 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubspace Recovery from Heterogeneous Data with Non-isotropic Noise
Oct 24, 2022Recovering linear subspaces from data is a fundamental and important task in statistics and machine learning. Motivated by heterogeneity in Federated Learning settings, we study a basic formulation of this problem: the principal component analysis (PCA), with a focus on dealing with irregular noise. Our data come from $n$ users with user $i$ contributing data samples from a $d$-dimensional distribution with mean $\mu_i$. Our goal is to recover the linear subspace shared by $\mu_1,\ldots,\mu_n$ using the data points from all users, where every data point from user $i$ is formed by adding an independent mean-zero noise vector to $\mu_i$. If we only have one data point from every user, subspace recovery is information-theoretically impossible when the covariance matrices of the noise vectors can be non-spherical, necessitating additional restrictive assumptions in previous work. We avoid these assumptions by leveraging at least two data points from each user, which allows us to design an efficiently-computable estimator under non-spherical and user-dependent noise. We prove an upper bound for the estimation error of our estimator in general scenarios where the number of data points and amount of noise can vary across users, and prove an information-theoretic error lower bound that not only matches the upper bound up to a constant factor, but also holds even for spherical Gaussian noise. This implies that our estimator does not introduce additional estimation error (up to a constant factor) due to irregularity in the noise. We show additional results for a linear regression problem in a similar setup.
Private Online Prediction from Experts: Separations and Faster Rates
Oct 24, 2022Online prediction from experts is a fundamental problem in machine learning and several works have studied this problem under privacy constraints. We propose and analyze new algorithms for this problem that improve over the regret bounds of the best existing algorithms for non-adaptive adversaries. For approximate differential privacy, our algorithms achieve regret bounds of $\tilde{O}(\sqrt{T \log d} + \log d/\varepsilon)$ for the stochastic setting and $\tilde O(\sqrt{T \log d} + T^{1/3} \log d/\varepsilon)$ for oblivious adversaries (where $d$ is the number of experts). For pure DP, our algorithms are the first to obtain sub-linear regret for oblivious adversaries in the high-dimensional regime $d \ge T$. Moreover, we prove new lower bounds for adaptive adversaries. Our results imply that unlike the non-private setting, there is a strong separation between the optimal regret for adaptive and non-adaptive adversaries for this problem. Our lower bounds also show a separation between pure and approximate differential privacy for adaptive adversaries where the latter is necessary to achieve the non-private $O(\sqrt{T})$ regret.
Resolving the Mixing Time of the Langevin Algorithm to its Stationary Distribution for Log-Concave Sampling
Oct 16, 2022
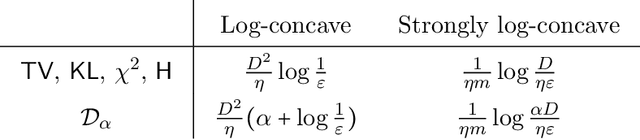
Sampling from a high-dimensional distribution is a fundamental task in statistics, engineering, and the sciences. A particularly canonical approach is the Langevin Algorithm, i.e., the Markov chain for the discretized Langevin Diffusion. This is the sampling analog of Gradient Descent. Despite being studied for several decades in multiple communities, tight mixing bounds for this algorithm remain unresolved even in the seemingly simple setting of log-concave distributions over a bounded domain. This paper completely characterizes the mixing time of the Langevin Algorithm to its stationary distribution in this setting (and others). This mixing result can be combined with any bound on the discretization bias in order to sample from the stationary distribution of the continuous Langevin Diffusion. In this way, we disentangle the study of the mixing and bias of the Langevin Algorithm. Our key insight is to introduce a technique from the differential privacy literature to the sampling literature. This technique, called Privacy Amplification by Iteration, uses as a potential a variant of R\'enyi divergence that is made geometrically aware via Optimal Transport smoothing. This gives a short, simple proof of optimal mixing bounds and has several additional appealing properties. First, our approach removes all unnecessary assumptions required by other sampling analyses. Second, our approach unifies many settings: it extends unchanged if the Langevin Algorithm uses projections, stochastic mini-batch gradients, or strongly convex potentials (whereby our mixing time improves exponentially). Third, our approach exploits convexity only through the contractivity of a gradient step -- reminiscent of how convexity is used in textbook proofs of Gradient Descent. In this way, we offer a new approach towards further unifying the analyses of optimization and sampling algorithms.
