 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis
Oct 28, 2019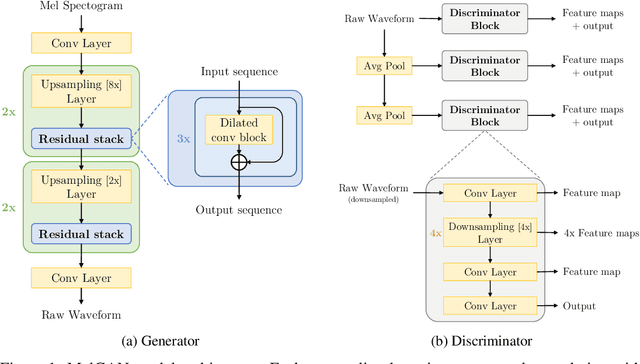


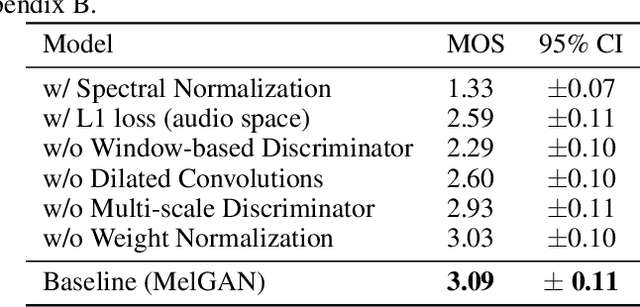
Previous works (Donahue et al., 2018a; Engel et al., 2019a) have found that generating coherent raw audio waveforms with GANs is challenging. In this paper, we show that it is possible to train GANs reliably to generate high quality coherent waveforms by introducing a set of architectural changes and simple training techniques. Subjective evaluation metric (Mean Opinion Score, or MOS) shows the effectiveness of the proposed approach for high quality mel-spectrogram inversion. To establish the generality of the proposed techniques, we show qualitative results of our model in speech synthesis, music domain translation and unconditional music synthesis. We evaluate the various components of the model through ablation studies and suggest a set of guidelines to design general purpose discriminators and generators for conditional sequence synthesis tasks. Our model is non-autoregressive, fully convolutional, with significantly fewer parameters than competing models and generalizes to unseen speakers for mel-spectrogram inversion. Our pytorch implementation runs at more than 100x faster than realtime on GTX 1080Ti GPU and more than 2x faster than real-time on CPU, without any hardware specific optimization tricks.
Blood Vessel Detection using Modified Multiscale MF-FDOG Filters for Diabetic Retinopathy
