 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Stochastic Convex Optimization: Optimal Rates in $\ell_1$ Geometry
Mar 02, 2021
Stochastic convex optimization over an $\ell_1$-bounded domain is ubiquitous in machine learning applications such as LASSO but remains poorly understood when learning with differential privacy. We show that, up to logarithmic factors the optimal excess population loss of any $(\varepsilon,\delta)$-differentially private optimizer is $\sqrt{\log(d)/n} + \sqrt{d}/\varepsilon n.$ The upper bound is based on a new algorithm that combines the iterative localization approach of~\citet{FeldmanKoTa20} with a new analysis of private regularized mirror descent. It applies to $\ell_p$ bounded domains for $p\in [1,2]$ and queries at most $n^{3/2}$ gradients improving over the best previously known algorithm for the $\ell_2$ case which needs $n^2$ gradients. Further, we show that when the loss functions satisfy additional smoothness assumptions, the excess loss is upper bounded (up to logarithmic factors) by $\sqrt{\log(d)/n} + (\log(d)/\varepsilon n)^{2/3}.$ This bound is achieved by a new variance-reduced version of the Frank-Wolfe algorithm that requires just a single pass over the data. We also show that the lower bound in this case is the minimum of the two rates mentioned above.
Lossless Compression of Efficient Private Local Randomizers
Feb 24, 2021
Locally Differentially Private (LDP) Reports are commonly used for collection of statistics and machine learning in the federated setting. In many cases the best known LDP algorithms require sending prohibitively large messages from the client device to the server (such as when constructing histograms over large domain or learning a high-dimensional model). This has led to significant efforts on reducing the communication cost of LDP algorithms. At the same time LDP reports are known to have relatively little information about the user's data due to randomization. Several schemes are known that exploit this fact to design low-communication versions of LDP algorithm but all of them do so at the expense of a significant loss in utility. Here we demonstrate a general approach that, under standard cryptographic assumptions, compresses every efficient LDP algorithm with negligible loss in privacy and utility guarantees. The practical implication of our result is that in typical applications the message can be compressed to the size of the server's pseudo-random generator seed. More generally, we relate the properties of an LDP randomizer to the power of a pseudo-random generator that suffices for compressing the LDP randomizer. From this general approach we derive low-communication algorithms for the problems of frequency estimation and high-dimensional mean estimation. Our algorithms are simpler and more accurate than existing low-communication LDP algorithms for these well-studied problems.
Hiding Among the Clones: A Simple and Nearly Optimal Analysis of Privacy Amplification by Shuffling
Dec 25, 2020
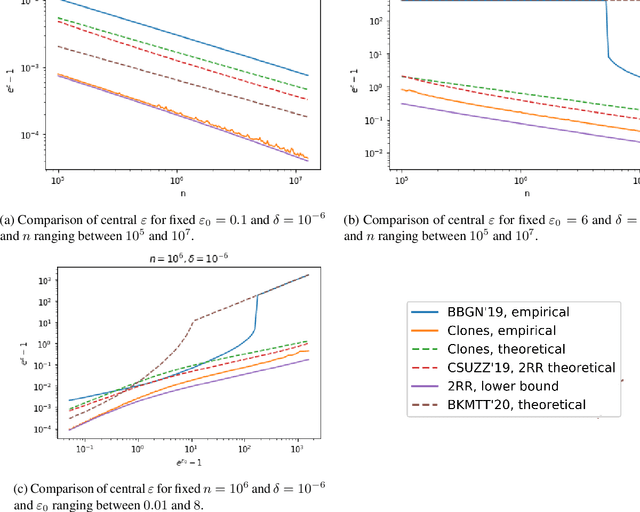
Recent work of Erlingsson, Feldman, Mironov, Raghunathan, Talwar, and Thakurta [EFMRTT19] demonstrates that random shuffling amplifies differential privacy guarantees of locally randomized data. Such amplification implies substantially stronger privacy guarantees for systems in which data is contributed anonymously [BEMMRLRKTS17] and has lead to significant interest in the shuffle model of privacy [CSUZZ19,EFMRTT19]. We show that random shuffling of $n$ data records that are input to $\varepsilon_0$-differentially private local randomizers results in an $(O((1-e^{-\varepsilon_0})\sqrt{\frac{e^{\varepsilon_0}\log(1/\delta)}{n}}), \delta)$-differentially private algorithm. This significantly improves over previous work and achieves the asymptotically optimal dependence in $\varepsilon_0$. Our result is based on a new approach that is simpler than previous work and extends to approximate differential privacy with nearly the same guarantees. Our work also yields an empirical method to derive tighter bounds the resulting $\varepsilon$ and we show that it gets to within a small constant factor of the optimal bound. As a direct corollary of our analysis, we derive a simple and asymptotically optimal algorithm for discrete distribution estimation in the shuffle model of privacy. We also observe that our result implies the first asymptotically optimal privacy analysis of noisy stochastic gradient descent that applies to sampling without replacement.
