 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOFEN: Deep Oblivious Forest ENsemble
Dec 24, 2024



Deep Neural Networks (DNNs) have revolutionized artificial intelligence, achieving impressive results on diverse data types, including images, videos, and texts. However, DNNs still lag behind Gradient Boosting Decision Trees (GBDT) on tabular data, a format extensively utilized across various domains. In this paper, we propose DOFEN, short for \textbf{D}eep \textbf{O}blivious \textbf{F}orest \textbf{EN}semble, a novel DNN architecture inspired by oblivious decision trees. DOFEN constructs relaxed oblivious decision trees (rODTs) by randomly combining conditions for each column and further enhances performance with a two-level rODT forest ensembling process. By employing this approach, DOFEN achieves state-of-the-art results among DNNs and further narrows the gap between DNNs and tree-based models on the well-recognized benchmark: Tabular Benchmark \citep{grinsztajn2022tree}, which includes 73 total datasets spanning a wide array of domains. The code of DOFEN is available at: \url{https://github.com/Sinopac-Digital-Technology-Division/DOFEN}.
An Attention-based Framework with Multistation Information for Earthquake Early Warnings
Dec 24, 2024



Earthquake early warning systems play crucial roles in reducing the risk of seismic disasters. Previously, the dominant modeling system was the single-station models. Such models digest signal data received at a given station and predict earth-quake parameters, such as the p-phase arrival time, intensity, and magnitude at that location. Various methods have demonstrated adequate performance. However, most of these methods present the challenges of the difficulty of speeding up the alarm time, providing early warning for distant areas, and considering global information to enhance performance. Recently, deep learning has significantly impacted many fields, including seismology. Thus, this paper proposes a deep learning-based framework, called SENSE, for the intensity prediction task of earthquake early warning systems. To explicitly consider global information from a regional or national perspective, the input to SENSE comprises statistics from a set of stations in a given region or country. The SENSE model is designed to learn the relationships among the set of input stations and the locality-specific characteristics of each station. Thus, SENSE is not only expected to provide more reliable forecasts by considering multistation data but also has the ability to provide early warnings to distant areas that have not yet received signals. This study conducted extensive experiments on datasets from Taiwan and Japan. The results revealed that SENSE can deliver competitive or even better performances compared with other state-of-the-art methods.
Abnormal Respiratory Sound Identification Using Audio-Spectrogram Vision Transformer
May 14, 2024


Respiratory disease, the third leading cause of deaths globally, is considered a high-priority ailment requiring significant research on identification and treatment. Stethoscope-recorded lung sounds and artificial intelligence-powered devices have been used to identify lung disorders and aid specialists in making accurate diagnoses. In this study, audio-spectrogram vision transformer (AS-ViT), a new approach for identifying abnormal respiration sounds, was developed. The sounds of the lungs are converted into visual representations called spectrograms using a technique called short-time Fourier transform (STFT). These images are then analyzed using a model called vision transformer to identify different types of respiratory sounds. The classification was carried out using the ICBHI 2017 database, which includes various types of lung sounds with different frequencies, noise levels, and backgrounds. The proposed AS-ViT method was evaluated using three metrics and achieved 79.1% and 59.8% for 60:40 split ratio and 86.4% and 69.3% for 80:20 split ratio in terms of unweighted average recall and overall scores respectively for respiratory sound detection, surpassing previous state-of-the-art results.
