively. The results show that our model outperforms the other five benchmark models in terms of prediction accuracy. For instance, our model reduces MAE by 25.3%, RMSE by 29.2%, and MAPE by 20.2%, compared to the state-of-the-art Diffusion Convolutional Recurrent Neural Network (DCRNN) model using the hourly dataset. Our model also achieves faster training than DCRNN by up to 52%. The data and implementation of GCGRNN can be found at https://github.com/leilin-research/GCGRNN.
Trend and Thoughts: Understanding Climate Change Concern using Machine Learning and Social Media Data
Nov 06, 2021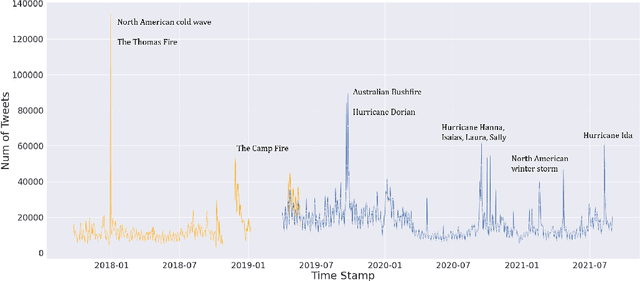
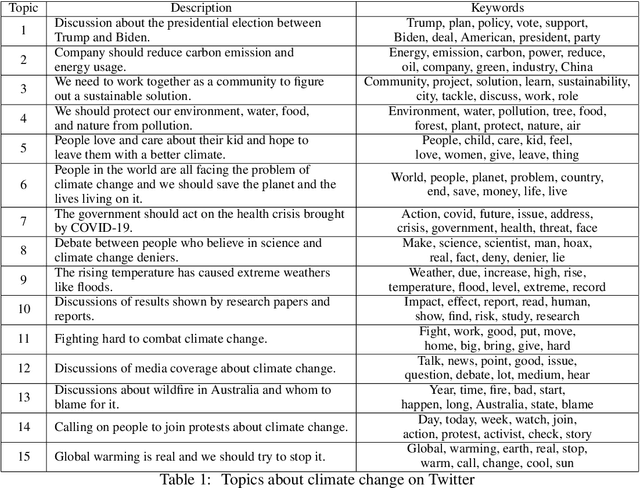
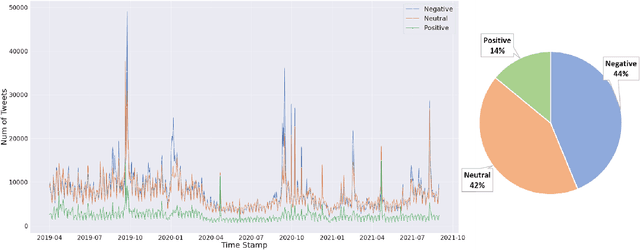
Nowadays social media platforms such as Twitter provide a great opportunity to understand public opinion of climate change compared to traditional survey methods. In this paper, we constructed a massive climate change Twitter dataset and conducted comprehensive analysis using machine learning. By conducting topic modeling and natural language processing, we show the relationship between the number of tweets about climate change and major climate events; the common topics people discuss climate change; and the trend of sentiment. Our dataset was published on Kaggle (\url{https://www.kaggle.com/leonshangguan/climate-change-tweets-ids-until-aug-2021}) and can be used in further research.
Robust Ensembling Network for Unsupervised Domain Adaptation
Aug 21, 2021Recently, in order to address the unsupervised domain adaptation (UDA) problem, extensive studies have been proposed to achieve transferrable models. Among them, the most prevalent method is adversarial domain adaptation, which can shorten the distance between the source domain and the target domain. Although adversarial learning is very effective, it still leads to the instability of the network and the drawbacks of confusing category information. In this paper, we propose a Robust Ensembling Network (REN) for UDA, which applies a robust time ensembling teacher network to learn global information for domain transfer. Specifically, REN mainly includes a teacher network and a student network, which performs standard domain adaptation training and updates weights of the teacher network. In addition, we also propose a dual-network conditional adversarial loss to improve the ability of the discriminator. Finally, for the purpose of improving the basic ability of the student network, we utilize the consistency constraint to balance the error between the student network and the teacher network. Extensive experimental results on several UDA datasets have demonstrated the effectiveness of our model by comparing with other state-of-the-art UDA algorithms.
