 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Interactive Facts for Stock Selection via Neural Recursive ODEs
Oct 28, 2022



Stock selection attempts to rank a list of stocks for optimizing investment decision making, aiming at minimizing investment risks while maximizing profit returns. Recently, researchers have developed various (recurrent) neural network-based methods to tackle this problem. Without exceptions, they primarily leverage historical market volatility to enhance the selection performance. However, these approaches greatly rely on discrete sampled market observations, which either fail to consider the uncertainty of stock fluctuations or predict continuous stock dynamics in the future. Besides, some studies have considered the explicit stock interdependence derived from multiple domains (e.g., industry and shareholder). Nevertheless, the implicit cross-dependencies among different domains are under-explored. To address such limitations, we present a novel stock selection solution -- StockODE, a latent variable model with Gaussian prior. Specifically, we devise a Movement Trend Correlation module to expose the time-varying relationships regarding stock movements. We design Neural Recursive Ordinary Differential Equation Networks (NRODEs) to capture the temporal evolution of stock volatility in a continuous dynamic manner. Moreover, we build a hierarchical hypergraph to incorporate the domain-aware dependencies among the stocks. Experiments conducted on two real-world stock market datasets demonstrate that StockODE significantly outperforms several baselines, such as up to 18.57% average improvement regarding Sharpe Ratio.
Self-supervised Representation Learning for Trip Recommendation
Sep 08, 2021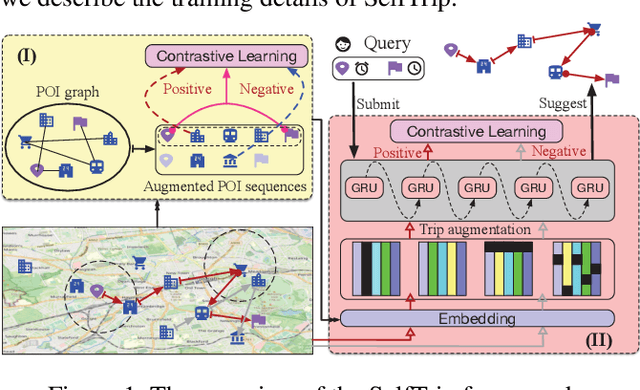
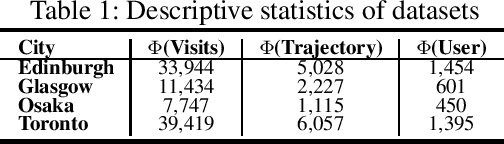
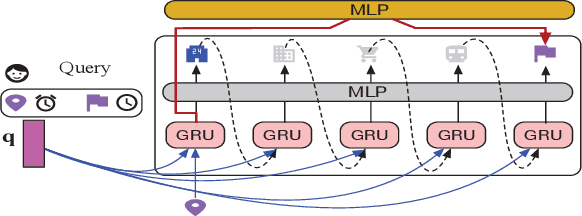
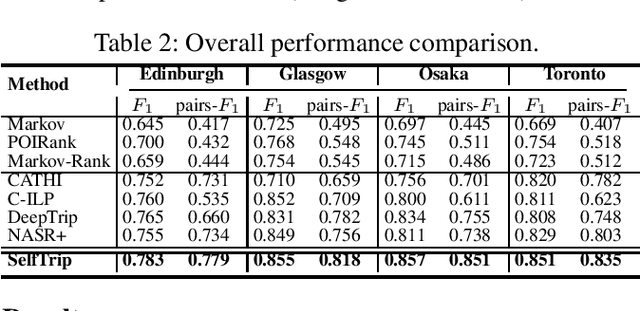
Trip recommendation is a significant and engaging location-based service that can help new tourists make more customized travel plans. It often attempts to suggest a sequence of point of interests (POIs) for a user who requests a personalized travel demand. Conventional methods either leverage the heuristic algorithms (e.g., dynamic programming) or statistical analysis (e.g., Markov models) to search or rank a POI sequence. These procedures may fail to capture the diversity of human needs and transitional regularities. They even provide recommendations that deviate from tourists' real travel intention when the trip data is sparse. Although recent deep recursive models (e.g., RNN) are capable of alleviating these concerns, existing solutions hardly recognize the practical reality, such as the diversity of tourist demands, uncertainties in the trip generation, and the complex visiting preference. Inspired by the advance in deep learning, we introduce a novel self-supervised representation learning framework for trip recommendation -- SelfTrip, aiming at tackling the aforementioned challenges. Specifically, we propose a two-step contrastive learning mechanism concerning the POI representation, as well as trip representation. Furthermore, we present four trip augmentation methods to capture the visiting uncertainties in trip planning. We evaluate our SelfTrip on four real-world datasets, and extensive results demonstrate the promising gain compared with several cutting-edge benchmarks, e.g., up to 4% and 12% on F1 and pair-F1, respectively.