When is Memorization of Irrelevant Training Data Necessary for High-Accuracy Learning?
Dec 11, 2020
Modern machine learning models are complex and frequently encode surprising amounts of information about individual inputs. In extreme cases, complex models appear to memorize entire input examples, including seemingly irrelevant information (social security numbers from text, for example). In this paper, we aim to understand whether this sort of memorization is necessary for accurate learning. We describe natural prediction problems in which every sufficiently accurate training algorithm must encode, in the prediction model, essentially all the information about a large subset of its training examples. This remains true even when the examples are high-dimensional and have entropy much higher than the sample size, and even when most of that information is ultimately irrelevant to the task at hand. Further, our results do not depend on the training algorithm or the class of models used for learning. Our problems are simple and fairly natural variants of the next-symbol prediction and the cluster labeling tasks. These tasks can be seen as abstractions of image- and text-related prediction problems. To establish our results, we reduce from a family of one-way communication problems for which we prove new information complexity lower bounds.
On the Error Resistance of Hinge Loss Minimization
Dec 02, 2020Commonly used classification algorithms in machine learning, such as support vector machines, minimize a convex surrogate loss on training examples. In practice, these algorithms are surprisingly robust to errors in the training data. In this work, we identify a set of conditions on the data under which such surrogate loss minimization algorithms provably learn the correct classifier. This allows us to establish, in a unified framework, the robustness of these algorithms under various models on data as well as error. In particular, we show that if the data is linearly classifiable with a slightly non-trivial margin (i.e. a margin at least $C/\sqrt{d}$ for $d$-dimensional unit vectors), and the class-conditional distributions are near isotropic and logconcave, then surrogate loss minimization has negligible error on the uncorrupted data even when a constant fraction of examples are adversarially mislabeled.
Faster Differentially Private Samplers via Rényi Divergence Analysis of Discretized Langevin MCMC
Oct 27, 2020
Various differentially private algorithms instantiate the exponential mechanism, and require sampling from the distribution $\exp(-f)$ for a suitable function $f$. When the domain of the distribution is high-dimensional, this sampling can be computationally challenging. Using heuristic sampling schemes such as Gibbs sampling does not necessarily lead to provable privacy. When $f$ is convex, techniques from log-concave sampling lead to polynomial-time algorithms, albeit with large polynomials. Langevin dynamics-based algorithms offer much faster alternatives under some distance measures such as statistical distance. In this work, we establish rapid convergence for these algorithms under distance measures more suitable for differential privacy. For smooth, strongly-convex $f$, we give the first results proving convergence in R\'enyi divergence. This gives us fast differentially private algorithms for such $f$. Our techniques and simple and generic and apply also to underdamped Langevin dynamics.
