 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering collective narratives shifts in online discussions
Jul 17, 2023



Narrative is a foundation of human cognition and decision making. Because narratives play a crucial role in societal discourses and spread of misinformation and because of the pervasive use of social media, the narrative dynamics on social media can have profound societal impact. Yet, systematic and computational understanding of online narratives faces critical challenge of the scale and dynamics; how can we reliably and automatically extract narratives from massive amount of texts? How do narratives emerge, spread, and die? Here, we propose a systematic narrative discovery framework that fill this gap by combining change point detection, semantic role labeling (SRL), and automatic aggregation of narrative fragments into narrative networks. We evaluate our model with synthetic and empirical data two-Twitter corpora about COVID-19 and 2017 French Election. Results demonstrate that our approach can recover major narrative shifts that correspond to the major events.
CPL-NoViD: Context-Aware Prompt-based Learning for Norm Violation Detection in Online Communities
May 18, 2023



Detecting norm violations in online communities is critical to maintaining healthy and safe spaces for online discussions. Existing machine learning approaches often struggle to adapt to the diverse rules and interpretations across different communities due to the inherent challenges of fine-tuning models for such context-specific tasks. In this paper, we introduce Context-aware Prompt-based Learning for Norm Violation Detection (CPL-NoViD), a novel method that employs prompt-based learning to detect norm violations across various types of rules. CPL-NoViD outperforms the baseline by incorporating context through natural language prompts and demonstrates improved performance across different rule types. Significantly, it not only excels in cross-rule-type and cross-community norm violation detection but also exhibits adaptability in few-shot learning scenarios. Most notably, it establishes a new state-of-the-art in norm violation detection, surpassing existing benchmarks. Our work highlights the potential of prompt-based learning for context-sensitive norm violation detection and paves the way for future research on more adaptable, context-aware models to better support online community moderators.
A Data Fusion Framework for Multi-Domain Morality Learning
Apr 04, 2023Language models can be trained to recognize the moral sentiment of text, creating new opportunities to study the role of morality in human life. As interest in language and morality has grown, several ground truth datasets with moral annotations have been released. However, these datasets vary in the method of data collection, domain, topics, instructions for annotators, etc. Simply aggregating such heterogeneous datasets during training can yield models that fail to generalize well. We describe a data fusion framework for training on multiple heterogeneous datasets that improve performance and generalizability. The model uses domain adversarial training to align the datasets in feature space and a weighted loss function to deal with label shift. We show that the proposed framework achieves state-of-the-art performance in different datasets compared to prior works in morality inference.
Data-Driven Estimation of Heterogeneous Treatment Effects
Jan 16, 2023



Estimating how a treatment affects different individuals, known as heterogeneous treatment effect estimation, is an important problem in empirical sciences. In the last few years, there has been a considerable interest in adapting machine learning algorithms to the problem of estimating heterogeneous effects from observational and experimental data. However, these algorithms often make strong assumptions about the observed features in the data and ignore the structure of the underlying causal model, which can lead to biased estimation. At the same time, the underlying causal mechanism is rarely known in real-world datasets, making it hard to take it into consideration. In this work, we provide a survey of state-of-the-art data-driven methods for heterogeneous treatment effect estimation using machine learning, broadly categorizing them as methods that focus on counterfactual prediction and methods that directly estimate the causal effect. We also provide an overview of a third category of methods which rely on structural causal models and learn the model structure from data. Our empirical evaluation under various underlying structural model mechanisms shows the advantages and deficiencies of existing estimators and of the metrics for measuring their performance.
Anger Breeds Controversy: Analyzing Controversy and Emotions on Reddit
Dec 01, 2022Emotions play an important role in interpersonal interactions and social conflict, yet their function in the development of controversy and disagreement in online conversations has not been explored. To address this gap, we study controversy on Reddit, a popular network of online discussion forums. We collect discussions from a wide variety of topical forums and use emotion detection to recognize a range of emotions from text, including anger, fear, joy, admiration, etc. Our study has three main findings. First, controversial comments express more anger and less admiration, joy and optimism than non-controversial comments. Second, controversial comments affect emotions of downstream comments in a discussion, usually resulting in long-term increase in anger and a decrease in positive emotions, although the magnitude and direction of emotional change depends on the forum. Finally, we show that emotions help better predict which comments will become controversial. Understanding emotional dynamics of online discussions can help communities to better manage conversations.
