 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergyLens: Predictive Energy-Aware Exploration for Multi-GPU LLM Inference Optimization
May 14, 2026We present EnergyLens, an end-to-end framework for energy-aware large language model (LLM) inference optimization. As LLMs scale, predicting and reducing their energy footprint has become critical for sustainability and datacenter operations, yet existing approaches either require production-level code and expensive profiling or fail to accurately capture multi-GPU energy behavior. As a result, practitioners lack tools for deciding which optimizations to prioritize and for selecting among existing deployment configurations when exhaustive profiling is impractical. EnergyLens addresses this gap with an intuitive einsum-based interface that captures LLM specifications including fusion, parallelism, and compute-communication overlap, combined with load-imbalance-aware MoE modeling and an empirically driven communication energy model for multi-GPU settings. We validate EnergyLens on Llama3 and Qwen3-MoE across tensor-parallel and expert-parallel configurations, achieving mean absolute percentage errors (MAPEs) between 9.25% and 13.19% for multi-GPU prefill and decode energy, and 12.97% across SM allocations for Megatron-style overlap. Our energy-driven exploration reveals up to 1.47x and 52.9x energy variation across configurations in prefill and decode efficiency and motivates distributed serving. We further show that compute-communication overlap is difficult to optimize with intuition alone, but EnergyLens correctly identifies Pareto-optimal overlap configurations.
Toward Clinically Ready Foundation Models in Medical Image Analysis: Adaptation Mechanisms and Deployment Trade-offs
Mar 15, 2026Foundation models (FMs) have demonstrated strong transferability across medical imaging tasks, yet their clinical utility depends critically on how pretrained representations are adapted to domain-specific data, supervision regimes, and deployment constraints. Prior surveys primarily emphasize architectural advances and application coverage, while the mechanisms of adaptation and their implications for robustness, calibration, and regulatory feasibility remain insufficiently structured. This review introduces a strategy-centric framework for FM adaptation in medical image analysis (MIA). We conceptualize adaptation as a post-pretraining intervention and organize existing approaches into five mechanisms: parameter-, representation-, objective-, data-centric, and architectural/sequence-level adaptation. For each mechanism, we analyze trade-offs in adaptation depth, label efficiency, domain robustness, computational cost, auditability, and regulatory burden. We synthesize evidence across classification, segmentation, and detection tasks, highlighting how adaptation strategies influence clinically relevant failure modes rather than only aggregate benchmark performance. Finally, we examine how adaptation choices interact with validation protocols, calibration stability, multi-institutional deployment, and regulatory oversight. By reframing adaptation as a process of controlled representational change under clinical constraints, this review provides practical guidance for designing FM-based systems that are robust, auditable, and compatible with clinical deployment.