MDQE: A More Accurate Direct Pretraining for Machine Translation Quality Estimation
Jul 24, 2021
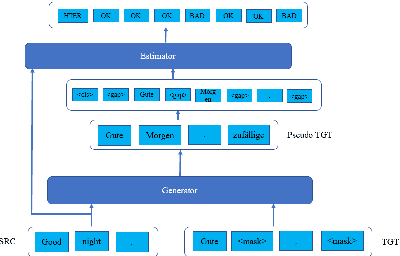

It is expensive to evaluate the results of Machine Translation(MT), which usually requires manual translation as a reference. Machine Translation Quality Estimation (QE) is a task of predicting the quality of machine translations without relying on any reference. Recently, the emergence of predictor-estimator framework which trains the predictor as a feature extractor and estimator as a QE predictor, and pre-trained language models(PLM) have achieved promising QE performance. However, we argue that there are still gaps between the predictor and the estimator in both data quality and training objectives, which preclude QE models from benefiting from a large number of parallel corpora more directly. Based on previous related work that have alleviated gaps to some extent, we propose a novel framework that provides a more accurate direct pretraining for QE tasks. In this framework, a generator is trained to produce pseudo data that is closer to the real QE data, and a estimator is pretrained on these data with novel objectives that are the same as the QE task. Experiments on widely used benchmarks show that our proposed framework outperforms existing methods, without using any pretraining models such as BERT.
Neural Process for Black-Box Model Optimization Under Bayesian Framework
Apr 03, 2021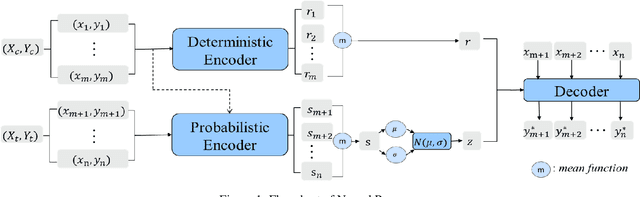
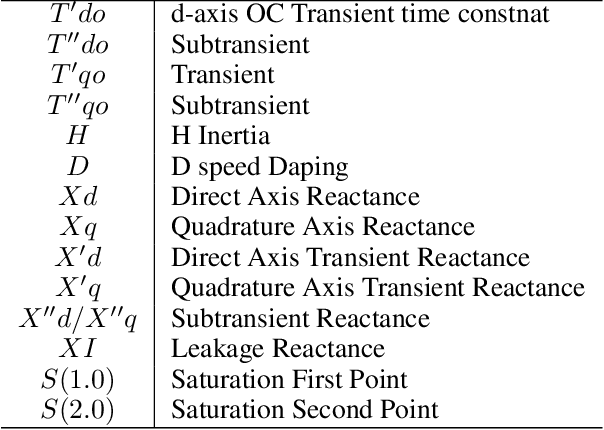
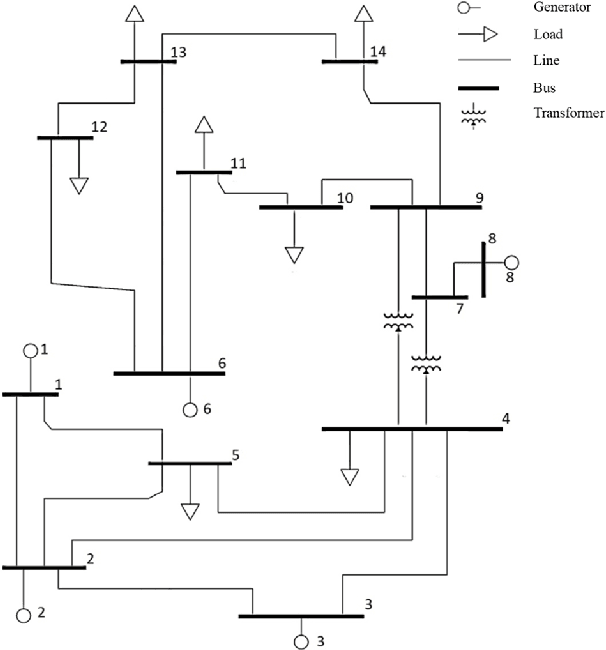
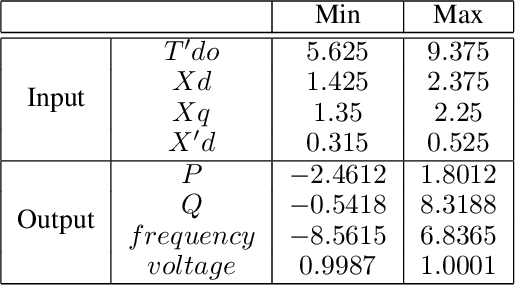
There are a large number of optimization problems in physical models where the relationships between model parameters and outputs are unknown or hard to track. These models are named as black-box models in general because they can only be viewed in terms of inputs and outputs, without knowledge of the internal workings. Optimizing the black-box model parameters