Using Emotion Embeddings to Transfer Knowledge Between Emotions, Languages, and Annotation Formats
Oct 31, 2022The need for emotional inference from text continues to diversify as more and more disciplines integrate emotions into their theories and applications. These needs include inferring different emotion types, handling multiple languages, and different annotation formats. A shared model between different configurations would enable the sharing of knowledge and a decrease in training costs, and would simplify the process of deploying emotion recognition models in novel environments. In this work, we study how we can build a single model that can transition between these different configurations by leveraging multilingual models and Demux, a transformer-based model whose input includes the emotions of interest, enabling us to dynamically change the emotions predicted by the model. Demux also produces emotion embeddings, and performing operations on them allows us to transition to clusters of emotions by pooling the embeddings of each cluster. We show that Demux can simultaneously transfer knowledge in a zero-shot manner to a new language, to a novel annotation format and to unseen emotions. Code is available at https://github.com/gchochla/Demux-MEmo .
Leveraging Label Correlations in a Multi-label Setting: A Case Study in Emotion
Oct 28, 2022


Detecting emotions expressed in text has become critical to a range of fields. In this work, we investigate ways to exploit label correlations in multi-label emotion recognition models to improve emotion detection. First, we develop two modeling approaches to the problem in order to capture word associations of the emotion words themselves, by either including the emotions in the input, or by leveraging Masked Language Modeling (MLM). Second, we integrate pairwise constraints of emotion representations as regularization terms alongside the classification loss of the models. We split these terms into two categories, local and global. The former dynamically change based on the