Stronger Privacy Amplification by Shuffling for Rényi and Approximate Differential Privacy
Aug 09, 2022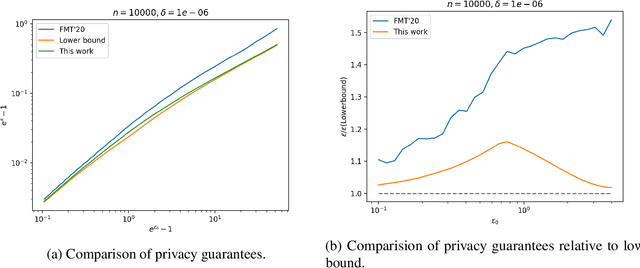
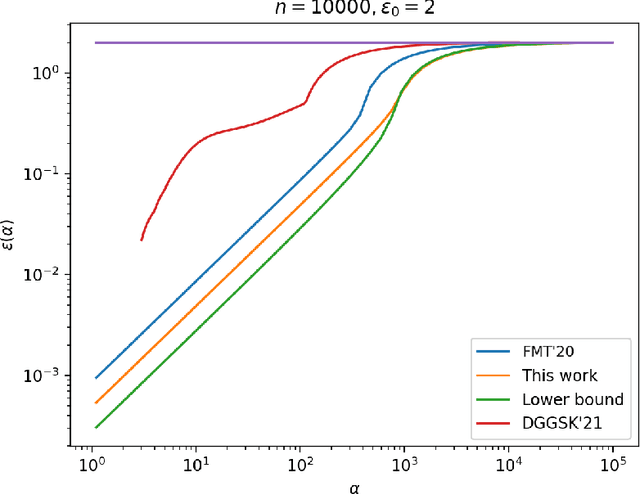
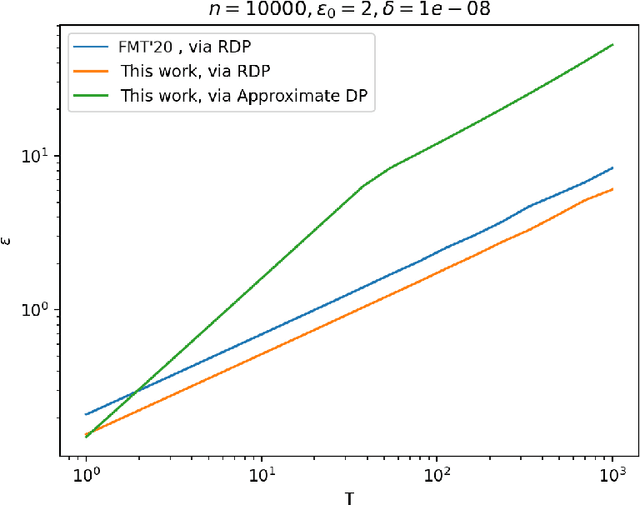
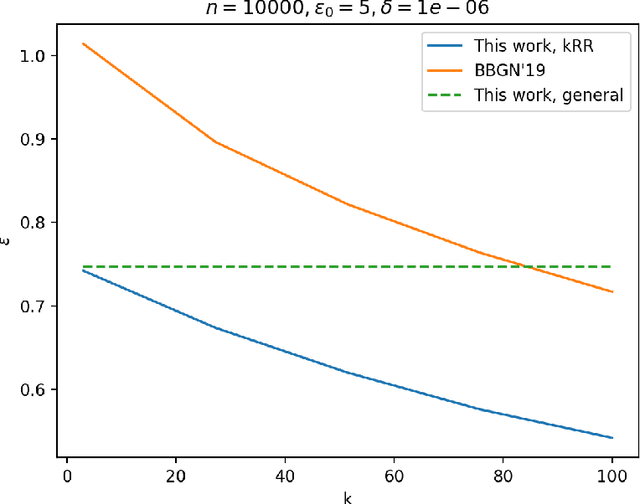
The shuffle model of differential privacy has gained significant interest as an intermediate trust model between the standard local and central models [EFMRTT19; CSUZZ19]. A key result in this model is that randomly shuffling locally randomized data amplifies differential privacy guarantees. Such amplification implies substantially stronger privacy guarantees for systems in which data is contributed anonymously [BEMMRLRKTS17]. In this work, we improve the state of the art privacy amplification by shuffling results both theoretically and numerically. Our first contribution is the first asymptotically optimal analysis of the R\'enyi differential privacy parameters for the shuffled outputs of LDP randomizers. Our second contribution is a new analysis of privacy amplification by shuffling. This analysis improves on the techniques of [FMT20] and leads to tighter numerical bounds in all parameter settings.
FLAIR: Federated Learning Annotated Image Repository
Jul 18, 2022