has become increasingly expensive and time consuming as they have become more complex. Hence, developing effective and efficient black-box model optimization algorithms has become an important task. One powerful algorithm to solve such problem is Bayesian optimization, which can effectively estimates the model parameters that lead to the best performance, and Gaussian Process (GP) has been one of the most widely used surrogate model in Bayesian optimization. However, the time complexity of GP scales cubically with respect to the number of observed model outputs, and GP does not scale well with large parameter dimension either. Consequently, it has been challenging for GP to optimize black-box models that need to query many observations and/or have many parameters. To overcome the drawbacks of GP, in this study, we propose a general Bayesian optimization algorithm that employs a Neural Process (NP) as the surrogate model to perform black-box model optimization, namely, Neural Process for Bayesian Optimization (NPBO). In order to validate the benefits of NPBO, we compare NPBO with four benchmark approaches on a power system parameter optimization problem and a series of seven benchmark Bayesian optimization problems. The results show that the proposed NPBO performs better than the other four benchmark approaches on the power system parameter optimization problem and competitively on the seven benchmark problems.
MCFlow: Monte Carlo Flow Models for Data Imputation
Mar 27, 2020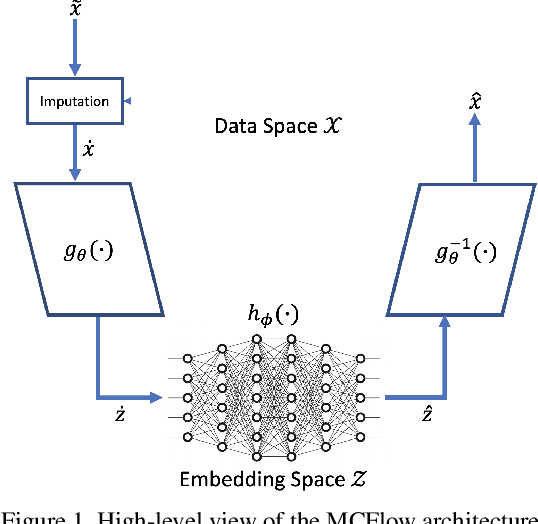
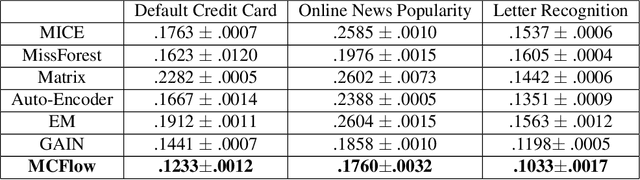
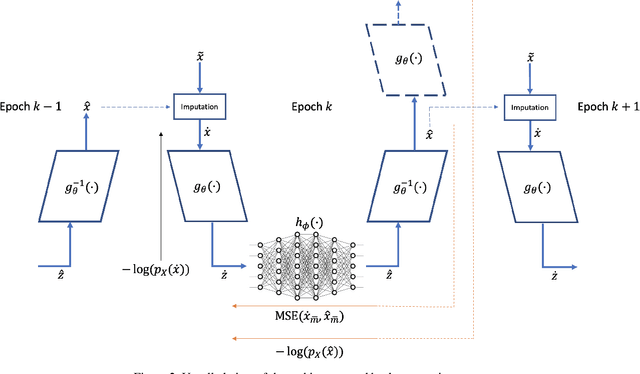
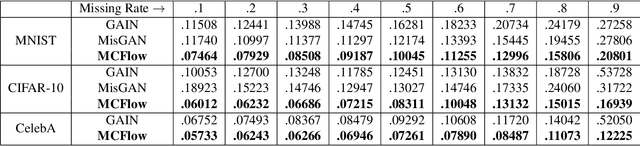
We consider the topic of data imputation, a foundational task in machine learning that addresses issues with missing data. To that end, we propose MCFlow, a deep framework for imputation that leverages normalizing flow generative models and Monte Carlo sampling. We address the causality dilemma that arises when