gold labels, while the latter remain static during training. We demonstrate state-of-the-art performance across Spanish, English, and Arabic in SemEval 2018 Task 1 E-c using monolingual BERT-based models. On top of better performance, we also demonstrate improved robustness. Code is available at https://github.com/gchochla/Demux-MEmo.
Noise Audits Improve Moral Foundation Classification
Oct 13, 2022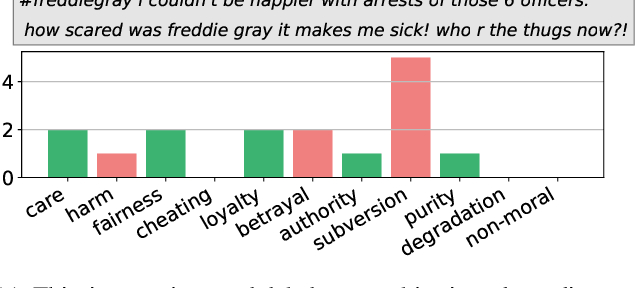
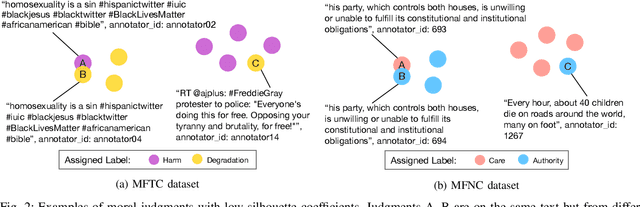
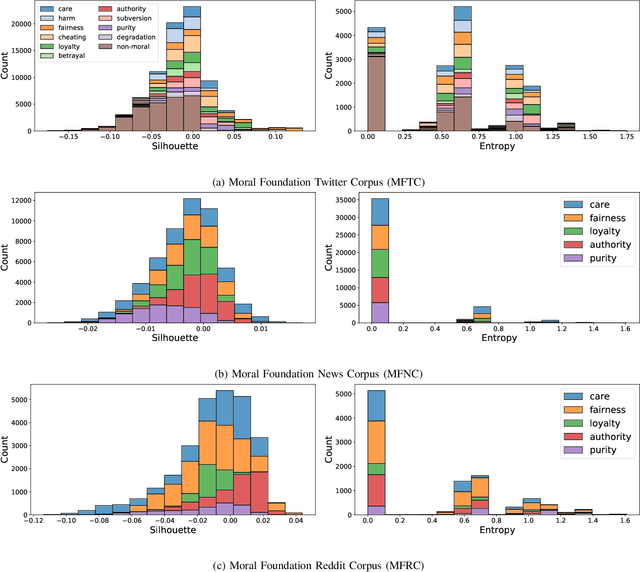
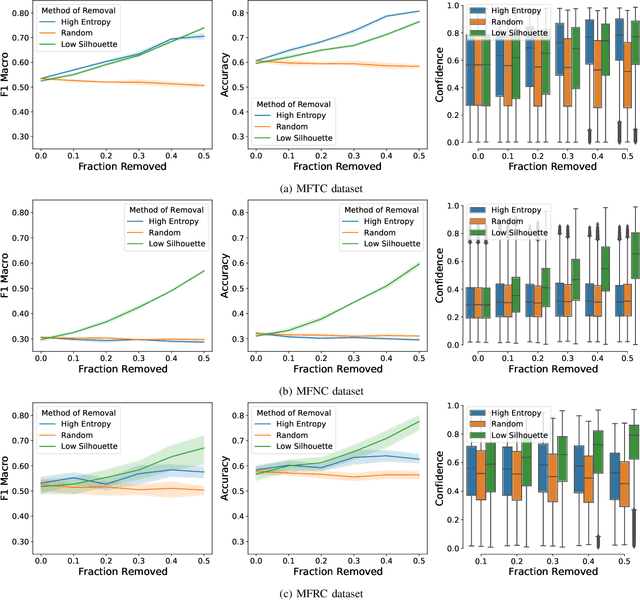
Morality plays an important role in culture, identity, and emotion. Recent advances in natural language processing have shown that it is possible to classify moral values expressed in text at scale. Morality classification relies on human annotators to label the moral expressions in text, which provides training data to achieve state-of-the-art performance. However, these annotations are inherently subjective and some of the instances are hard to classify, resulting in noisy annotations due to error or lack of agreement. The presence of noise in training data harms the classifier's ability to accurately recognize moral foundations from text. We propose two metrics to audit the noise of annotations. The first metric is entropy of instance labels, which is a proxy measure of annotator disagreement about how the instance should be labeled. The second metric is the silhouette coefficient of a label assigned by an annotator to an instance. This metric leverages the idea that instances with the same label should have similar latent representations, and deviations from collective judgments are indicative of errors. Our experiments on three widely used moral foundations datasets show that removing noisy annotations based on the proposed metrics improves classification performance.
Infusing Knowledge from Wikipedia to Enhance Stance Detection
Apr 08, 2022
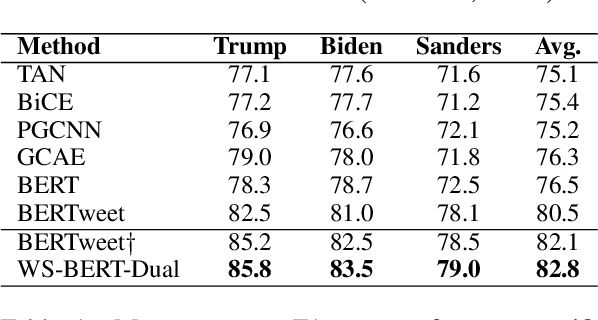
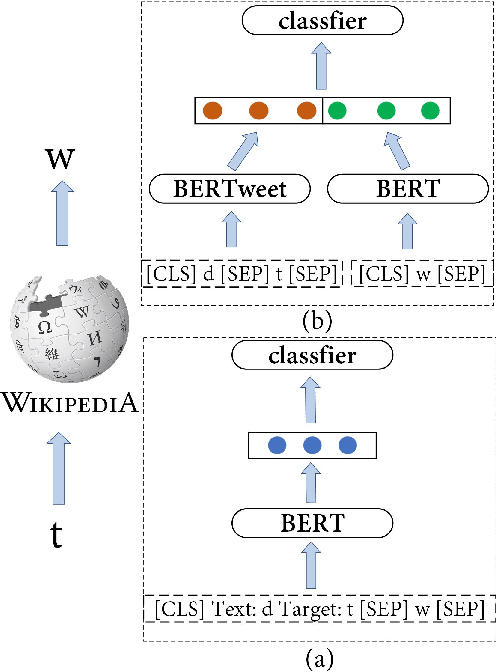
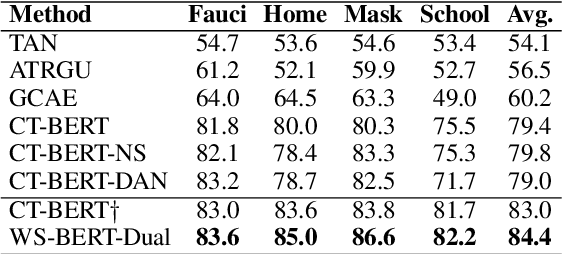
