 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Clinically Ready Foundation Models in Medical Image Analysis: Adaptation Mechanisms and Deployment Trade-offs
Mar 15, 2026Foundation models (FMs) have demonstrated strong transferability across medical imaging tasks, yet their clinical utility depends critically on how pretrained representations are adapted to domain-specific data, supervision regimes, and deployment constraints. Prior surveys primarily emphasize architectural advances and application coverage, while the mechanisms of adaptation and their implications for robustness, calibration, and regulatory feasibility remain insufficiently structured. This review introduces a strategy-centric framework for FM adaptation in medical image analysis (MIA). We conceptualize adaptation as a post-pretraining intervention and organize existing approaches into five mechanisms: parameter-, representation-, objective-, data-centric, and architectural/sequence-level adaptation. For each mechanism, we analyze trade-offs in adaptation depth, label efficiency, domain robustness, computational cost, auditability, and regulatory burden. We synthesize evidence across classification, segmentation, and detection tasks, highlighting how adaptation strategies influence clinically relevant failure modes rather than only aggregate benchmark performance. Finally, we examine how adaptation choices interact with validation protocols, calibration stability, multi-institutional deployment, and regulatory oversight. By reframing adaptation as a process of controlled representational change under clinical constraints, this review provides practical guidance for designing FM-based systems that are robust, auditable, and compatible with clinical deployment.
Computationally Efficient Diffusion Models in Medical Imaging: A Comprehensive Review
May 09, 2025The diffusion model has recently emerged as a potent approach in computer vision, demonstrating remarkable performances in the field of generative artificial intelligence. Capable of producing high-quality synthetic images, diffusion models have been successfully applied across a range of applications. However, a significant challenge remains with the high computational cost associated with training and generating these models. This study focuses on the efficiency and inference time of diffusion-based generative models, highlighting their applications in both natural and medical imaging. We present the most recent advances in diffusion models by categorizing them into three key models: the Denoising Diffusion Probabilistic Model (DDPM), the Latent Diffusion Model (LDM), and the Wavelet Diffusion Model (WDM). These models play a crucial role in medical imaging, where producing fast, reliable, and high-quality medical images is essential for accurate analysis of abnormalities and disease diagnosis. We first investigate the general framework of DDPM, LDM, and WDM and discuss the computational complexity gap filled by these models in natural and medical imaging. We then discuss the current limitations of these models as well as the opportunities and future research directions in medical imaging.
Bridging the Gap Between Training and Inference for Spatio-Temporal Forecasting
May 19, 2020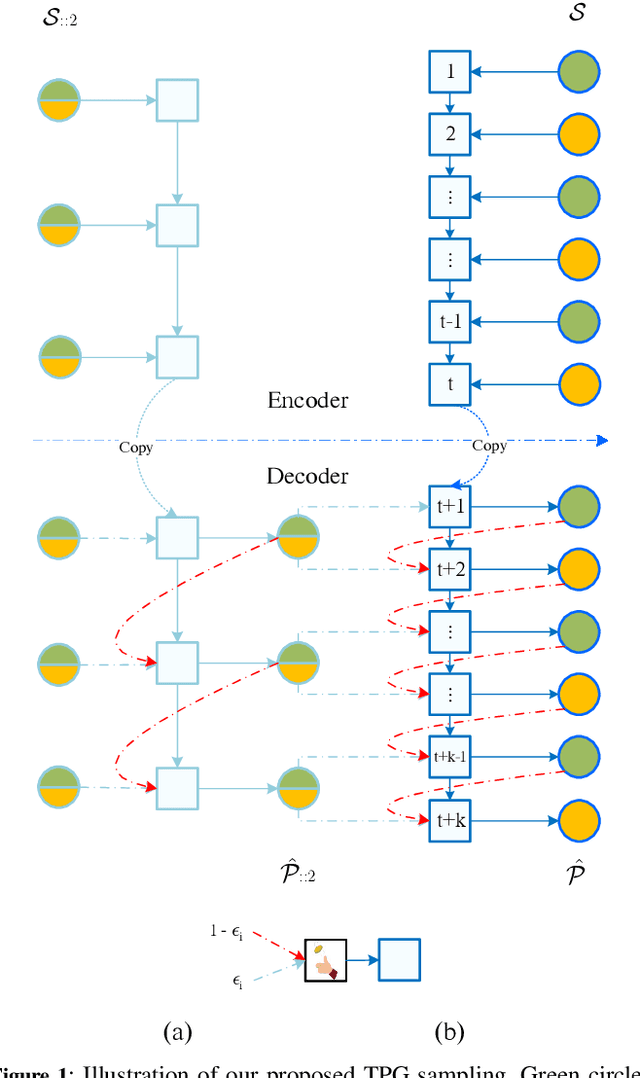
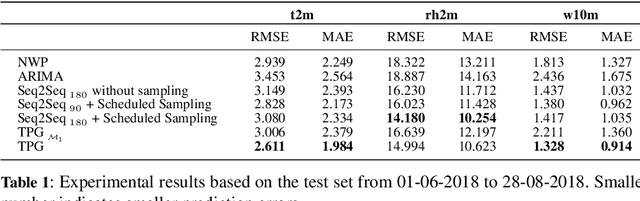
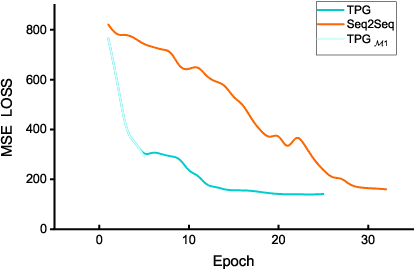
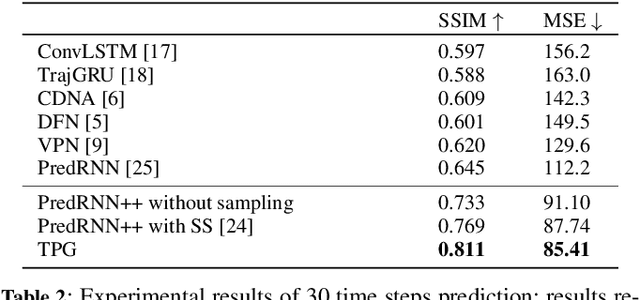
Spatio-temporal sequence forecasting is one of the fundamental tasks in spatio-temporal data mining. It facilitates many real world applications such as precipitation nowcasting, citywide crowd flow prediction and air pollution forecasting. Recently, a few Seq2Seq based approaches have been proposed, but one of the drawbacks of Seq2Seq models is that, small errors can accumulate quickly along the generated sequence at the inference stage due to the different distributions of training and inference phase. That is because Seq2Seq models minimise single step errors only during training, however the entire sequence has to be generated during the inference phase which generates a discrepancy between training and inference. In this work, we propose a novel curriculum learning based strategy named Temporal Progressive Growing Sampling to effectively bridge the gap between training and inference for spatio-temporal sequence forecasting, by transforming the training process from a fully-supervised manner which utilises all available previous ground-truth values to a less-supervised manner which replaces some of the ground-truth context with generated predictions. To do that we sample the target sequence from midway outputs from intermediate models trained with bigger timescales through a carefully designed decaying strategy. Experimental results demonstrate that our proposed method better models long term dependencies and outperforms baseline approaches on two competitive datasets.