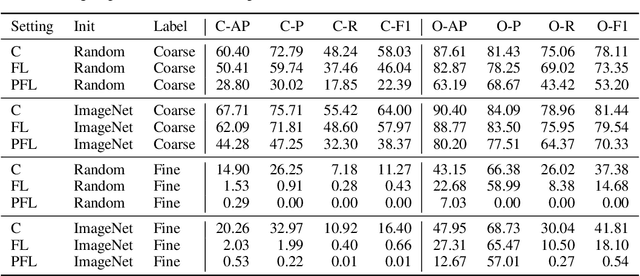
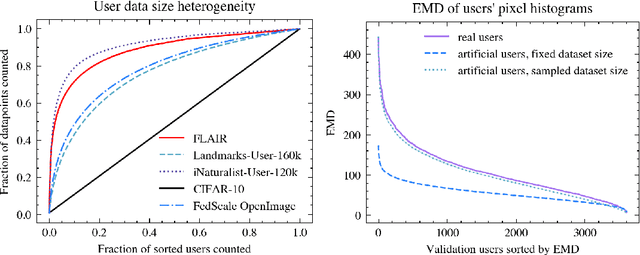
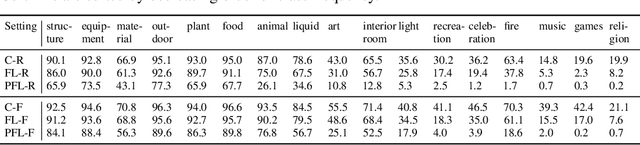
Cross-device federated learning is an emerging machine learning (ML) paradigm where a large population of devices collectively train an ML model while the data remains on the devices. This research field has a unique set of practical challenges, and to systematically make advances, new datasets curated to be compatible with this paradigm are needed. Existing federated learning benchmarks in the image domain do not accurately capture the scale and heterogeneity of many real-world use cases. We introduce FLAIR, a challenging large-scale annotated image dataset for multi-label classification suitable for federated learning. FLAIR has 429,078 images from 51,414 Flickr users and captures many of the intricacies typically encountered in federated learning, such as heterogeneous user data and a long-tailed label distribution. We implement multiple baselines in different learning setups for different tasks on this dataset. We believe FLAIR can serve as a challenging benchmark for advancing the state-of-the art in federated learning. Dataset access and the code for the benchmark are available at \url{https://github.com/apple/ml-flair}.