Stance detection infers a text author's attitude towards a target. This is challenging when the model lacks background knowledge about the target. Here, we show how background knowledge from Wikipedia can help enhance the performance on stance detection. We introduce Wikipedia Stance Detection BERT (WS-BERT) that infuses the knowledge into stance encoding. Extensive results on three benchmark datasets covering social media discussions and online debates indicate that our model significantly outperforms the state-of-the-art methods on target-specific stance detection, cross-target stance detection, and zero/few-shot stance detection.
Zero-shot meta-learning for small-scale data from human subjects
Mar 29, 2022
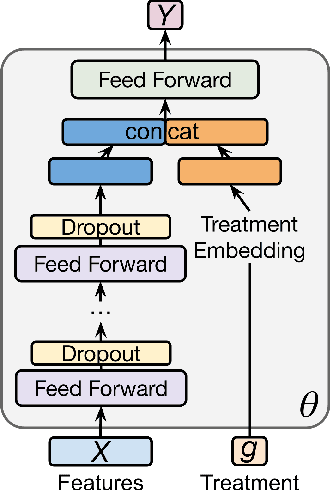
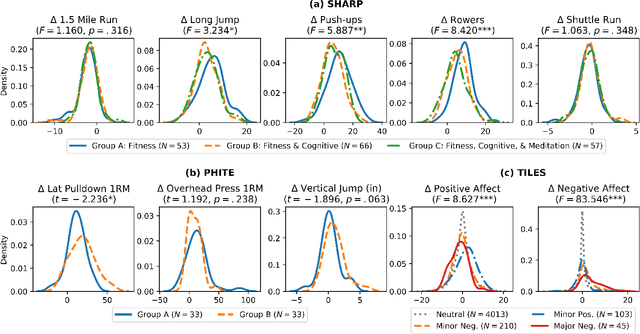
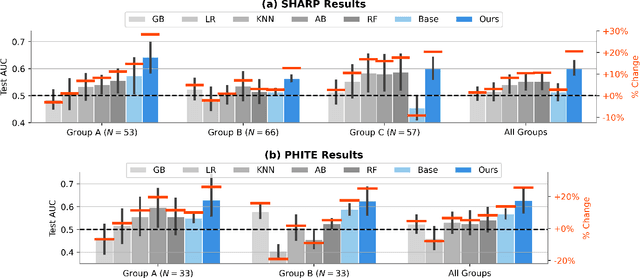
While developments in machine learning led to impressive performance gains on big data, many human subjects data are, in actuality, small and sparsely labeled. Existing methods applied to such data often do not easily generalize to out-of-sample subjects. Instead, models must make predictions on test data that may be drawn from a different distribution, a problem known as \textit{zero-shot learning}. To address this challenge, we develop an end-to-end framework using a meta-learning approach, which enables the model to rapidly adapt to a new prediction task with limited training data for out-of-sample test data. We use three real-world small-scale human subjects datasets (two randomized control studies and one observational study), for which we predict treatment outcomes for held-out treatment groups. Our model learns the latent treatment effects of each intervention and, by design, can naturally handle multi-task predictions. We show that our model performs the best holistically for each held-out group and especially when the test group is distinctly different from the training group. Our model has implications for improved generalization of small-size human studies to the wider population.