Enhanced Seq2Seq Autoencoder via Contrastive Learning for Abstractive Text Summarization
Aug 26, 2021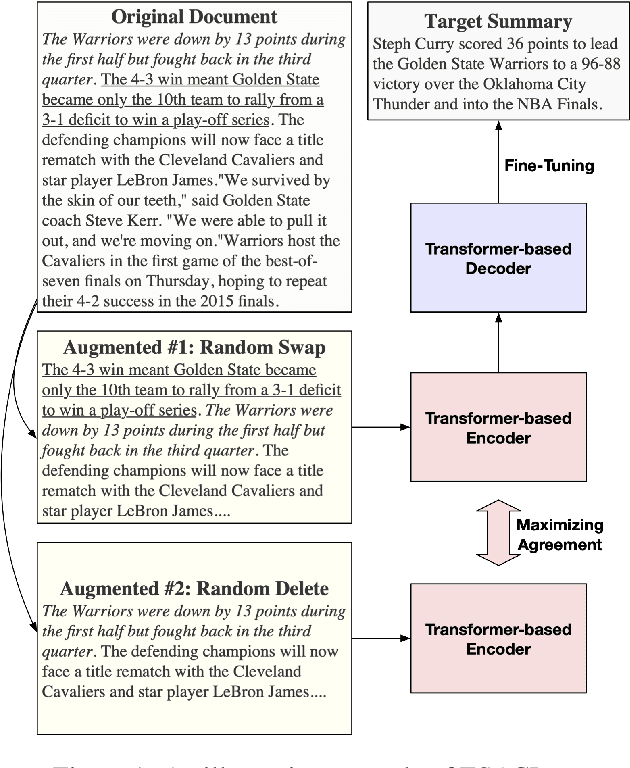
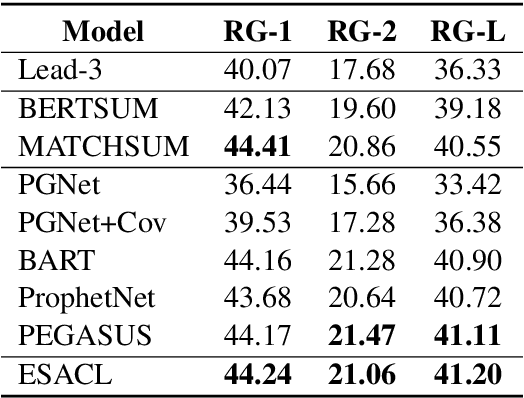
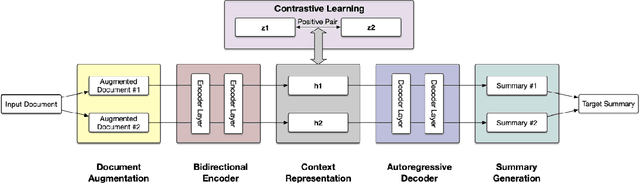
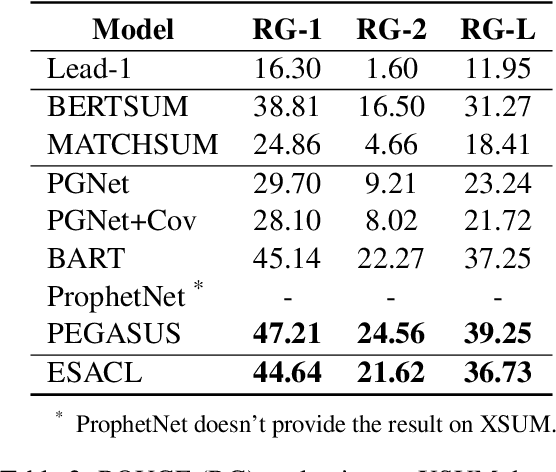
In this paper, we present a denoising sequence-to-sequence (seq2seq) autoencoder via contrastive learning for abstractive text summarization. Our model adopts a standard Transformer-based architecture with a multi-layer bi-directional encoder and an auto-regressive decoder. To enhance its denoising ability, we incorporate self-supervised contrastive learning along with various sentence-level document augmentation. These two components, seq2seq autoencoder and contrastive learning, are jointly trained through fine-tuning, which improves the performance of text summarization with regard to ROUGE scores and human evaluation. We conduct experiments on two datasets and demonstrate that our model outperforms many existing benchmarks and even achieves comparable performance to the state-of-the-art abstractive systems trained with more complex architecture and extensive computation resources.
CCGL: Contrastive Cascade Graph Learning
Jul 27, 2021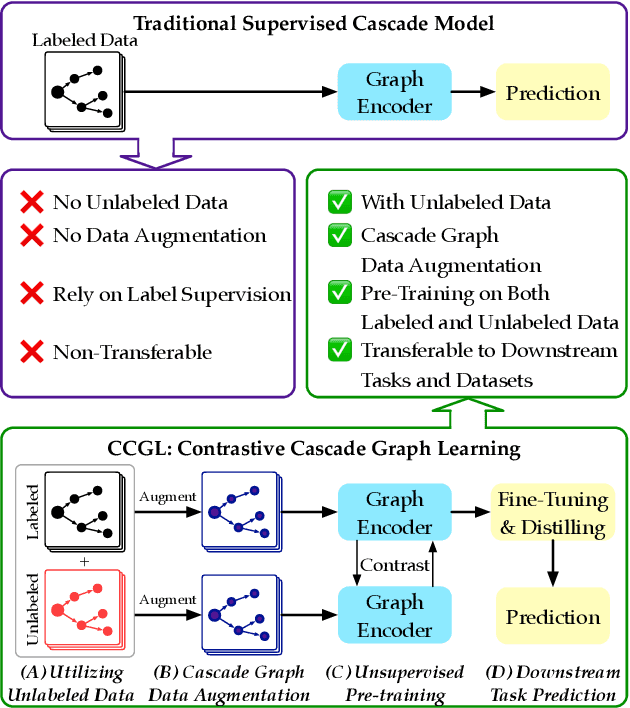
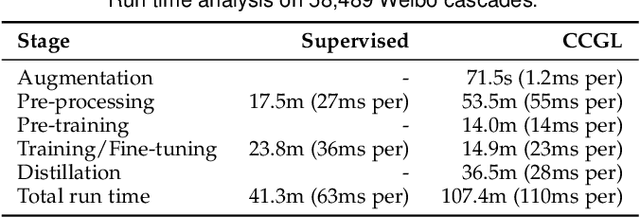
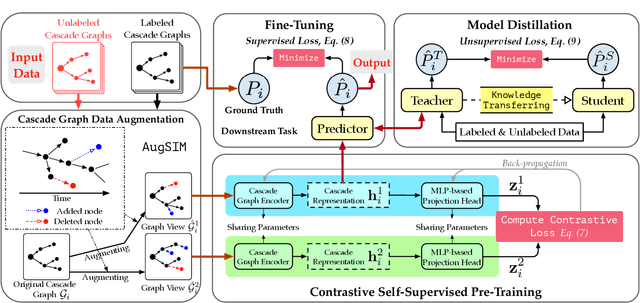
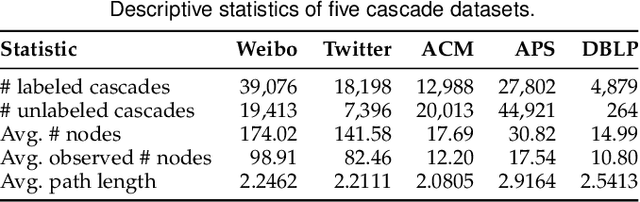