Privacy of Noisy Stochastic Gradient Descent: More Iterations without More Privacy Loss
May 27, 2022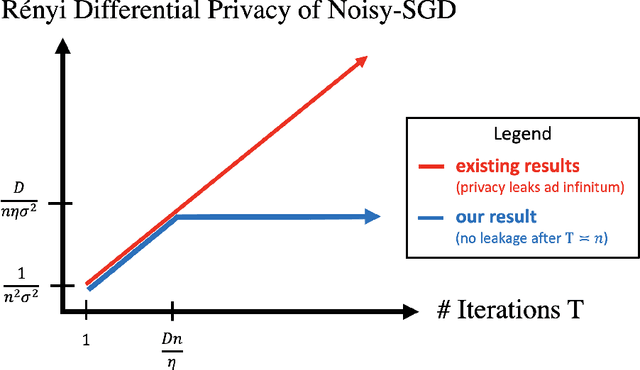
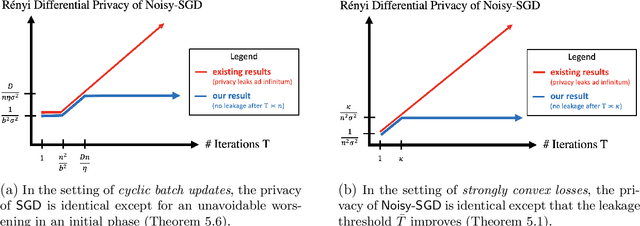
A central issue in machine learning is how to train models on sensitive user data. Industry has widely adopted a simple algorithm: Stochastic Gradient Descent with noise (a.k.a. Stochastic Gradient Langevin Dynamics). However, foundational theoretical questions about this algorithm's privacy loss remain open -- even in the seemingly simple setting of smooth convex losses over a bounded domain. Our main result resolves these questions: for a large range of parameters, we characterize the differential privacy up to a constant factor. This result reveals that all previous analyses for this setting have the wrong qualitative behavior. Specifically, while previous privacy analyses increase ad infinitum in the number of iterations, we show that after a small burn-in period, running SGD longer leaks no further privacy. Our analysis departs completely from previous approaches based on fast mixing, instead using techniques based on optimal transport (namely, Privacy Amplification by Iteration) and the Sampled Gaussian Mechanism (namely, Privacy Amplification by Sampling). Our techniques readily extend to other settings, e.g., strongly convex losses, non-uniform stepsizes, arbitrary batch sizes, and random or cyclic choice of batches.
Optimal Algorithms for Mean Estimation under Local Differential Privacy
May 05, 2022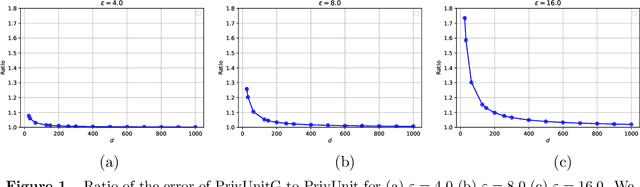
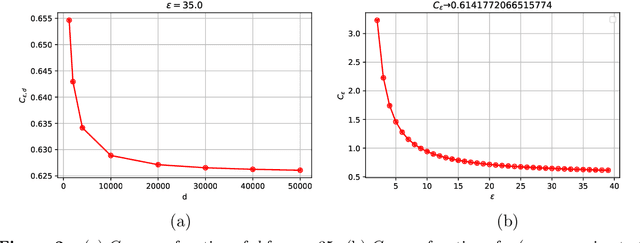
We study the problem of mean estimation of $\ell_2$-bounded vectors under the constraint of local differential privacy. While the literature has a variety of algorithms that achieve the asymptotically optimal rates for this problem, the performance of these algorithms in practice can vary significantly due to varying (and often large) hidden constants. In this work, we investigate the question of designing the protocol with the smallest variance. We show that PrivUnit (Bhowmick et al. 2018) with optimized parameters achieves the optimal variance among a large family of locally private randomizers. To prove this result, we establish some properties of local randomizers, and use symmetrization arguments that allow us to write the optimal randomizer as the optimizer of a certain linear program. These structural results, which should extend to other problems, then allow us to show that the optimal randomizer belongs to the PrivUnit family. We also develop a new variant of PrivUnit based on the Gaussian distribution which is more amenable to mathematical analysis and enjoys the same optimality guarantees. This allows us to establish several useful properties on the exact constants of the optimal error as well as to numerically estimate these constants.