Stochastic Optimization with Laggard Data Pipelines
Oct 26, 2020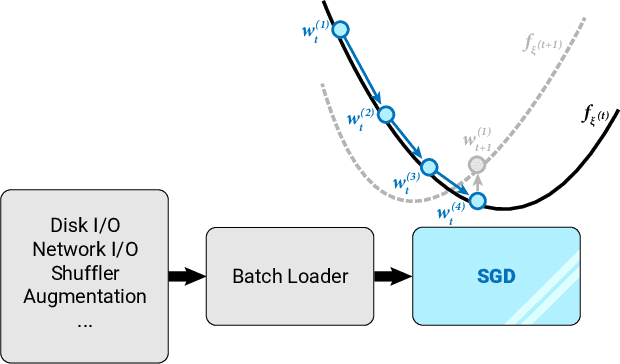
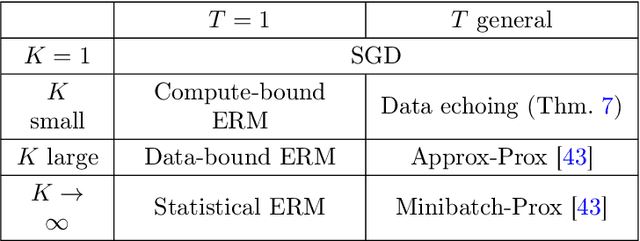
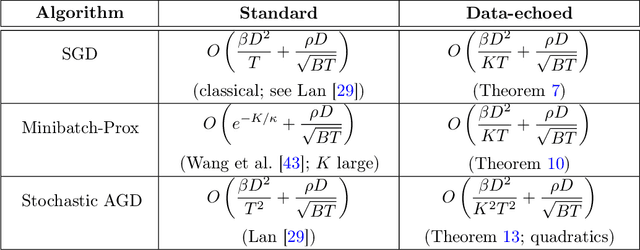
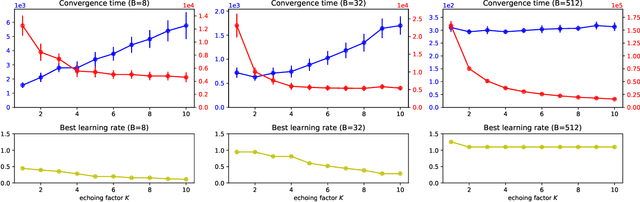
State-of-the-art optimization is steadily shifting towards massively parallel pipelines with extremely large batch sizes. As a consequence, CPU-bound preprocessing and disk/memory/network operations have emerged as new performance bottlenecks, as opposed to hardware-accelerated gradient computations. In this regime, a recently proposed approach is data echoing (Choi et al., 2019), which takes repeated gradient steps on the same batch while waiting for fresh data to arrive from upstream. We provide the first convergence analyses of "data-echoed" extensions of common optimization methods, showing that they exhibit provable improvements over their synchronous counterparts. Specifically, we show that in convex optimization with stochastic minibatches, data echoing affords speedups on the curvature-dominated part of the convergence rate, while maintaining the optimal statistical rate.
Stability of Stochastic Gradient Descent on Nonsmooth Convex Losses
Jun 12, 2020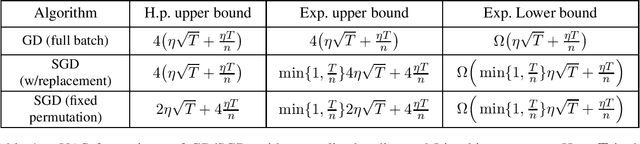
Uniform stability is a notion of algorithmic stability that bounds the worst case change in the model output by the algorithm when a single data point in the dataset is replaced. An influential work of Hardt et al. (2016) provides strong upper bounds on the uniform stability of the stochastic gradient descent (SGD) algorithm on sufficiently smooth convex losses. These results led to important progress in understanding of the generalization properties of SGD and several applications to differentially private convex optimization for smooth losses. Our work is the first to address uniform stability of SGD on {\em nonsmooth} convex losses. Specifically, we provide sharp upper and lower bounds for several forms of SGD and full-batch GD on arbitrary Lipschitz nonsmooth convex losses. Our lower bounds show that, in the nonsmooth case, (S)GD can be inherently less stable than in the smooth case. On the other hand, our upper bounds show that (S)GD is sufficiently stable for deriving new and useful bounds on generalization error. Most notably, we obtain the first dimension-independent generalization bounds for multi-pass SGD in the nonsmooth case. In addition, our bounds allow us to derive a new algorithm for differentially private nonsmooth stochastic convex optimization with optimal excess population risk. Our algorithm is simpler and more efficient than the best known algorithm for the nonsmooth case Feldman et al. (2020).