training models with incomplete data by introducing an iterative learning scheme which alternately updates the density estimate and the values of the missing entries in the training data. We provide extensive empirical validation of the effectiveness of the proposed method on standard multivariate and image datasets, and benchmark its performance against state-of-the-art alternatives. We demonstrate that MCFlow is superior to competing methods in terms of the quality of the imputed data, as well as with regards to its ability to preserve the semantic structure of the data.
AnonymousNet: Natural Face De-Identification with Measurable Privacy
Apr 19, 2019

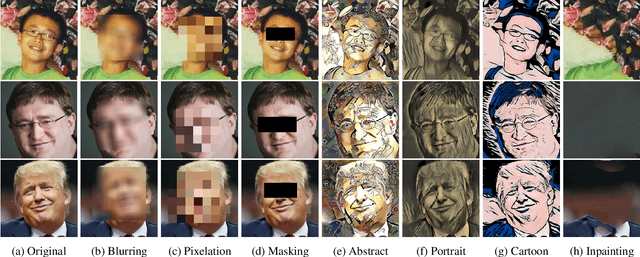

With billions of personal images being generated from social media and cameras of all sorts on a daily basis, security and privacy are unprecedentedly challenged. Although extensive attempts have been made, existing face image de-identification techniques are either insufficient in photo-reality or incapable of balancing privacy and usability qualitatively and quantitatively, i.e., they fail to answer counterfactual questions such as "is it private now?", "how private is it?", and "can it be more private?" In this paper, we propose a novel framework called AnonymousNet, with an effort to address these issues systematically, balance usability, and enhance privacy in a natural and measurable manner. The framework encompasses four stages: facial attribute estimation, privacy-metric-oriented face obfuscation, directed natural image synthesis, and adversarial perturbation. Not only do we achieve the state-of-the-arts in terms of image quality and attribute prediction accuracy, we are also the first to show that facial privacy is measurable, can be factorized, and accordingly be manipulated in a photo-realistic fashion to fulfill different requirements and application scenarios. Experiments further demonstrate the effectiveness of the proposed framework.