Oct 26, 2019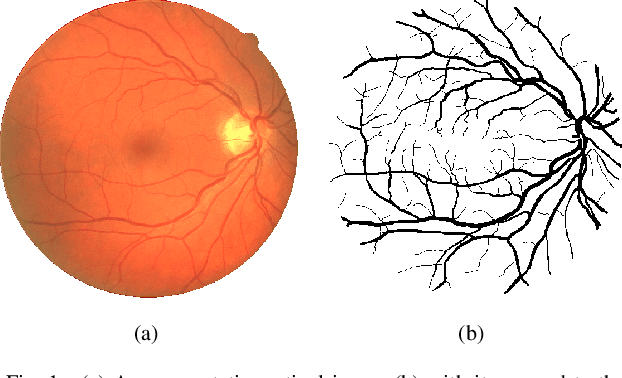
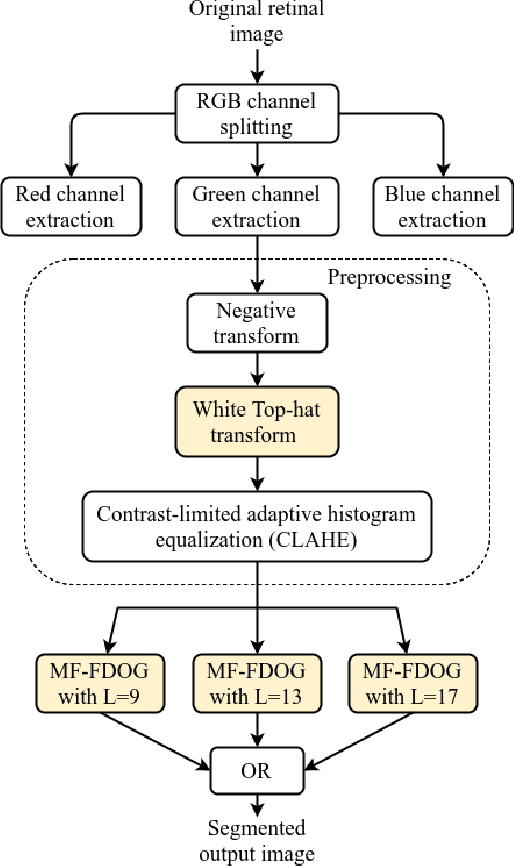
Blindness in diabetic patients caused by retinopathy (characterized by an increase in the diameter and new branches of the blood vessels inside the retina) is a grave concern. Many efforts have been made for the early detection of the disease using various image processing techniques on retinal images. However, most of the methods are plagued with the false detection of the blood vessel pixels. Given that, here, we propose a modified matched filter with the first derivative of Gaussian. The method uses the top-hat transform and contrast limited histogram equalization. Further, we segment the modified multiscale matched filter response by using a binary threshold obtained from the first derivative of Gaussian. The method was assessed on a publicly available database (DRIVE database). As anticipated, the proposed method provides a higher accuracy compared to the literature. Moreover, a lesser false detection from the existing matched filters and its variants have been observed.
Automated retinal vessel segmentation based on morphological preprocessing and 2D-Gabor wavelets
Aug 12, 2019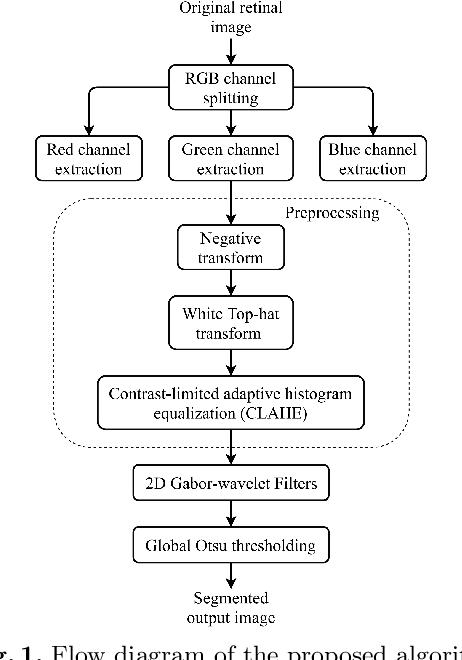
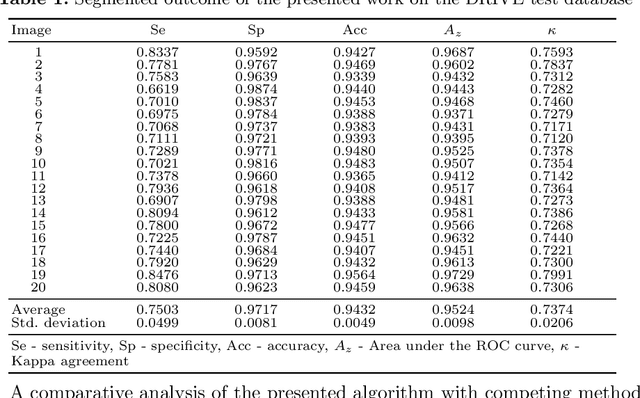

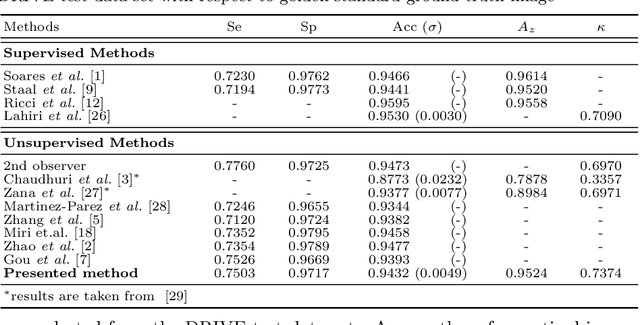