* Published in 2023 45th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC)
HypR: A comprehensive study for ASR hypothesis revising with a reference corpus
Sep 19, 2023

With the development of deep learning, automatic speech recognition (ASR) has made significant progress. To further enhance the performance, revising recognition results is one of the lightweight but efficient manners. Various methods can be roughly classified into N-best reranking methods and error correction models. The former aims to select the hypothesis with the lowest error rate from a set of candidates generated by ASR for a given input speech. The latter focuses on detecting recognition errors in a given hypothesis and correcting these errors to obtain an enhanced result. However, we observe that these studies are hardly comparable to each other as they are usually evaluated on different corpora, paired with different ASR models, and even use different datasets to train the models. Accordingly, we first concentrate on releasing an ASR hypothesis revising (HypR) dataset in this study. HypR contains several commonly used corpora (AISHELL-1, TED-LIUM 2, and LibriSpeech) and provides 50 recognition hypotheses for each speech utterance. The checkpoint models of the ASR are also published. In addition, we implement and compare several classic and representative methods, showing the recent research progress in revising speech recognition results. We hope the publicly available HypR dataset can become a reference benchmark for subsequent research and promote the school of research to an advanced level.
Trompt: Towards a Better Deep Neural Network for Tabular Data
May 31, 2023



Tabular data is arguably one of the most commonly used data structures in various practical domains, including finance, healthcare and e-commerce. The inherent heterogeneity allows tabular data to store rich information. However, based on a recently published tabular benchmark, we can see deep neural networks still fall behind tree-based models on tabular datasets. In this paper, we propose Trompt--which stands for Tabular Prompt--a novel architecture inspired by prompt learning of language models. The essence of prompt learning is to adjust a large pre-trained model through a set of prompts outside the model without directly modifying the model. Based on this idea, Trompt separates the learning strategy of tabular data into two parts. The first part, analogous to pre-trained models, focus on learning the intrinsic information of a table. The second part, analogous to prompts, focus on learning the variations among samples. Trompt is evaluated with the benchmark mentioned above. The experimental results demonstrate that Trompt outperforms state-of-the-art deep neural networks and is comparable to tree-based models.