Medical Time Series Classification with Hierarchical Attention-based Temporal Convolutional Networks: A Case Study of Myotonic Dystrophy Diagnosis
Mar 28, 2019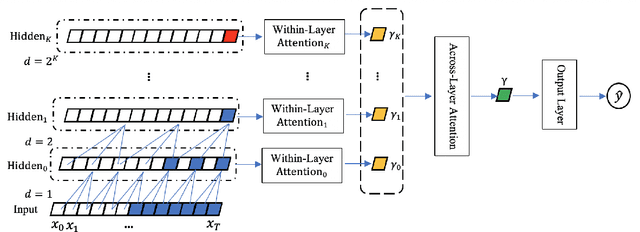
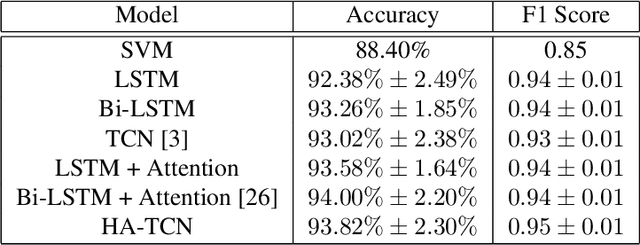
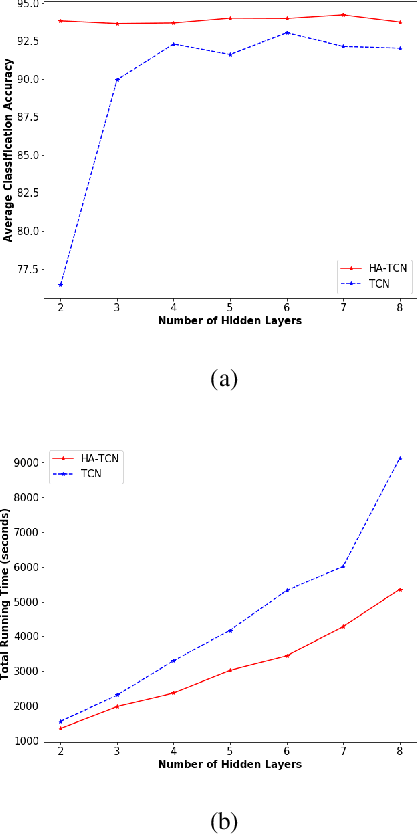
Myotonia, which refers to delayed muscle relaxation after contraction, is the main symptom of myotonic dystrophy patients. We propose a hierarchical attention-based temporal convolutional network (HA-TCN) for myotonic dystrohpy diagnosis from handgrip time series data, and introduce mechanisms that enable model explainability. We compare the performance of the HA-TCN model against that of benchmark TCN models, LSTM models with and without attention mechanisms, and SVM approaches with handcrafted features. In terms of classification accuracy and F1 score, we found all deep learning models have similar levels of performance, and they all outperform SVM. Further, the HA-TCN model outperforms its TCN counterpart with regards to computational efficiency regardless of network depth, and in terms of performance particularly when the number of hidden layers is small. Lastly, HA-TCN models can consistently identify relevant time series segments in the relaxation phase of the handgrip time series, and exhibit increased robustness to noise when compared to attention-based LSTM models.