Supervised learning, while prevalent for information cascade modeling, often requires abundant labeled data in training, and the trained model is not easy to generalize across tasks and datasets. Semi-supervised learning facilitates unlabeled data for cascade understanding in pre-training. It often learns fine-grained feature-level representations, which can easily result in overfitting for downstream tasks. Recently, contrastive self-supervised learning is designed to alleviate these two fundamental issues in linguistic and visual tasks. However, its direct applicability for cascade modeling, especially graph cascade related tasks, remains underexplored. In this work, we present Contrastive Cascade Graph Learning (CCGL), a novel framework for cascade graph representation learning in a contrastive, self-supervised, and task-agnostic way. In particular, CCGL first designs an effective data augmentation strategy to capture variation and uncertainty. Second, it learns a generic model for graph cascade tasks via self-supervised contrastive pre-training using both unlabeled and labeled data. Third, CCGL learns a task-specific cascade model via fine-tuning using labeled data. Finally, to make the model transferable across datasets and cascade applications, CCGL further enhances the model via distillation using a teacher-student architecture. We demonstrate that CCGL significantly outperforms its supervised and semi-supervised counterpartsfor several downstream tasks.
Graph Neural Network Based VC Investment Success Prediction
May 25, 2021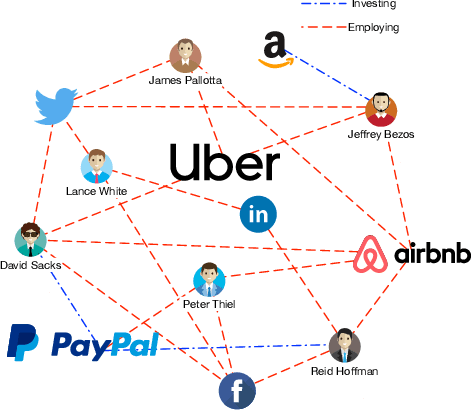
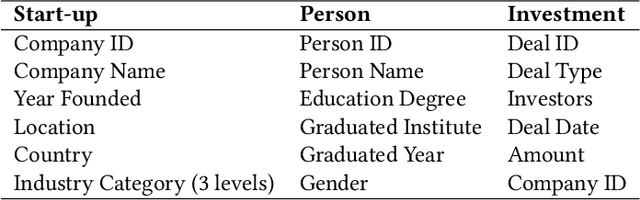
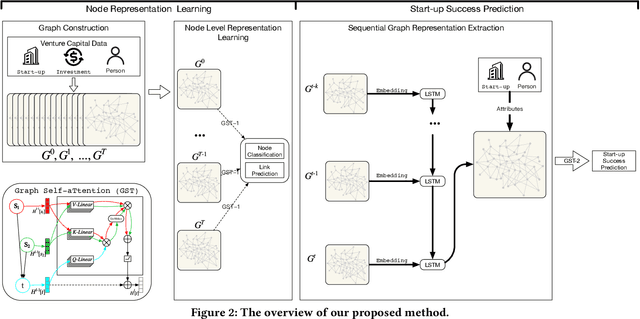
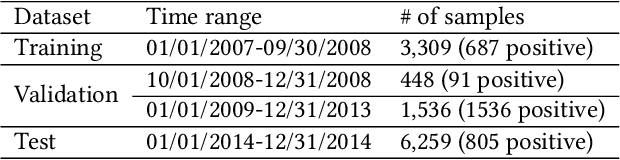
Predicting the start-ups that will eventually succeed is essentially important for the venture capital business and worldwide policy makers, especially at an early stage such that rewards can possibly be exponential. Though various empirical studies and data-driven modeling work have been done, the predictive power of the complex networks of stakeholders including venture capital investors, start-ups, and start-ups' managing members has not been thoroughly explored. We design an incremental representation learning mechanism and a sequential learning model, utilizing the network structure together with the rich attributes of the nodes. In general, our method achieves the state-of-the-art prediction performance on a comprehensive dataset of global venture capital investments and surpasses human investors by large margins. Specifically, it excels at predicting the outcomes for start-ups in industries such as healthcare and IT. Meanwhile, we shed light on impacts on start-up success from observable factors including gender, education, and networking, which can be of value for practitioners as well as policy makers when they screen ventures of high growth potentials.