Private Frequency Estimation via Projective Geometry
Mar 01, 2022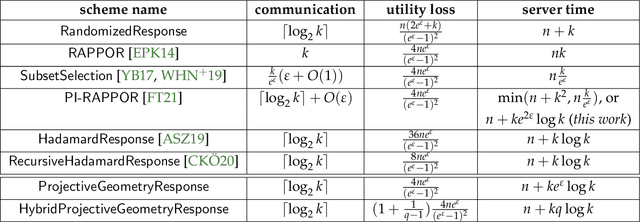
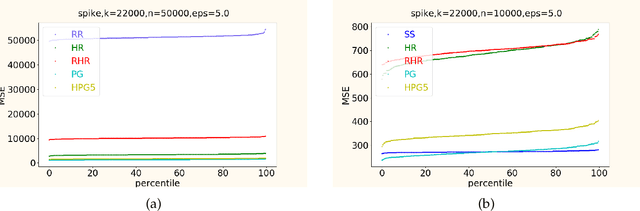
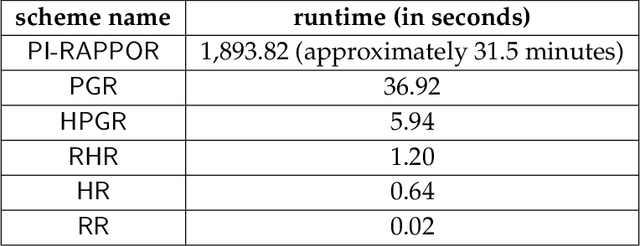
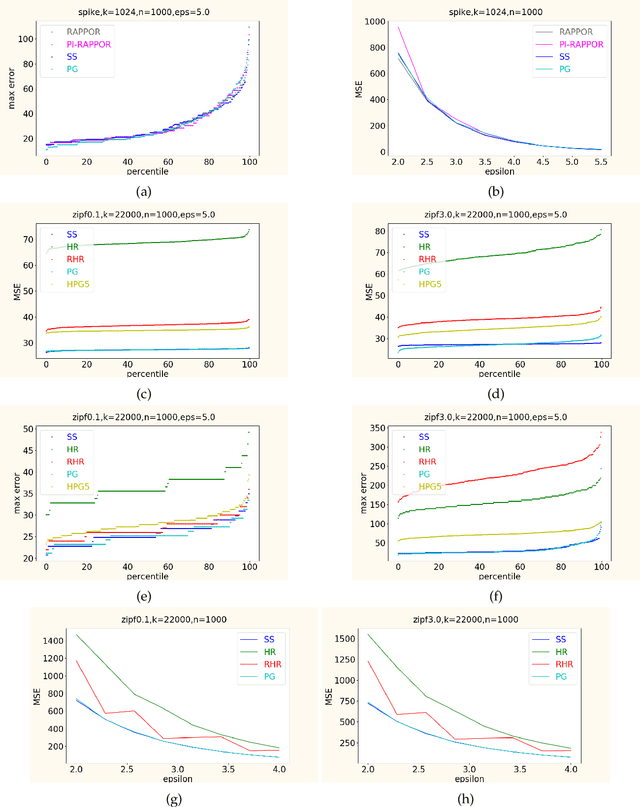
In this work, we propose a new algorithm ProjectiveGeometryResponse (PGR) for locally differentially private (LDP) frequency estimation. For a universe size of $k$ and with $n$ users, our $\varepsilon$-LDP algorithm has communication cost $\lceil\log_2k\rceil$ bits in the private coin setting and $\varepsilon\log_2 e + O(1)$ in the public coin setting, and has computation cost $O(n + k\exp(\varepsilon) \log k)$ for the server to approximately reconstruct the frequency histogram, while achieving the state-of-the-art privacy-utility tradeoff. In many parameter settings used in practice this is a significant improvement over the $ O(n+k^2)$ computation cost that is achieved by the recent PI-RAPPOR algorithm (Feldman and Talwar; 2021). Our empirical evaluation shows a speedup of over 50x over PI-RAPPOR while using approximately 75x less memory for practically relevant parameter settings. In addition, the running time of our algorithm is within an order of magnitude of HadamardResponse (Acharya, Sun, and Zhang; 2019) and RecursiveHadamardResponse (Chen, Kairouz, and Ozgur; 2020) which have significantly worse reconstruction error. The error of our algorithm essentially matches that of the communication- and time-inefficient but utility-optimal SubsetSelection (SS) algorithm (Ye and Barg; 2017). Our new algorithm is based on using Projective Planes over a finite field to define a small collection of sets that are close to being pairwise independent and a dynamic programming algorithm for approximate histogram reconstruction on the server side. We also give an extension of PGR, which we call HybridProjectiveGeometryResponse, that allows trading off computation time with utility smoothly.
Differential Secrecy for Distributed Data and Applications to Robust Differentially Secure Vector Summation