A Lexical-aware Non-autoregressive Transformer-based ASR Model
May 18, 2023


Non-autoregressive automatic speech recognition (ASR) has become a mainstream of ASR modeling because of its fast decoding speed and satisfactory result. To further boost the performance, relaxing the conditional independence assumption and cascading large-scaled pre-trained models are two active research directions. In addition to these strategies, we propose a lexical-aware non-autoregressive Transformer-based (LA-NAT) ASR framework, which consists of an acoustic encoder, a speech-text shared encoder, and a speech-text shared decoder. The acoustic encoder is used to process the input speech features as usual, and the speech-text shared encoder and decoder are designed to train speech and text data simultaneously. By doing so, LA-NAT aims to make the ASR model aware of lexical information, so the resulting model is expected to achieve better results by leveraging the learned linguistic knowledge. A series of experiments are conducted on the AISHELL-1, CSJ, and TEDLIUM 2 datasets. According to the experiments, the proposed LA-NAT can provide superior results than other recently proposed non-autoregressive ASR models. In addition, LA-NAT is a relatively compact model than most non-autoregressive ASR models, and it is about 58 times faster than the classic autoregressive model.
A context-aware knowledge transferring strategy for CTC-based ASR
Oct 12, 2022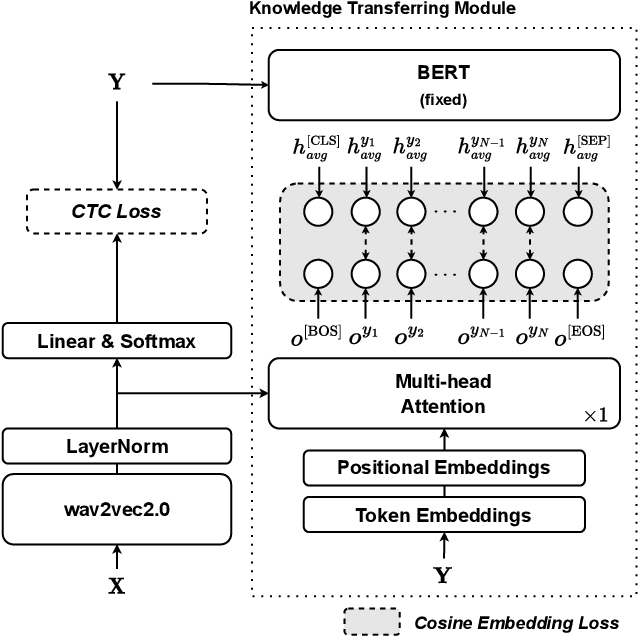
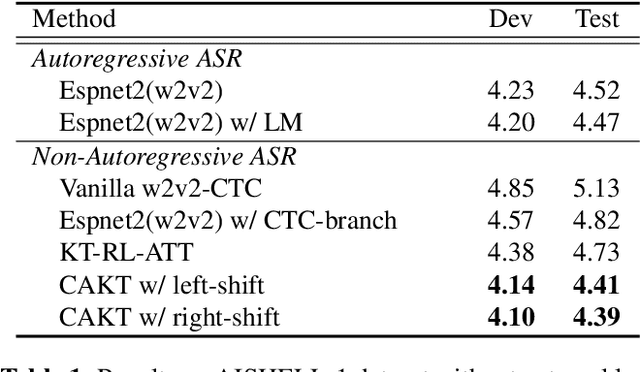
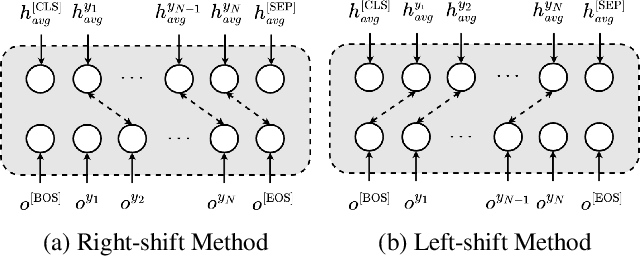
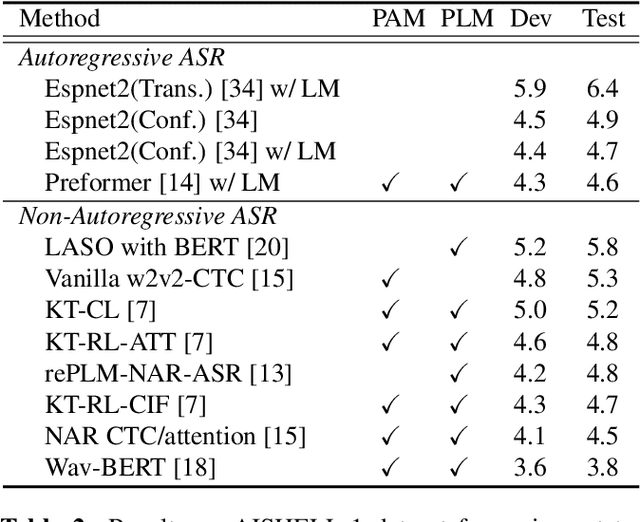
Non-autoregressive automatic speech recognition (ASR) modeling has received increasing attention recently because of its fast decoding speed and superior performance. Among representatives, methods based on the connectionist temporal classification (CTC) are still a dominating stream. However, the theoretically inherent flaw, the assumption of independence between tokens, creates a performance barrier for the school of works. To mitigate the challenge, we propose a context-aware knowledge transferring strategy, consisting of a knowledge transferring module and a context-aware training strategy, for CTC-based ASR. The former is designed to distill linguistic information from a pre-trained language model, and the latter is framed to modulate the limitations caused by the conditional independence assumption. As a result, a knowledge-injected context-aware CTC-based ASR built upon the wav2vec2.0 is presented in this paper. A series of experiments on the AISHELL-1 and AISHELL-2 datasets demonstrate the effectiveness of the proposed method.