Automated segmentation of vascular map in retinal images endeavors a potential benefit in diagnostic procedure of different ocular diseases. In this paper, we suggest a new unsupervised retinal blood vessel segmentation approach using top-hat transformation, contrast-limited adaptive histogram equalization (CLAHE), and 2-D Gabor wavelet filters. Initially, retinal image is preprocessed using top-hat morphological transformation followed by CLAHE to enhance only the blood vessel pixels in the presence of exudates, optic disc, and fovea. Then, multiscale 2-D Gabor wavelet filters are applied on preprocessed image for better representation of thick and thin blood vessels located at different orientations. The efficacy of the presented algorithm is assessed on publicly available DRIVE database with manually labeled images. On DRIVE database, we achieve an average accuracy of 94.32% with a small standard deviation of 0.004. In comparison with major algorithms, our algorithm produces better performance concerning the accuracy, sensitivity, and kappa agreement.
Large-Scale Neuromorphic Spiking Array Processors: A quest to mimic the brain
May 23, 2018
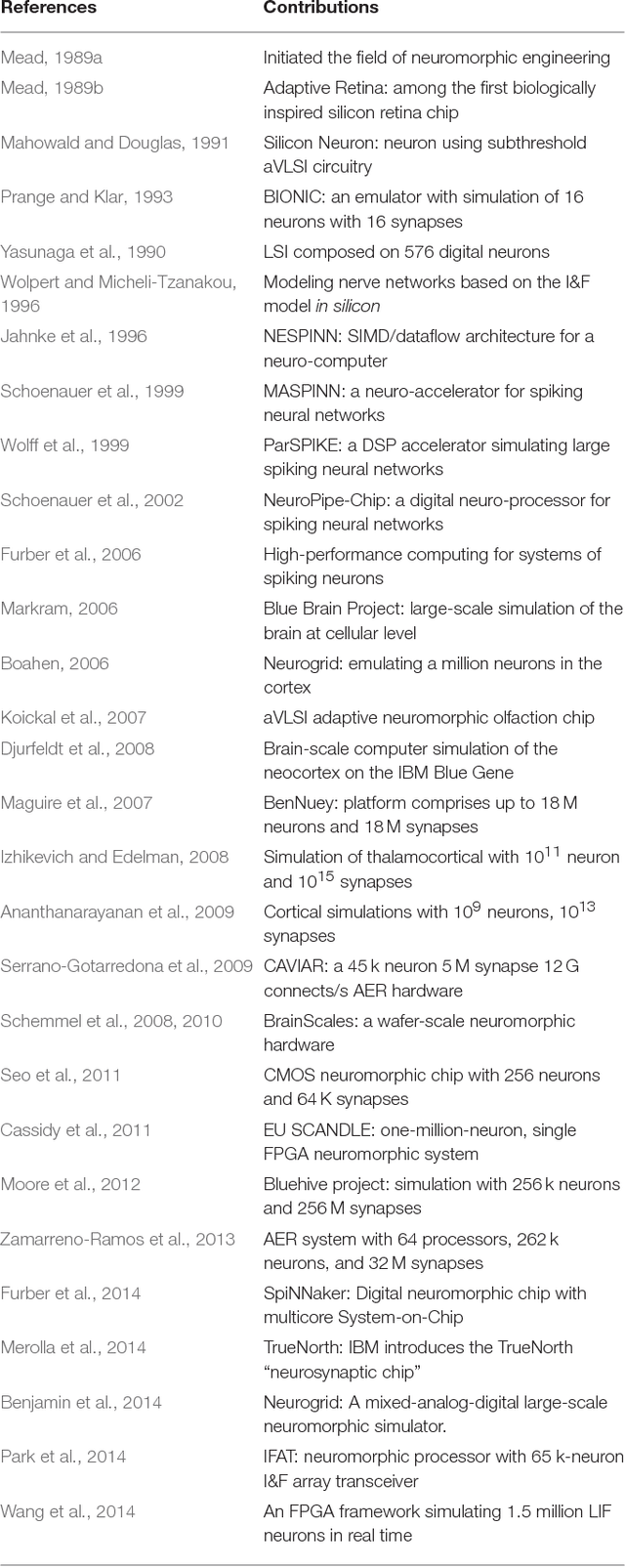
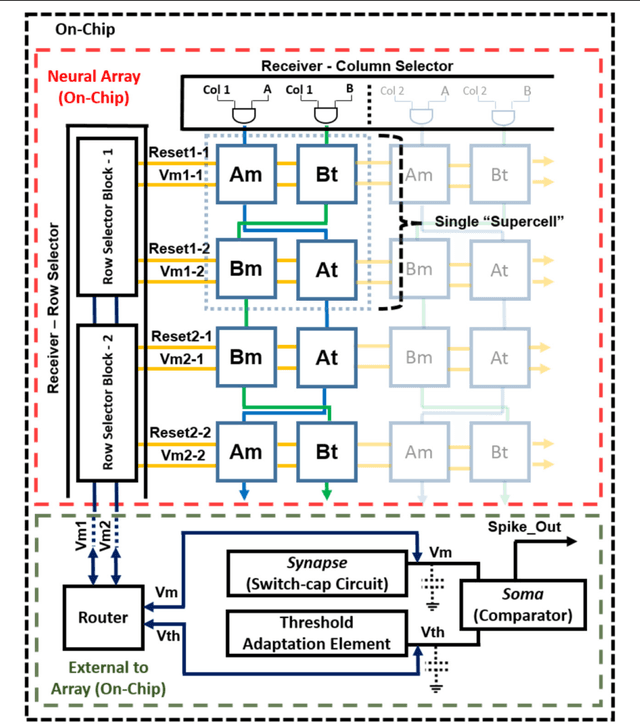
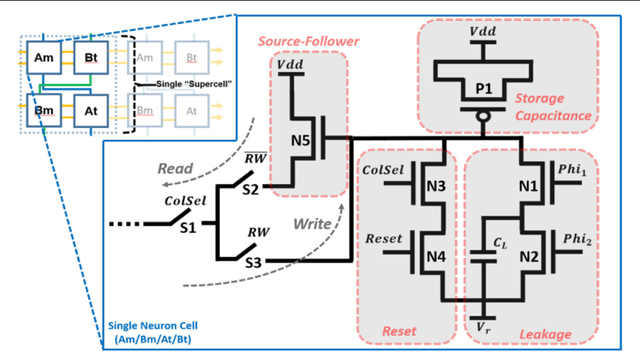
Neuromorphic engineering (NE) encompasses a diverse range of approaches to information processing that are inspired by neurobiological systems, and this feature distinguishes neuromorphic systems from conventional computing systems. The brain has evolved over billions of years to solve difficult engineering problems by using efficient, parallel, low-power computation. The goal of NE is to design systems capable of brain-like computation. Numerous large-scale neuromorphic projects have emerged recently. This interdisciplinary field was listed among the top 10 technology breakthroughs of 2014 by the MIT Technology Review and among the top 10 emerging technologies of 2015 by the World Economic Forum. NE has two-way goals: one, a scientific goal to understand the computational properties of biological neural systems by using models implemented in integrated circuits (ICs); second, an engineering goal to exploit the known properties of biological systems to design and implement efficient devices for engineering applications. Building hardware neural emulators can be extremely useful for simulating large-scale neural models to explain how intelligent behavior arises in the brain. The principle advantages of neuromorphic emulators are that they are highly energy efficient, parallel and distributed, and require a small silicon area. Thus, compared to conventional CPUs, these neuromorphic emulators are beneficial in many engineering applications such as for the porting of deep learning algorithms for various recognitions tasks. In this review article, we describe some of the most significant neuromorphic spiking emulators, compare the different architectures and approaches used by them, illustrate their advantages and drawbacks, and highlight the capabilities that each can deliver to neural modelers.