Weighting-Based Treatment Effect Estimation via Distribution Learning
Jan 06, 2021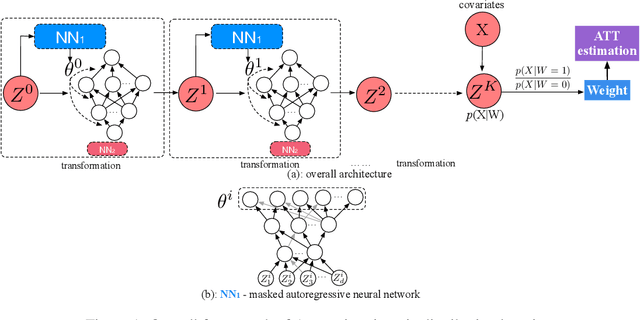
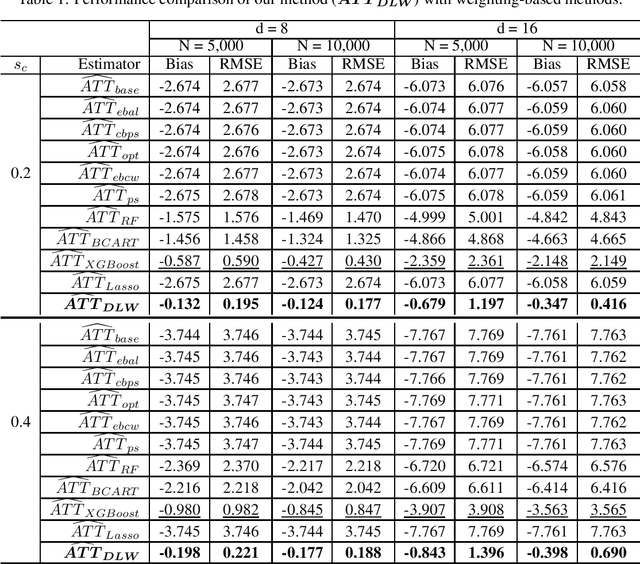
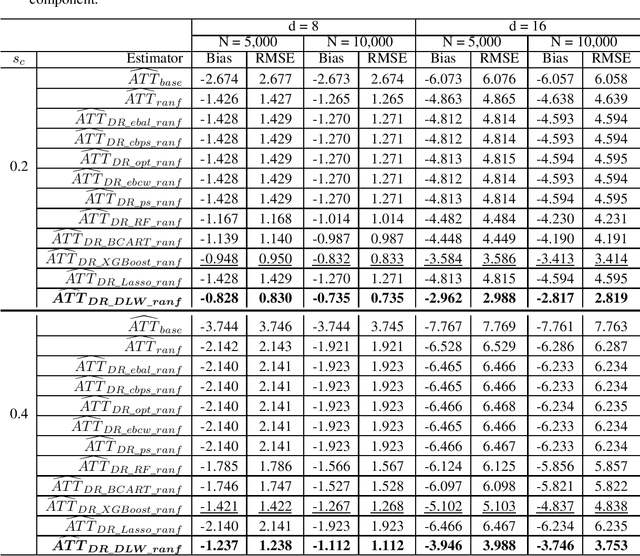
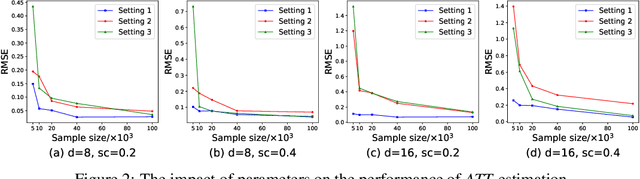
Existing weighting methods for treatment effect estimation are often built upon the idea of propensity scores or covariate balance. They usually impose strong assumptions on treatment assignment or outcome model to obtain unbiased estimation, such as linearity or specific functional forms, which easily leads to the major drawback of model mis-specification. In this paper, we aim to alleviate these issues by developing a distribution learning-based weighting method. We first learn the true underlying distribution of covariates conditioned on treatment assignment, then leverage the ratio of covariates' density in the treatment group to that of the control group as the weight for estimating treatment effects. Specifically, we propose to approximate the distribution of covariates in both treatment and control groups through invertible transformations via change of variables. To demonstrate the superiority, robustness, and generalizability of our method, we conduct extensive experiments using synthetic and real data. From the experiment results, we