A Transformer-based Cross-modal Fusion Model with Adversarial Training for VQA Challenge 2021
Jun 24, 2021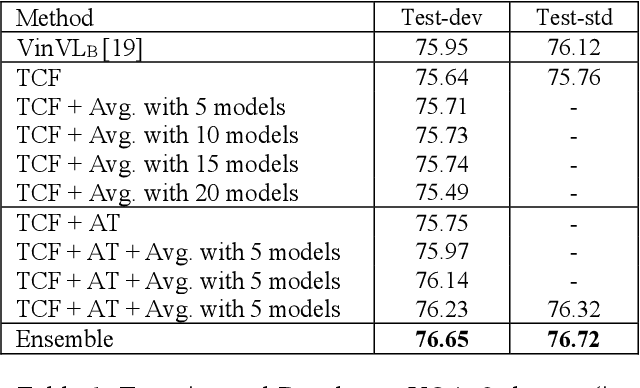
In this paper, inspired by the successes of visionlanguage pre-trained models and the benefits from training with adversarial attacks, we present a novel transformerbased cross-modal fusion modeling by incorporating the both notions for VQA challenge 2021. Specifically, the proposed model is on top of the architecture of VinVL model [19], and the adversarial training strategy [4] is applied to make the model robust and generalized. Moreover, two implementation tricks are also used in our system to obtain better results. The experiments demonstrate that the novel framework can achieve 76.72% on VQAv2 test-std set.
Non-autoregressive Transformer-based End-to-end ASR using BERT
Apr 10, 2021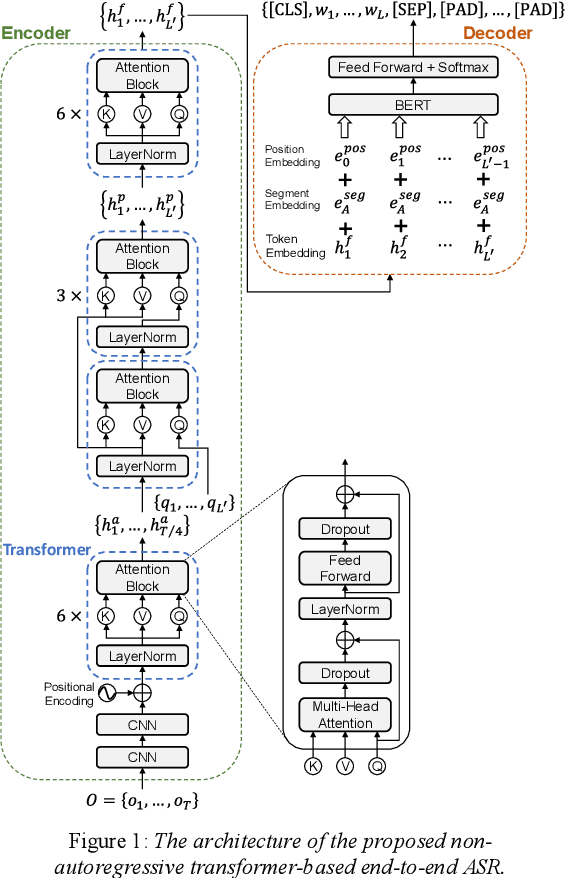
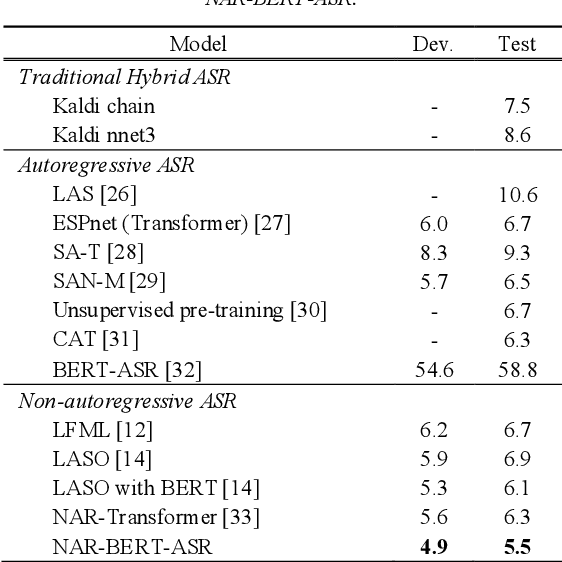

Transformer-based models have led to a significant innovation in various classic and practical subjects, including speech processing, natural language processing, and computer vision. On top of the transformer, the attention-based end-to-end automatic speech recognition (ASR) models have become a popular fashion in recent years. Specifically, the non-autoregressive modeling, which can achieve fast inference speed and comparable performance when compared to conventional autoregressive methods, is an emergent research topic. In the context of natural language processing, the bidirectional encoder representations from transformers (BERT) model has received widespread attention, partially due to its ability to infer contextualized word representations and to obtain superior performances of downstream tasks by performing only simple fine-tuning. In order to not only inherit the advantages of non-autoregressive ASR modeling, but also receive benefits from a pre-trained language model (e.g., BERT), a non-autoregressive transformer-based end-to-end ASR model based on BERT is presented in this paper. A series of experiments conducted on the AISHELL-1 dataset demonstrates competitive or superior results of the proposed model when compared to state-of-the-art ASR systems.