Predicting Station-level Hourly Demands in a Large-scale Bike-sharing Network: A Graph Convolutional Neural Network Approach
Oct 19, 2018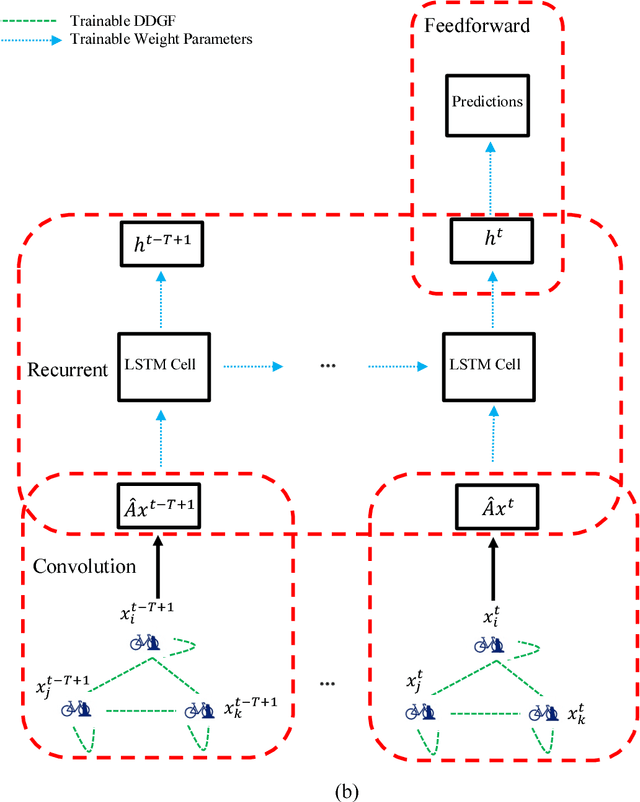

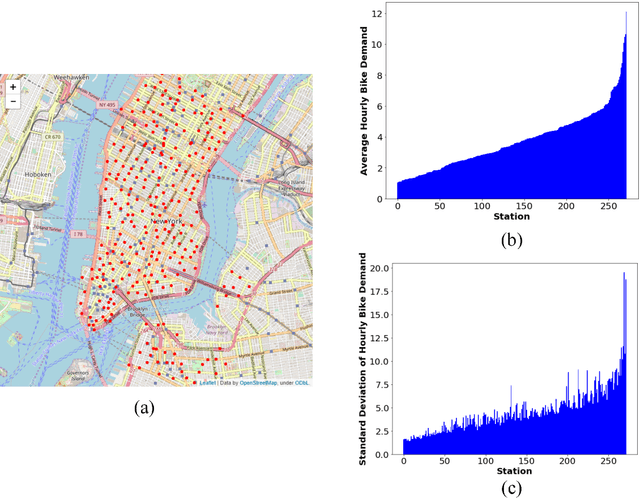
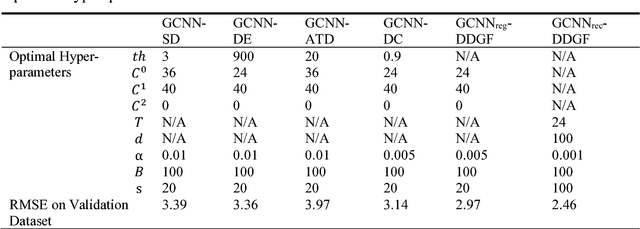
This study proposes a novel Graph Convolutional Neural Network with Data-driven Graph Filter (GCNN-DDGF) model that can learn hidden heterogeneous pairwise correlations between stations to predict station-level hourly demand in a large-scale bike-sharing network. Two architectures of the GCNN-DDGF model are explored; GCNNreg-DDGF is a regular GCNN-DDGF model which contains the convolution and feedforward blocks, and GCNNrec-DDGF additionally contains a recurrent block from the Long Short-term Memory neural network architecture to capture temporal dependencies in the bike-sharing demand series. Furthermore, four types of GCNN models are proposed whose adjacency matrices are based on various bike-sharing system data, including Spatial Distance matrix (SD), Demand matrix (DE), Average Trip Duration matrix (ATD), and Demand Correlation matrix (DC). These six types of GCNN models and seven other benchmark models are built and compared on a Citi Bike dataset from New York City which includes 272 stations and over 28 million transactions from 2013 to 2016. Results show that the GCNNrec-DDGF performs the best in terms of the Root Mean Square Error, the Mean Absolute Error and the coefficient of determination (R2), followed by the GCNNreg-DDGF. They outperform the other models. Through a more detailed graph network analysis based on the learned DDGF, insights are obtained on the black box of the GCNN-DDGF model. It is found to capture some information similar to details embedded in the SD, DE and DC matrices. More importantly, it also uncovers hidden heterogeneous pairwise correlations between stations that are not revealed by any of those matrices.