find that our method for estimating average treatment effect on treated (ATT) with observational data outperforms several cutting-edge weighting-only benchmarking methods, and it maintains its advantage under a doubly-robust estimation framework that combines weighting with some advanced outcome modeling methods.
A Two-Phase Approach for Abstractive Podcast Summarization
Nov 16, 2020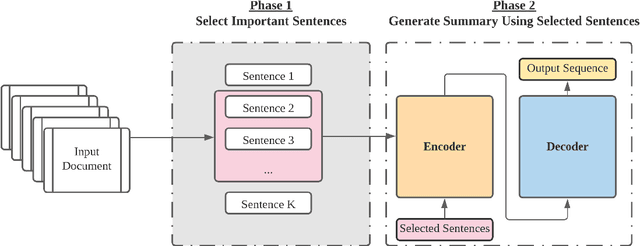


Podcast summarization is different from summarization of other data formats, such as news, patents, and scientific papers in that podcasts are often longer, conversational, colloquial, and full of sponsorship and advertising information, which imposes great challenges for existing models. In this paper, we focus on abstractive podcast summarization and propose a two-phase approach: sentence selection and seq2seq learning. Specifically, we first select important sentences from the noisy long podcast transcripts. The selection is based on sentence similarity to the reference to reduce the redundancy and the associated latent topics to preserve semantics. Then the selected sentences are fed into a pre-trained encoder-decoder framework for the summary generation. Our approach achieves promising results regarding both ROUGE-based measures and human evaluations.