ObamaNet: Photo-realistic lip-sync from text
Dec 06, 2017
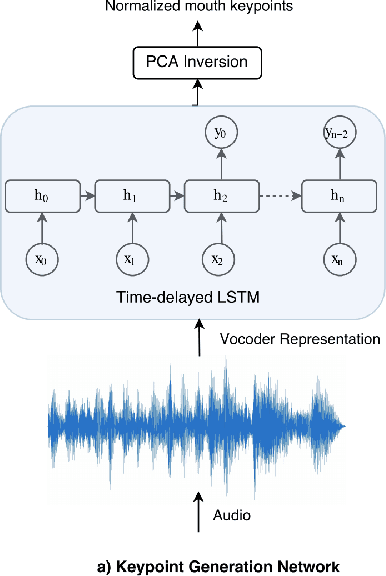
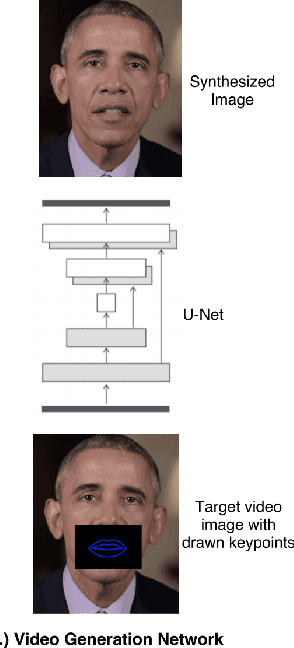

We present ObamaNet, the first architecture that generates both audio and synchronized photo-realistic lip-sync videos from any new text. Contrary to other published lip-sync approaches, ours is only composed of fully trainable neural modules and does not rely on any traditional computer graphics methods. More precisely, we use three main modules: a text-to-speech network based on Char2Wav, a time-delayed LSTM to generate mouth-keypoints synced to the audio, and a network based on Pix2Pix to generate the video frames conditioned on the keypoints.
SampleRNN: An Unconditional End-to-End Neural Audio Generation Model
Feb 11, 2017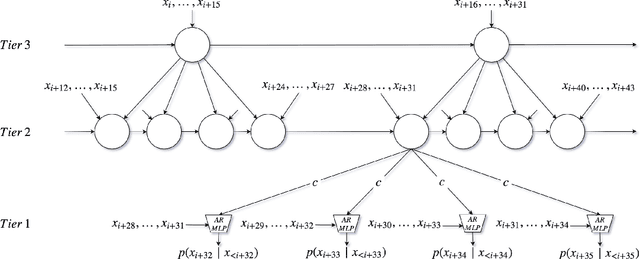

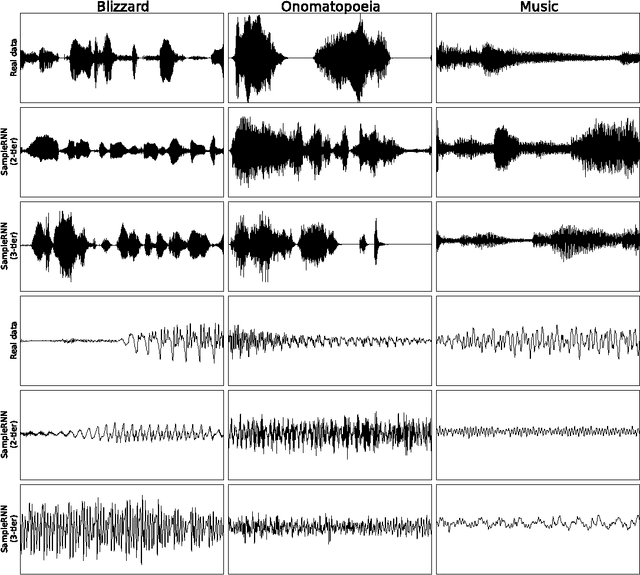
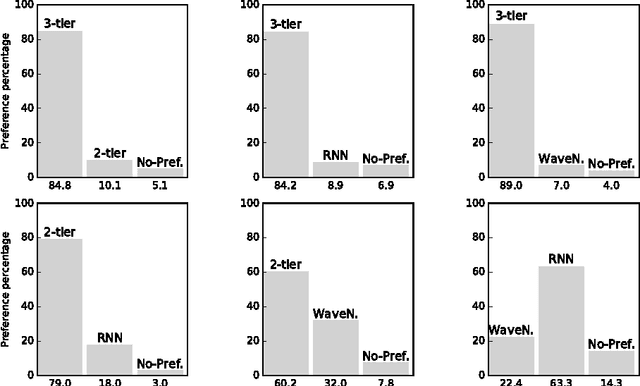
In this paper we propose a novel model for unconditional audio generation based on generating one audio sample at a time. We show that our model, which profits from combining memory-less modules, namely autoregressive multilayer perceptrons, and stateful recurrent neural networks in a hierarchical structure is able to capture underlying sources of variations in the temporal sequences over very long time spans, on three datasets of different nature. Human evaluation on the generated samples indicate that our model is preferred over competing models. We also show how each component of the model contributes to the exhibited performance.
On Random Weights for Texture Generation in One Layer Neural Networks
Dec 19, 2016
Recent work in the literature has shown experimentally that one can use the lower layers of a trained convolutional neural network (CNN) to model natural textures. More interestingly, it has also been experimentally shown that only one layer with random filters can also model textures although with