Feb 22, 2022Computing the noisy sum of real-valued vectors is an important primitive in differentially private learning and statistics. In private federated learning applications, these vectors are held by client devices, leading to a distributed summation problem. Standard Secure Multiparty Computation (SMC) protocols for this problem are susceptible to poisoning attacks, where a client may have a large influence on the sum, without being detected. In this work, we propose a poisoning-robust private summation protocol in the multiple-server setting, recently studied in PRIO. We present a protocol for vector summation that verifies that the Euclidean norm of each contribution is approximately bounded. We show that by relaxing the security constraint in SMC to a differential privacy like guarantee, one can improve over PRIO in terms of communication requirements as well as the client-side computation. Unlike SMC algorithms that inevitably cast integers to elements of a large finite field, our algorithms work over integers/reals, which may allow for additional efficiencies.
Private Adaptive Gradient Methods for Convex Optimization
Jun 25, 2021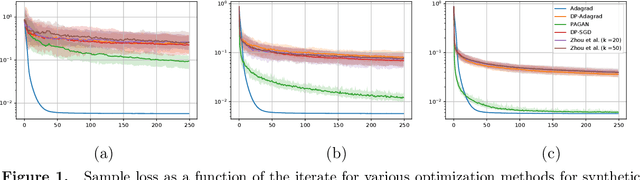

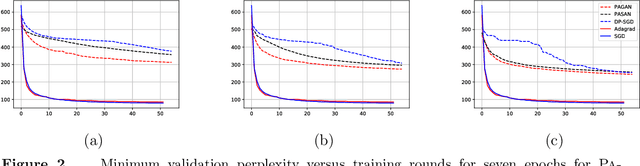
We study adaptive methods for differentially private convex optimization, proposing and analyzing differentially private variants of a Stochastic Gradient Descent (SGD) algorithm with adaptive stepsizes, as well as the AdaGrad algorithm. We provide upper bounds on the regret of both algorithms and show that the bounds are (worst-case) optimal. As a consequence of our development, we show that our private versions of AdaGrad outperform adaptive SGD, which in turn outperforms traditional SGD in scenarios with non-isotropic gradients where (non-private) Adagrad provably outperforms SGD. The major challenge is that the isotropic noise typically added for privacy dominates the signal in gradient geometry for high-dimensional problems; approaches to this that effectively optimize over lower-dimensional subspaces simply ignore the actual problems that varying gradient geometries introduce. In contrast, we study non-isotropic clipping and noise addition, developing a principled theoretical approach; the consequent procedures also enjoy significantly stronger empirical performance than prior approaches.