Private Stochastic Convex Optimization: Optimal Rates in Linear Time
May 10, 2020We study differentially private (DP) algorithms for stochastic convex optimization: the problem of minimizing the population loss given i.i.d. samples from a distribution over convex loss functions. A recent work of Bassily et al. (2019) has established the optimal bound on the excess population loss achievable given $n$ samples. Unfortunately, their algorithm achieving this bound is relatively inefficient: it requires $O(\min\{n^{3/2}, n^{5/2}/d\})$ gradient computations, where $d$ is the dimension of the optimization problem. We describe two new techniques for deriving DP convex optimization algorithms both achieving the optimal bound on excess loss and using $O(\min\{n, n^2/d\})$ gradient computations. In particular, the algorithms match the running time of the optimal non-private algorithms. The first approach relies on the use of variable batch sizes and is analyzed using the privacy amplification by iteration technique of Feldman et al. (2018). The second approach is based on a general reduction to the problem of localizing an approximately optimal solution with differential privacy. Such localization, in turn, can be achieved using existing (non-private) uniformly stable optimization algorithms. As in the earlier work, our algorithms require a mild smoothness assumption. We also give a linear-time algorithm achieving the optimal bound on the excess loss for the strongly convex case, as well as a faster algorithm for the non-smooth case.
Exploring the Memorization-Generalization Continuum in Deep Learning
Feb 08, 2020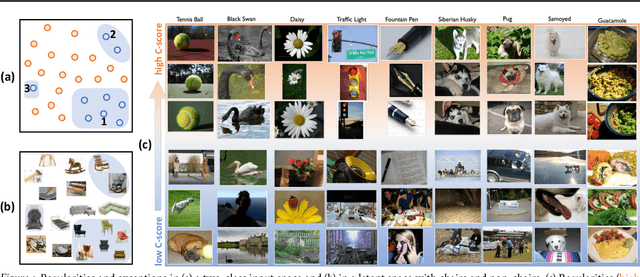
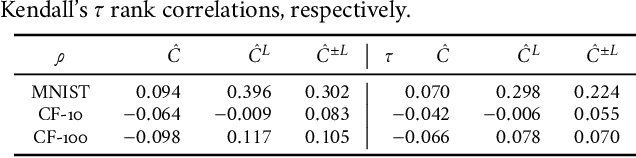
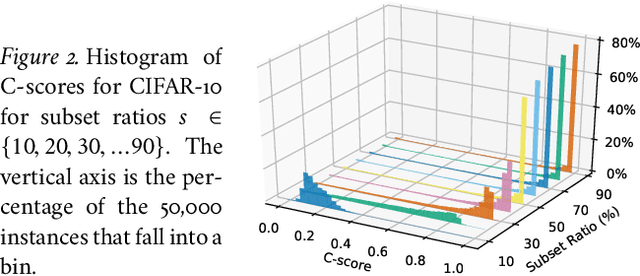
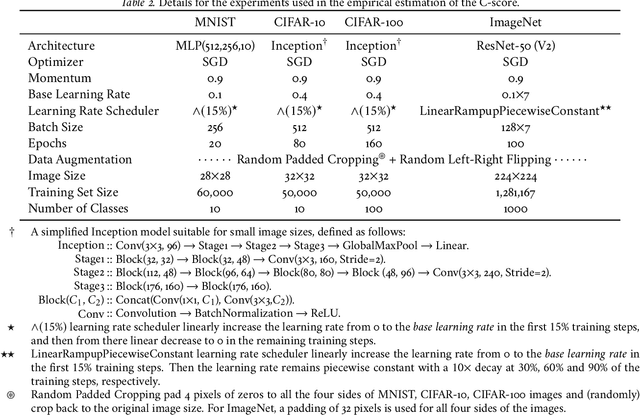
Human learners appreciate that some facts demand memorization whereas other facts support generalization. For example, English verbs have irregular cases that must be memorized (e.g., go->went) and regular cases that generalize well (e.g., kiss->kissed, miss->missed). Likewise, deep neural networks have the capacity to memorize rare or irregular forms but nonetheless generalize across instances that share common patterns or structures. We analyze how individual instances are treated by a model on the memorization-generalization continuum via a consistency score. The score is the expected accuracy of a particular architecture for a held-out instance on a training set of a fixed size sampled from the data distribution. We obtain empirical estimates of this score for individual instances in multiple datasets, and we show that the score identifies out-of-distribution and mislabeled examples at one end of the continuum and regular examples at the other end. We explore three proxies to the consistency score: kernel density estimation on input and hidden representations; and the time course of training, i.e., learning speed. In addition to helping to understand the memorization versus generalization dynamics during training, the C-score proxies have potential application for out-of-distribution detection, curriculum learning, and active data collection.