less variability. In this paper we ask the question as to why one layer CNNs with random filters are so effective in generating textures? We theoretically show that one layer convolutional architectures (without a non-linearity) paired with the an energy function used in previous literature, can in fact preserve and modulate frequency coefficients in a manner so that random weights and pretrained weights will generate the same type of images. Based on the results of this analysis we question whether similar properties hold in the case where one uses one convolution layer with a non-linearity. We show that in the case of ReLu non-linearity there are situations where only one input will give the minimum possible energy whereas in the case of no nonlinearity, there are always infinite solutions that will give the minimum possible energy. Thus we can show that in certain situations adding a ReLu non-linearity generates less variable images.
PixelVAE: A Latent Variable Model for Natural Images
Nov 15, 2016
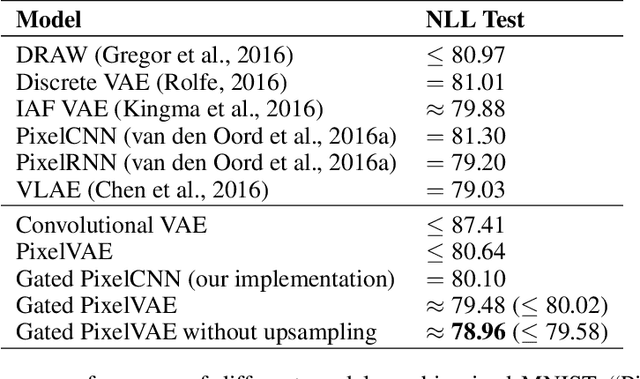


Natural image modeling is a landmark challenge of unsupervised learning. Variational Autoencoders (VAEs) learn a useful latent representation and model global structure well but have difficulty capturing small details. PixelCNN models details very well, but lacks a latent code and is difficult to scale for capturing large structures. We present PixelVAE, a VAE model with an autoregressive decoder based on PixelCNN. Our model requires very few expensive autoregressive layers compared to PixelCNN and learns latent codes that are more compressed than a standard VAE while still capturing most non-trivial structure. Finally, we extend our model to a hierarchy of latent variables at different scales. Our model achieves state-of-the-art performance on binarized MNIST, competitive performance on 64x64 ImageNet, and high-quality samples on the LSUN bedrooms dataset.