Topic-Aware Abstractive Text Summarization
Oct 20, 2020
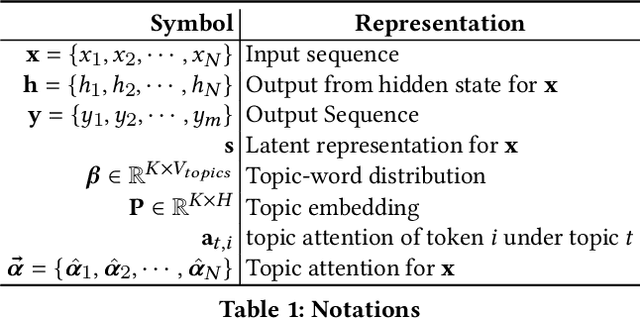
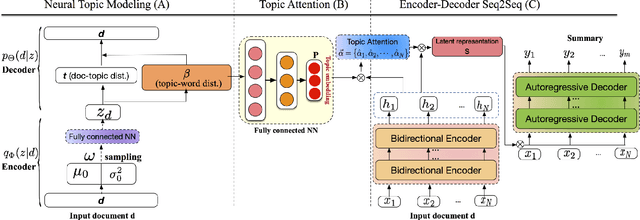
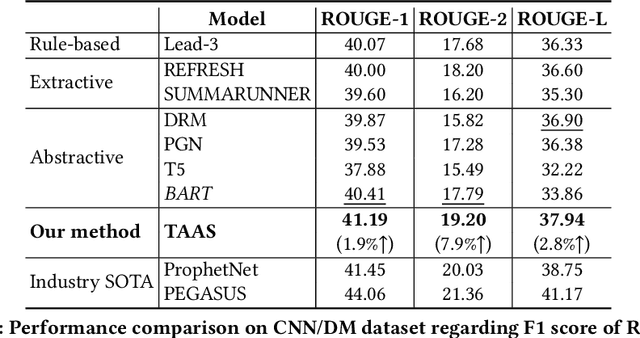
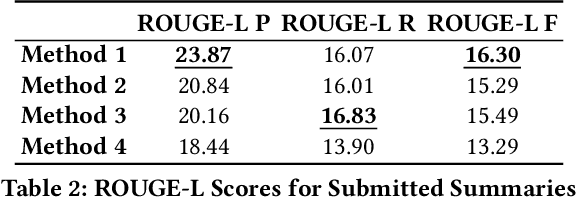
Automatic text summarization aims at condensing a document to a shorter version while preserving the key information. Different from extractive summarization which simply selects text fragments from the document, abstractive summarization generates the summary in a word-by-word manner. Most current state-of-the-art (SOTA) abstractive summarization methods are based on the Transformer-based encoder-decoder architecture and focus on novel self-supervised objectives in pre-training. While these models well capture the contextual information among words in documents, little attention has been paid to incorporating global semantics to better fine-tune for the downstream abstractive summarization task. In this study, we propose a topic-aware abstractive summarization (TAAS) framework by leveraging the underlying semantic structure of documents represented by their latent topics. Specifically, TAAS seamlessly incorporates a neural topic modeling into an encoder-decoder based sequence generation procedure via attention for summarization. This design is able to learn and preserve global semantics of documents and thus makes summarization effective, which has been proved by our experiments on real-world datasets. As compared to several cutting-edge baseline methods, we show that TAAS outperforms BART, a well-recognized SOTA model, by 2%, 8%, and 12% regarding the F measure of ROUGE-1, ROUGE-2, and ROUGE-L, respectively. TAAS also achieves comparable performance to PEGASUS and ProphetNet, which is difficult to accomplish given that training PEGASUS and ProphetNet requires enormous computing capacity beyond what we used in this study.
A Baseline Analysis for Podcast Abstractive Summarization
Aug 26, 2020
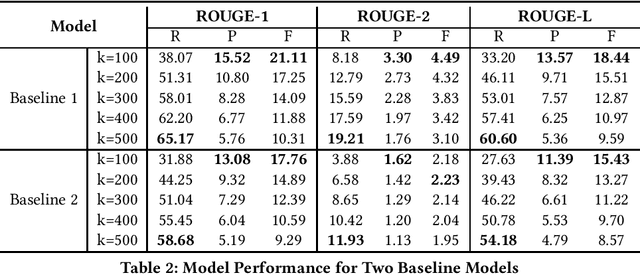
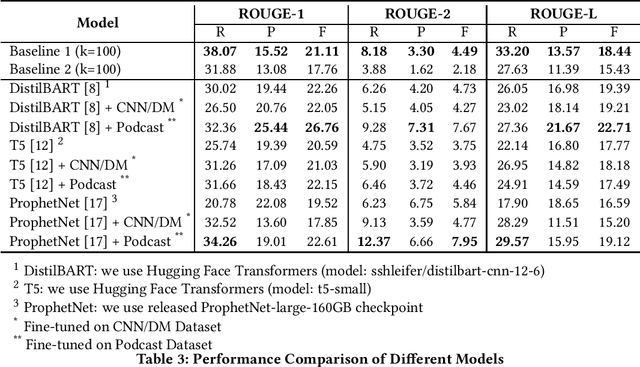
Podcast summary, an important factor affecting end-users' listening decisions, has often been considered a critical feature in podcast recommendation systems, as well as many downstream applications. Existing abstractive summarization approaches are mainly built on fine-tuned models on professionally edited texts such as CNN and DailyMail news. Different from news, podcasts are often longer, more colloquial and conversational, and noisier with contents on commercials and sponsorship, which makes automatic podcast summarization extremely challenging. This paper presents a baseline analysis of podcast summarization using the Spotify Podcast Dataset provided by TREC 2020. It aims to help researchers understand current state-of-the-art pre-trained models and hence build a foundation for creating better models.