Rethinking Empirical Evaluation of Adversarial Robustness Using First-Order Attack Methods
Jun 01, 2020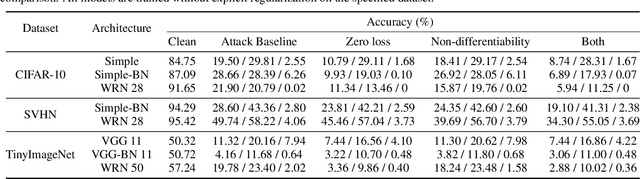
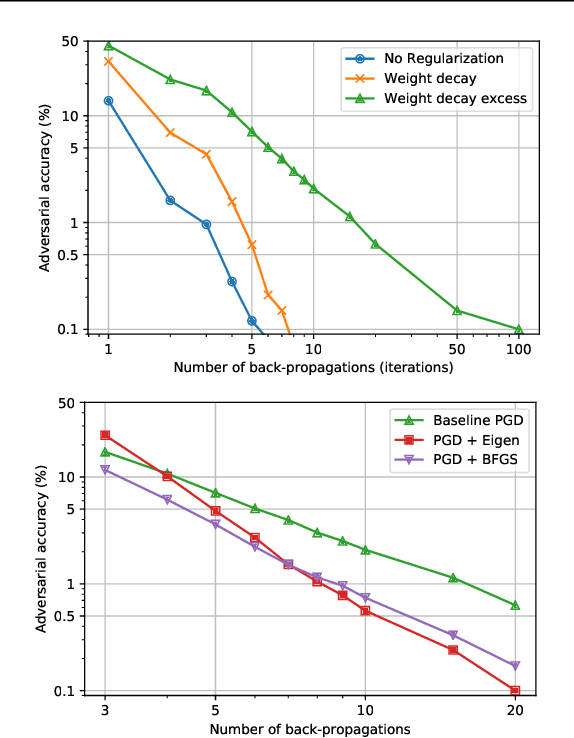
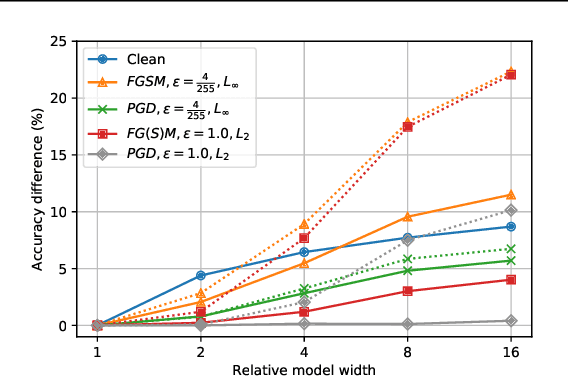
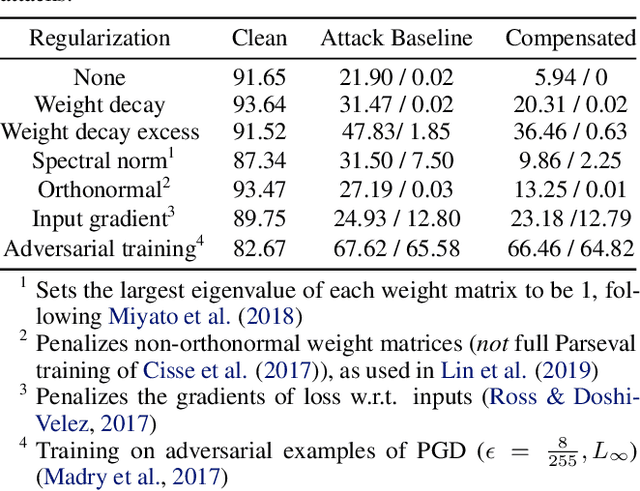
We identify three common cases that lead to overestimation of adversarial accuracy against bounded first-order attack methods, which is popularly used as a proxy for adversarial robustness in empirical studies. For each case, we propose compensation methods that either address sources of inaccurate gradient computation, such as numerical instability near zero and non-differentiability, or reduce the total number of back-propagations for iterative attacks by approximating second-order information. These compensation methods can be combined with existing attack methods for a more precise empirical evaluation metric. We illustrate the impact of these three cases with examples of practical interest, such as benchmarking model capacity and regularization techniques for robustness. Overall, our work shows that overestimated adversarial accuracy that is not indicative of robustness is prevalent even for conventionally trained deep neural networks, and highlights cautions of using empirical evaluation without guaranteed bounds.
Autoencoder-Based Incremental Class Learning without Retraining on Old Data
Jul 18, 2019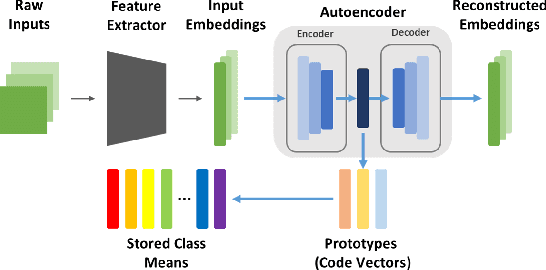
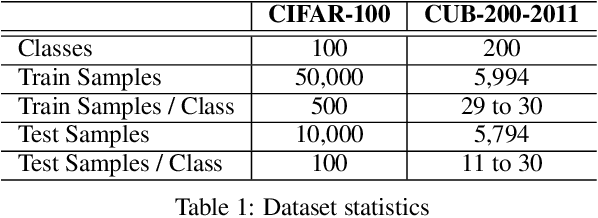

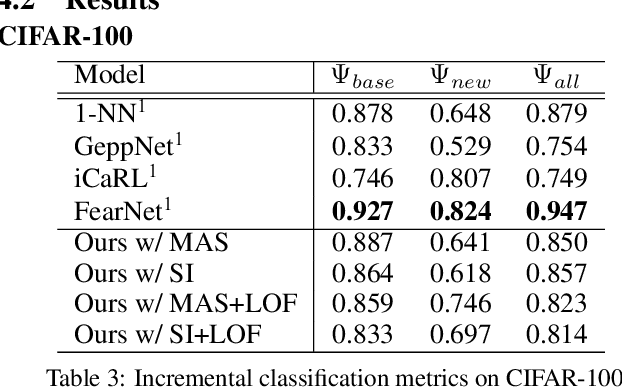
Incremental class learning, a scenario in continual learning context where classes and their training data are sequentially and disjointedly observed, challenges a problem widely known as catastrophic forgetting. In this work, we propose a novel incremental class learning method that can significantly reduce memory overhead compared to previous approaches. Apart from conventional classification scheme using softmax, our model bases on an autoencoder to extract prototypes for given inputs so that no change in its output unit is required. It stores only the mean of prototypes per class to perform metric-based classification, unlike rehearsal approaches which rely on large memory or generative model. To mitigate catastrophic forgetting, regularization methods are applied on our model when a new task is encountered. We evaluate our method by experimenting on CIFAR-100 and CUB-200-2011 and show that its performance is comparable to the state-of-the-art method with much lower additional memory cost.