Speech Recognition by Simply Fine-tuning BERT
Jan 30, 2021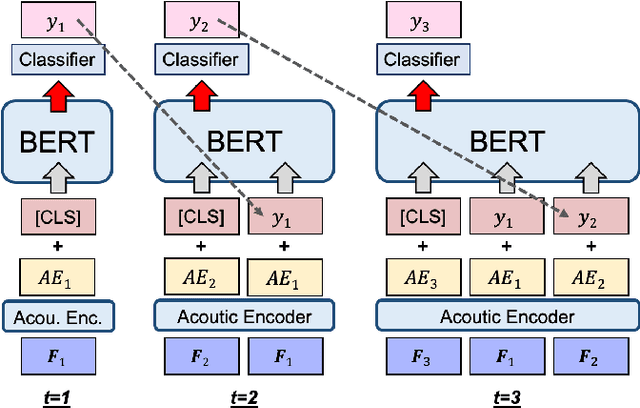
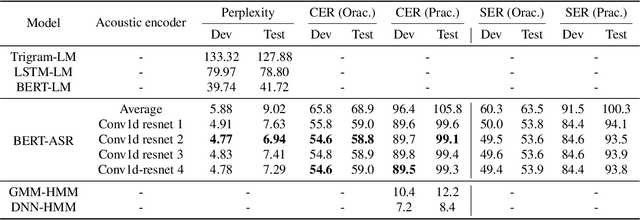
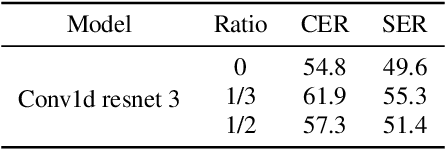
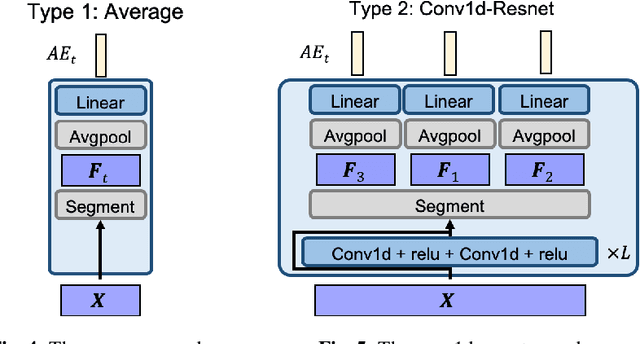
We propose a simple method for automatic speech recognition (ASR) by fine-tuning BERT, which is a language model (LM) trained on large-scale unlabeled text data and can generate rich contextual representations. Our assumption is that given a history context sequence, a powerful LM can narrow the range of possible choices and the speech signal can be used as a simple clue. Hence, comparing to conventional ASR systems that train a powerful acoustic model (AM) from scratch, we believe that speech recognition is possible by simply fine-tuning a BERT model. As an initial study, we demonstrate the effectiveness of the proposed idea on the AISHELL dataset and show that stacking a very simple AM on top of BERT can yield reasonable performance.