A Survey of Information Cascade Analysis: Models, Predictions and Recent Advances
May 25, 2020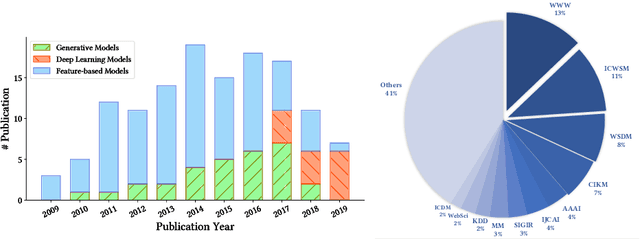
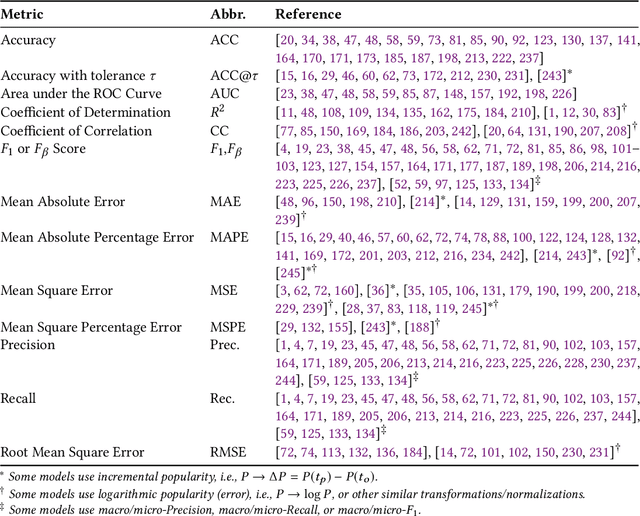
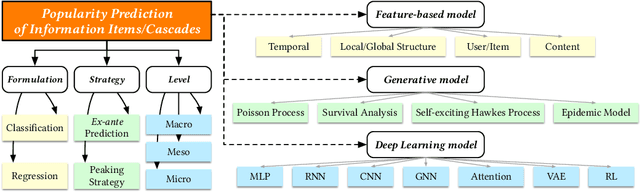

The deluge of digital information in our daily life -- from user-generated content such as microblogs and scientific papers, to online business such as viral marketing and advertising -- offers unprecedented opportunities to explore and exploit the trajectories and structures of the evolution of information cascades. Abundant research efforts, both academic and industrial, have aimed to reach a better understanding of the mechanisms driving the spread of information and quantifying the outcome of information diffusion. This article presents a comprehensive review and categorization of information popularity prediction methods, from feature engineering and stochastic processes, through graph representation, to deep learning-based approaches. Specifically, we first formally define different types of information cascades and summarize the perspectives of existing studies. We then present a taxonomy that categorizes existing works into the aforementioned three main groups as well as the main subclasses in each group, and we systematically review cutting-edge research work. Finally, we summarize the pros and cons of existing research efforts and outline the open challenges and opportunities in this field.